embedding、LSTM、seq2seq+attention的知识总结
一、 embedding
1. input : [ seqlen , batchsize ]
2. output: [ seq_len, batchsize, embed_dim ]
二、 LSTM
输入:
1. input: [ seq_len, batch, input_size]
2. h0 : [ num_layers * num_directions,batch_size,hidden_size ]
输出:
1. out: [ seq_len, batch, num_directions * hidden_size ]
2. hn : [ num_layers * num_directions, batch, hidden_size ]
三、seq2seq的架构图和维度
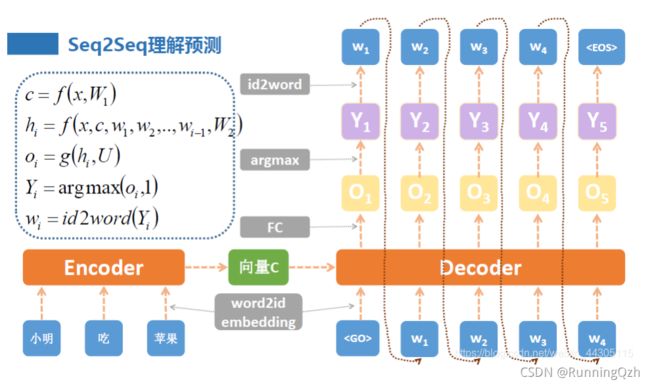

因为Encode的h和c会作为Decode的第一次的输入,所以Encode和Decode的LSTM中hiddensize必须一致。
在decode过程中,每次的input是target的每一项,或者是上一次的预测(output),而h和c则一直选取上次的。
但是这里我存在一个问题: 在decode时,我们从target中每次拿一项,循环放进lstm中拿出结果;
但是在encode时,我们直接把整个seqlen都扔到lstm中。
这两种放数据方式存在什么不同吗?
检验代码:
import torch
import torch.nn as nn
bilstm = nn.LSTM(input_size=10, hidden_size=20)
inputs = torch.randn(5, 3, 10) # [seq_len, batch, inputsize]
h0 = torch.randn(1, 3, 20) # layernum , batch , hiddensize
c0 = torch.randn(1, 3, 20)
output, (hn, cn) = bilstm(inputs, (h0, c0))
print('output shape: ', output.shape) # seqlen, batch, hiddensize
print('hn shape: ', hn.shape) # layer , batch, hiddensize
print('cn shape: ', cn.shape)
print(output)
print('----------')
outputs = torch.zeros(5, 3, 20)
seqlen = inputs.size(0)
for i in range(seqlen):
input = torch.Tensor(inputs[i])
input = input.unsqueeze(0)
output, (h0, c0) = bilstm(input, (h0, c0))
outputs[i] = output
print(outputs)
结论:
把一个seqlen的序列直接扔到lstm 和 for循环每次扔一个, 扔seqlen次,最后的结果是一样的。
通过这个例子,我顺便明白了LSTM的反人类设计之:为什么seqlen作为第一个参数?
因为LSTM内部也是通过for循环每次取出seqlen的一个,然后扔进LSTM中运行的,一共循环seqlen次,所以seqlen作为第一个维度比较好做。 (哈哈啊哈啊哈哈我真聪明!)
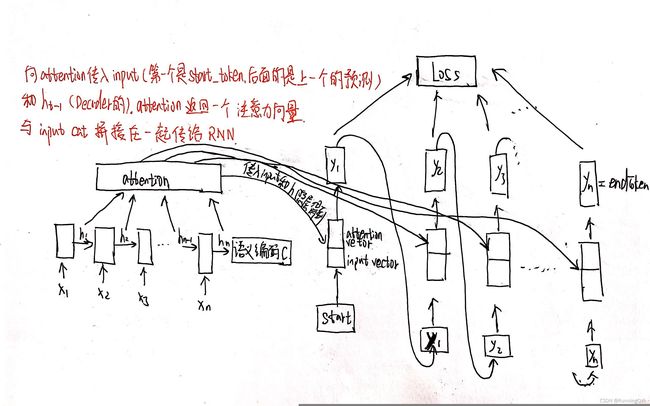
四、初探Attention 机制
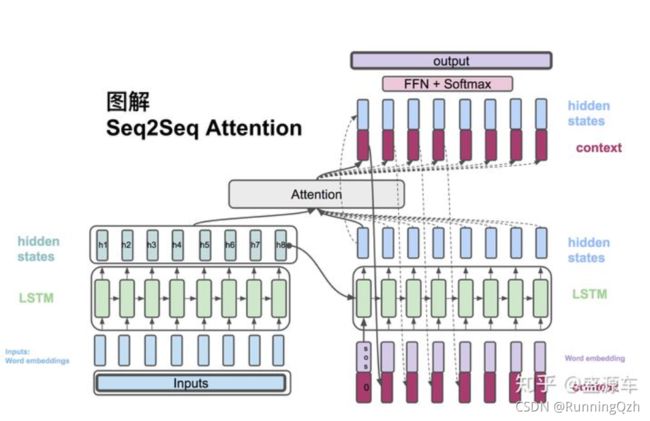
实现Attention的方式有很多种,这里展示比较常用的一种。在Encoder的过程中保留每一步RNN单元的隐藏状态h1……hn,组成编码的状态矩阵Encoder_outputs;在解码过程中,原本是通过上一步的输出yt-1和前一个隐藏层h作为输入,现又加入了利用Encoder_outputs计算注意力权重attention_weight的步骤。
相比于原始的Encoder-Decoder模型,加入Attention机制后最大的区别就是它不在要求编码器将所有输入信息都编码进一个固定长度的向量之中。而是,编码器需要将输入编码成一个向量的序列,在解码的时候,每一步都会选择性的从向量序列中挑选一个子集进行进一步处理。这样,在产生每一个输出的时候,都能够做到充分利用输入序列携带的信息。而且这种方法在翻译任务中取得了非常不错的成果。
这是一个基本的attention模型,encoder保存每次的hidden。在decoder端把input传入和隐藏单元拼接起来传入线性层,将其映射到seqlen维,每一维描述的是输入encoder中各位置元素对当前decoder输出单词的重要性占比。然后利用矩阵相乘获取到加权求和之后的注意力向量,用于描述“划了重点”之后的输入序列对当前预测这个单词的影响。然后将注意力向量和input拼接在一起,再利用一个线性层将其映射到RNN的输入维度,最后送入RNN,得到新的hidden和output。output作为下一个的输入。