机器学习 | 李宏毅课程笔记(三)Optimization
【对上篇中Optimization issue详细展开】
目录
为什么Optimization Fails?
一、Gradient=0引起的Optimization issue
1.为什么讨论Critical point?
2.如何判断一个点是Local minima还是Saddle point呢?
3.Saddle point如何进一步更新参数?
4.Saddle point和Local minima哪个更加常见呢?
5.如何对抗Local Minima或Saddle Point呢?
Batch
Momentum
二、Loss不能再小引起的Optimization issue
1.为什么会出现Loss不能再小的情况呢?
2.gradient descent特殊化——特制化learning rate
方法①:Root Mean Square
方法②:RMSProp
3.Adagrad训练结果
[改进解读]
[“爆炸”现象原因解读]
4.learning rate scheduling(让学习速率与时间相关)
①Learning Rate Decay(学习速率衰减)
②Warm Up
Optimization总结
为什么Optimization Fails?
①gradient为0。(当梯度值接近0时,参数不会再更新)
②loss值无法再小。(Loss值不会再变小≠gradient=0)
一、Gradient=0引起的Optimization issue
梯度为0的点统称为Critical point:包括Local minima和Saddle point两种。
1.为什么讨论Critical point?
卡在Local minima则no way go,卡在Saddle point还可以继续走,所以讨论训练模型过程中到底是卡在了哪里对于提高训练结果准确性是必要的。若是Saddle point,则有机会继续训练,H可以指出update参数的方向(后文中会介绍H—Hessian)。
2.如何判断一个点是Local minima还是Saddle point呢?
——要知道Loss Function形状。
怎么知道Loss Function形状呢?
——无法知道Loss Function完整形状,但给定某一组参数θ’,利用多元函数的泰勒展开,在θ’附近的Loss Function是有办法写出来的。
- 写在θ’附近的Loss函数式
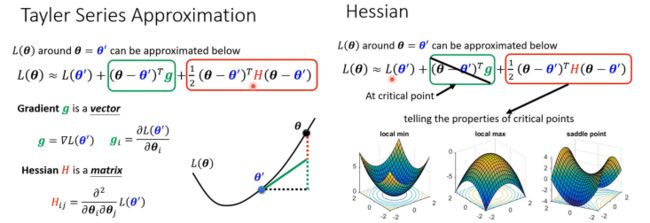
由展开式可知,当梯度为0时,右侧第二项为0,则可根据H来判断θ’附近的形状。
- 判断θ’附近的形状
利用局部极值的性质,通过比较θ与θ’两点处的Loss函数值大小来判断θ’点附近Loss函数的形状,从而判断θ’点是Local minima还是Saddle point。

【实例计算Example】

【计算步骤】
写出Loss函数;求出Loss函数对每一个参数的偏导,将待验证点(w1=0,w2=0)的参数值带入,判断其是否为Critical Point,若其对应偏导值均为0,则梯度g(L对w1的偏导,L对w2的偏导)=0向量,即梯度值为0,则表示其是Critical Point;进而求二阶偏导,表示出Hessian;求出Hessian矩阵的特征值eigen value,通过其特征值的正负性来判断该矩阵是正定、负定还是不定的,进而根据上文中的结论判断出该点是Local minima还是Saddle Point。
3.Saddle point如何进一步更新参数?
如果该点是Saddle Point,那么我们就有机会继续Update参数训练模型。Hessian不仅可以判断出该点是Local minima还是Saddle Point,还可以指出下一步Update参数的方向。
那么Hessian如何指出下一步Update参数的方向呢?
先给出结论:找出H的负的特征值λ及其对应的特征向量u,沿着H的特征向量u方向更新参数θ(即θ=θ’+u)即可减小Loss
推导:设H的特征向量为u,特征值为λ,根据上文中提到的在一点θ’处的泰勒展开公式,若令θ-θ’=u(即θ=θ’+u),则原展开式右边第二项即可更换为uTHu。根据上文可知,当λ<0时,该点是Saddle point,此时uTHu=uT(λu)=λ||u||2<0(根据特征向量定义式得出),所以此时L(θ)

4.Saddle point和Local minima哪个更加常见呢?
如果在从二维空间去看的话Saddle Point就可能被认为是Local Minima,反过来假如我们从更高维度去看的话Local Minima却是Saddle Point。也就是说假如我们在某个维度没路可走的时候,我们可以提高维度来使其变成Saddle Point从而有路可走。这就是现在为什么神经网络如此复杂、参数众多的重要原因。
5.如何对抗Local Minima或Saddle Point呢?
有可能对抗Local Minima或Saddle Point的技术:Batch&Momentum
[Smaller batch size and momentum help escape critical points.]
-
Batch
(笔记一中有提到Batch与Epoch)
现在假如说有一笔N资料,我们可以把N笔资料一次性全部跑完再计算Loss和更新一次参数θ,但是我们也可以将N笔资料分成许多个batch资料,我们每跑完一个batch资料就计算更新一次参数。1 epoch等于把全部的batch都看一遍。
【为什么需要batch?】
首先将用batch与不用batch的模型训练进行比较。
参数更新效果比较:没有用batch的model的蓄力时间比较长,但每走一步都比较稳;用了batch的model蓄力时间短,但每次走的时候是十分乱的。

参数更新时间比较:如果不考虑平行运算,直觉上没用batch会比用了batch的耗费时间长;但是如果考虑GPU的平行运算,没有用batch耗费的时间不一定比用了batch所花时间长。

一个batch会更新一次参数,一个epoch会查完所有的batch,更新与batch数相同次参数。左图中显示当batch size=1000时,其每一个batch更新的时间和batch size=1时的更新时间所差无几,但对于相同训练数据数来说,大batch(batch size=1000)的一个epoch所需要更新的次数却是比小batch(batch size=1)更新次数要少很多的,也就是说此时小batch所耗费的时间更多。
预测正确率比较:小batch预测结果正确率更高。大batch往往会给训练数据准确性带来较差的结果。对于相同模型,大batch比小batch准确率更低,说明不是model bias,而是optimization issue。

【为什么小的batch会有更好的结果呢?】
对于未用batch的模型,沿着Loss函数来更新参数,当陷入一个local minima或者saddle point之后就停止更新参数;而对于用batch的模型,并不是对整体计算出一个Loss,还是对每一个batch计算出L1,L2...,计算gradient更新参数时,假设我们用θ1参数组来算一个batch(它的loss函数是L1)的gradient时,当遇到gradient=0时就卡住了,但不会停止更新函数,可以用下一个batch来继续训练优化model。因为参数θ1在L1函数上gradient=0,而在L2函数上gradient不一定为0,所以训练可以继续进行。
【Small batch VS Large batch】
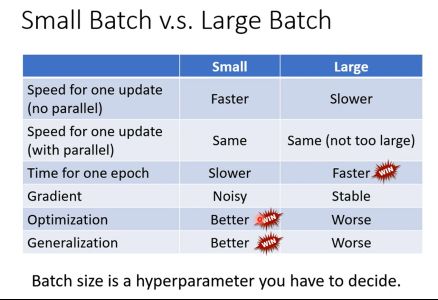
根据比较可以看到small batch和large batch有各自的优点,也正因为如此,所以Batch size变成一个hyper parameter(超参数)
-
Momentum
它的概念可以想象成物理世界中的惯性。在物理世界,一个球在Loss高速滚下,由于动量其不一定会被Local Minima或Saddle ponit卡住。
[工作过程]
[Gradient descent]
对于一个初始参数点θ,计算该点处的gradient,沿gradient的反方向更新参数得到θ1,再计算该点处的gradient,沿反方向更新参数得到θ2,重复此过程。
注:因为梯度方向是函数增加速度最快的方向,沿其反方向更新则可以使Loss函数值减少的最快。
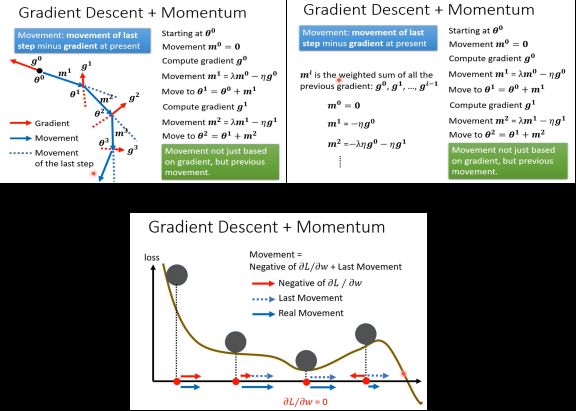
[Gradient descent + Momentum]
更新gradient时不只是沿着gradient的反方向,还要加上前一步参数Update的方向进行更新,即向量相加。
其本质是不止看该点的梯度方向,还会将之前所有的梯度方向综合起来。这样即使在Critical point处gradient=0,还会有一个momentum向量提供参数更新方向,保证其可以继续更新。可结合下图理解参数更新过程。
二、Loss不能再小引起的Optimization issue
上文提到在沿着Loss函数我们可能会卡在Critical point从而导致参数无法更新,Loss也就不再下降。但事实是当Loss不再下降的时候,gradient不一定很小。也就是说Loss不能再小≠gradient=0。
1.为什么会出现Loss不能再小的情况呢?
①可以想象更新参数时不停在一个峡谷里震荡,无法下落到最低点。这时不能继续更新参数并不是因为卡在Critical point而是因为learning rate太大,使更新参数步伐太大,从而导致gradient不断在山谷两侧反复横跳,导致Loss值不能再下降。
(注:Learning rate决定更新参数的步伐)
那么为什么不降低learningrate使其下降到谷底呢?
②再想象这样一种情况,当峡谷谷底附近十分平缓时,十分小的learning rate又会导致其依旧不能继续向前走。
基于这两种情况,我们就需要一种特殊的gradient descent来实现参数更新。也就是每一个参数需要拥有不同的Learning rate来进行更新。
2.gradient descent特殊化——特制化learning rate
一般的gradient descent法实现参数更新的公式为:
(其中η是learning rate,i是参数编号,t是更新迭代次数)
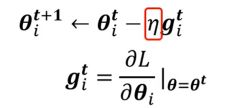
通过上述两种情况的举例,我们可以得到这样的结论:当在某个地方的方向十分陡峭时我们就需要小的learning rate,反之需要大的learning rate。根据gradient的几何意义可以知道,越陡峭的地方gradient会越大,越平缓的地方gradient会越小。因此可以引入一个与gradient相关的参数σ用来控制learning rate的大小。使得不同参数不同迭代次数下对应的learning rate均不相同。即更新参数的同时,也会更新learning rate。则特制化learning rate后对应的更新参数公式为:
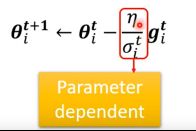
那么与gradient相关的参数σ应该如何计算呢?
方法①:Root Mean Square
——将之前所有gradient平方和再平均开方。(其中每一时刻的gradient都具有同样的重要性)

该方法可以被用于Adagrad算法中。Adagrad是解决不同参数应该使用不同的更新速率的问题。Adagrad为自适应地为各个参数分配不同学习率的算法。

但是Root Mean Square方法还是不够好的,上述方法中同一个参数对应的gradient值都是差不多的,都是朝着一个方向呈单调性变化的,但是在现实实验中我们可能会遇到的gradient在一个方向变化的程度可以是很大的。
所以我们就需要能够动态改变learning rate的值。
方法②:RMSProp
(可以自己调整过去与当前gradient的重要性)这个α就像learning rate一样,需要人工调整,是一个hyperparameter。通过将α设的很小接近于0可以使当前计算的gradient具有更大的重要性,这样会使learning rate根据当前坡度进行很快的调整。这是相对于方法1的一个进步。
我们结合RMSProp和Momentum就可以构成最常用的优化器:Adam

3.Adagrad训练结果

[改进解读]
未采用Adaptive Learning rate前,该训练可以走到蓝色箭头位置。采用Adagrad方法后,其可以在水平方向上走得更远,更接近最低点。(黄色箭头就是改进的地方。)因为刚开始在水平方向上走的时候水平方向上gradient很小,所以就会自动调大水平方向上的learning rate,步伐变大,就可以不断地前进。
[“爆炸”现象原因解读]
我们注意到最左侧红色圈里出现了“爆炸”现象,这是为什么呢?是因为在初始位置纵向上gradient很大,但在水平前进的方向上纵向的gradient很小,但对于Adagrad方法来说,其在更新学习率时,是会对过去所有gradient平方求和取均值的,所以随着迭代次数增多,累积很小的纵向gradient值,分母(迭代次数)增大,但分子(即gradient平方和)增加得却很小很小,这就使得参数σ变得很小,学习速率变得很大,所以在纵向上就会突然爆发。
但它是可以修正回来的。因为爆发后,纵向的gradient又会变大,这个σ又慢慢变大,参数update的步伐就又慢慢变小。我们会发现它走着走着,突然往左右喷了一下,但不会永远在那里震荡停不下来。这个力道会慢慢变小,因为有摩擦力让它慢慢地回到中间这个峡谷来,但是之后又累计一段时间以后又会爆发,然后又慢慢地回来。
[如何处理“爆发”问题呢?]
4.learning rate scheduling(让学习速率与时间相关)

①Learning Rate Decay(学习速率衰减)
随着时间不断地前进、随着参数不断的update,让η越来越小。
合理性:随着参数不断update,距离终点越来越近,所以把learning rate减小,让参数更新踩一个刹车,让参数的更新能够慢慢地慢下来。
②Warm Up
先变大后变小。其中变大变小的程度、速度都属于hyperparameter,要自己手动调。
Optimization总结

原始版本的gradient descent只是在梯度反方向进行更新参数,且所有参数都使用相同的learning rate;
而现在完整的optimization版本,在更新参数的方向上使用momentum方法,综合上过去所有梯度的方向进行向量加和后,沿其反方向更新;在更新步伐上,采用RMS方法,将过去所有梯度值的大小进行平方加和取平均,并结合Learning rate scheduling方法使learning rate与训练时间关联起来,在更新参数的同时也更新learning rate,以实时更改参数更新的步伐。