必备算法基础——神经网络
线性函数(也叫得分函数):

输入图像经过一个函数映射得到图像属于每个类别的得分,x为图像数据矩阵,W表示属于某个类别的权重参数。
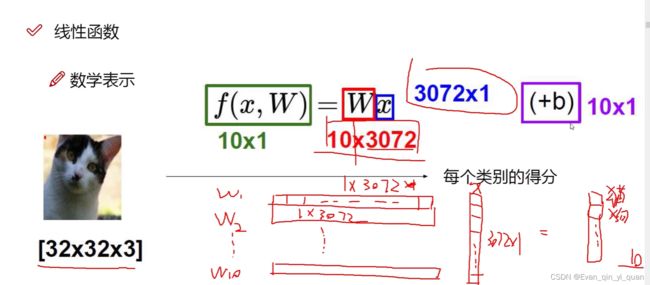
划分10个类别,W1表示属于猫类别的权重,W1*x表示属于猫的得分,W2、W3.....依次类推。
“b” 属于一个偏置项,用来微调 ,表示对于得到的10个类别都要进行微调。权重参数W对结果起决定性作用。
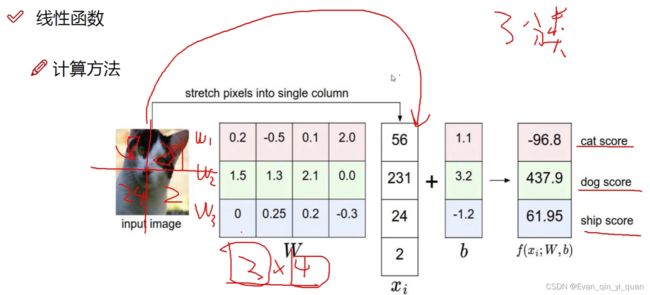
假设输入图像xi有4个像素点 ,划分为三个类别cat、dog、ship;W1的4个权重值的大小表示对应像素点对于cat类别的重要程度,0.2与56对应,-0.5与231对应。每个类别的权重值大小表示对应像素点对当前类别的影响的重要程度,比如w2(1.5,1.3,2.1,0)中0对应像素2,表示像素点2对于类别dog的影响比较小,正值代表促进的作用,负值代表抑制的作用。
w1*xi+b =-96.8,得到属于cat类别的得分,依次类推。
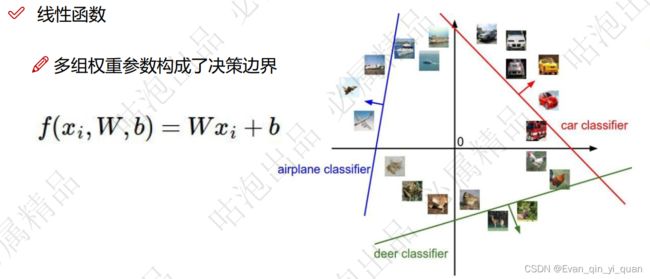
神经网络的作用就是什么样的W能更适合数据做当前的任务,我们就怎么样改变这个W,一开始拿随机值做W,在迭代过程中想办法不断改进W参数。
损失函数:衡量分类或者回归结果的好坏,损失函数是当我们获得一个结果后才能评估的,做得好损失值小,做的不好损失值大

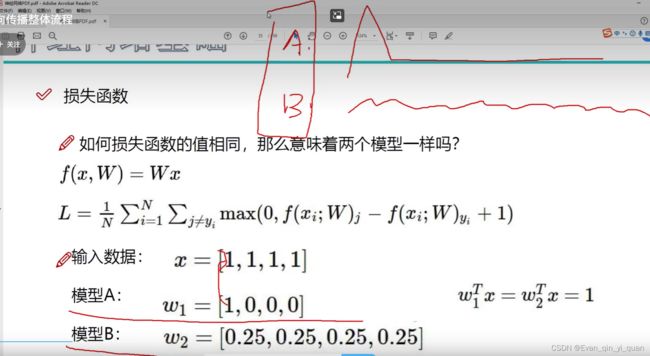
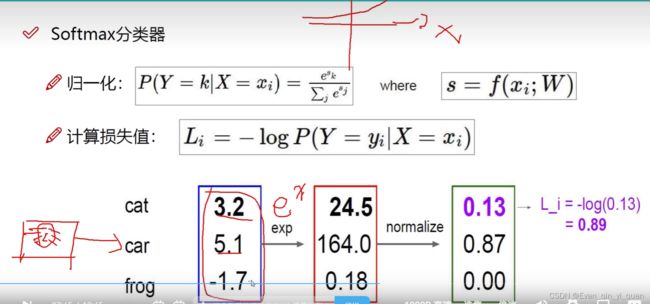
例如:第一幅猫图像属于cat类别是3.2分,属于car类别是5.1分,错误判断为car类别。Sj表示错误类别得分,Syi表示正确类别得分
损失函数当其值为0时代表没有损失,加“+1”表示正确类别至少比错误类别高1以上才算没有损失的
损失函数改进
虽然下面两个模型的损失函数值相同,但两个模型不一样 ,模型A中后3个权重值为0,说明它只关注输入数据中的第1个,只关注局部后面的不关注。模型B是对输入数据的每一个都关注。
假设模型A输出数据如下图,会产生变异,我们希望得到的是模型B的图
因此在构建损失函数的时候加入正则化惩罚项,用来去掉变异,入值比较大说明要去掉数据中的变异,神经网络过于强大的,过拟合的风险越大


通过exp映射,将差异放大,x=3.2, e^x = 24.5, x=5.1, e^5.1 = 164,依次类推。
通过归一化normalize得到概率值24.5/(0.18+164+24.5) =0.13
属于cat得分24.5,car:164,frog:0.18,那么属于cat的概率即为24.5/(0.18+164+24.5) =0.13,
属于car的概率为164/(0.18+164+24.5) =0.87
归一化公式就是:先x=3.2, e^x = 24.5, x=5.1, e^5.1 = 164,x=-1.7, e^(-1.7) = 0.18
然后24.5/(0.18+164+24.5) =0.13
第一步得到,计算各个得分映射e^sk,第二步,再求出某个得分的概率
通过对数函数计算损失值,概率越接近1说明判断越准确,对数函数越接近0,损失越小。
回归任务由得分值计算损失,分类任务由概率值计算损失
得到x,给一个w,就能计算损失,神经网络就是怎么样调整W,才能使损失变小,这就是一种优化。
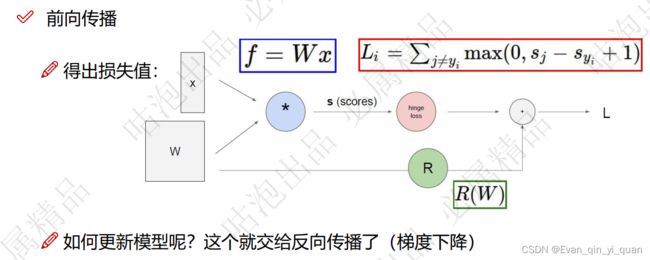 hinge loss :损失函数
hinge loss :损失函数