Conformer
注:下有视频讲解,可供参考
论文题目
Conformer: Local Features Coupling Global Representations for Visual Recognition
摘要
在卷积网络中,卷积操作非常擅长捕捉局部特征信息,但是对于捕捉图像中的全局特征信息就非常困难;对于Transformer,级联的self-attention机制可以捕捉到长距离的特征信息,但是又会弱化掉局部特征信息。其实这也是卷积和Transformer机制各自的优缺点,如何解决呢?论文中的思想其实很容易想到,既然单一的卷积或者Transformer机制都无法很好的获得图像的feature information,那么两个联合起来呢?于是,论文中提出一种混合网络,即Conformer,充分利用到卷积和transformer机制的优点。Conformer依赖于Feature Coupling Unit(FCU)特征耦合单元,以一种交互式的方式去融合convolutional得到的local feature和transformer得到的global feature。Conformer采用并行式结构,以获取最大程度上的local features和global features。实验结果上,在ImageNet上的Top-1相比DeiT-B高出2.3%;在COCO数据集上的检测和分割任务上,相比于ResNet-101作为backbone,分别高出3.7个点和3.6个点。
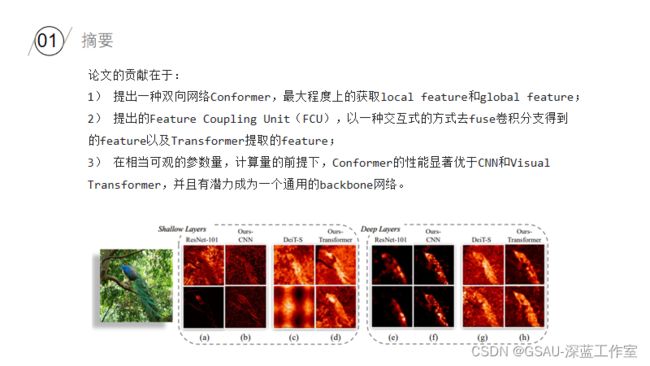
网络结构

CNN Branch

Transformer Branch
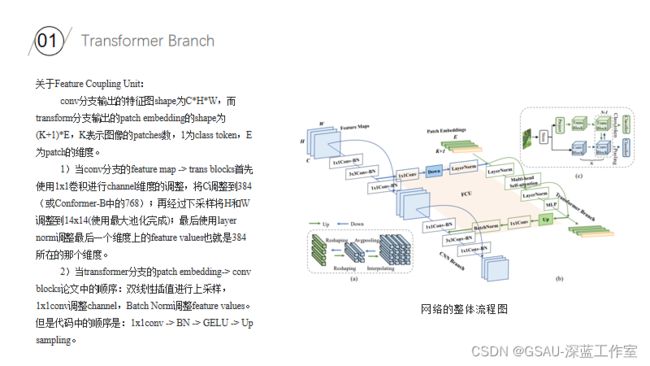
Conformer代码段
class Conformer(nn.Module):
def __init__(self, patch_size=16, in_chans=3, num_classes=1000, base_channel=64, channel_ratio=4, num_med_block=0,
embed_dim=768, depth=12, num_heads=12, mlp_ratio=4., qkv_bias=False, qk_scale=None,
drop_rate=0., attn_drop_rate=0., drop_path_rate=0.):
# Transformer
super().__init__()
self.num_classes = num_classes
self.num_features = self.embed_dim = embed_dim # num_features for consistency with other models
assert depth % 3 == 0
self.cls_token = nn.Parameter(torch.zeros(1, 1, embed_dim))
self.trans_dpr = [x.item() for x in torch.linspace(0, drop_path_rate, depth)] # stochastic depth decay rule
# Classifier head
self.trans_norm = nn.LayerNorm(embed_dim)
self.trans_cls_head = nn.Linear(embed_dim, num_classes) if num_classes > 0 else nn.Identity()
self.pooling = nn.AdaptiveAvgPool2d(1)
self.conv_cls_head = nn.Linear(int(256 * channel_ratio), num_classes)
# Stem stage: get the feature maps by conv block (copied form resnet.py)
self.conv1 = nn.Conv2d(in_chans, 64, kernel_size=7, stride=2, padding=3, bias=False) # 1 / 2 [112, 112]
self.bn1 = nn.BatchNorm2d(64)
self.act1 = nn.ReLU(inplace=True)
self.maxpool = nn.MaxPool2d(kernel_size=3, stride=2, padding=1) # 1 / 4 [56, 56]
# 1 stage
stage_1_channel = int(base_channel * channel_ratio)
trans_dw_stride = patch_size // 4
self.conv_1 = ConvBlock(inplanes=64, outplanes=stage_1_channel, res_conv=True, stride=1)
self.trans_patch_conv = nn.Conv2d(64, embed_dim, kernel_size=trans_dw_stride, stride=trans_dw_stride, padding=0)
self.trans_1 = Block(dim=embed_dim, num_heads=num_heads, mlp_ratio=mlp_ratio, qkv_bias=qkv_bias,
qk_scale=qk_scale, drop=drop_rate, attn_drop=attn_drop_rate, drop_path=self.trans_dpr[0],
)
# 2~4 stage
init_stage = 2
fin_stage = depth // 3 + 1
for i in range(init_stage, fin_stage):
self.add_module('conv_trans_' + str(i),
ConvTransBlock(
stage_1_channel, stage_1_channel, False, 1, dw_stride=trans_dw_stride, embed_dim=embed_dim,
num_heads=num_heads, mlp_ratio=mlp_ratio, qkv_bias=qkv_bias, qk_scale=qk_scale,
drop_rate=drop_rate, attn_drop_rate=attn_drop_rate, drop_path_rate=self.trans_dpr[i-1],
num_med_block=num_med_block
)
)
stage_2_channel = int(base_channel * channel_ratio * 2)
# 5~8 stage
init_stage = fin_stage # 5
fin_stage = fin_stage + depth // 3 # 9
for i in range(init_stage, fin_stage):
s = 2 if i == init_stage else 1
in_channel = stage_1_channel if i == init_stage else stage_2_channel
res_conv = True if i == init_stage else False
self.add_module('conv_trans_' + str(i),
ConvTransBlock(
in_channel, stage_2_channel, res_conv, s, dw_stride=trans_dw_stride // 2, embed_dim=embed_dim,
num_heads=num_heads, mlp_ratio=mlp_ratio, qkv_bias=qkv_bias, qk_scale=qk_scale,
drop_rate=drop_rate, attn_drop_rate=attn_drop_rate, drop_path_rate=self.trans_dpr[i-1],
num_med_block=num_med_block
)
)
stage_3_channel = int(base_channel * channel_ratio * 2 * 2)
# 9~12 stage
init_stage = fin_stage # 9
fin_stage = fin_stage + depth // 3 # 13
for i in range(init_stage, fin_stage):
s = 2 if i == init_stage else 1
in_channel = stage_2_channel if i == init_stage else stage_3_channel
res_conv = True if i == init_stage else False
last_fusion = True if i == depth else False
self.add_module('conv_trans_' + str(i),
ConvTransBlock(
in_channel, stage_3_channel, res_conv, s, dw_stride=trans_dw_stride // 4, embed_dim=embed_dim,
num_heads=num_heads, mlp_ratio=mlp_ratio, qkv_bias=qkv_bias, qk_scale=qk_scale,
drop_rate=drop_rate, attn_drop_rate=attn_drop_rate, drop_path_rate=self.trans_dpr[i-1],
num_med_block=num_med_block, last_fusion=last_fusion
)
)
self.fin_stage = fin_stage
trunc_normal_(self.cls_token, std=.02)
self.apply(self._init_weights)
def _init_weights(self, m):
if isinstance(m, nn.Linear):
trunc_normal_(m.weight, std=.02)
if isinstance(m, nn.Linear) and m.bias is not None:
nn.init.constant_(m.bias, 0)
elif isinstance(m, nn.LayerNorm):
nn.init.constant_(m.bias, 0)
nn.init.constant_(m.weight, 1.0)
elif isinstance(m, nn.Conv2d):
nn.init.kaiming_normal_(m.weight, mode='fan_out', nonlinearity='relu')
elif isinstance(m, nn.BatchNorm2d):
nn.init.constant_(m.weight, 1.)
nn.init.constant_(m.bias, 0.)
elif isinstance(m, nn.GroupNorm):
nn.init.constant_(m.weight, 1.)
nn.init.constant_(m.bias, 0.)
@torch.jit.ignore
def no_weight_decay(self):
return {'cls_token'}
def forward(self, x):
B = x.shape[0]
cls_tokens = self.cls_token.expand(B, -1, -1)
# pdb.set_trace()
# stem stage [N, 3, 224, 224] -> [N, 64, 56, 56]
x_base = self.maxpool(self.act1(self.bn1(self.conv1(x))))
# 1 stage
x = self.conv_1(x_base, return_x_2=False)
x_t = self.trans_patch_conv(x_base).flatten(2).transpose(1, 2)
x_t = torch.cat([cls_tokens, x_t], dim=1)
x_t = self.trans_1(x_t)
# 2 ~ final
for i in range(2, self.fin_stage):
x, x_t = eval('self.conv_trans_' + str(i))(x, x_t)
# conv classification
x_p = self.pooling(x).flatten(1)
conv_cls = self.conv_cls_head(x_p)
# trans classification
x_t = self.trans_norm(x_t)
tran_cls = self.trans_cls_head(x_t[:, 0])
return [conv_cls, tran_cls]分享视频:
Conformer
分享人:李 龙
分享时间:2022/4/19
分享平台:腾讯会议