GPU通用计算调研报告
摘要:NVIDIA公司在1999年发布GeForce256时首先提出GPU(图形处理器)的概念,随后大量复杂的应用需求促使整个产业蓬勃发展至今。GPU在这十多年的演变过程中,我们看到GPU从最初帮助CPU分担几何吞吐量,到Shader(着色器)单元初具规模,然后出现Shader单元可编程性,到今天GPU通用计算领域蓬勃发展这一清晰轨迹。本报告首先根据搜集到的资料记录GPU通用计算的发展过程中硬件和软件的演变,然后介绍并简要比较现在比较流行的GPU通用计算编程模型,最后对GPU通用计算在不同领域的成功应用进行概述。
关键词:GPU GPU通用计算 可编程单元 编程模型 GPGPU应用
1、GPU通用计算的背景和动机
GPU英文全称Graphic Processing Unit,中文翻译为“图形处理器”。GPU从诞生之日起就以超越摩尔定律的速度发展,运算能力不断提升。业界很多研究者注意到GPU进行计算的潜力,于2003年SIGGRAPH大会上提出了GPGPU(General-purpose computing on graphics processing units)的概念。GPU逐渐从由若干专用的固定功能单元(Fixed Function Unit)组成的专用并行处理器向以通用计算资源为主,固定功能单元为辅的架构转变。
1.1 为什么要用GPU进行计算
GPU在处理能力和存储器带宽上相对于CPU有明显优势,在成本和功耗上也不需要付出太大代价。由于图形渲染的高度并行性,使得GPU可以通过增加并行处理单元和存储器控制单元的方式提高处理能力和存储器带宽。GPU设计者将更多的晶体管用作执行单元,而不是像CPU那样用作复杂的控制单元和缓存并以此来提高少量执行单元的执行效率[1]。图1对CPU与GPU中的逻辑架构进行了对比。
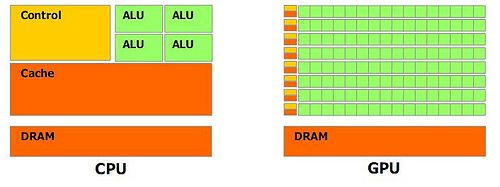
图1 CPU和GPU逻辑架构对比
CPU的整数计算、分支、逻辑判断和浮点运算分别由不同的运算单元执行,此外还有一个浮点加速器。因此,CPU面对不同类型的计算任务会有不同的性能表现。而GPU是由同一个运算单元执行整数和浮点计算,因此,GPU的整型计算能力与其浮点能力相似。目前,主流GPU都采用了统一架构单元,凭借强大的可编程流处理器阵容,GPU在单精度浮点运算方面将CPU远远甩在身后[1]。最顶级的英特尔Core i7 965处理器,在默认情况下,它的浮点计算能力只有NVIDIA GeForce GTX 280 的1/13,与AMD Radeon HD 4870相比差距就更大。
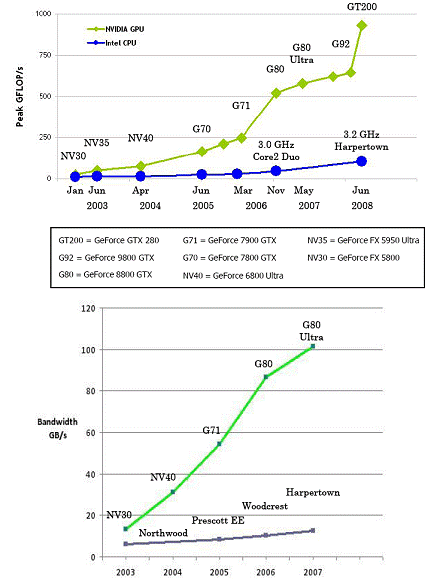
图2 CPU 和 GPU 的每秒浮点运算次数和存储器带宽
GPU运算相对于CPU还有一项巨大的优势,那就是其内存子系统,也就是GPU上的显存[1]。当前桌面级顶级产品3通道DDR3-1333的峰值是32GB/S,实测中由于诸多因素带宽在20 GB/S上下浮动。AMD HD 4870 512MB使用了带宽超高的GDDR5显存,内存总线数据传输率为3.6T/s或者说107GB/s的总线带宽。NVIDIA GTX280使用了高频率GDDR3显存,但是其显存控制器支持的位宽达到了512bit,搭载16颗0.8ns GDDR3显存,带宽高达惊人的142GB/s。而主流GPU普遍拥有40-60 GB/s显存带宽。存储器的超高带宽让巨大的浮点运算能力得以稳定吞吐,也为数据密集型任务的高效运行提供了保障。
还有,从GTX200和HD 4870系列GPU开始,AMD和NVIDIA两大厂商都开始提供对双精度运算的支持,这正是不少应用领域的科学计算都需要的。NVIDIA公司最新的Fermi架构更是将全局ECC(Error Checking and Correcting)、可读写缓存、分支预测等技术引入到GPU的设计中,明确了将GPU作为通用计算核心的方向。
GPU通用计算被越来越多的采用,除了GPU本身架构的优越性,市场需求也是重要的原因。比如很多企业或科研单位无法布置昂贵的的计算机集群,而大部分普通用户PC上装配的GPU使用率很低,提高GPU利用率的有效途径就是将软件的部分计算任务分配到GPU上,从而实现高性能、低功耗的最终目标。
1.2 什么适合GPU进行计算
尽管GPU计算已经开始崭露头角,但GPU并不能完全替代X86解决方案,很多操作系统、软件以及部分代码现在还不能运行在GPU上,所谓的GPU+CPU异构超级计算机也并不是完全基于GPU进行计算。一般而言适合GPU运算的应用有如下特征[2]:
• 运算密集。
• 高度并行。
• 控制简单。
• 分多个阶段执行。
符合这些条件或者是可以改写成类似特征的应用程序,就能够在GPU上获取较高的性能。
2、GPU通用计算的前世今生
GPU通用计算其实是从GPU渲染管线发展来的。GPU渲染管线的主要任务是完成3D模型到图像的渲染工作。常用的图形学API(DirectD/OpenGL)编程模型中渲染过程被分成几个可以并行处理的阶段,分别由GPU中渲染管线的不同单元进行处理。在GPU渲染管线的不同阶段,需要处理的对象分别是顶点(Vertex)、几何图元(primitive)、片元(fragment)、像素(pixel)。图形渲染过程具有内在的并行性:顶点之间、图元之间、片元之间的数据相关性很弱,对它们的计算可以独立并行进行,这使得通过并行处理提高吞吐量成为可能[3]。这儿不对GPU渲染管线进行详细介绍,而是着重于介绍GPU可编程器件和编程模型的发展历程。
2.1 GPU可编程器件的发展
1999年8月,NVIDIA正式发表了具有跨世纪意义的产品NV10——GeForce 256。GeForce256是业界第一款256bit的GPU,也是全球第一个集成T&L(Transforming&Lighting几何光照转换)、动态光影、三角形设置/剪辑和四像素渲染等3D加速功能的图形引擎。通过T&L技术,显卡不再是简单像素填充机以及多边形生成器,它还将参与图形的几何计算从而将CPU从繁重的3D管道几何运算中解放出来。可以说,T&L技术是显卡进化到GPU的标志。
从某种意义上说,GeForce 256开创了一个全新的3D图形时代,再到后来GeForce 3开始引入可编程特性,能将图形硬件的流水线作为流处理器来解释,基于GPU的通用计算也开始出现。GeForce3被用于实现矩阵乘法运算和求解数学上的扩散方程,这是GPU通用计算的早期应用。
研究人员发现,要实现更加复杂多变的图形效果,不能仅仅依赖三角形生成和硬件T&L实现的固定光影转换,而要加强顶点和像素运算能力。Shader(着色器)就是在这样的背景下提出的。Pixel Shader(顶点着色器)和Vertex Shader(像素着色器)的硬件逻辑支持可编程的像素和顶点,虽然当时可编程性很弱,硬件限制太多,顶点部分出现可编程性,像素部分可编程性有限,但这的确是硬件T&L之后PC图形技术的又一重大飞跃。3D娱乐的视觉体验也因此向接近真实迈进了一大步。可编程管线的引入,也为GPU发展翻开了新的篇章,GPU开始向SIMD(Single Instruction Multiple Data,单指令多数据流)处理器方向发展,凭借强大的并行处理性能,使得GPU开始用有了部分流式处理器特征。
随后到来的DirectX[1] 9.0时代,让Shader单元具备了更强的可编程性。2002年底微软发布的DirectX 9.0中,Pixel Shader单元的渲染精度已达到浮点精度,传统的硬件T&L单元也被取消。全新的Vertex Shader编程将比以前复杂得多,新的Vertex Shader标准增加了流程控制,更多的常量,每个程序的着色指令增加到了1024条。
Shader Model 2.0时代突破了以前限制PC图形图像质量在数学上的精度障碍,它的每条渲染流水线都升级为128位浮点颜色,让游戏程序设计师们更容易更轻松的创造出更漂亮的效果,让程序员编程更容易。而从通用性方面理解,支持浮点运算让GPU已经具备了通用计算的基础,这一点是至关重要的。
图形流水线中可编程单元的行为由Shader单元定义,着色器的性能由DirectX中规定的Shader Model来区分,并可以由高级的Shading语言(例如NV的Cg,OpenGL的GLSL,Microsoft的HLSL)编写。Shader源码被译为字节码,然后在运行时由驱动程序将其转化为基于特定GPU的二进制程序,具备可移植性好等优势。传统的图形渲染流线中有两种不同的可编程着色器,分别是顶点着色单元(Vertex Shader,VS)和像素着色单元(Pixel Shader,PS)。
在Shader Model 4.0之前,VS和PS两种着色器的架构既有相同之处,又有一些不同。两者处理的都是四元组数据(顶点着色器处理用于表示坐标的w、x、y、z,但像素着色器处理用于表示颜色的a、r、g、b),顶点渲染需要比较高的计算精度;而像素渲染则可以使用较低的精度,从而可以增加在单位面积上的计算单元数量。传统的分离架构中,两种着色器的比例往往是固定的。在GPU核心设计完成时,各种着色器的数量便确定下来,比如著名的“黄金比例”——顶点着色器与像素着色器的数量比例为1:3。但不同的游戏对顶点资源和像素资源的计算能力要求是不同的。如果场景中有大量的小三角形,则顶点着色器必须满负荷工作,而像素着色器则会被闲置;如果场景中有少量的大三角形,又会发生相反的情况。因此,固定比例的设计无法完全发挥GPU中所有计算单元的性能。
Shader Model 4.0统一了两种着色器,顶点和像素着色器的规格要求完全相同,都支持32位浮点数。这是GPU发展的一个分水岭。过去只能处理顶点和只能处理像素的专门处理单元被统一之后,更加适应通用计算的需求,应用程序调用着色器运算能力的效率也更高。
DirectX 11提出的Shader Model 5.0版本继续强化了通用计算的地位,微软提出的全新API—Direct Compute将把GPU通用计算推向新的巅峰。同时Shader Model 5.0是完全针对流处理器而设定的,所有类型的着色器,如:像素、顶点、几何、计算、Hull和Domaim(位于Tessellator前后)都将从新指令集中获益[4]。
着色器的可编程性也随着架构的发展不断提高,下表给出每代模型的大概特点[1]。
表1 Shader Model版本
| Shader Model |
GPU代表 |
显卡时代 |
特点 |
|
|
1999年第一代NV Geforce256 |
DirectX 7 1999~2001 |
GPU可以处理顶点的矩阵变换和进行光照计算(T&L),操作固定,功能单一,不具备可编程性 |
| SM 1.0 |
2001年第二代NV Geforce3 |
DirectX 8 |
将图形硬件流水线作为流处理器来解释,顶点部分出现可编程性,像素部分可编程性有限(访问纹理的方式和格式受限,不支持浮点) |
| SM 2.0 |
2003 年 ATI R300 和第三代NV Geforce FX |
DirectX 9.0b |
顶点和像素可编程性更通用化,像素部分支持FP16/24/32浮点,可包含上千条指令,处理纹理更加灵活:可用索引进行查找,也不再限制[0,1]范围,从而可用作任意数组(这一点对通用计算很重要) |
| SM 3.0 |
2004年 第四代NV Geforce 6 和 ATI X1000 |
DirectX 9.0c |
顶点程序可以访问纹理VTF,支持动态分支操作,像素程序开始支持分支操作(包括循环、if/else等),支持函数调用,64位浮点纹理滤波和融合,多个绘制目标 |
| SM 4.0 |
2007年 第五代NV G80和ATI R600 |
DirectX 10 2007~2009 |
统一渲染架构,支持IEEE754浮点标准,引入Geometry Shader(可批量进行几何处理),指令数从1K提升至64K,寄存器从32个增加到4096个,纹理规模从16+4个提升到128个,材质Texture格式变为硬件支持的RGBE格式,最高纹理分辨率从2048*2048提升至8192*8192 |
| SM 5.0 |
2009年 ATI RV870 和2010年NV GF100 |
DirectX 11 2009~ |
明确提出通用计算API Direct Compute概念和Open CL分庭抗衡,以更小的性能衰减支持IEEE754的64位双精度浮点标准,硬件Tessellation单元,更好地利用多线程资源加速多个GPU |
2.2 AMD与NVIDIA最新GPU架构比较
在图形计算领域,NVIDIA和ATI/AMD把持着民用市场的绝大部分份额和大部分专用市场。为了抢占更大的市场,两家公司不断曾经改进自家GPU的架构以实现更逼真的3D效果,现在他们同样代表了GPU通用计算的方向,这儿对两家公司最新的GPU架构进行简单的分析和比较。
AMD的最新GPU架构是RV870,又被命名为Cypress,采用了第二代“TeraScale 2”核心架构。RV870包括流处理器在内的所有核心规格都比上一代架构RV770翻了一倍,也就是“双核心”设计,几乎是并排放置两颗RV770核心,另外在装配引擎内部设计有两个Rasterizer(光栅器)和Hierarchial-Z(多级Z缓冲模块),以满足双倍核心规格的胃口。RV870的晶体管数量的达到了21亿个,流处理器也从RV770时代的800个扩充到了1600个,每个流处理器单元的“1大4小”结构包括一个全功能SP单元和4个能执行乘加运算的SP[5]。
NVIDIA的最新GPU架构是GF100,又被命名为Fermi,这是NVIDIA为了抢占GPU通用计算性能制高点和完整支持DirectX 11而设计的架构。GF100拥有三层分级架构:4个GPC(Graphics Processing Clusters,图形处理图团簇)、16个SM(Streaming Multiprocessors,流阵列多处理器)、512个CUDA核心。每个GPC包括4个SM,每个SM包括32个CUDA核心。一个完整的的GF100还有6个内存控制器(Memory Controller)。GF100核心,除具备前一代架构GT200的L1纹理缓存之外,还拥有真正意义的可读写L1缓存和L2缓存。GF100的晶体管数量达到了30亿个,可以认为GF100是一颗4核心(GPC)处理器,因为GPC几乎是一颗全能的处理器[6]。
两种架构最明显的区别就是流处理器结构。RV870选择延续上一代非统一执行架构GPU产品的SIMD结构,用庞大的规模效应压制对手,偏向于ILP(Instruction-Level Parallelism,指令并行度)方向,而GF100则使用了G80以来创新的MIMD(Multiple Instruction Multiple Data)架构,更偏重于TLP(Thread-Level Parallelism,线程并行度)方向。在单指令多数据流(SIMD)的结构中,单一控制部件向每条流水线分派指令,同样的指令被所有处理部件同时执行。另一种控制结构多指令多数据流(MIMD)中,每条流水线都能够独立于其他流水线执行不同的程序。MIMD能比较有效率地执行分支程序,而SIMD体系结构运行条件语句时会造成很低的资源利用率。TLP要求强大的仲裁机制,丰富的共享cache和寄存器资源以及充足的发射端,这些都是极占晶体管的部件,幸好Fermi架构在增大缓存和分支论断上迈出了坚实的一步。
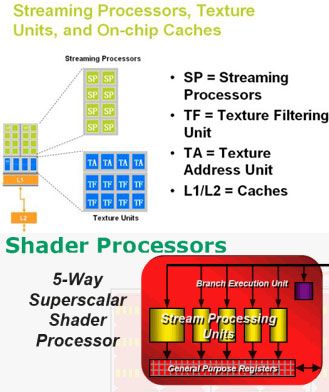
图3 NVIDIA和AMD使用了两种不同的流处理器架构
两种架构的另一个不同在于它们的缓存配置,虽然在在RV870与GF100上,我们都看到了一级缓存与二级缓存的设计。AMD RV870提供了32KB的LDS(Local Data Store),作用类似于NVIDIA传统的shared memory,但是目前的资料来看这个LDS并不具备配置为硬件cache的能力。GF100同时提供了shared memory 和 cache,并允许程序员选择对它们的划分。GF100的每个 SM 都有 64KB 可配置为 48KB shared memory + 16KB L1 cache 或者 16KB shared memory + 48KB L1 cache的高速片上RAM。AMD的RV870提供了 64KB Global Data Shared,本质上是一个可读写的cache,可用于各个SIMD Core之间的数据交换。GF100提供了768KB的一体化L2 cache,这个L2 cache为所有的Load/Store以及纹理请求提供高速缓存,对所有的SM来说L2 cache上的数据都是连贯一致的,从L2 cache读取到的数据就是最新的数据。RV870的L2 cache则不能提供GF100中 L2 Cache共享内核间数据的特性。
还有一个不同是两家厂商选择了不同的最小线程执行粒度。粒度越细,能够调用并行度来进行指令延迟掩盖的机会越大,性能衰减越小。细化粒度偏向TLP方向,对GPU的线程仲裁机制要求很大,最终会导致硬件开销过大。GPU通用计算中最小的执行单位是线程(Thread),多个线程会被打包成一个线程束,NVIDIA称线程束为Warp,AMD称之为Frontwave。Frontwave包含64个线程,NVIDIA的线程管理粒度更小,每个Warp包含32个线程。RV870每凑够64个线程,仲裁器就会动作一次,把一个Frontwave发送给空闲的一个SIMD Core。NVIDIA的GF100比较特殊,还存在Half-Warp,也就是说每16个线程就可以发送给SM一次。Half-Warp由线程中的前16个线程或者后16个线程组成。
还要提到的是GF100架构首次在GPU中引入全局ECC(Error Checking and Correcting内存错误检查和修复)。在使用GPU做大数据量的处理和高性能计算的时候,ECC有大量的需求,尤其在医疗图像处理和大型集群中,ECC是非常有用的特性。
总体来说,两家厂商的差异在于:AMD堆砌了更大规模的运算器单元,NVIDIA则更注重如何利用有限的运算器资源。AMD将更多的晶体管消耗在大量的SIMD Core单元上,NVIDIA则将更多的晶体管消耗在仲裁机制、丰富的共享缓存资源和寄存器资源以及充足的发射端方面。AMD的GPU偏向于ILP结构,NVIDIA偏向于TLP结构。TLP(线程并行度)考验线程能力和并行能力,ILP(指令并行度)则考验指令处理。
2.3 GPU通用计算编程模型
GPU通用计算通常采用CPU+GPU异构模式,由CPU负责执行复杂逻辑处理和事务处理等不适合数据并行的计算,由GPU负责计算密集型的大规模数据并行计算。这种利用GPU强大处理能力和高带宽弥补CPU性能不足的计算方式在发掘计算机潜在性能,在成本和性价比方面有显著的优势。在2007年NVIDIA推出CUDA(Compute Unified Device Architecture,统一计算设备架构)之前,GPU通用计算受硬件可编程性和开发方式的制约,开发难度较大。2007年以后,CUDA不断发展的同时,其他的GPU通用计算标准也被相继提出,如由Apple提出Khronos Group最终发布的OpenCL,AMD推出的Stream SDK,Microsoft则在其最新的Windows7系统中集成了DirectCopmute以支持利用GPU进行通用计算。
2.3.1 传统GPU通用计算开发
最早的GPGPU开发直接使用图形学API编程。这种开发方式要求程序员将数据打包成纹理,将计算任务映射为对纹理的渲染过程,用汇编或者高级着色语言(如GLSL,Cg,HLSL)编写shader程序,然后通过图形学API(Direct3D、OpenGL)执行。2003年斯坦福大学的Ian Buck等人对ANSI C进行扩展,开发了基于NVIDIA Cg的Brook源到源编译器。Brook可以将类似C的brook C语言通过brcc编译器编译为Cg代码,隐藏了利用图形学API实现的细节,大大简化了开发过程。但早期的Brook编译效率很低,并且只能使用像素着色器(Pixel Shader)进行运算。受GPU架构限制,Brook也缺乏有效的数据通信机制。AMD在其GPGPU通用计算产品Stream中采用Brook的改进版本Brook+作为高级开发语言。Brook+的编译器工作方式与Brook不同,提高了效率[7]。
2.3.2 CUDA –C/C++及其SDK
2007年6月,NVIDIA推出了CUDA技术。CUDA是一种将GPU作为数据并行计算设备的软硬件体系,硬件上NVIDIA GeForce 8系列以后的GPU(包括GeForce、ION、Quadro、Tesla系列)已经采用支持CUDA的架构,软件开发包上CUDA也已经发展到CUDA Toolkit 3.2(截止到2010年11月),并且支持Windows、Linux、MacOS三种主流操作系统。CUDA采用比较容易掌握的类C语言进行开发,而且正在开发适用于CUDA架构的用于科学计算的Fortran版本。无论是CUDA C-语言或是OpenCL,指令最终都会被驱动程序转换成PTX(Parallel Thread Execution,并行线程执行,CUDA架构中的指令集,类似于汇编语言)代码,交由显示核心计算[8]。
CUDA编程模型将CPU作为主机(Host),GPU作为协处理器(co-processor)或者设备(Device)。在一个系统中可以存在一个主机和若干个设备。CPU、GPU各自拥有相互独立的存储地址空间:主机端内存和设备端显存。CUDA对内存的操作与一般的C程序基本相同,但是增加了一种新的pinned memory;操作显存则需要调用CUDA API存储器管理函数。一旦确定了程序中的并行部分,就可以考虑把这部分计算工作交给GPU。运行在GPU上的CUDA并行计算函数称为kernel(内核函数)。一个完整的CUDA程序是由一系列的设备端kernel函数并行步骤和主机端的串行处理步骤共同组成的。这些处理步骤会按照程序中相应语句的顺序依次执行,满足顺序一致性。
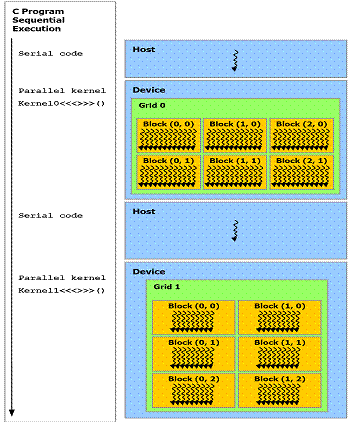
图4 异构编程模型
CUDA SDK提供的API分为CUDA runtime API(运行时API)和CUDA driver API(驱动程序API)。CUDA runtime API在CUDA driver API的基础上进行了封装,隐藏了一些实现细节,编程更加方便。CUDA runtime API函数前都有CUDA前缀。CUDA driver API是一种基于句柄的底层接口,可以加载二进制或汇编形式的kernel模块,指定参数并启动运算。CUDA driver API编程复杂,但有时能通过直接操作硬件的执行实现一些更加复杂的功能或者获得更高的性能。由于它使用的设备端代码是二进制或者汇编代码,因此可以在各种语言中调用。CUDA driver API所有函数的前缀为cu。另外CUDA SDK也提供了CUFFT(CUDA Fast Fourier Transform,基于CUDA的快速傅立叶变换)、CUBLAS(CUDA Basic Linear Algebra Subprograms,基于CUDA的基本矩阵与向量运算库)和CUDPP(CUDA Data Parallel Primitives,基于CUDA的常用并行操作函数)等函数库,提供了简单高效的常用函数供开发者直接使用。
从CUDA Toolkit3.0开始支持NVIDIA最新的Fermi架构,最大程度上利用Fermi架构在通用计算方面的优势。CUDA 3.0也开始支持C++的继承和模板机制提高编程灵活性,同时CUDA C/C++内核现在以标准ELF格式进行编译,开始支持硬件调试,还增加了一个新的Direct3D、OpenGL统一协作API,支持OpenGL纹理和Direct3D 11标准,支持所有的OpenCL特征。
2.3.3 OpenCL
OpenCL (Open Computing Language,开放计算语言) 是一个为异构平台编写程序的框架,此异构平台可由CPU、GPU或其他类型的处理器组成。OpenCL由用于编写kernels (在OpenCL设备上运行的函数)的语言(基于C99)和一组用于定义并控制平台的API组成。OpenCL提供了基于任务分区和数据分区的并行计算机制。
OpenCL最初由Apple公司开发,Apple拥有其商标权,并在与AMD,IBM,Intel和NVIDIA技术团队的合作之下初步完善。随后,Apple将这一草案提交至Khronos Group。2008年6月16日,Khronos的通用计算工作小组成立。5个月后的2008年11月18日,该工作组完成了OpenCL 1.0规范的技术细节。该技术规范在由Khronos成员进行审查之后,于2008年12月8日公开发表。2010年6月14日,OpenCL 1.1 发布[9]。
OpenCL也是基于C的一个程式语言,分为Platform Layer、Runtime、Compiler三个部分:Platform Layer用来管理计算装置,提供启始化装置的界面,并用来建立compute contexts和work-queues。Runtime用来管理资源,并执行程序的kernel。Compiler则是ISO C99的子集合,并加上了OpenCL特殊的语法。在OpenCL的执行模型中,有所谓的Compute Kernel和Compute Program。 Compute Kernel基本上类似于CUDA定义的kernel,是最基本的的计算单元;而Compute Program则是Compute Kernel和内建函数的集合,类似一个动态函数库。很大程度上OpenCL与CUDA Driver API比较相像。
自从2008年12月NVIDIA在SIGGRAPH Asia大会上在笔记本电脑上展示全球首款OpenCL GPU演示以来,AMD、NVIDIA、Apple、RapidMind、Gallium3D、ZiiLABS、IBM、Intel先后发布他们自己的OpenCL规范实现(当一台机器上存在不同厂家的支持OpenCL的设备时,这样也给开发应用程序带来不统一的一些麻烦)。除了AMD和NVIDIA,其他厂商如S3、VIA等也纷纷发布他们支持OpenCL的硬件产品[10]。
2.3.4 DirectCopmute
Directcompute是一种由Microsoft开发和推广的用于GPU通用计算的应用程序接口,集成在Microsoft DirectX内,允许Windows Vista或Windows 7平台上运行的程序利用GPU进行通用计算。虽然DirectCompute最初在DirectX 11 API中得以实现,但支持DX10的GPU可以利用此API的一个子集进行通用计算(DirectX 10内集成Directcompute 4.0,DirectX 10.1内集成Directcompute 4.1),支持DirectX11的GPU则可以使用完整的DirectCompute功能(DirectX 11内集成Directcompute 5.0)。Directcompute和OpenCL都是开放标准,得到NVIDIA CUDA架构和ATI Stream技术的支持。
Windows 7增加了视频即时拖放转换功能,可以将电脑中的视频直接转换到移动媒体播放器上,如果电脑中的GPU支持Directcompute,那么这一转换过程就将由GPU完成。其转换速度将达到CPU的5-6倍。Internet Explorer 9加入了对Directcompute技术的支持,可以调用GPU对网页中的大计算量元素做加速计算,另外Excel2010、Powerpoint2010均提供Directcompute技术支持[11]。
2.3.5 Stream SDK
AMD的流计算模型其实也包含了流处理器架构和相应的软件包。AMD在2007年12月发布运行在Windows XP系统下的Steam SDK v1.0, 此SDK采用了Brook+作为开发语言,Brook+是AMD对斯坦福大学开发的Brook语言(基于ANSI C)的改进版本。Stream SDK为开发者提供对系统和平台开放的标准以方便合作者开发第三方工具。软件包包含了如下组件:支持Brook+的编译器,支持流处理器的设备驱动CAL(Compute Abstraction Layer),程序库ACML(AMD Core Math Library)以及内核函数分析器。
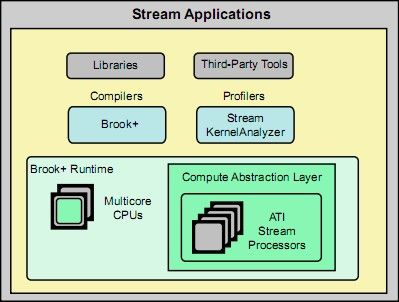
图5 AMD流计算软件系统之间的关系
在Stream编程模型中,在流处理器上执行的程序称为kernel(内核函数),每个运行在SIMD引擎的流处理器上的kernel实例称为thread(线程),线程映射到物理上的运行区域称为执行域。流处理器调度线程阵列到线程处理器上执行,直到所有线程完成后才能运行下一个内核函数。
Brook+是流计算的上层语言,抽象了硬件细节,开发者编写能够运行在流处理器上的内核函数,只需指定输入输出和执行域,无需知道流处理器硬件的实现。Brook+语言中两个关键特性是:Stream和Kernel。Stream是能够并行执行的相同类型元素的集合;Kernel是能够在执行域上并行执行的函数。Brook+软件包包含brcc和brt。brcc是一个源语言对源语言的编译器,能够将Brook+程序翻译成设备相关的IL(Intermediate Language),这些代码被后续链接、执行。brt是一个可以执行内核函数的运行时库,这些库函数有些运行在CPU上,有些运行在流处理器上。运行在流处理器上的核函数库又称为CAL(Compute Abstraction Layer)。CAL是一个用C编写的设备驱动库,允许开发者在保证前端一致性的同时对流处理器核心从底层进行优化。CAL提供了设备管理、资源管理、内核加载和执行、多设备支持、与3D 图形API交互等功能。同时,Stream SDK也提供了常用数学函数库ACML(AMD Core Math Library)供开发者快速获得高性能的计算。ACML包括基本完整的线性代数子例程、FFT运算例程、随机数产生例程和超越函数例程[12]。
面对NVIDIA在GPU通用计算上的不断创新,AMD也不甘示弱,不断改进自己的Stream SDK。截止到2010年11月,AMD发布了Stream SDK v2.2,能够在WindowsXP SP3、Windows 7和部分Linux发行版上运行,开始支持OpenCL 1.1规范和双精度浮点数操作。
3、GPU通用计算的应用领域
从SIGGRAPH 2003大会首先提出GPU通用计算概念,到NVIDIA公司2007年推出CUDA平台,GPU通用计算依靠其强大的计算能力和很高的存储带宽在很多领域取得了成功。越来越多的信号告诉我们,GPU通用计算是一片正在被打开的潜力巨大的市场[13]。
GPGPU项目研究中的先行者是英国剑桥大学的BionicFx课题组。早在2004年9月,剑桥大学的BionicFx课题组便宣布在NVIDIA的GeForce FX 5900产品中实现了专业的实时音频处理功能,并且准备进行商业化的运作,对其产品进行销售,给音乐创作者带来实惠。在随后的一段时间,GPGPU进入了深入研究阶段,但是由于编程语言架构和编程环境都难以通用,该领域的发展能力受到广泛质疑。就在人们认为GPGPU的研究即将偃旗息鼓的时候,ATI在2006年8月惊人地宣布即将联手斯坦福大学在其Folding@Home项目中提供对ATI Radeon X1900的支持。在显卡加入Folding@Home项目后,科研进展速度被成倍提升,人们第一次感受到了GPU的运算威力。
毫无疑问,在GPGPU研究上,ATI跨出了极具意义的一步。同时将GPGPU的应用领域和普及程度推向高潮。随后NVIDIA凭借GeForce 8800GTX这款业界首个DirectX 10 GPU,在GPU通用计算方面实现了大步跨越,特别是CUDA概念的提出(该工具集的核心是一个C语言编译器),在新的通用计算领域后来居上。
下面对GPU通用计算在各个领域的成功应用做一个概述。

图6 不同项目使用CUDA后获得的加速比
3.1 常见软件
最新版本的MATLAB 2010b中Parallel Computing Toolbox与MATLAB Distributed Computing Server的最新版本可利用NVIDIA的CUDA并行计算架构在NVIDIA计算能力1.3以上的GPU上处理数据,执行GPU加速的MATLAB运算,将用户自己的CUDA Kernel函数集成到MATLAB应用程序当中。另外,通过在台式机上使用Parallel Computing Toolbox以及在计算集群上使用MATLAB Distributed Computing Server来运行多个MATLAB worker程序,从而可在多颗NVIDIA GPU上进行计算[14]。AccelerEyes公司开发的Jacket插件也能够使MATLAB利用GPU进行加速计算。Jacket不仅提供了GPU API(应用程序接口),而且还集成了GPU MEX功能。在一定程度说,Jacket是一个完全对用户透明的系统,能够自动的进行内存分配和自动优化。Jacket使用了一个叫“on-the- fly”的编译系统,使MATLAB交互式格式的程序能够在GPU上运行。目前,Jacket只是基于NVIDIA的CUDA技术,但能够运行在各主流操作系统上[15]。
Photoshop虽然已经支持多核心处理器,但在某些时候的速度仍然让人抓狂,比如打开一个超大文件,或者应用一个效果复杂的滤镜。从Photoshop CS4开始,Adobe将GPU通用计算技术引入到自家的产品中来。GPU可提供对图像旋转、缩放和放大平移这些常规浏览功能的加速,还能够实现2D/3D合成,高质量抗锯齿,HDR高动态范围贴图,色彩转换等。而在Photoshop CS5中,更多的算法和滤镜也开始支持GPU加速。另外,Adobe的其他产品如Adobe After Effects CS4、Adobe Premiere Pro CS4也开始使用GPU进行加速。这些软件借助的也是NVIDIA的CUDA技术[16]。
下一代主流操作系统 Windows 7 的核心组成部分包括了支持GPU通用计算的Directcompute API,为视频处理、动态模拟等应用进行加速。Windows 7借助Directcompute增加了对由GPU支持的高清播放的in-the-box支持,可以流畅观看,同时CPU占用率很低。Internet Explorer 9加入了对Directcompute技术的支持,可以调用GPU对网页中的大计算量元素做加速计算;Excel2010、Powerpoint2010也开始提供对Directcompute技术的支持。
3.2 高性能计算
超级计算机一般指在性能上居于世界领先地位的计算机,通常有成千上万个处理器以及专门设计的内存和I/O系统。它们采用的架构与通常的个人计算机有很大区别,使用的技术也随着时代和具体应用不断变动。GPU通用计算提出以后,不断有超级计算机开始安装GPU以提高性能。2010年9月,全球超级计算机领军企业Cray公司正式宣布,该公司将为Cray XE6系列产品开发基于NVIDIA Tesla20系列GPU的刀片服务器。2010年11月揭晓的世界上最快的超级计算机top500列表中,最快的5个系统中有3个使用了NVIDIA的Tesla型号GPU产品,其中中国国防科技大学研发的“天河一号”荣膺榜首,最快运算速度达到2.507 petaflops。2009年10月29日完成的“天河一号”一期系统有3072颗Intel Quad Core Xeon E5540 2.53GHz和3072颗Intel Quad Core Xeon E5450 3.0GHz以及2560块AMD Radeon HD 4870 X2,峰值性能为每秒1206万亿次(top500中排名第5)。2010年10月,升级优化后的“天河一号”,配备了14336颗Xeon X5670处理器(32nm工艺,六核12线程,2.93GHz主频),7168块基于NVIDIA Fermi架构的Tesla M2050计算卡(主频1.15GHz,双精度浮点性能515Gflops、单精度浮点性能1.03Tflops)以及2048颗国防科技大学研制的飞腾处理器(八核64线程,主频1GHz),峰值性能每秒4700万亿次、持续性能每秒2507万亿次(LINPACK实测值)。
计算机集群(简称集群)是一种通过松散集成的计算机软件和硬件连接起来高度紧密地完成计算工作的系统,采用将计算任务分配到集群的不同计算节点而提高计算能力,主要应用在科学计算领域。比较流行的集群采用Linux操作系统和其它一些免费软件来完成并行运算。
2006年10月,全球最大的分布式计算项目——Folding@home中提供对ATI Radeon X1900的支持后,任何一台个人电脑都可以下载客户端参与,科研进展速度被成倍提升。该项目可精确地模拟蛋白质折叠和错误折叠的过程,以便能更好地了解多种疾病的起因和发展。在目前的大约10万台参与该项目的计算机中,仅有的11370颗支持CUDA的GPU提供总计算能力的一半,而运行Windows的CPU共计208268颗,却只能提供该项目总能力的约6%的计算[1]。
早在2007年,AMAX,Supermicro等公司就已经开始探索和研究GPU用于服务器和集群。时至今日,AMAX已成为集CPU+GPU塔式服务器、机柜式服务器、CPU+GPU集群等几十种系列产品的生产和销售为一体的一站式GPU解决方案供应商,可以满足不同领域科研群体的计算需求。AMAX GPU集群相对于传统CPU集群产品,可以以十分之一的价格,二十分之一的功耗,获得20-150倍的计算性能提高和60%的空间节余。AMAX采用NVIDIA支持大规模并行计算的CUDA架构GPU,支持IEEE 754单精度和双精度浮点计算,支持CUDA编程环境、多种编程语言和API,包括C、C + +、OpenCL、DirectCompute或Fortran,支持ECC、NVIDIA Parallel DataCache 技术,以及NVIDIA GigaThread引擎技术,支持异步传输和系统监控功能[17]。目前众多科研机构和公司(如哈佛大学、中国科学院、剑桥大学、英国航空公司等等)都已经架设了基于NVIDIA Tesla(支持CUDA)系列GPU的通用计算机集群。2010年7月,AMD也宣称其合作伙伴,荷兰公司ClusterVision,已经开始利用其新一代的Opteron处理器(12核心CPU)和FireStream图形计算加速卡组建服务器集群。
云计算指服务的交付和使用模式,通过网络以按需、易扩展的方式获得所需的服务。 “云”是一些可以自我维护和管理的虚拟计算资源,通常为一些大型服务器集群,包括计算服务器、存储服务器、宽带资源等等。此前的种种云计算,都是通过网络传输CPU的运算能力,为客户端返回计算结果或者文件;而GPU云计算则偏重于图形渲染运算或大规模并行计算。2009年10月,NVIDIA联合Mental Images公司推出基于GPU的云计算平台RealityServer,利用Tesla RS硬件和RealityServer 3.0软件,为PC、笔记本、上网本、智能手机提供逼真的交互式3D图形渲染服务。2010年11月,Amazon与NVIDIA宣布推出基于亚马逊集群GPU计算实例(Amazon Cluster GPU Instances)的EC2(弹性计算云)服务[18],亚马逊GPU集群实例提供了22GB的存储容量,33.5 个EC2计算单元,并且利用亚马逊 EC2集群网络为高性能计算和数据集中处理提供了很高的吞吐量和低延迟。每一个GPU实例都配有两个NVIDIA Tesla(R) M2050 GPU,提供了甚至超过每秒100万兆次的双精度浮点计算的超高的性能。通过GPU实例的数百个内核并行处理能力,许多工作负载可以被大大加速。
3.3 信号与图像处理
很多信号与图像处理算法的计算密度非常高,随着GPU通用计算的快速发展,越来越多的算法实现了在GPU上运行,获得令人满意的加速。在NVIDIA推出CUDA技术之前,尽管开发不方便,不少研究者利用图形API和各种Shader语言(HLSL、GLSL、Cg等)实现了一些图像分割、CT图像重建、快速傅立叶变换、图像以及音视频编解码等算法。AMD的Brook+尤其是CUDA技术的推出极大地方便了在GPU上开发信号与图像处理并行算法。
AMD的Stream SDK和NVIDIA 的CUDA SDK发布时就包含了各自经优化后的基本线性代数例程(BLAS)和快速傅立叶变换库(FFT)。2008年Georgia Tech的Andrew Kerr等开发了基于CUDA平台的VSIPL(Vector Signal Image Processing Library)[19],支持向量和矩阵运算,快速FIR(Finite Impulse Response,有限冲击响应)滤波,矩阵的QR分解等;2009年6月,NVIDIA又发布了专注于图像和视频处理的库NPP(NVIDIA Performing Primitives),对一些统计函数、JPEG编解码、滤波函数、边缘检测算法进行了封装[20];2010年8月,TunaCode宣布对NPP库进行扩展,推出了CUVI Lib(CUDA for Vision and Imaging Lib),增加了NPP中不包含的一些高级计算机视觉和图像处理算法,如光流法、离散小波变换、Hough变换、颜色空间转换等[21]。另外,2010年9月,Graz大学的研究人员发布了专用于图像边缘分割的GPU4Vision库,用GPU实现图像分割算法的加速[22]。NVIDIA主导的OpenVIDIA项目在2010年6月发布了CUDA VisionWorkbench v 1.3.1.0,里面使用OpenGL,Cg,CUDA-C等语言,而且支持OpenCL和DirectCompute的例子会于近期添加,该项目实现了立体视觉、光流法、特征跟踪的一些算法[23]。
在特征提取领域,瑞典的Marten Bjorkman和美国北卡罗来纳大学的Wu等实现了基于CUDA的SIFT(Lowe's Scale Invariant Feature Transform,尺度不变特征)的提取[24];北卡罗来纳州立大学的Christopher Zach等则在GPU上实现KLT算法用于视频中的特征跟踪。在机器学习领域,斯坦福大学的Rajat Raina等在GPU上实现了大规模深度无监督算法DBNs(Deep Belief Networks)和稀疏编码(Sparse Coding)算法;谷歌上的开源项目multisvm则基于CUDA实现了SVM(Support Vector Machine,支持向量机)的多分类器,实验表明加速效果明显[25]。
另外值得一提的是,医学成像是最早利用 GPU计算加快性能的应用之一,GPU通用计算在这一领域的应用日趋成熟,当前许多医学成像领域的算法已在GPU上实现。Digisens和Acceleware AxRecon已经分别开发出能够利用GPU进行计算的用于X线CT和电子断层摄影术的3D成像软件和在无损图像质量的情况下可实时重建图像的软件。Techniscan的开发人员在其新一代全乳房超声波成像系统中将其专有的逆向散射算法在CUDA平台上实现,获得很高的加速比。东京大学Takeyoshi Dohi教授与他的同事则在其实时医疗成像的裸眼立体成像系统中使用GPU加速体绘制过程和后期文件格式转换。另外,比利时安特卫普大学,通用电气医疗集团,西门子医疗,东芝中风研究中心和纽约州立大学水牛城分校的都针对GPU加速CT重建进行了各自的研究,不仅如此,西门子医疗用GPU实现了加速MRI中的GRAPPA自动校准,完成MR重建,快速MRI网格化,随机扩散张量磁共振图像(DT-MRI)连通绘图等算法。其他的一些研究者则把医学成像中非常重要的二维与三维图像中器官分割(如Level Set算法),不同来源图像的配准,重建体积图像的渲染等也移植到GPU上进行计算。
3.4 数据库与数据挖掘
面对当前海量增加的数据,搜索数据库并找到有用信息已经成为一个巨大的计算难题。学术界以及微软、Oracle、SAP等公司的研究人员正在研究利用GPU的强大计算能力来找到一款可扩展的解决方案。
加利福尼亚大学的Santa Cruz等(现任职于Oracle)比较早地提出把GPU强大的运算能力应用于数据库技术。2009年Oracle的Blas, Tim Kaldewey 在IEEE Spectrum上著文分析为什么图形处理器将彻底改变数据库处理(Why graphics processors will transform database processing),在另一篇文章中他们探索了利用GPU实现并行的搜索算法[27],如并行二分搜索和P-ary搜索;更多的研究者如深圳先进技术研究院和香港中文大学的S. Chen,P. A. Heng,加州伯克利大学的Nadathur Satish[28],微软研究院的Naga K. Govindaraju等[29],瑞典的Erik Sintorn等[30]则研究了在GPU上实现高效率的并行排序算法。香港科技大学的Bingsheng He等研究了使用GPU进行查询协同处理[31]。
在数据挖掘领域,HP实验室的Wu,Zhang,Hsu等研究了使用GPU对商业智能分析进行加速[32]。福尼吉亚理工大学的Sean P. Ponce在其硕士论文中应用算法转换于临时数据挖掘,使其数据并行化,更适合在GPU上实现加速[33]。北卡罗来纳州立大学的Y. Zhang和美国橡树岭国家实验室的X. Cui联合研究了利用CUDA加速文本挖掘,开发了优化的文本搜索算法[34]。马里兰大学的Schatz,Trapnel等开发的Cmatch和MUMmerGPU[35][36],在GPU上实现了高效的的后缀树算法,能够对一系列查询字符串及其子串进行并行搜索,从而进行快速准确的字符串匹配。香港科技大学的Fang和微软亚洲研究院的He等开发了一个小工具GPUMiner,实现了K-均值聚类算法和先验频率模式挖掘算法,用CPU对控制数据I/O和CPU与GPU之间的数据传输,用CPU和GPU联合实现并行算法并提供可视化界面[26]。
另有一些研究者正在研究将Map-Reduce架构扩展到GPU上实现。香港科技大学的Bingsheng He 和Wenbin Fang在单GPU上开发的Mars,目前已经包含字符串匹配,矩阵乘法,倒序索引,字词统计,网页访问排名,网页访问计数,相似性评估和K均值等8项应用,能够在32与64位的linux平台下运行[37]。德克萨斯大学的Alok Mooley等也在分布式的GPU网络上实现了功能类似的系统DisMaRC[38]。加州伯克利大学的Bryan Catanzaro等则在基于CUDA实现的Map-Reduce框架下实现了SVM(Support Vector Machine,支持向量机)的训练和分类。
4、总结和展望
GPU拥有超高的计算密度和显存带宽,CPU+GPU混合架构凭借其高性能、低功耗等优势在许多领域有优异的表现。巨大的运算能力让人们对GPU充满期待,似乎在一夜之间,GPU用于通用计算(General Purpose GPU)及其相关方面的问题成为一个十分热门的话题。视频编解码应用、矩阵运算及仿真、医疗行业应用、生命科学研究等需要大量重复的数据集运算和密集的内存存取,纷纷利用GPU实现了比CPU强悍得多的计算能力[39]。
展望未来GPU发展,以下几个问题是必须解决的。首先是分支预测能力,GPU需要拥有更好的分支能力,才能运行更多复杂程序,更好的利用cache来掩盖分支的延迟;然后是更大的缓存和Shared memory(AMD称之为LDS ,Local Data Share),这种共享寄存器负责共享数据和临时挂起线程,容量越大,线程跳转和分支能力就越强;线程粒度同样重要,粒度越细能够调用并行度来进行指令延迟掩盖的机会越大,性能衰减越小,而细化粒度对GPU的线程仲裁机制要求很大。
GPU发展到今天,已经突破了无数技术屏障,最初因图形处理而诞生的硬件发展成为今天大规模并行计算领域的明星。我们完全可以相信GPU的架构还会不断优化,并被越来越多的大型计算所采用。
参考文献:
[1] 张舒,褚艳丽等著, GPU高性能计算之CUDA, 中国水利水电出版社, 2009
[2] John D. Owens, Mike Houston,et al,GPU Computing, Proceedings of the IEEE, Vol. 96, No. 5, May 2008
[3] GPGPU website, http://gpgpu.org/
[4] 10年GPU通用计算回顾, http://vga.zol.com.cn/172/1721480.html
[5] Programming Guide:ATI Stream Computing,
http://developer.amd.com/gpu/ATIStreamSDK/assets/ATI_Stream_SDK_CAL_Programming_Guide_v2.0%5B1%5D.pdf
[6] Fermi Compute Architecture White Paper
http://www.nvidia.com/content/PDF/fermi_white_papers/NVIDIA_Fermi_Compute_Architecture_Whitepaper.pdf
[7] John D. Owens1, David Luebke, et al, A Survey of General-Purpose Computation on Graphics Hardware, COMPUTER GRAPHICS forum, Volume 26 (2007), number 1 pp. 80–113
[8] NVIDIA CUDA Programming Guide
http://developer.download.nvidia.com/compute/cuda/2_0/docs/NVIDIA_CUDA_Programming_Guide_2.0.pdf
[9] OpenCL Website, http://www.khronos.org/opencl/
[10] 维基百科OpenCL Website, http://en.wikipedia.org/wiki/OpenCL
[11] 百度百科DirectCompute Website, http://baike.baidu.com/view/3245449.html?fromTaglist
[12] Technical Overview:ATI Stream Computing,
http://developer.amd.com/gpu_assets/Stream_Computing_Overview.pdf
[13] 维基百科GPGPU Website, http://en.wikipedia.org/wiki/GPGPU
[14] Matlab Parallel Computing, http://www.mathworks.com/products/parallel-computing/
[15] Jacket Website, http://www.accelereyes.com/
[16] http://www.nvidia.com/object/builtforadobepros.html
[17] AMAX GPU集群开创高性能计算新纪元, http://server.zol.com.cn/189/1891144.html
[18] Announcing Cluster GPU Instances for Amazon EC2, http://aws.amazon.com/ec2/
[19] GPU VSIPL: High-Performance VSIPL Implementation for GPUs
http://gpu-vsipl.gtri.gatech.edu/
[20] NVIDIA Performance Primitives (NPP) Library
http://developer.nvidia.com/object/npp_home.html
[21] CUDA Vision and Imaging Library, http://www.cuvilib.com/
[22] GPU4Vision, http://gpu4vision.icg.tugraz.at/
[23] OpenVIDIA: Parallel GPU Computer Vision
http://openvidia.sourceforge.net/index.php/OpenVIDIA
[24] SiftGPU: A GPU Implementation of Scale Invariant Feature Transform (SIFT)
http://www.cs.unc.edu/~ccwu/siftgpu/
[25] Multisvm Website, http://code.google.com/p/multisvm/
[26] GPUMiner Website, http://code.google.com/p/gpuminer/
[27] Parallel Search On Video Cards
http://www.usenix.org/event/hotpar09/tech/full_papers/kaldeway/kaldeway.pdf
[28] Nadathur Satis, et al, Designing Efficient Sorting Algorithms for Manycore GPUs, 23rd IEEE International Parallel and Distributed Processing Symposium, May 2009
http://mgarland.org/files/papers/gpusort-ipdps09.pdf
[29] Naga K. Govindaraju, et al, GPUTeraSort:High Performance Graphics Coprocessor Sorting for Large Database Management, Microsoft Technical Report 2005
http://research.microsoft.com/pubs/64572/tr-2005-183.pdf
[30] Erik Sintorn, et al, Fast Parallel GPU-Sorting Using a Hybrid Algorithm,
http://www.cse.chalmers.se/~uffe/hybridsort.pdf
[31] GPUQP: Query Co-Processing Using Graphics Processors, http://www.cse.ust.hk/gpuqp/
[32] Ren Wu, et al, GPU-Accelerated Large Scale Analytics, HP Laboratories
http://www.hpl.hp.com/techreports/2009/HPL-2009-38.pdf
[33] Sean P. Ponce, Towards Algorithm Transformation for Temporal Data Mining on GPU, Master Thesis of Sean P. Ponce, Virginia Polytechnic Institute and State University
http://scholar.lib.vt.edu/theses/available/etd-08062009-133358/unrestricted/ponce-thesis.pdf
[34] Yongpeng Zhang, Frank Mueller, et al, GPU-Accelerated Text Mining, EPHAM’09
http://moss.csc.ncsu.edu/~mueller/ftp/pub/mueller/papers/epham09.pdf
[35] Cmatch: Fast Exact String Matching on the GPU,http://www.cbcb.umd.edu/software/cmatch/
[36] MUMmerGPU: High-throughput sequence alignment using Graphics Processing Units
http://sourceforge.net/apps/mediawiki/mummergpu/index.php?title=MUMmerGPU
[37] Mars: A MapReduce Framework on Graphics Processors
http://www.cse.ust.hk/gpuqp/Mars.html
[38] DisMaRC: A Distributed Map Reduce framework on CUDA
http://www.cs.utexas.edu/~karthikm/dismarc.pdf
[39] NVIDIA行业软件解决方案,http://www.nvidia.cn/object/vertical_solutions_cn.html