一览群智率先开启多模态预训练“大模型”的落地应用,深度探索行业价值
![]()
3月20日,北京智源人工智能研究院举办“智源悟道1.0 AI研究成果发布会暨大规模预训练模型交流论坛”。北京市科委、中关村管委会副主任许心超出席会议并致辞。北京大学、清华大学、中国人民大学、中国科学院等高校院所的专家学者,美团、快手、搜狗、360、一览群智、循环智能等AI企业,以及新华社等应用机构代表参会。
![]()
随着OpenAI超大规模语言模型GPT-3的发布,预训练语言模型在自然语言理解能力上再次被推至新的高峰。发布会上,中国人民大学高瓴人工智能学院执行院长、智源首席科学家、一览群智首席科学家文继荣教授作了题为《用多模态预训练模型连接图与文》的主题报告,发布了第一代“悟道·文澜”,旨在发掘预训练模型在中文通用多模态数据上的理解能力,并展示了“多模态预训练模型-文澜”方面的技术突破。
“悟道·文澜”是“超大规模多模态预训练模型”,目标是突破基于图、文和视频相结合的多模态数据的预训练理论难题,并最终生成产业级中文图文预训练模型和应用,并在多个评测应用上超过国际最高性能。
据悉,“悟道·文澜”模型参数量达10亿,基于从公开来源收集到的5000万个图文对上进行训练,是首个公开的中文通用图文多模态预训练模型。目前,该模型性能已经到达国际领先水平,在中文公开多模态测试集AIC-ICC的图像生成描述任务中,得分比冠军队高出5%;在图文互检任务中,得分比目前流行的UNITER模型高出20%。
为了展示如何使用“悟道·文澜”模型,智源研究院联合中国人民大学高瓴人工智能学院和一览群智,推出“AI心情电台”小程序,利用图片和歌词的相关性,为用户上传的照片搭配最合拍的音乐。
![]()
布灵-为图片赋予音乐的灵魂
用户随便上传一张图片后,布灵为用户配上一首符合意境的歌。《AI心情电台》是使用BriVL提取图像和文本特征,接着进行图文检索,将图片和歌词特征进行匹配,并将歌词准确定位到最符合图片特征的歌词位置。

“悟道·文澜”为图文音视频等多模态数据在语义层面构建了通路,使得可以通过操作语义向量的方式完成跨模态、混合模态的信息检索、推荐、生成等任务。
作为认知智能行业领导者,一览群智基于Transformer双塔结构的多模态预训练模型,推出智空-多模态文本转化与生成平台,该产品在基于图像的文本生成与打标、场景语义解析、异常场景情况预警、多模态语义检索以及智能信息检索、问答系统等多场景内率先开启探索产业价值。
![]()
智空-灵活、智能的多模态文本转化与生成平台
智空平台基于Transformer双塔结构的多模态预训练模型,可以生成多模态语义向量,支持TB 级向量的增删改操作和近实时查询,具有高度灵活、稳定可靠以及高速查询等特点,涵盖对图片、文字、视频进行分类、打标签、以文搜图、以图搜文、以图搜视频等功能。展示了多模态预训练“大模型”的落地应用,从而更有效率的服务于客户,推动技术边界,与客户一起创作更大的产业价值。
01
【案例一】基于图像的文本生成及打标签
智空平台具备强大的视觉-语言检索能力和一定的常识理解能力。可以实现用文本检索图像、以及用图像生成文本的功能。同时,它还可以实现基于图像的文本生成、为图像打标签等功能。
尽管现有的一些文本生成模型可以生成相关的图像描述,但却存在着与用户交互性差、多样性低等问题。一方面,大多数图像描述模型仅被动地生成句子,并不考虑用户感兴趣的内容或者期望描述的详细程度。另一方面,这种被动生成模式倾向于使用常见的高频表达生成较为“安全”的句子,较为简单空洞,且缺乏关键性的、用户所需的细节信息。
针对此痛点,智空基于双塔结构的多模态预训练模型可以达到模态级别的匹配、可处理文本弱相关、检索速度快、实际场景易于部署等优势。

工作中,对于素材管理而言,一个常见的解决方案是去给素材库中的每张图片打上各种标签,然后便可以方便地去归类、查找和检索了。当所有的素材都加上了合适的标签后,这确实会是一个相当高效的管理和查找方式。只不过,这一切的前提基础都是:你需要手动将图库内所有的内容都加上合适的标签。这在少量内容时并不是什么问题,但是当你的图库达到上千甚至更多的数量级时,手动添加标签显然变成了一个无法完成的任务。因此,当前的图像理解需要大量的人工标注,且不利于标签数量的快速增加。
通过多模态预训练模型进行内容理解,可以为图像提供更准确更精细的标签,有利于物料分发和个性化推荐。同时,借助于多模态信息处理,小规模样本数据和非监督的内容理解将会有一定的突破。
多模态包含比单模态更丰富的信息,并且存在一定的信息冗余,通过多模态之间信息相互增强和补充,在小规模样本数据和非监督内容理解方面比单模态更有优势。
02
【案例二】智慧城市
在智慧城市建设中,智空平台充分运用“视频+AI+数据”技术,让“城市大脑”的“眼睛”更加智能和明亮。汇聚处理海量多模态数据,及时发现异常行为情况,有效进行预警接收和处理。
随着天气转暖,越来越多市民开始扫码骑行,共享单车再度变得“活跃”。因此,由“潮汐”现象引发的共享单车淤积新痛点也开始出现,期待各方合力破解。
在一些主要路段,每天早晚上下班高峰时段,居民骑车往来地铁站、公交站点等,导致共享单车聚集量迅速达到峰值,而共享单车的调度却赶不上"潮汐"起落的速度,局部车辆供需失衡现象严重,同时也带来了在某个时间段停放杂乱无序的问题。另外,在一些主要路段的轨道交通站点出入口,这样的情况也同样存在。尤其是早晚上下班的高峰时期,很多单车就停在地铁出口,越临近上班点越混乱,有的人发现快迟到了,就直接把单车一扔,匆匆走人。同样的情况还会出现在小区门口,主要居住社区会在下班高峰期呈现单车堆叠、杂乱摆放的现象,阻碍各小区附近的正常交通。
面对这种现象,传统CV解决方案一般都是定制标注训练相关业务逻辑模型,初始建设周期长,并需要持续标注以改进效果,而且复用性低,换个场景就需要重新构建整个过程,这些都为实现业务效果带来了时间和成本压力,再考虑到前期硬件设备和网络的基础设施依赖,使得很多场景的解决方案只存在于PPT里,难以实际落地。
智空平台利用当前视频实时监控采集回来的数据,通过图文检索+图图检索,对抓拍的区域进行智能分析,合理应用资源,实现对共享单车场景监测,对可能发生的潜在“危险”提供数据支撑,配合有关部门进行综合治理。
整个检索过程分为以下几个步骤:
1.由街道、路口以及小区卡口摄像头抓拍实时视频流,数据接入智空平台,形成自己的图数据库。
2.根据需求检索信息,例如“共享单车”,实时检索当前有关共享单车的主要场景。

3.对共享单车异常摆放或存在阻碍交通的图片进行偏好标注,提取所有场景异常图片。

4.判断异常问题是否需要上报处理。

在整个过程中,将降低人工定期定点巡查的工作量;同时,更加智能的计算出共享单车在某一特定位置的态势发展,有利于综合部门制定应对政策。
03
【案例三】个人相册智能搜索
随着智能手机像素的提升、存储的增大,用户在相册里面的照片越来越多,不再是几十张,动不动就有几百张上千张。形式也不仅仅是jpg,还有大量的短视频、gif图等。通常情况下,大部分照片拍过之后就再也没看过,但是当需要查找的时候就只能凭借临近日期不停翻找。因此,如何将海量照片进行智能管理,分类有序、快速查找,是很多用户的需求。
常见的数字相册,只能通过照片的meta信息如时间、地点进行检索,进一步也只能实现基于人脸识别的人像检索、基于物体识别的物品检索、基于OCR的图像文字检索,对于生活中可能出现的更多类型的内容要素很难覆盖全面,更无法通过理解语义的方式实现更个性化的语义检索。
面对这些痛点,智空平台充分利用用户的自有数据,构建语义向量数据库,并结合实时多模态数据向量化能力,快速检索用户所需要的的图片,帮助用户随时随地快速的找回曾经有价值的记忆,大大提升用户体验。
张先生(化名)作为智能手机的使用者,习惯用手机相册记录工作和生活中的点滴画面。正因如此,他常常因为找不到最需要的“那一张”而发愁。在征询其本人同意的前提下,一览群智尝试用智空的多模态语义检索功能对其个人相册进行智能查找,效果显而易见。
1)以场景作为语义描述输入检索,输入“瀑布”,获得正向结果反馈。

2)以行为动作作为语义描述输入检索,输入“滑雪”,获得正向结果反馈。
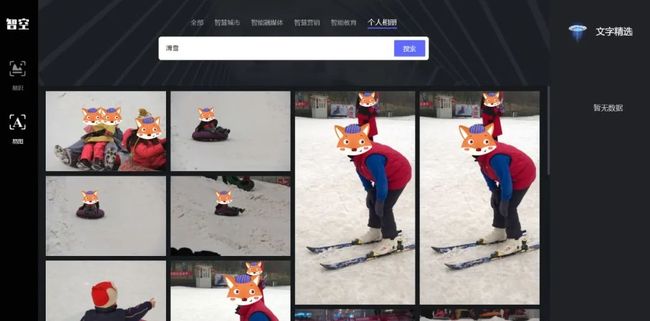
3)将地点作为语义描述输入检索,输入“西湖”,获得正向结果反馈。

4)为输入的语义向量做“加减法”。以上述西湖场景为例,在原有搜索中输入“+自行车”,获得正向结果反馈。

![]()
![]()
![]()
智空利用多模态预训练模型、实时向量数据库、跨模态语义操作等领先技术,不仅跨越了传统知识图谱构建、分类标签标注、人工规则检索的复杂系统构建过程,而且极大的简化了检索过程,标志着多模态信息检索迈入了真正的语义检索时代,未来将会在更多的应用场景发挥巨大潜力。
