机器学习-决策树(预剪枝和后剪枝)
剪枝的意义
剪枝是决策树解决过拟合问题的方法。在决策树学习过程中,为了尽可能正确分类训练样本,结点划分过程将不断重复,有时会造成决策树分支过多,于是可能将训练样本学得太好,以至于把训练集自身的一些特点当作所有数据共有的一般特点而导致测试集预测效果不好,出现了过拟合现象。因此,可以通过剪枝来去掉一些分支来降低过拟合的风险。
决策树剪枝的基本策略
预剪枝
预剪枝是指在决策树生成的过程中,对每个结点在划分前先进行估计,如果当前结点的划分不能带来决策树泛化性能的提升,那么停止划分并且将当前结点标记为叶子结点。
后剪枝
后剪枝则是从训练集生成一棵完整的决策树,然后自底向上地对非叶子节点进行考察,如果将该结点对应地子树替代为叶子结点能带来决策树泛化性能地提升,那么就将该子树替换为叶子结点。
剪枝实现
导入库
import math
import numpy as np 处理数据
def dealData(filename):
fr = open(filename,'r',encoding='utf-8-sig')
arrayOLines = fr.readlines()
numberOfLines = len(arrayOLines)
data = np.zeros((numberOfLines, 4))
Label = []
name=['high','weight','age','subdcript','sex']
index = 0
for line in arrayOLines:
line = line.strip()
listFromLine = line.split('\t')
data[index,:] = listFromLine[0:4]
Label.append(listFromLine[-1]) #最后一列是标签集合
index += 1
#对数据特征进行分类
for j in range(4):
for i in range(numberOfLines):
#身高
if(j==0):
if(data[i][j])>1.69:data[i][j]=3
elif(data[i][j]==1.69):data[i][j]=2
else:data[i][j]=1
#体重
if(j==1):
if(data[i][j])>64:data[i][j]=3
elif(data[i][j]==64):data[i][j]=2
else:data[i][j]=1
#年龄
if(j==2):
if(data[i][j])>26:data[i][j]=3
elif(data[i][j]==26):data[i][j]=2
else:data[i][j]=1
#脚码
if(j==3):
if(data[i][j])>32:data[i][j]=3
elif(data[i][j]==32):data[i][j]=2
else:data[i][j]=1
return data,Label,name创建基础函数(如计算熵、计算条件熵、信息增益、信息增益率等)
# 定义一个常用函数 用来求numpy array中数值等于某值的元素数量
equalNums = lambda x,y: 0 if x is None else x[x==y].size
# 定义计算信息熵的函数
def singleEntropy(x):
"""计算一个输入序列的信息熵"""
# 转换为 numpy 矩阵
x = np.asarray(x)
# 取所有不同值
xValues = set(x)
# 计算熵值
entropy = 0
for xValue in xValues:
p = equalNums(x, xValue) / x.size
entropy -= p * math.log(p, 2)
return entropy
# 定义计算条件信息熵的函数
def conditionnalEntropy(feature, y):
"""计算 某特征feature 条件下y的信息熵"""
# 转换为numpy
feature = np.asarray(feature)
y = np.asarray(y)
# 取特征的不同值
featureValues = set(feature)
# 计算熵值
entropy = 0
for feat in featureValues:
# 解释:feature == feat 是得到取feature中所有元素值等于feat的元素的索引(类似这样理解)
# y[feature == feat] 是取y中 feature元素值等于feat的元素索引的 y的元素的子集
p = equalNums(feature, feat) / feature.size
entropy += p * singleEntropy(y[feature == feat])
return entropy
# 定义信息增益
def infoGain(feature, y):
return singleEntropy(y) - conditionnalEntropy(feature, y)
# 定义信息增益率
def infoGainRatio(feature, y):
return 0 if singleEntropy(feature) == 0 else infoGain(feature, y) / singleEntropy(feature)
创建树生成相关函数 (特征选取、数据分割、多数投票、树生成、使用树分类、树信息统计)
# 特征选取
def bestFeature(data, labels, method = 'id3'):
assert method in ['id3', 'c45'], "method 须为id3或c45"
data = np.asarray(data)
labels = np.asarray(labels)
# 根据输入的method选取 评估特征的方法:id3 -> 信息增益; c45 -> 信息增益率
def calcEnt(feature, labels):
if method == 'id3':
return infoGain(feature, labels)
elif method == 'c45' :
return infoGainRatio(feature, labels)
# 特征数量 即 data 的列数量
featureNum = data.shape[1]
# 计算最佳特征
bestEnt = 0
bestFeat = -1
for feature in range(featureNum):
ent = calcEnt(data[:, feature], labels)
if ent >= bestEnt:
bestEnt = ent
bestFeat = feature
# print("feature " + str(feature + 1) + " ent: " + str(ent)+ "\t bestEnt: " + str(bestEnt))
return bestFeat, bestEnt
# 根据特征及特征值分割原数据集 删除data中的feature列,并根据feature列中的值分割 data和label
def splitFeatureData(data, labels, feature):
"""feature 为特征列的索引"""
# 取特征列
features = np.asarray(data)[:,feature]
# 数据集中删除特征列
data = np.delete(np.asarray(data), feature, axis = 1)
# 标签
labels = np.asarray(labels)
uniqFeatures = set(features)
dataSet = {}
labelSet = {}
for feat in uniqFeatures:
dataSet[feat] = data[features == feat]
labelSet[feat] = labels[features == feat]
return dataSet, labelSet
# 多数投票
def voteLabel(labels):
uniqLabels = list(set(labels))
labels = np.asarray(labels)
finalLabel = 0
labelNum = []
for label in uniqLabels:
# 统计每个标签值得数量
labelNum.append(equalNums(labels, label))
# 返回数量最大的标签
return uniqLabels[labelNum.index(max(labelNum))]
# 创建决策树
def createTree(data, labels, names, method = 'id3'):
data = np.asarray(data)
labels = np.asarray(labels)
names = np.asarray(names)
# 如果结果为单一结果
if len(set(labels)) == 1:
return labels[0]
# 如果没有待分类特征
elif data.size == 0:
return voteLabel(labels)
# 其他情况则选取特征
bestFeat, bestEnt = bestFeature(data, labels, method = method)
# 取特征名称
bestFeatName = names[bestFeat]
# 从特征名称列表删除已取得特征名称
names = np.delete(names, [bestFeat])
# 根据选取的特征名称创建树节点
decisionTree = {bestFeatName: {}}
# 根据最优特征进行分割
dataSet, labelSet = splitFeatureData(data, labels, bestFeat)
# 对最优特征的每个特征值所分的数据子集进行计算
for featValue in dataSet.keys():
decisionTree[bestFeatName][featValue] = createTree(dataSet.get(featValue), labelSet.get(featValue), names, method)
return decisionTree
# 树信息统计 叶子节点数量 和 树深度
def getTreeSize(decisionTree):
nodeName = list(decisionTree.keys())[0]
nodeValue = decisionTree[nodeName]
leafNum = 0
treeDepth = 0
leafDepth = 0
for val in nodeValue.keys():
if type(nodeValue[val]) == dict:
leafNum += getTreeSize(nodeValue[val])[0]
leafDepth = 1 + getTreeSize(nodeValue[val])[1]
else :
leafNum += 1
leafDepth = 1
treeDepth = max(treeDepth, leafDepth)
return leafNum, treeDepth
# 使用模型对其他数据分类
def dtClassify(decisionTree, rowData, names):
names = list(names)
# 获取特征
feature = list(decisionTree.keys())[0]
# 决策树对于该特征的值的判断字段
featDict = decisionTree[feature]
# 获取特征的列
feat = names.index(feature)
# 获取数据该特征的值
featVal = rowData[feat]
# 根据特征值查找结果,如果结果是字典说明是子树,调用本函数递归
if featVal in featDict.keys():
if type(featDict[featVal]) == dict:
classLabel = dtClassify(featDict[featVal], rowData, names)
else:
classLabel = featDict[featVal]
return classLabel树的可视化
import matplotlib.pyplot as plt
decisionNodeStyle = dict(boxstyle = "sawtooth", fc = "0.8")
leafNodeStyle = {"boxstyle": "round4", "fc": "0.8"}
arrowArgs = {"arrowstyle": "<-"}
# 画节点
def plotNode(nodeText, centerPt, parentPt, nodeStyle):
createPlot.ax1.annotate(nodeText, xy = parentPt, xycoords = "axes fraction", xytext = centerPt
, textcoords = "axes fraction", va = "center", ha="center", bbox = nodeStyle, arrowprops = arrowArgs)
# 添加箭头上的标注文字
def plotMidText(centerPt, parentPt, lineText):
xMid = (centerPt[0] + parentPt[0]) / 2.0
yMid = (centerPt[1] + parentPt[1]) / 2.0
createPlot.ax1.text(xMid, yMid, lineText)
# 画树
def plotTree(decisionTree, parentPt, parentValue):
# 计算宽与高
leafNum, treeDepth = getTreeSize(decisionTree)
# 在 1 * 1 的范围内画图,因此分母为 1
# 每个叶节点之间的偏移量
plotTree.xOff = plotTree.figSize / (plotTree.totalLeaf - 1)
# 每一层的高度偏移量
plotTree.yOff = plotTree.figSize / plotTree.totalDepth
# 节点名称
nodeName = list(decisionTree.keys())[0]
# 根节点的起止点相同,可避免画线;如果是中间节点,则从当前叶节点的位置开始,
# 然后加上本次子树的宽度的一半,则为决策节点的横向位置
centerPt = (plotTree.x + (leafNum - 1) * plotTree.xOff / 2.0, plotTree.y)
# 画出该决策节点
plotNode(nodeName, centerPt, parentPt, decisionNodeStyle)
# 标记本节点对应父节点的属性值
plotMidText(centerPt, parentPt, parentValue)
# 取本节点的属性值
treeValue = decisionTree[nodeName]
# 下一层各节点的高度
plotTree.y = plotTree.y - plotTree.yOff
# 绘制下一层
for val in treeValue.keys():
# 如果属性值对应的是字典,说明是子树,进行递归调用; 否则则为叶子节点
if type(treeValue[val]) == dict:
plotTree(treeValue[val], centerPt, str(val))
else:
plotNode(treeValue[val], (plotTree.x, plotTree.y), centerPt, leafNodeStyle)
plotMidText((plotTree.x, plotTree.y), centerPt, str(val))
# 移到下一个叶子节点
plotTree.x = plotTree.x + plotTree.xOff
# 递归完成后返回上一层
plotTree.y = plotTree.y + plotTree.yOff
# 画出决策树
def createPlot(decisionTree):
fig = plt.figure(1, facecolor = "white")
fig.clf()
axprops = {"xticks": [], "yticks": []}
createPlot.ax1 = plt.subplot(111, frameon = False, **axprops)
# 定义画图的图形尺寸
plotTree.figSize = 1.5
# 初始化树的总大小
plotTree.totalLeaf, plotTree.totalDepth = getTreeSize(decisionTree)
# 叶子节点的初始位置x 和 根节点的初始层高度y
plotTree.x = 0
plotTree.y = plotTree.figSize
plotTree(decisionTree, (plotTree.figSize / 2.0, plotTree.y), "")
plt.show()未剪枝树
Data, Label, Name = dealData('D:/learn/three first/machine learning/Data1.txt')
Data=np.array(Data)
Label=np.array(Label)
Name=np.array(Name)
Tree = createTree(Data, Label, Name, method = 'id3')
print(Tree)
createPlot(Tree)
预剪枝
def createTreePrePruning(dataTrain, labelTrain, dataTest, labelTest, names, method = 'id3'):
"""
预剪枝 需要使用测试数据对每次的划分进行评估
策略说明:原本如果某节点划分前后的测试结果没有提升,根据奥卡姆剃刀原则将不进行划分(即执行剪枝),但考虑到这种策略容易造成欠拟合,
且不能排除后续划分有进一步提升的可能,因此,没有提升仍保留划分,即不剪枝
另外:周志华的书上评估的是某一个节点划分前后对该层所有数据综合评估,如评估对脐部 凹陷下色泽是否划分,
书上取的色泽划分前的精度是71.4%(5/7),划分后的精度是57.1%(4/7),都是脐部下三个特征(凹陷,稍凹,平坦)所有的数据的精度,计算也不易
而我觉得实际计算时,只对当前节点下的数据划分前后进行评估即可,如脐部凹陷时有三个测试样本,
三个样本色泽划分前的精度是2/3=66.7%,色泽划分后的精度是1/3=33.3%,因此判断不划分
"""
trainData = np.asarray(dataTrain)
labelTrain = np.asarray(labelTrain)
testData = np.asarray(dataTest)
labelTest = np.asarray(labelTest)
names = np.asarray(names)
# 如果结果为单一结果
if len(set(labelTrain)) == 1:
return labelTrain[0]
# 如果没有待分类特征
elif trainData.size == 0:
return voteLabel(labelTrain)
# 其他情况则选取特征
bestFeat, bestEnt = bestFeature(dataTrain, labelTrain, method = method)
# 取特征名称
bestFeatName = names[bestFeat]
# 从特征名称列表删除已取得特征名称
names = np.delete(names, [bestFeat])
# 根据最优特征进行分割
dataTrainSet, labelTrainSet = splitFeatureData(dataTrain, labelTrain, bestFeat)
# 预剪枝评估
# 划分前的分类标签
labelTrainLabelPre = voteLabel(labelTrain)
labelTrainRatioPre = equalNums(labelTrain, labelTrainLabelPre) / labelTrain.size
# 划分后的精度计算
if dataTest is not None:
dataTestSet, labelTestSet = splitFeatureData(dataTest, labelTest, bestFeat)
# 划分前的测试标签正确比例
labelTestRatioPre = equalNums(labelTest, labelTrainLabelPre) / labelTest.size
# 划分后 每个特征值的分类标签正确的数量
labelTrainEqNumPost = 0
for val in labelTrainSet.keys():
labelTrainEqNumPost += equalNums(labelTestSet.get(val), voteLabel(labelTrainSet.get(val))) + 0.0
# 划分后 正确的比例
labelTestRatioPost = labelTrainEqNumPost / labelTest.size
# 如果没有评估数据 但划分前的精度等于最小值0.5 则继续划分
if dataTest is None and labelTrainRatioPre == 0.5:
decisionTree = {bestFeatName: {}}
for featValue in dataTrainSet.keys():
decisionTree[bestFeatName][featValue] = createTreePrePruning(dataTrainSet.get(featValue), labelTrainSet.get(featValue)
, None, None, names, method)
elif dataTest is None:
return labelTrainLabelPre
# 如果划分后的精度相比划分前的精度下降, 则直接作为叶子节点返回
elif labelTestRatioPost < labelTestRatioPre:
return labelTrainLabelPre
else :
# 根据选取的特征名称创建树节点
decisionTree = {bestFeatName: {}}
# 对最优特征的每个特征值所分的数据子集进行计算
for featValue in dataTrainSet.keys():
decisionTree[bestFeatName][featValue] = createTreePrePruning(dataTrainSet.get(featValue), labelTrainSet.get(featValue)
, dataTestSet.get(featValue), labelTestSet.get(featValue)
, names, method)
return decisionTree
DataTrain, LabelTrain, DataTest, LabelTest = splitXgData20(Data, Label)
# 生成预剪枝的树
TreePrePruning = createTreePrePruning(DataTrain, LabelTrain, DataTest, LabelTest, Name, method = 'id3')
# 画剪枝后的树
print("剪枝后的树")
createPlot(TreePrePruning)
后剪枝
def createTreeWithLabel(data, labels, names, method = 'id3'):
data = np.asarray(data)
labels = np.asarray(labels)
names = np.asarray(names)
# 如果不划分的标签为
votedLabel = voteLabel(labels)
# 如果结果为单一结果
if len(set(labels)) == 1:
return votedLabel
# 如果没有待分类特征
elif data.size == 0:
return votedLabel
# 其他情况则选取特征
bestFeat, bestEnt = bestFeature(data, labels, method = method)
# 取特征名称
bestFeatName = names[bestFeat]
# 从特征名称列表删除已取得特征名称
names = np.delete(names, [bestFeat])
# 根据选取的特征名称创建树节点 划分前的标签votedPreDivisionLabel=_vpdl
decisionTree = {bestFeatName: {"_vpdl": votedLabel}}
# 根据最优特征进行分割
dataSet, labelSet = splitFeatureData(data, labels, bestFeat)
# 对最优特征的每个特征值所分的数据子集进行计算
for featValue in dataSet.keys():
decisionTree[bestFeatName][featValue] = createTreeWithLabel(dataSet.get(featValue), labelSet.get(featValue), names, method)
return decisionTree
# 将带预划分标签的tree转化为常规的tree
# 函数中进行的copy操作,原因见有道笔记 【YL20190621】关于Python中字典存储修改的思考
def convertTree(labeledTree):
labeledTreeNew = labeledTree.copy()
nodeName = list(labeledTree.keys())[0]
labeledTreeNew[nodeName] = labeledTree[nodeName].copy()
for val in list(labeledTree[nodeName].keys()):
if val == "_vpdl":
labeledTreeNew[nodeName].pop(val)
elif type(labeledTree[nodeName][val]) == dict:
labeledTreeNew[nodeName][val] = convertTree(labeledTree[nodeName][val])
return labeledTreeNew
# 后剪枝 训练完成后决策节点进行替换评估 这里可以直接对xgTreeTrain进行操作
def treePostPruning(labeledTree, dataTest, labelTest, names):
newTree = labeledTree.copy()
dataTest = np.asarray(dataTest)
labelTest = np.asarray(labelTest)
names = np.asarray(names)
# 取决策节点的名称 即特征的名称
featName = list(labeledTree.keys())[0]
# print("\n当前节点:" + featName)
# 取特征的列
featCol = np.argwhere(names==featName)[0][0]
names = np.delete(names, [featCol])
# print("当前节点划分的数据维度:" + str(names))
# print("当前节点划分的数据:" )
# print(dataTest)
# print(labelTest)
# 该特征下所有值的字典
newTree[featName] = labeledTree[featName].copy()
featValueDict = newTree[featName]
featPreLabel = featValueDict.pop("_vpdl")
# print("当前节点预划分标签:" + featPreLabel)
# 是否为子树的标记
subTreeFlag = 0
# 分割测试数据 如果有数据 则进行测试或递归调用 np的array我不知道怎么判断是否None, 用is None是错的
dataFlag = 1 if sum(dataTest.shape) > 0 else 0
if dataFlag == 1:
# print("当前节点有划分数据!")
dataTestSet, labelTestSet = splitFeatureData(dataTest, labelTest, featCol)
for featValue in featValueDict.keys():
# print("当前节点属性 {0} 的子节点:{1}".format(featValue ,str(featValueDict[featValue])))
if dataFlag == 1 and type(featValueDict[featValue]) == dict:
subTreeFlag = 1
# 如果是子树则递归
newTree[featName][featValue] = treePostPruning(featValueDict[featValue], dataTestSet.get(featValue), labelTestSet.get(featValue), names)
# 如果递归后为叶子 则后续进行评估
if type(featValueDict[featValue]) != dict:
subTreeFlag = 0
# 如果没有数据 则转换子树
if dataFlag == 0 and type(featValueDict[featValue]) == dict:
subTreeFlag = 1
# print("当前节点无划分数据!直接转换树:"+str(featValueDict[featValue]))
newTree[featName][featValue] = convertTree(featValueDict[featValue])
# print("转换结果:" + str(convertTree(featValueDict[featValue])))
# 如果全为叶子节点, 评估需要划分前的标签,这里思考两种方法,
# 一是,不改变原来的训练函数,评估时使用训练数据对划分前的节点标签重新打标
# 二是,改进训练函数,在训练的同时为每个节点增加划分前的标签,这样可以保证评估时只使用测试数据,避免再次使用大量的训练数据
# 这里考虑第二种方法 写新的函数 createTreeWithLabel,当然也可以修改createTree来添加参数实现
if subTreeFlag == 0:
ratioPreDivision = equalNums(labelTest, featPreLabel) / labelTest.size
equalNum = 0
for val in labelTestSet.keys():
equalNum += equalNums(labelTestSet[val], featValueDict[val])
ratioAfterDivision = equalNum / labelTest.size
# print("当前节点预划分标签的准确率:" + str(ratioPreDivision))
# print("当前节点划分后的准确率:" + str(ratioAfterDivision))
# 如果划分后的测试数据准确率低于划分前的,则划分无效,进行剪枝,即使节点等于预划分标签
# 注意这里取的是小于,如果有需要 也可以取 小于等于
if ratioAfterDivision < ratioPreDivision:
newTree = featPreLabel
return newTree
DataTrain, LabelTrain, DataTest, LabelTest = splitXgData20(Data, Label)
# 生成预剪枝的树
TreePrePruning =createTreeWithLabel(Data, Label, Name, method = 'id3')
# 画剪枝后的树
print("剪枝后的树")
createPlot(TreePrePruning) 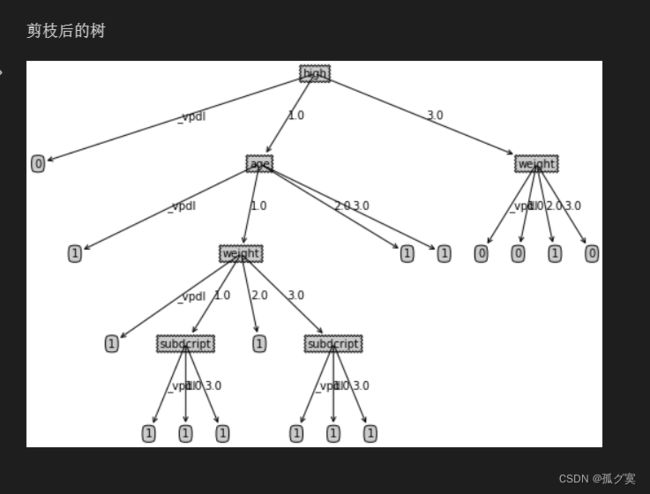
结果分析
从预剪枝和后剪枝的图中可以看出,后剪枝决策树通常比预剪枝决策树保留了更多的分支。一般情况,后剪枝决策树的欠拟合风险小,泛化能力往往优于预剪枝决策树。但是后剪枝决策树的训练时间更长,首先后剪枝决策树本身就是基于完全决策树上建立的,并且还需要自底向上的对树中地所有非叶子节点进行逐一考察。