Python 中的决策树

决策树是用于分类和回归任务的监督学习算法,我们将在决策树教程的第一部分集中讨论分类。
决策树被分配给基于信息的学习算法,这些算法使用不同的信息增益度量进行学习。我们可以将决策树用于我们有连续但也有分类输入和目标特征的问题。决策树的主要思想是找到那些包含关于目标特征的最多“信息”的描述性特征,然后沿着这些特征的值分割数据集,使得生成的 sub_datasets 的目标特征值尽可能纯 - -> 最纯粹地留下目标特征的描述性特征被认为是信息量最大的特征。这个寻找“信息量最大”特征的过程一直完成,直到我们完成一个停止标准,然后我们最终在所谓的叶节点中结束. 叶节点包含我们将对呈现给我们训练模型的新查询实例进行的预测。这是可能的,因为模型已经学习了训练数据的底层结构,因此可以在给定一些假设的情况下对未见过的查询实例的目标特征值(类)进行预测。
决策树主要由根节点、内部节点和叶节点组成,这些节点通过分支连接。
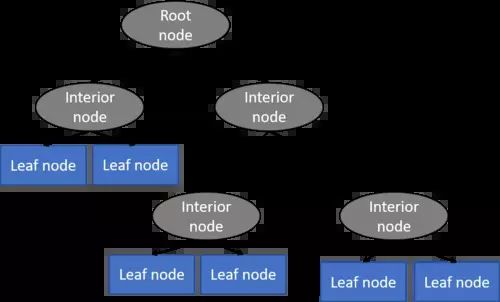
决策树被进一步细分,无论目标特征是像房价这样连续缩放还是像动物物种那样分类缩放。

简单来说,训练决策树和预测查询实例的目标特征的过程如下:
1. 呈现一个包含多个训练实例的数据集,这些实例具有多个描述性特征和一个目标特征
2. 通过在训练过程中使用信息增益的度量,沿着描述性特征的值连续分割目标特征来训练决策树模型
3. 生长树直到我们完成一个停止条件 --> 创建代表我们想要对新查询实例进行的预测的叶节点
4. 向树显示查询实例并沿着树向下运行,直到我们到达叶节点
5. 完成 - 恭喜您找到问题的答案
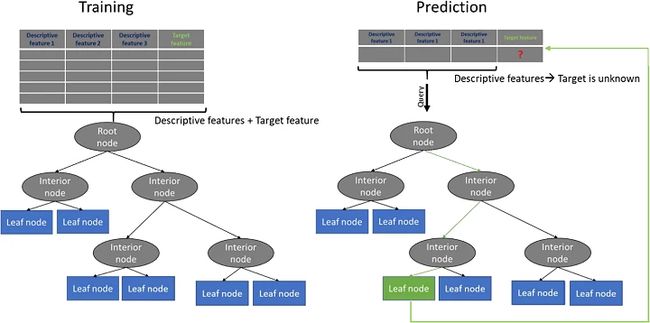
那么在知道之前我们知道什么?
原则上,决策树可用于通过基于已知目标特征值的现有数据构建模型(监督学习)来预测未知查询实例的目标特征。此外,我们知道该模型可以对未知查询实例进行预测,因为它对已知描述特征和已知目标特征之间的关系进行建模。在我们的以下示例中,树模型分别学习“特定动物物种的样子”以及动物物种特有的描述性特征值的组合。
此外,我们知道要训练决策树模型,我们需要一个由许多训练示例组成的数据集,这些示例具有许多描述性特征和一个目标特征。
在知道之前我们不知道的是:我们如何构建树模型。
为了回答这个问题,我们应该概括一下我们尝试使用决策树模型实现的目标。我们希望,给定一个数据集,训练一个模型,该模型学习描述性特征和目标特征之间的关系,以便我们可以向模型呈现一组新的、未见过的查询实例,并预测这些查询实例的目标特征值。让我们进一步概括一下决策树的一般形状。我们知道我们在树叶节点的底部有包含(在最佳情况下)目标特征值。为了使这更具有说明性,我们使用 UCI 机器学习动物园动物分类数据集的简化版本作为实际示例,其中包括作为描述特征的动物属性以及作为目标特征。在我们的示例中,根据动物是否有齿、有腿和呼吸,将动物分类为哺乳动物或爬行动物。数据集如下所示:
将 熊猫 导入为 pd
数据 = pd 。数据帧({ “齿” :[ “真” ,“真” ,“真” ,“假” ,“真” ,“真” ,“真” ,“真” ,“真” ,“假” ],
“头发” :[ “真” ,“真” ,“假” ,“真” ,“真” ,“真” ,“假”
:[ “真” ,“真” ,“真” ,“真” ,“真” ,“真” ,“假” ,“真” ,“真” ,“真” ],
“腿” :[ “真” " 、"真" 、"假" 、"真" 、"真" 、"真" 、"假" 、"假" 、"真" 、"真"],
"物种" :[ "哺乳动物" , "哺乳动物" , "爬行动物" ,“哺乳动物” ,“哺乳动物” ,“哺乳动物” ,“爬行动物” ,“爬行动物” ,“哺乳动物” ,“爬行动物” ]},
列= [ “牙齿” ,“头发” ,“呼吸” ,“腿” ,“物种" ])
特征 = 数据[[ “牙齿” ,“头发” ,“呼吸” ,“腿” ]]
目标 = 数据[ “物种” ]
数据
因此,回到我们最初的问题,每个叶节点(在最好的情况下)应该只包含“哺乳动物”或“爬行动物”。我们现在的任务是找到拆分数据集的最佳“方式”,以便实现这一目标。当我说split时我是什么意思?考虑上面的数据集,并考虑必须做什么才能将数据集拆分为仅包含哺乳动物作为目标特征值(物种)的数据集 1 和仅包含爬行动物的数据集 2。为了实现这一点,在这个简化的示例中,我们只需要描述性特征hair,因为如果 hair 为 TRUE,则相关物种始终是 Mammal。因此,在这种情况下,我们的树模型将如下所示:

也就是说,我们通过询问动物是否有头发的问题来分割我们的数据集。而正是这种询问和分裂是决策树模型的关键。现在在这种情况下,拆分非常容易,因为我们只有少量的描述性特征,并且数据集完全可以根据一个描述性特征的值进行分离。然而,大多数时候数据集并不是那么容易分离,我们必须多次拆分数据集(“多问一个问题”)。这里,直接出现下一个问题:鉴于我们必须多次拆分数据集,即提出多个问题来分离数据集,我们应该从哪个描述性特征(根节点)开始,以及我们应该以什么顺序提出问题(构建内部节点),也就是说,使用描述性特征来分割数据集?好吧,我们已经看到使用头发描述特征似乎占据了关于目标特征的最多信息,因为我们只需要这个特征来完美地分割数据集。因此,测量特征的“信息量”并使用“信息量最大”的特征作为应该用于分割数据的特征将是有用的。从现在开始,我们使用术语信息增益作为特征的“信息量”的度量。在下一节中,我们将介绍一些数学术语并推导如何计算信息增益以及如何基于此构建树模型。
决策树背后的数学
在上一节中,我们介绍了信息增益作为描述性特征适合拆分数据集的程度的衡量标准。为了能够计算信息增益,我们必须首先引入数据集的熵。数据集的熵用于衡量数据集的杂质,我们将在计算中使用这种信息量度量。还有其他类型的度量可用于计算信息增益。最突出的是:基尼指数、卡方、信息增益比、方差. 术语熵(在信息论中)可以追溯到 Claude E. Shannon。熵背后的想法,简而言之,如下:想象你有一个包含 100 个绿球的彩票轮盘。彩票轮内的一组球可以说是完全纯净的,因为只包括绿色球。用熵的术语来表达这一点,这组球的熵为 0(我们也可以说零杂质)。现在考虑,其中 30 个球被红色球取代,20 个球被蓝色球取代。

如果您现在从彩票轮中抽取另一个球,则收到绿球的概率已从 1.0 下降到 0.5。由于杂质增加,纯度降低,因此熵也增加。因此我们可以说,数据集越“不纯”,熵就越高,而数据集越不“不纯”,熵越低。香农的熵模型使用对数函数 (升○G2(磷(X))) 来测量数据集的熵和杂质,因为获得特定结果的概率越高 == P(x)(随机绘制一个绿球),越接近二元对数 1。
导入 numpy 作为 np
导入 matplotlib.pyplot 作为 plt
无花果= plt 。图()
ax =图. add_subplot ( 111 )
斧头。绘图( np . linspace ( 0.01 , 1 ), np . log2 ( np . linspace ( 0.01 , 1 )))
ax . set_xlabel ( "P(x)" )
ax 。set_ylabel ( "log2(P(x))" )
PLT 。显示()

一旦数据集包含多于一种“类型”的元素,特别是多于一个目标特征值,杂质将大于零。因此,数据集的熵也将大于零。因此,假设我们将从目标特征值空间中随机抽取值,将每个可能的目标特征值的熵相加并通过获得这些值的概率对其加权是有用的(仅通过机会?正好是 0.5,因此我们必须用 0.5 对为绿色球计算的熵进行加权)。这最终导致作为信息增益计算基线的香农熵的正式定义:
H(X)=-∑F○r 克 ∈吨一个rG电子吨(磷(X=克)*升○G2(磷(X=克)))
其中我们说 P(x=k) 是概率,即目标特征采用特定值 k。因此,将这个公式应用到我们得到的三个彩色球的例子中:
绿球: H(X=Gr电子电子n)=0.5*升○G2(0.5)=-0.5
蓝色球: H(X=乙升你电子)=0.2*升○G2(0.2)=-0.464
红球: H(X=r电子d)=0.3*升○G2(0.3)=-0.521
高(x): H(X)=-((-0.5)+(-0.464)+(-0.521))=1.485
让我们将此方法应用于我们想要预测动物物种的原始数据集。我们的数据集在其目标特征值空间 {Mammal, Reptile} 中有两个目标特征值。在哪里磷(X=米一个米米一个升)=0.6 和 磷(X=电阻电子p吨一世升电子)=0.4 因此,我们的数据集关于目标特征的熵计算如下:
H(X)=-((0.6*升○G2(0.6))+(0.4*升○G2(0.4)))=0.971
那么我们现在在创建树模型的道路上在哪里呢?
我们现在已经确定了总杂质/纯度(≈ 熵)我们的数据集大约等于 0.971. 现在我们的任务是找到信息增益方面的最佳特征(请记住,我们希望找到沿着目标特征值最准确地分割数据的特征),我们应该使用它来首先分割我们的数据(作为根节点)。请记住,头发特征不再是我们特征集的一部分。
在此之后,我们如何检查哪个描述性特征最准确地分割了数据集,即仍然是杂质最少的数据集≈熵,或者换句话说,最好通过自身对目标特征进行分类?好吧,我们使用每个描述性特征并沿着这些描述性特征的值分割数据集,然后在我们沿着特征值分割数据后计算数据集的熵。在我们沿着特征值拆分数据集之后,这为我们提供了剩余的熵。接下来,我们从数据集最初计算的熵中减去这个值,看看这个特征拆分减少了原始熵的程度。特征的信息增益计算公式为:
一世nF○G一个一世n(F电子一个吨你r电子d)=乙n吨r○p是(D)-乙n吨r○p是(F电子一个吨你r电子d)
因此,我们唯一要做的就是将数据集沿每个特征的值拆分,然后将这些子集视为熵计算方面的“原始”数据集。每个特征的信息增益计算公式为:
一世nF○rG一个一世n(F电子一个吨你r电子d,D)=乙n吨r○p是(D)-∑吨 ∈ F电子一个吨你r电子(|F电子一个吨你r电子d=吨||D|*H(F电子一个吨你r电子d=吨))
=
乙n吨r○p是(D)-∑吨 ∈ F电子一个吨你r电子(|F电子一个吨你r电子d=吨||D|*(-∑克 ∈ 吨一个rG电子吨(磷(吨一个rG电子吨=克,F电子一个吨你r电子d=吨)*升○G2(磷(吨一个rG电子吨=克,F电子一个吨你r电子d=吨))))
总而言之,对于每个描述性特征,我们总结了沿着特征值分割数据集的所得熵,并另外通过它们的出现概率对特征值熵进行加权。

现在我们将计算每个描述性特征的信息增益:
有齿:
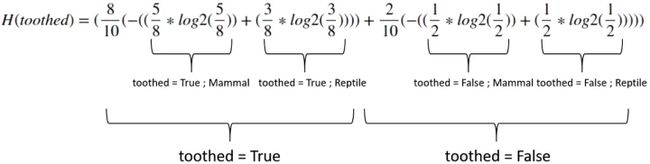
= 0.963547
一世nF○G一个一世n(吨○○吨H电子d)=0.971-0.963547= 0.00745
呼吸:
H(乙r电子一个吨H电子秒)=(910*-((69*升○G2(69))+(39*升○G2(39)))+110*-((0)+(1*升○G2(1))))= 0.82647
一世nF○G一个一世n(乙r电子一个吨H电子秒)=0.971-0.82647= 0.1445
腿:
H(升电子G秒)=710*-((67*升○G2(67))+(17*升○G2(17)))+310*-((0)+(1*升○G2(1)))=0.41417
一世nF○G一个一世n(升电子G秒)=0.971-0.41417= 0.5568
因此,沿着特征腿分割数据集会导致最大的信息增益,我们应该将此特征用于我们的根节点。
因此,目前决策树模型如下所示:

我们看到,对于legs == False,剩余数据集的目标特征值都是爬行动物,因此我们将其设置为叶节点,因为我们有一个纯数据集(在剩余两个特征中的任何一个上进一步拆分数据集不会导致不同或更准确的结果,因为无论我们在此之后做什么,预测都将保持Reptile)。此外,您会看到特征腿不再包含在其余数据集中。因为我们已经使用了这个(分类)特征来分割数据集,所以不能再使用了。
到现在为止,我们已经找到了根节点的特征以及legs == False的叶节点。现在也必须对剩余的legs == True数据集完成信息增益计算的相同步骤,因为这里我们仍然有不同目标特征值的混合。因此:
剩余数据集腿的齿状和呼吸特征的信息增益计算== True:
第一次拆分后(新)子数据集的熵:
H(D)=-((67*升○G2(67))+(17*升○G2(17)))= 0.5917
有齿:
H(吨○○吨H电子d)=57*-((1*升○G2(1))+(0))+27*-((12*升○G2(12))+(12*升○G2(12)))= 0.285
一世nF○G一个一世n(吨○○吨H电子d)=0.5917-0.285= 0.3067
呼吸:
H(乙r电子一个吨H电子秒)= 77*-((67*升○G2(67))+(17*升○G2(17)))+0= 5917
一世nF○G一个一世n(吨○○吨H电子d)= 0.5917-0.5917= 0
有齿 == False 的数据集仍然包含不同目标特征值的混合,为什么我们继续对最后一个左侧特征进行分区(==呼吸)
因此,完全长大的树看起来像:

请注意数据集在呼吸功能上拆分的最后一个拆分(节点)。这里的呼吸功能仅包含呼吸 == True 的数据。因此对于Breaths == False,数据集中没有实例,因此没有可以构建的子数据集。在这种情况下,我们返回原始数据集中出现频率最高的目标特征值,即Mammal。这是我们的树模型如何概括训练数据的示例。
如果我们考虑另一个分支,那就是Breaths == True我们知道,在我们的案例中,根据特定特征的值(呼吸 {True,False})分割数据集后,必须删除该特征。好吧,这会导致数据集没有更多特征可用于进一步拆分数据集。因此,我们停止生长树并返回直接父节点的众数值,即“哺乳动物”。
这导致我们引入了 ID3 算法,这是一种流行的决策树生长算法,由 Ross Quinlan 于 1986 年发表。 除了 ID3 算法之外,还有其他流行的算法,如 C4.5、C5.0 和 CART算法,这里不再赘述。在我们介绍 ID3 算法之前,让我们快速回到上述生长树的停止标准。我们可以定义几乎任意数量的停止标准。假设例如,我们说一棵树只允许生长 2 秒,然后生长过程应该停止 - 这将是一个停止标准 - 尽管如此,主要有三种有用的情况我们可以阻止树生长,假设我们不要通过定义例如最大树深度或最小信息增益值来预先阻止它。
1. 目标特征中的所有行都具有相同的值
2. 数据集不能再拆分,因为没有更多的特征了
3. 数据集不能再拆分,因为没有更多的行了/没有数据了
根据定义,我们说如果由于停止条件二而停止增长,叶节点应该预测上级(父)节点最常出现的目标特征值。如果增长因第三个停止标准而停止,我们为叶节点分配原始数据集的模式目标特征值。
注意,我们现在介绍ID3算法:
ID3 算法的伪代码基于 (Mitchell, 1997) 的伪代码说明。
ID3(D,Feature_Attributes,Target_Attributes)
Create a root node r
Set r to the mode target feature value in D
If all target feature values are the same:
return r
Else:
pass
If Feature_Attributes is empty:
return r
Else:
Att = Attribute from Feature_Attributes with the largest information gain value
r = Att
For values in Att:
Add a new node below r where node_values = (Att == values)
Sub_D_values = (Att == values)
If Sub_D_values == empty:
Add a leaf node l where l equals the mode target value in D
Else:
add Sub_Tree with ID3(Sub_D_values,Feature_Attributes = Feature_Attributes without Att, Target_Attributes)好吧,如果您不熟悉决策树,并且您的脑海中没有决策树的心理图景,那么这个伪代码可能有点令人困惑。因此,我们将在图片中说明这个伪代码,让事情更清楚一点——希望如此——。

使用 Python 从头开始分类决策树
由于我们现在知道 ID3 算法的主要步骤,我们将开始在Python 中从头开始创建我们自己的决策树分类模型。
因此,我们将使用整个UCI Zoo 数据集。
该数据集由 101 行和 17 个分类值属性组成,用于定义动物是否具有特定属性(例如毛发、羽毛等)。第一个属性代表动物的名字,将被移除。目标特征由 7 个整数值 [1 到 7] 组成,代表 [1:Mammal, 2:Bird, 3:Reptile, 4:Fish, 5:Amphibian, 6:Bug, 7:Invertebrate]
不过,在我们最终开始构建决策树之前,我想注意一些事情:
以下代码的目的不是创建 ID3 决策树的高效和健壮的实现。为此,聪明的头脑创建了预先打包的 sklearn 决策树模型,我们将在下一节中使用它。
通过以下代码,我想提供并展示从头开始创建决策树背后的基本原理和步骤,目标是我们可以更有效地使用预先打包的模块,因为我们了解并知道它们在做什么,并且最终可以构建我们的自己的机器学习模型。
也就是说,有四个重要步骤:
- 信息增益的计算
- TreeModel 的递归调用
- 实际树状结构的构建
- 一种新的看不见的动物实例的物种预测
这里最关键的方面是 TreeModel 的递归调用、树本身的创建(构建树结构)以及对未见过的查询实例的预测(在树上徘徊以预测未见过的类的过程)查询实例)。
"""
导入需要的python包
"""
import pandas as pd
import numpy as np
from pprint import pprint
#导入数据集并定义特征以及目标数据集/列#
dataset = pd . read_csv ('数据/ zoo.csv' ,
名字= [ 'animal_name' ,'头发' ,'羽毛' ,'蛋' ,'牛奶' ,
'浮在空中' ,'水生' ,'捕食者' ,'齿' ,'脊椎' ,
'呼吸' ,'有毒' ,'鳍' ,'腿' ,'catsize' , 'class' ,]) #导入省略包含动物名称的拳头的所有列
#我们删除了动物名称,因为这不是在
dataset = dataset上拆分数据的好功能。下降('animal_name' ,轴= 1 )
###################
def entropy ( target_col ):
"""
计算一个数据集的熵。
这个函数的唯一参数是 target_col 参数,它指定了目标列
"""
元素,counts = np 。unique ( target_col , return_counts = True )
entropy = np 。总和([(-计数[我] / NP 。总和(计数))* NP 。log2 ( counts [ i ] / np . sum ( counts )) for i in range ( len ( elements ))])
返回 熵
###################
###################
def InfoGain ( data , split_attribute_name , target_name = "class" ):
"""
计算数据集的信息增益。这个函数需要三个参数:
1. data = 应该为其特征计算 IG 的数据集
2. split_attribute_name = the需要计算信息增益的特征
的名称 3. target_name = 目标特征的名称,本例默认为"class"
"""
#计算总数据集的熵
total_entropy = entropy ( data [ target_name ])
##计算数据集的熵
#计算分割属性
vals的值和相应的计数,counts = np 。唯一(数据[ split_attribute_name ], return_counts = True )
#计算加权熵
Weighted_Entropy = np . sum ([( counts [ i ] / np . sum ( counts )) * entropy ( data . where ( data [ split_attribute_name ] == vals [ i ]) . dropna ()[ target_name ]) for i in range ( len ( vals ) ))])
#计算信息增益
Information_Gain = total_entropy - Weighted_Entropy
return Information_Gain
###################
###################
def ID3 ( data , originaldata , features , target_attribute_name = "class" , parent_node_class = None ):
"""
ID3算法:这个函数需要五个参数:
1. data = ID3算法应该运行的数据 --> In第一次运行 this 等于总数据集
2。 originaldata = 这是 在第一个参数传递的数据集为空的情况下计算原始数据集的模式目标特征值所需的原始数据集
3. features = 数据集的特征空间。这是递归调用所必需的,因为在树生长过程中,
我们必须从数据集中删除特征 --> 在每个节点拆分
4. target_attribute_name = 目标属性的名称
5. parent_node_class = 这是特定节点的父节点的模式目标特征值的值或类别。这
对于递归调用也是必需的,因为如果拆分导致特征
空间
中没有更多特征的情况,我们希望返回直接父节点的模式目标特征值。 """ #定义
停止条件 --> 如果满足其中之一,我们要返回一个叶子节点#
#如果所有 target_values 的值相同,则返回此值
if len ( np . unique ( data [ target_attribute_name ])) <= 1 :
return np . 唯一(数据[目标属性名称])[ 0 ]
#如果数据集为空,则返回原始数据集中的模式目标特征值
elif len ( data ) == 0 :
return np . 唯一( originaldata [ target_attribute_name ]) [ np . argmax (NP 。独特(originaldata [ target_attribute_name ],return_counts =真)[ 1 ])]
#如果特征空间为空,则返回直接父节点的模式目标特征值 --> 注意#
直接父节点是调用ID3算法当前运行的节点,因此#
模式目标特征值存储在 parent_node_class 变量中。
elif len ( features ) == 0 :
返回 parent_node_class
#如果以上都不成立,那就种树吧!
else :
#设置此节点的默认值 --> 当前节点的模式目标特征值
parent_node_class = np . 唯一(数据[目标属性名称])[ np . argmax (NP 。独特(数据[ target_attribute_name ],return_counts =真)[ 1 ])]
#选择最能分割数据集的特征
item_values = [ InfoGain ( data , feature , target_attribute_name ) for feature in features ] #返回数据集中特征的信息增益值
best_feature_index = np 。argmax ( item_values )
best_feature = features [ best_feature_index ]
#创建树结构。根
在第一次运行
树中 获取具有最大信息#gain的特征名称 (best_feature) = { best_feature :{}}
#从特征空间中移除具有最佳信息增益的特征
features = [ i for i in features if i != best_feature ]
#为根节点特征的每个可能值在根节点下生长一个分支
对于 价值 的 NP 。unique ( data [ best_feature ]):
value = value
#按照信息增益最大的特征
值分割数据集,然后创建 sub_datasets sub_data = data 。其中(数据[ best_feature ] == 值)。滴滴()
#使用新参数为每个子数据集调用ID3算法-->递归来了!
subtree = ID3 ( sub_data , dataset , features , target_attribute_name , parent_node_class )
#添加子树,从sub_dataset生长到根节点
树下的树[ best_feature ][ value ] = subtree
返回(树)
###################
###################
def predict ( query , tree , default = 1 ):
"""
对新的/未见过的查询实例的预测。这需要两个参数:
1. 查询实例作为形状的字典 {"feature_name":feature_value,... }
2. 树
我们也以递归方式执行此操作。也就是说,我们在树上徘徊并检查我们是否已经到达叶子或我们是否仍在子树中。
由于这是理解的重要步骤,因此下面对单个步骤进行了广泛的评论。
1.检查查询实例中的每个特征是否在第一次调用的tree.keys()中存在该特征,
tree.keys()只包含根节点的值
-->如果该值不存在,我们无法进行预测,必须
返回默认值,即目标特征的多数值
2. 首先,我们必须注意一个重要的事实:由于我们使用数据库 A 训练我们的模型,然后向我们的模型显示
一个看不见的查询,因此这些查询的特征值可能不存在于我们的树模型中,因为没有一个
训练实例对这个特定功能有这样的价值。
例如,想象一下您的模型只看到有 1 到 4
条腿的
动物的情况 - 模型中的“腿”节点将只有 4 个输出分支(从 1 到 4)。如果你现在向你的模型展示 一个新的实例(动物),它的腿有 5 号谷,你必须告诉你的模型在这样的情况下要做什么
情况,因为否则就不可能进行分类,因为在分类步骤中,您尝试
使用值为 5 的传出分支运行,但没有这样的分支。因此:错误且无分类!
我们可以使用例如 (999) 的分类值来解决这个问题,它告诉我们不可能进行分类,
或者我们分配用于训练模型的数据集的最频繁目标特征值。或者,例如在
医疗应用中,我们可以返回最糟糕的情况——只是为了确保......
我们还可以返回直接父节点的最频繁值。长话短说,我们必须告诉模型
在这种情况下该做什么。
在我们的示例中,由于我们正在处理错误分类并不那么重要的动物物种,因此我们将分配
值 1,即哺乳动物物种的值(为方便起见)。
3. 在树中找到适合键值的键 --> 请注意,键 == 查询中的特征。
因为我们希望树预测隐藏在键值下的值(假设您
在您面前的表
上有一个绘制的树模型,并且您有一个要预测其目标特征的查询实例 - 你是什么?在做什么? - 正确:
您从根节点开始并沿着树向下漫步,将您的查询与节点值进行比较。因此,您希望拥有
隐藏在当前节点下的值。如果这是一片叶子,那么完美,否则您就会徘徊树更深,直到
到达叶节点。
但是,您希望拥有隐藏在当前节点下的这个“东西”[叶子或子树],
因此我们必须寻址树中的节点,该节点 == 来自我们的查询实例的键值。
这是通过 tree[keys] 完成的。接下来,您要运行此节点的分支,该分支等于
在查询实例的键值
“后面”给出的值,例如,如果您找到“legs”== to tree.keys() 即,对于第一次运行== 根节点。 您想要更深入地运行,因此您必须在您的节点处将值为 == 的分支寻址到键后面的值。
这是通过 query[key] 完成的,例如 query[key] == query['legs'] == 0 --> 因此,我们沿着节点的分支运行
值 0。总而言之,在这一步中,我们要解决隐藏在根节点特定分支后面的节点(在第一次运行中),
这是通过以下方式完成的:result = [key][query[key]]
4. 如 2. 步骤所述,我们沿着节点和分支向下运行树,直到到达叶节点。
也就是说,如果 result = tree[key][query[key]] 返回另一个树对象(我们已经用一个 dict 对象来表示它 -->
即如果 result 是一个 dict 对象)我们知道我们还没有到达根节点,必须运行更深的树。
好吧...看看你在你面前绘制的树...你在做什么?...好吧,你跑到下一个分支...
正如我们上面所做的那样,我们已经有了轻微的不同通过一个节点,
因此只需要运行树的一小部分 --> 聪明的家伙!“树的一部分”正是我们存储
在“结果”下的内容。
因此,我们只需使用相同的查询实例调用我们的 predict 方法(我们不必从查询
实例中
删除任何特征,因为例如根节点的特征在任何更深的 sub_trees 中 都将不可用,因此我们根本不会找到那个特征)以及存储在结果中的“reduced / sub_tree”。
总结:如果我们有一个由特征值组成的查询实例,我们会使用这些特征并检查
根节点 的名称是否等于查询特征之一。 如果这是真的,我们运行根节点传出分支,其值等于查询特征的值 == 根节点。
如果我们在这个分支的末尾找到一个叶子节点(不是一个 dict 对象),我们就会返回这个值(这是我们的预测)。
如果我们找到另一个节点(== sub_tree == dict objct),我们会在查询中搜索
与该节点的值相等的特征。接下来,我们查找查询特征的值并沿着值等于
查询[key] == 查询特征值。正如你所看到的,这正是我们谈到的递归
,重要的事实是,对于我们沿着树向下运行的每个节点,我们只检查该节点
下方
的节点和分支,而不是从根开始运行整个树node --> 这就是为什么我们用'result'
"""重新调用分类函数的原因
#1.
对于 关键 的 列表(查询。键()):
如果 键 在 列表(树。键()):
#2。
尝试:
结果 = 树[键][查询[键]]
除外:
返回 默认值
#3.
结果 = 树[键][查询[键]]
#4。
if isinstance ( result , dict ):
return predict ( query , result )
else :
返回 结果
"""
检查我们预测的准确性
。train_test_split函数以数据集为参数,应该分为
训练集和测试集。测试函数有两个参数,分别是测试数据和树模型。
” ""
###################
###################
def train_test_split ( dataset ):
training_data = dataset 。iloc [: 80 ] 。reset_index ( drop = True ) #我们删除索引分别重新标记索引
#starting form 0,因为我们不想遇到关于行标签/索引
testing_data = dataset 的错误。国际劳工组织[ 80 :] 。reset_index ( drop = True )
返回 training_data , testing_data
training_data = train_test_split (数据集)[ 0 ]
testing_data = train_test_split (数据集)[ 1 ]
def test ( data , tree ):
#通过简单地从原始数据集中删除目标特征列
并将其转换为字典来
创建新的查询实例query = data 。iloc [:,: - 1 ] 。to_dict ( orient = "records" )
#创建一个空的DataFrame,树的预测存储在其列中
predicted = pd 。数据帧(列= [ “预测” ])
#Calculate预测精度
为 我 在 范围(len个(数据)):
预测。LOC [我,“预测” ] = 预测(查询[我],树,1.0 )
打印('的预测精度是:' ,(NP 。总和(预测[ “预测” ] == 数据[ “类” ])/ len (数据)) * 100 , '%' )
"""
训练树,打印树并预测准确率
"""
tree = ID3 ( training_data , training_data , training_data . columns [: - 1 ])
pprint ( tree )
test ( testing_data , tree )
输出:
{'legs': {'0': {'fins': {'0': {'toothed': {'0': '7', '1': '3'}},
'1':{'鸡蛋':{'0':'1','1':'4'}}}},
'2':{'头发':{'0':'2','1':'1'}},
'4': {'hair': {'0': {'toothed': {'0': '7', '1': '5'}}, '1': '1'}},
'6':{'水生':{'0':'6','1':'7'}},
'8': '7',
'腿':'class_type'}}
预测准确率为:86.36363636363636%
正如我们所看到的,动物园数据集的预测准确度约为 86%,考虑到我们没有做任何改进,例如定义最小分割大小或每个叶子或装袋的最小实例数量,这实际上还不错或提升,或修剪等。
使用 sklearn 的决策树
即使上面的代码对于传达决策树的概念以及如何“从头”实现分类树模型是合适且重要的,但在 sklearn sklearn.tree.DecisionTreeClassifier¶ 中实现了一个非常强大的决策树分类模型。多亏了这个模型,我们可以更快、更高效、更整洁地实现树模型,因为我们只需几行代码即可完成。使用 sklearn 分类决策树的步骤遵循主要的 sklearn API,它们是:
- 选择您要使用的模型 --> DecisionTreeClassifier
- 设置模型超参数 --> 例如每片叶子的最小样本数
- 创建一个特征数据集以及一个包含实例标签的目标数组
- 将模型拟合到训练数据
- 在看不见的数据上使用拟合模型。
而已!与往常一样,步骤是直截了当的。
"""
导入 DecisionTreeClassifier 模型。
"""
#
从 sklearn.tree 导入 DecisionTreeClassifier import DecisionTreeClassifier
############################################### ############################################### #######
############################################### ############################################### ######
"""
导入动物园数据集
"""
#导入数据
集 dataset = pd . read_csv ( 'data/zoo.csv' )
#我们删除动物名称,因为这不是在
dataset = dataset上拆分数据的好功能。下降('animal_name' ,轴= 1 )
############################################### ############################################### #######
############################################### ############################################### ######
"""
将数据拆分为训练集和测试集
"""
train_features = 数据集。iloc [: 80 ,: - 1 ]
test_features = 数据集。iloc [ 80 :,: - 1 ]
train_targets = dataset 。iloc [: 80 , - 1 ]
test_targets = 数据集。iloc [ 80 :, - 1 ]
############################################### ############################################### #######
############################################### ############################################### ######
"""
训练模型
"""
树 = DecisionTreeClassifier (标准 = 'entropy' )。适合(train_features ,train_targets )
############################################### ############################################### #######
############################################### ############################################### ######
"""
预测新的、看不见的数据的类别
"""
prediction = tree 。预测(test_features )
############################################### ############################################### #######
############################################### ############################################### ######
"""
检查准确性
"""
打印(“预测精度为:” ,树。分数(test_features ,test_targets )* 100 ,“%” )
输出:
预测准确率为:80.95238095238095%
是不是很酷?好吧,准确性并没有那么令人兴奋,但这更有可能是由于数据本身的组成以及模型的原因。随意尝试不同的模型参数以提高模型的准确性。
决策树的优缺点
由于我们现在已经看到了如何在 Python 中手动和使用预先打包的 sklearn 模型对决策树分类模型进行编程,因此我们将总体考虑决策树的主要优点和缺点,而不仅仅是分类决策树。

好处
- 白盒,易于解释的模型
- 无需特征归一化
- 树模型可以处理连续和分类数据(分类和回归树)
- 可以模拟非线性关系
- 可以对不同描述性特征之间的交互进行建模
缺点
- 如果使用连续特征,树可能会变得非常大,因此难以解释
- 决策树容易过度拟合训练数据,因此如果没有实施停止标准或改进(如修剪、提升或装袋),则不能很好地概括数据
- 数据的微小变化可能会导致完全不同的树。这个问题可以通过使用集成方法来解决,比如 bagging、boosting 或随机森林
- 一些目标特征值比其他目标特征值出现得更频繁的不平衡数据集可能会导致有偏差的树,因为频繁出现的特征值优先于出现频率较低的特征值。促进:通常有三种情况为什么我们想要增长叶节点: 如果 sub_set 中只有纯目标特征值 --> 我们返回这个值;如果sub_dataset为空 --> 我们返回原始数据集的众数值;如果sub_dataset中已经没有特征了-->我们返回父节点的众数值。如果我们现在有一个目标特征值,其频率高于所有其他频率,那么结果可能偏向于该值的原因就很明显了。我们可以通过确保数据集在目标特征值方面相对平衡来解决这个问题
- 如果特征数量比较多(高维),实例数量比较少,树可能会过拟合数据
- 具有多个级别的特征可能比具有较少级别的特征更受欢迎,因为对它们来说,分割数据集“更容易”,以便 sub_datasets 只包含纯目标特征值。这个问题可以通过优先选择例如信息增益比作为信息增益的分割标准来解决
- 当我们说明目标特征分割过程时,我们看到树模型将目标特征类分类为矩形区域。因此树模型假设底层数据可以被分割,分别由这些矩形区域表示。
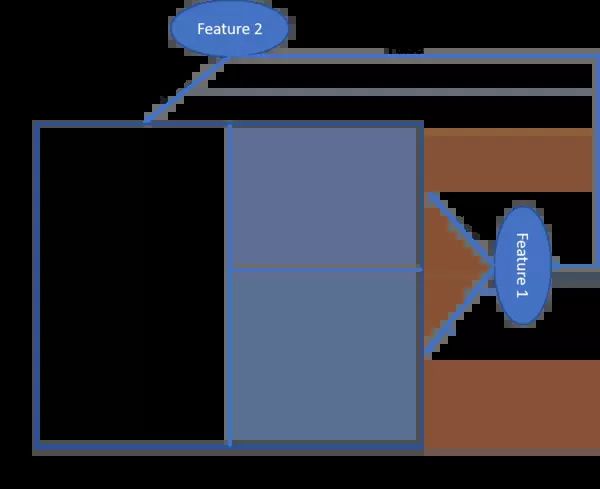
进一步的问题和变化
上面没有显示的第一件事是当描述性特征不是分类而是连续缩放时如何生长一棵树。
这与上述方法没有太大区别,区别很大,我们可以在树的生长过程中多次使用连续缩放的特征,并且我们必须使用与目标特征值有关的特征的均值或众数,而不是单个(分类)特征值 --> 这些不能再使用了,因为现在有无数不同的可能值。
第二个重要的变化是当我们不再有分类缩放但持续缩放的目标特征时。如果是这种情况,我们将树模型称为回归树模型而不是分类树模型。这里作为一个例子,我们可以使用与目标特征相关的特征方差作为分割标准,而不是信息增益。然后我们使用具有最低加权方差的特征作为分裂特征。
我们在上面说过决策树容易过度拟合训练数据。我们还提到可以使用称为修剪的方法来解决此问题。这正是它听起来的样子。我们修剪树。因此,我们从叶子节点开始,如果我们修剪叶子并将这些叶子的父节点替换为代表该节点的模式目标特征值的叶子节点,则只需检查准确度是否增加。按照这个过程,我们在树上徘徊,直到修剪不会导致更高的准确性或直到修剪不会降低准确性。长话短说,如果修剪不会降低准确性,请修剪。完毕。我们已经找到了在我们的测试数据集方面产生最大准确度的树。

另一种提高树模型准确性的方法是使用集成方法。使用集成方法,我们从原始数据集创建不同的模型(在本例中)树,并让不同的模型对测试数据集进行多数投票。也就是说,我们使用每个创建的模型预测测试数据集的目标值,然后返回大多数模型预测的目标特征值。创建决策树集成模型的最突出方法称为bagging和boosting。基于 boosting 的决策树集成模型的一个变体称为随机森林模型这是最强大的机器学习算法之一。还可以通过对单个模型使用不同的拆分标准(例如基尼指数和信息增益比)来创建集成模型。
我们现在已经看到决策树模型的许多变化和不同的方法。但是,没有关于应该使用哪种方法的一般指南。- 天下没有免费的午餐- 通常,这取决于……而唯一可以给出的真正建议是,您必须尝试具有不同超参
数的不同模型,以找到针对特定问题的最佳拟合模型。尽管如此,诸如随机森林算法之类的集成模型已被证明是非常强大的模型。
在接下来的章节中,我们将讨论上述一些变体,以更深入地了解决策树。
