id3-sklearn算法实现(西瓜数据集)
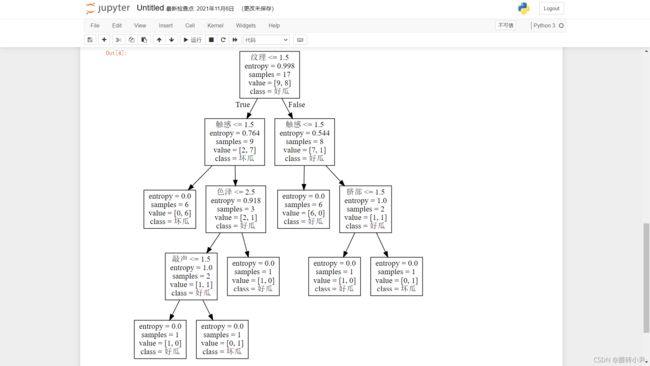
使用sklearn id3算法基于西瓜书上的西瓜集训练出模型,效果:
# 读取西瓜数据集
import numpy as np
import pandas as pd
df =pd.read_table(r'watermelon.txt',encoding='utf8',delimiter=',',index_col=0)
df.head()
# 由于上面的数据中包含了中文汉字,所以需要对数据进一步处理
'''
属性:
色泽 1-3代表 浅白 青绿 乌黑 根蒂 1-3代表 稍蜷 蜷缩 硬挺
敲声 1-3代表 清脆 浊响 沉闷 纹理 1-3代表 清晰 稍糊 模糊
脐部 1-3代表 平坦 稍凹 凹陷 触感 1-2代表 硬滑 软粘
标签:
好瓜 1代表 是 0 代表 不是
'''
df['色泽']=df['色泽'].map({'浅白':1,'青绿':2,'乌黑':3})
df['根蒂']=df['根蒂'].map({'稍蜷':1,'蜷缩':2,'硬挺':3})
df['敲声']=df['敲声'].map({'清脆':1,'浊响':2,'沉闷':3})
df['纹理']=df['纹理'].map({'清晰':1,'稍糊':2,'模糊':3})
df['脐部']=df['脐部'].map({'平坦':1,'稍凹':2,'凹陷':3})
df['触感'] = np.where(df['触感']=="硬滑",1,2)
df['好瓜'] = np.where(df['好瓜']=="是",1,0)
#由于西瓜数据集样本比较少,所以不划分数据集,将所有的西瓜数据用来训练模型
Xtrain = df.iloc[:,:-1]
Xtrain = np.array(Xtrain)
Ytrain = df.iloc[:,-1]
# 调用sklearn内置的决策树的库和画图工具
from sklearn import tree
import graphviz
# 采用ID3算法,利用信息熵构建决策树模型
clf = tree.DecisionTreeClassifier(criterion="entropy")
clf = clf.fit(Xtrain,Ytrain)
##y_predict=clf.predict([[3,2,3,2,2,1]])
##print(y_predict)
##print(clf.feature_importances_)
# 绘制决策树的图形
feature_names = ["色泽","根蒂","敲声","纹理","脐部","触感"]
dot_data = tree.export_graphviz(clf,feature_names=feature_names,class_names=["好瓜","坏瓜"])
graph = graphviz.Source(dot_data)
graph.view()西瓜集内容如下:
编号,色泽,根蒂,敲声,纹理,脐部,触感,好瓜
1,青绿,蜷缩,浊响,清晰,凹陷,硬滑,是
2,乌黑,蜷缩,沉闷,清晰,凹陷,硬滑,是
3,乌黑,蜷缩,浊响,清晰,凹陷,硬滑,是
4,青绿,蜷缩,沉闷,清晰,凹陷,硬滑,是
5,浅白,蜷缩,浊响,清晰,凹陷,硬滑,是
6,青绿,稍蜷,浊响,清晰,稍凹,软粘,是
7,乌黑,稍蜷,浊响,稍糊,稍凹,软粘,是
8,乌黑,稍蜷,浊响,清晰,稍凹,硬滑,是
9,乌黑,稍蜷,沉闷,稍糊,稍凹,硬滑,否
10,青绿,硬挺,清脆,清晰,平坦,软粘,否
11,浅白,硬挺,清脆,模糊,平坦,硬滑,否
12,浅白,蜷缩,浊响,模糊,平坦,软粘,否
13,青绿,稍蜷,浊响,稍糊,凹陷,硬滑,否
14,浅白,稍蜷,沉闷,稍糊,凹陷,硬滑,否
15,乌黑,稍蜷,浊响,清晰,稍凹,软粘,否
16,浅白,蜷缩,浊响,模糊,平坦,硬滑,否
17,青绿,蜷缩,沉闷,稍糊,稍凹,硬滑,否