多图详解attention和mask。从循环神经网络、transformer到GPT2
transformer原理
文章目录
-
- transformer原理
-
- 1. Transformer的兴起
- 2. 图解Attention
-
- 2.1 seq2seq
- 2.2 循环神经网络的不足:
- 2.3 attention的引出(重点内容)
-
- 2.3.1 经典seq2seq模型的改进
- 2.3.2 为什么求内积之后除以 d \sqrt{d} d
- 2.4 Self-Attention
-
- 2.4.1 Self-Attention结构
- 2.4.2 Self-Attention和经典的(seq2seq)模型的区别
- 2.4.3 Self Attention和循环神经网络对比
- 2.4.4 Self-Attention 过程
- 2.5 Attention模型的改进形式
- 3.多头注意力机制(multi-head attention)
-
- 3.1 从attention引出multi-head attention
- 3.2 Multi-Head Attention的公式变换:
- 3.4 代码实现矩阵计算 Attention
-
- 3.4.1 定义MultiheadAttention
- 3.4.2 forward的输入(引出mask机制)
- 3.4.3 forward的输出
- 3.5 手动实现attention
- 3.6 手动实现多头注意力
- 4. 图解transformer
-
- 4.1 自注意力模型的缺点及transformer的提出
- 4.2 transformer的改进
-
- 4.2.1 融入位置信息
- 4.2.2 输入向量角色信息
- 4.2.3 多层自注意力(多层编码解码结构、FFNN、Norm+Add)
- 4.2.4 多头自注意力( Multi - head Self - attention )
- 4.3 Encoder
-
- 4.3.1 Encoder层结构
- 4.3.2残差连接和标准化
- 4.3.3 Transformer-encoder结构梳理——数学表示.
- 4.4 Decoder(解码器)
- 4.5 最后的线性层和 Softmax 层
- 4.6 Transformer 的输入
- 5. Transformer 的训练过程
-
- 5.1 损失函数
- 5.2 贪婪解码和集束搜索
- 2.4 从机器翻译推广到attention的一般模式
- 6. 花式Mask预训练(我悟了)
说明:
本文主要来自datawhale的开源教程 《基于transformers的自然语言处理(NLP)入门》,此项目也发布在 github。部分内容(章节2.1-2.5,3.1-3.2,4.1-4.2)来自北大博士后卢菁老师的《速通机器学习》一书。
另外篇幅有限,关于多头注意力的encoder-decoder attention模块进行运算的更详细内容可以参考 《Transformer概览总结》。从attention到transformer的API实现和自编程代码实现,可以查阅 《Task02 学习Attention和Transformer》(这篇文章排版很好,干净简洁,看着非常舒服,非常推荐)
Transformer代码参考《Transformer源代码解释之PyTorch篇》、《《The Annotated Transformer》翻译————注释和代码实现《Attention Is All You Need》》。
1. Transformer的兴起
2017年,《Attention Is All You Need》论文首次提出了Transformer模型结构并在机器翻译任务上取得了The State of the Art(SOTA, 最好)的效果。2018年,《BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding》使用Transformer模型结构进行大规模语言模型(language model)预训练(Pre-train),再在多个NLP下游(downstream)任务中进行微调(Finetune),一举刷新了各大NLP任务的榜单最高分,轰动一时。2019年-2021年,研究人员将Transformer这种模型结构和预训练+微调这种训练方式相结合,提出了一系列Transformer模型结构、训练方式的改进(比如transformer-xl,XLnet,Roberta等等)。如下图所示,各类Transformer的改进不断涌现。
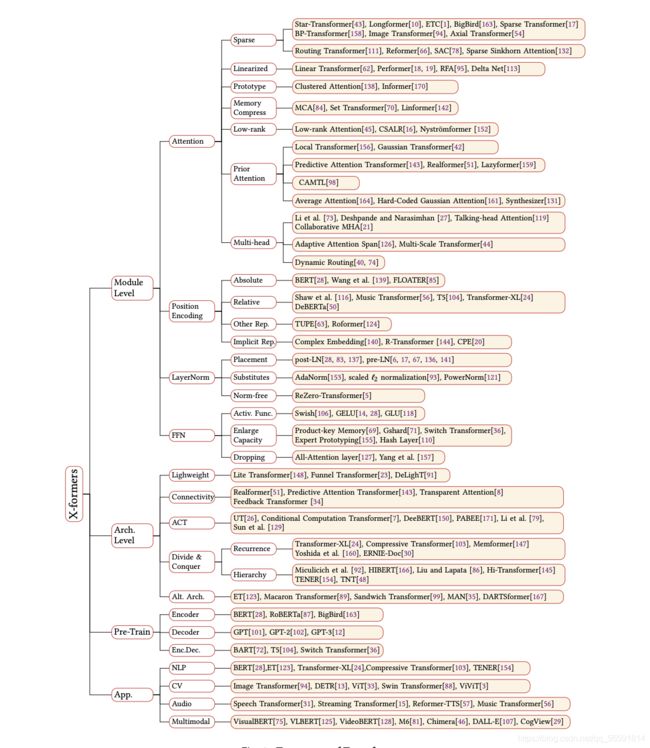
图片来自复旦大学邱锡鹏教授:NLP预训练模型综述《A Survey of Transformers》。中文翻译可以参考:https://blog.csdn.net/Raina_qing/article/details/106374584
https://blog.csdn.net/weixin_42691585/article/details/105950385
另外,由于Transformer优异的模型结构,使得其参数量可以非常庞大从而容纳更多的信息,因此Transformer模型的能力随着预训练不断提升,随着近几年计算能力的提升,越来越大的预训练模型以及效果越来越好的Transformers不断涌现。
本教程也将基于HuggingFace/Transformers, 48.9k Star进行具体编程和解决方案实现。
NLP中的预训练+微调的训练方式推荐阅读知乎的两篇文章 《2021年如何科学的“微调”预训练模型?》 和《从Word Embedding到Bert模型—自然语言处理中的预训练技术发展史》。
2. 图解Attention
2.1 seq2seq
seq2seq模型是由编码器(Encoder)和解码器(Decoder)组成的。以两个具有不同参数的LSTM分别作为encoder和decoder处理机器翻译为例,结构如下:
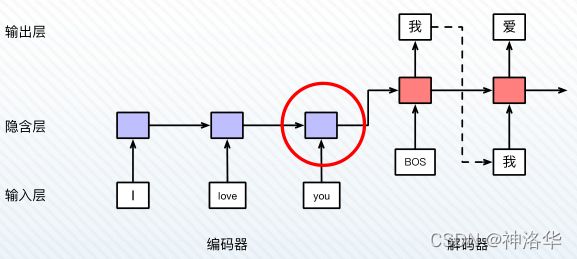
LSTM1为编码器,在最后时刻的上下文信息 Context 包含中文“我爱你”的完整信息,传给给解码器LSTM2,作为翻译阶段LSTM2的起始状态
2.2 循环神经网络的不足:
循环神经网络的处理此类任务存在一些不足:
1.长距离衰减问题:机器翻译时,LSTM模型的encoder只输出最后时刻的上下文信息C,当编码句子较长时,句子靠前部分对C的影响会降低;
2.解码阶段,随着序列的推移,编码信息C对翻译的影响越来越弱。因此,越靠后的内容,翻译效果越差。(其实也是因为长距离衰减问题)
3.解码阶段缺乏对编码阶段各个词的直接利用。简单说就是:机器翻译领域,解码阶段的词和编码阶段的词有很强的映射关系,比如“爱”和“love”。但是seq2seq模型无法再译“love”时直接使用“爱”这个词的信息,因为在编码阶段只能使用全局信息C。(attention在这点做得很好)
在 2014——2015年提出并改进了一种叫做注意力attetion的技术,它极大地提高了机器翻译的质量。注意力使得模型可以根据需要,关注到输入序列的相关部分。
2.3 attention的引出(重点内容)
2.3.1 经典seq2seq模型的改进
基于2.2提到的3点,需要对模型进行改造。(图不是很好,将就看看)
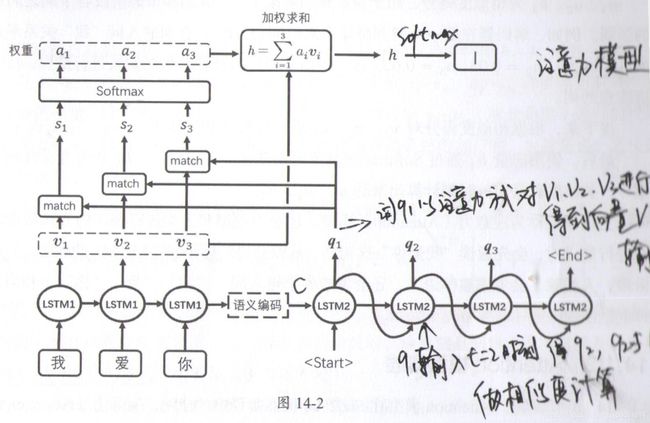
编码阶段和前面的模型没有区别,保留了各时刻LSTM1的输出向量v。解码阶段,模型预测的方法有了变化,比如在t=1时刻,预测方式为:
- 计算LSTM2在t=1时刻的输出q1,以及v1、v2、v3的相似度,即对q1和v1、v2、v3求内积:
s1=
s2=
s3= - s1、s2、s3可以理解为未归一化的相似度,通过softmax函数对其归一化,得到a1、a2、a3。满足a1+a2+a3=1。a1、a2、a3就是相似度得分attention score。用于表示解码阶段t=1时刻和编码阶段各个词之间的关系。
例如解码器在第一个时刻,翻译的词是“I”,它和编码阶段的“我”这个词关系最近, a 我 a_我 a我的分数最高(比如0.95)。由此达到让输出对输入进行聚焦的能力,找到此时刻解码时最该注意的词,这就是注意力机制。比起循环神经网络有更好的效果。
(attention score只表示注意力强度,是一个标量,一个系数,不是向量,不含有上下文信息,所以还不是最终输出结果。在此回答一些小伙伴的疑问)
- 根据相似度得分对v1、v2、v3进行加权求和,即 h 1 = a 1 v 1 + a 2 v 2 + a 3 v 3 h_{1}=a_{1}v_{1}+a_{2}v_{2}+a_{3}v_{3} h1=a1v1+a2v2+a3v3。
- 向量h1经过softmax函数来预测单词“I”。可以看出,此时的h1由最受关注的向量 v 我 v_我 v我主导。因为 a 我 a_我 a我最高。
上述模型就是注意力(Attention)模型)(这里没有用Self-Attention代替LSTM,主要还是讲attention机制是基于什么原因引出的。)。(此处的模型没有key向量,是做了简化,即向量 K = V K=V K=V)
注意力模型和人类翻译的行为更为相似。人类进行翻译时,会先通读“我爱你”这句话,从而获得整体语义(LSTM1的输出C)。而在翻译阶段,除了考虑整体语义,还会考虑各个输入词(“我”、“爱”、“你”)和当前待翻译词之间的映射关系(权重a1、a2、a3来聚焦注意力)
2.3.2 为什么求内积之后除以 d \sqrt{d} d
上面计算相似度s=
对于两个d维向量q,k,假设它们都采样自“均值为0、方差为1”的分布。Attention是内积后softmax,主要设计的运算是 e q ⋅ k e^{q⋅k} eq⋅k,我们可以大致认为内积之后、softmax之前的数值在 − 3 d -3\sqrt{d} −3d到 3 d 3\sqrt{d} 3d这个范围内,由于d通常都至少是64,所以 e 3 d e^{3\sqrt{d}} e3d比较大而 e − 3 d e^{-3\sqrt{d}} e−3d比较小,softmax函数进入饱和区。这样会有两个影响:
- 带来严重的梯度消失问题,导致训练效果差。
- softmax之后,归一化后计算出来的结果a要么趋近于1要么趋近于0,Attention的分布非常接近一个one hot分布了,加权求和退化成胜者全拿,则解码时只关注注意力最高的(attention模型还是希望别的词也有权重)
相应地,解决方法就有两个:(参考苏剑林《浅谈Transformer的初始化、参数化与标准化》)
- 像NTK参数化那样,在内积之后除以 d \sqrt{d} d,使q⋅k的方差变为1,对应 e 3 e^3 e3, e − 3 e^{−3} e−3都不至于过大过小,这也是常规的Transformer如BERT里边的Self Attention的做法。对公式s=
s = < q , k > d k e y s=\frac{ - 另外就是不除以 d \sqrt{d} d,但是初始化q,k的全连接层的时候,其初始化方差要多除以一个d,这同样能使得使q⋅k的初始方差变为1,T5采用了这样的做法。
2.4 Self-Attention
2.4.1 Self-Attention结构
H = A t t e n t i o n ( Q , K , V ) H=Attention(Q,K,V) H=Attention(Q,K,V)有一种特殊情况,就是 Q = K = V Q=K=V Q=K=V,也就是自注意力模型self-attention。(一个输入向量同时承担了三种角色)
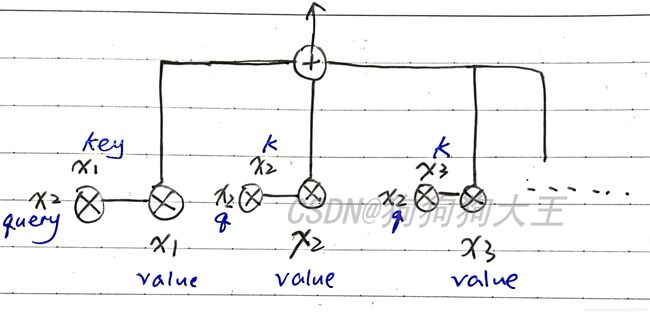
如上图所示,self-attention中query、key、value的这三样东西其实是一样的,它们的形状都是:(L,N,E)
L:输入序列的长度(例如一个句子的长度)
N:batch size(例如一个批的句子个数)
E:词向量长度
Self-Attention只有一个序列(即只有一种输入特征),比如机器翻译中,输入只有词向量。这应该就是Self-Attention和Attention的区别。
2.4.2 Self-Attention和经典的(seq2seq)模型的区别
一个注意力模型不同于经典的(seq2seq)模型,主要体现在 3 个方面:
- 编码器把所有时间步的 hidden state(隐藏层状态)传递给解码器,而非只传递最后一个 hidden state。即编码器会把更多的数据传递给解码器。
- 对于Self Attention机制,会把其他单词的理解融入处理当前的单词。使得模型不仅能够关注这个位置的词,而且能够关注句子中其他位置的词,作为辅助线索,进而可以更好地编码当前位置的词。
- 解码器输出之前,计算了注意力。让模型找到此时刻最该注意的词。
对于第二点举例如下:
机器人第二定律
机器人必须服从人给予 它 的命令,当 该命令 与 第一定律 冲突时例外。
句子中高亮的3 个部分,用于指代其他的词。如果不结合它们所指的上下文,就无法理解或者处理这些词。当一个模型要处理好这个句子,它必须能够知道:
它 指的是机器人
该命令 指的是这个定律的前面部分,也就是 人给予 它 的命令
第一定律 指的是机器人第一定律
Self Attention 能做到这一点。它在处理某个词之前,将模型中这个词的相关词和关联词的理解融合起来(并输入到一个神经网络)。它通过对句子片段中每个词的相关性打分(attention score),并将这些词向量加权求和。
下图顶部模块中的 Self Attention 层在处理单词it的时候关注到 a robot。它最终传递给神经网络的向量,是这 3 个单词的词向量加权求和的结果。
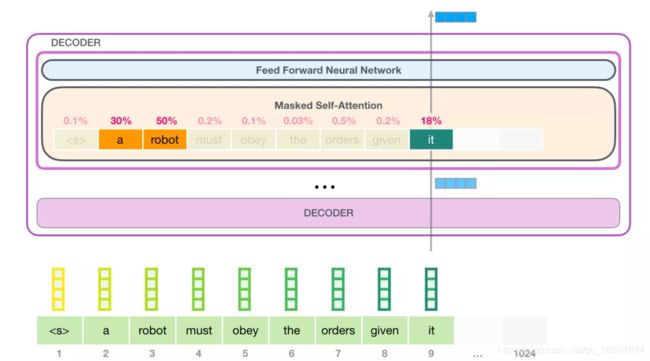
2.4.3 Self Attention和循环神经网络对比
Self Attention是一个词袋模型,对词序不敏感。因为每时刻输出 h i = a 1 v 1 + a 2 v 2 + a 3 v 3 . . . = ∑ a i , j v i h_{i}=a_{1}v_{1}+a_{2}v_{2}+a_{3}v_{3}...=\sum a_{i,j}v_{i} hi=a1v1+a2v2+a3v3...=∑ai,jvi。这是一个加权求和,调换词序对结果不影响。所以对比循环神经网络可以发现:
1.LSTM、RNN、ELMo等循环神经网络模型考虑了词序,但是正因为如此,每个时刻的输出依赖上一时刻的输入,所以只能串行计算,无法并行,无利用更庞大的算力来加快模型训练,这也是循环神经网络渐渐被attention替代的原因之一。Self Attention模型不考虑词序,所有字是全部同时训练的, 各时刻可以独立计算,可以并行,反而成了它的优点。
2.循环神经网络的存在长距离衰减问题,而attention可以无视词的距离,因为每时刻都是加权求和,考虑了每一个词,不存在信息衰减。
LSTM:非词袋模型,含有顺序信息,无法解决长距离依赖,无法并行,没有注意力机制
Self Attention:词袋模型,不含位置信息,没有长距离依赖,可以并行,有注意力机制。
但是这里有个问题,语义和词序是有一定的关联的,为了解决这个问题,有两个办法:
1.位置嵌入(Position Embeddings)
2.位置编码(Position Encodings)
在transformer部分会进一步介绍
2.4.4 Self-Attention 过程
如上一节所讲Self Attention 它在处理某个词之前,通过对句子片段中每个词的相关性进行打分,并将这些词的表示向量加权求和。
Self-Attention 沿着句子中每个 token 的路径进行处理,主要组成部分包括 3 个向量。
Query:Query 向量是当前单词的表示,用于对其他所有单词(使用这些单词的 key 向量)进行评分。我们只关注当前正在处理的 token 的 query 向量。
Key:Key 向量就像句子中所有单词的标签。它们就是我们在搜索单词时所要匹配的。
Value:Value 向量是实际的单词表示,一旦我们对每个词的相关性进行了评分,我们需要对这些向量进行加权求和,从而表示当前的词。
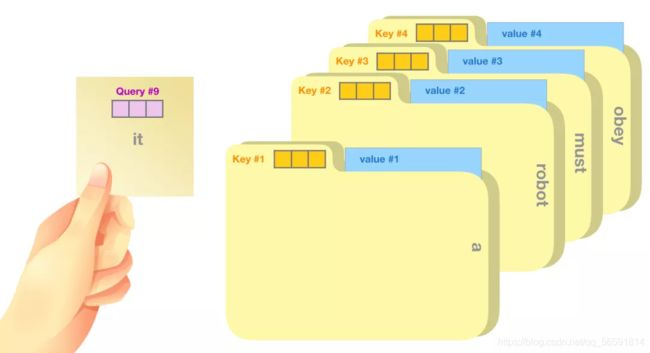
一个粗略的类比是把它看作是在一个文件柜里面搜索
| 向量 | 含义 |
|---|---|
| Query | 一个便签,上面写着你正在研究的主题 |
| Key | 柜子里的文件夹的标签 |
| Value | 文件夹里面的内容 |
首先将主题便签与标签匹配,会为每个文件夹产生一个分数(attention score)。然后取出匹配的那些文件夹里面的内容 Value 向量。最后我们将每个 Value 向量和分数加权求和,就得到 Self Attention 的输出。(下图是单指计算it的时候)
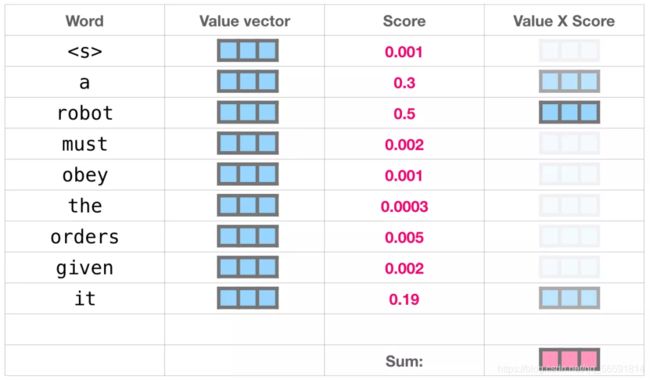
这些加权的 Value 向量会得到一个向量,它将 50% 的注意力放到单词robot 上,将 30% 的注意力放到单词 a,将 19% 的注意力放到单词 it。最终一个具有高分数的 Value 向量会占据结果向量的很大一部分。
注意:上面都是展示大量的单个向量,是想把重点放在词汇层面上。而实际的代码实现,是通过巨大的矩阵相乘来完成的。

更详细的self-attention介绍可以参考《图解GPT》
2.5 Attention模型的改进形式
Attention模型计算相似度,除了直接求内积
s = A T T a n h ( q W + k U ) s=A^{T}Tanh(qW+kU) s=ATTanh(qW+kU)
多层感知机, A 、 W 、 U A 、 W 、 U A、W、U都是待学习参数。这种方法不仅避开了求内积时 q 和 k 的向量长度必须一致的限制,还可以进行不同空间的向量匹配。例如,在进行图文匹配时, q 和 k 分别来自文字空间和图像空间,可以先分别通过 W 、 U W 、 U W、U将它们转换至同一空间,再求相似度。
上面式子中, W 、 U W 、U W、U是矩阵参数,相乘后可以使q和k的维度一致。比如机器翻译中,中文一词多义情况比较多,中文向量q维度可以设置长一点,英文中一词多义少,k的维度可以设置短一点。 q W + k U qW+kU qW+kU是同长度向量相加,结果还是一个向量,再经过列向量 A T A^{T} AT相乘,得到一个标量,即attention score数值。
第二个改进式子:
s = < q W k T > d k e y s=\frac{
其中,W是待学习参数,q和k维度可以不同。
第三个改进式子:
s = < q W , k U > d k e y s=\frac{
3.多头注意力机制(multi-head attention)
3.1 从attention引出multi-head attention
见本文4.2.4。现在都很少有原始的Self Attention了,都是Self-multi-head-Attention。
3.2 Multi-Head Attention的公式变换:
- 用矩阵系数 W 1 Q 、 W 1 K 、 W 1 V W_{1}^{Q}、W_{1}^{K}、W_{1}^{V} W1Q、W1K、W1V将Q,K , V 转至语义空间1,公式为:
Q 1 = Q W 1 Q = [ q 1 W 1 Q . . . q m W 1 Q ] Q_{1}=QW_{1}^{Q}=\begin{bmatrix} q_{1}W_{1}^{Q}\\ ...\\ q_{m}W_{1}^{Q}\end{bmatrix} Q1=QW1Q=⎣ ⎡q1W1Q...qmW1Q⎦ ⎤
K 1 = K W 1 K = [ q 1 W 1 K . . . q m W 1 K ] K_{1}=KW_{1}^{K}=\begin{bmatrix} q_{1}W_{1}^{K}\\ ...\\ q_{m}W_{1}^{K}\end{bmatrix} K1=KW1K=⎣ ⎡q1W1K...qmW1K⎦ ⎤
V 1 = V W 1 V = [ q 1 W 1 V . . . q m W 1 V ] V_{1}=VW_{1}^{V}=\begin{bmatrix} q_{1}W_{1}^{V}\\ ...\\ q_{m}W_{1}^{V}\end{bmatrix} V1=VW1V=⎣ ⎡q1W1V...qmW1V⎦ ⎤
Q,K , V都是向量序列,因此特征变换就是各时序上的向量变换。 W 1 Q 、 W 1 K 、 W 1 V W_{1}^{Q}、W_{1}^{K}、W_{1}^{V} W1Q、W1K、W1V是待学习参数。 - 在转换后的语义空间进行attention计算, Z 1 = h e a d 1 = A t t e n t i o n ( Q 1 , K 1 , V 1 ) Z_1=head_1= Attention(Q_1,K_1 , V_1) Z1=head1=Attention(Q1,K1,V1)。 h e a d 1 head_1 head1也是向量序列,长度和Q一致(一个输入对应一个输出)。具体地:
- 计算 Attention Score(注意力分数)。有几种计算方式,常用的是求点积。注意力分数决定了我们在编码时,需要对句子中其他位置的每个词放置多少的注意力。
- 把每个分数除以 ( d k e y ) \sqrt(d_{key}) (dkey)(Key 向量的长度,也可以是其它数),再进行softmax归一化,得到系数a;
- a和向量V加权求和得z。这种做法背后的直觉理解就是:对于分数高的位置,相乘后的值就越大,我们把更多的注意力放到了它们身上
即。
由于我们使用了矩阵来计算,所以这几步可以表示为:
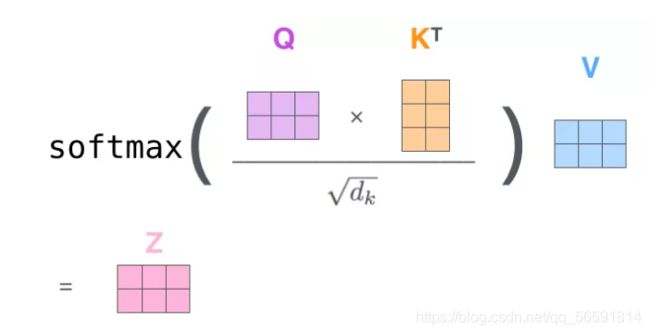
- 用矩阵系数 W 2 Q 、 W 2 K 、 W 2 V W_{2}^{Q}、W_{2}^{K}、W_{2}^{V} W2Q、W2K、W2V将Q 、 K 、 V 转换至语义空间2,进行Attention计算,得到 h e a d 2 head_2 head2。同理计算出 h e a d 3 . . . . h e a d c head_3....head_c head3....headc。
- 多抽头的每一组注意力的 的权重矩阵都是随机初始化的,都是不一样的。经过训练之后,每一组注意力 W Q W^Q WQ, W K W^K WK W V W^V WV 可以看作是把输入的向量映射到一个”子表示空间“。
- h e a d c head_c headc是多个不同语义空间注意力计算的结果,将它们串联拼接起来。
总结起来,多头注意力模型公式可以写成:
M u l t i − H e a d ( Q , K , V ) = c o n c a t ( h e a d 1 . . . . h e a d c ) W O = [ c o n c a t ( h 1 , 1 . . . h n , 1 ) W O . . . c o n c a t ( h 1 , m . . . h n , m W O ] Multi-Head(Q ,K , V )=concat(head_1....head_c)W^{O}=\begin{bmatrix} concat(h_{1,1}...h_{n,1})W^{O}\\ ...\\ concat(h_{1,m}...h_{n,m}W^{O}\end{bmatrix} Multi−Head(Q,K,V)=concat(head1....headc)WO=⎣ ⎡concat(h1,1...hn,1)WO...concat(h1,m...hn,mWO⎦ ⎤
多头注意力结果串联在一起维度可能比较高,所以通过 W O W^{O} WO进行一次线性变换,实现降维和各头信息融合的目的,得到最终结果。
下面以head=8举例说明如下:
- 输入 X 和8组权重矩阵 W Q W^Q WQ, W K W^K WK W V W^V WV相乘,得到 8 组 Q, K, V 矩阵。进行attention计算,得到 8 组 Z 矩阵(特就是head)
- 把8组矩阵拼接起来,乘以权重矩阵 W O W^O WO,得到最终的矩阵 Z。这个矩阵包含了所有 attention heads(注意力头) 的信息。
- 矩阵Z会输入到 FFNN (Feed orward Neural Network)层。(前馈神经网络层接收的也是 1 个矩阵,而不是8个。其中每行的向量表示一个词)
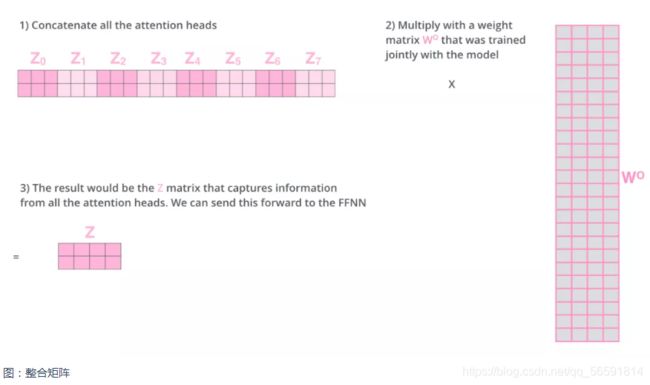
这就是多头注意力的全部内容。下面我把所有的内容都放到一张图中,这样你可以总揽全局,在这张图中看到所有的内容。

多头注意力模型中,head数是一个超参数,语料大,电脑性能好就可以设置的高一点。宁可冗余也不遗漏。
在前面的讲解中,我们的 K、Q、V 矩阵的序列长度都是一样的。但是在实际中,K、V 矩阵的序列长度是一样的(加权求和),而 Q 矩阵的序列长度可以不一样。
这种情况发生在:在解码器部分的Encoder-Decoder Attention层中,Q 矩阵是来自解码器下层,而 K、V 矩阵则是来自编码器的输出。
更进一步讲解可以看GPT-2里的self-attention讲解。
3.4 代码实现矩阵计算 Attention
下面我们是用代码来演示,如何使用矩阵计算 attention。首先使用 PyTorch 库提供的函数实现,然后自己再实现。
PyTorch 提供了 MultiheadAttention 来实现 attention 的计算。(其实应该理解为多头自注意力模型)
3.4.1 定义MultiheadAttention
torch.nn.MultiheadAttention(embed_dim, num_heads, dropout=0.0, bias=True, add_bias_kv=False, add_zero_attn=False, kdim=None, vdim=None)
1.embed_dim:最终输出的 K、Q、V 矩阵的维度,这个维度需要和词向量的维度一样
2.num_heads:设置多头注意力的数量。要求embed_dim%num_heads==0,即要能被embed_dim整除。这是为了把词的隐向量长度平分到每一组,这样多组注意力也能够放到一个矩阵里,从而并行计算多头注意力。
3.dropout:这个 dropout 加在 attention score 后面
例如,我们前面说到,8 组注意力可以得到 8 组 Z 矩阵,然后把这些矩阵拼接起来,得到最终的输出。
如果最终输出的每个词的向量维度是 512,那么每组注意力的向量维度应该是512/8=64 如果不能够整除,那么这些向量的长度就无法平均分配。
3.4.2 forward的输入(引出mask机制)
定义 MultiheadAttention 的对象后,调用forward时传入的参数如下。
forward(query, key, value, key_padding_mask=None, need_weights=True, attn_mask=None)
1.query:对应于 Query矩阵,形状是 (L,N,E) 。其中 L 是输出序列长度,N 是 batch size,E 是词向量的维度
2.key:对应于 Key 矩阵,形状是 (S,N,E) 。其中 S 是输入序列长度,N 是 batch size,E 是词向量的维度
3.value:对应于 Value 矩阵,形状是 (S,N,E) 。其中 S 是输入序列长度,N 是 batch size,E 是词向量的维度
下面重点介绍.key_padding_mask和attn_mask:
key_padding_mask:使padding部分softmax值为0,不影响后续计算
我们通常对一个mini_batch数据进行self -attention来计算, 而一个mini_batch数据是由多个不等长的句子组成的, 计算前要将所有句子进行补齐到统一长度,这个过程叫padding。(一般用0来进行填充,到每个批次最大序列长度或者模型的最大序列长度)
由于softmax函数: σ ( z ) i = e z i ∑ j = 1 K e z j \sigma (\mathbf {z} )_{i}={\frac {e^{z_{i}}}{\sum _{j=1}^{K}e^{z_{j}}}} σ(z)i=∑j=1Kezjezi
有 e 0 e^0 e0=1, 这样的话softmax中被padding的部分就参与了运算, 就等于是让无效的部分参与了运算, 会产生很大隐患, 这时就需要做一个mask让这些无效区域不参与运算, 我们一般给无效区域加一个很大的负数的偏置, 也就是: z i l l e g a l = z i l l e g a l + b i a s i l l e g a l z_{illegal} = z_{illegal} + bias_{illegal} zillegal=zillegal+biasillegal b i a s i l l e g a l → − ∞ bias_{illegal} \to -\infty biasillegal→−∞ e z i l l e g a l → 0 e^{z_{illegal}} \to 0 ezillegal→0
经过上式的 m a s k i n g masking masking我们使无效区域经过 s o f t m a x softmax softmax计算之后还几乎为 0 0 0, 这样就避免了无效区域参与计算.。
key_padding_mask = ByteTensor,非 0 元素对应的位置会被忽略
key_padding_mask =BoolTensor, True 对应的位置会被忽略
(如果 key_padding_mask对应是0、1张量,那么1表示mask,如果是布尔张量,则true表示mask)
key_padding_mask形状是 (N,S)。其中 N 是 batch size,S 是输入序列长度,里面的值是1或0。我们先取得key中有padding的位置,然后把mask里相应位置的数字设置为1,这样attention就会把key相应的部分变为"-inf". (为什么变为-inf参考https://blog.csdn.net/weixin_41811314/article/details/106804906)
5.attn_mask:表示不计算未来时序的信息。以机器翻译为例,Decoder的Self-Attention层只允许关注到输出序列中早于当前位置之前的单词,在Self-Attention分数经过Softmax层之前,屏蔽当前位置之后的位置。
attn_mask形状可以是 2D (L,S),或者 3D (N∗numheads,L,S)。其中 L 是输出序列长度,S 是输入序列长度,N 是 batch size。
attn_mask =ByteTensor,非 0 元素对应的位置会被忽略(不计算attention,不看这个词)
attn_mask =BoolTensor, True 对应的位置会被忽略
mask机制更具体内容可以参考Transformer相关——(7)Mask机制
3.4.3 forward的输出
解码(decoding )阶段的每一个时间步都输出一个翻译后的单词(以英语翻译为例)。
#实例化一个nn.MultiheadAttention
multihead_attn = nn.MultiheadAttention(embed_dim, num_heads)
attn_output, attn_output_weights = multihead_attn(query, key, value)
即输出是:
attn_output:即最终输出的的注意力Z,形状是为(L,N,E)。 L 是输出序列长度,N 是 batch size,E 是词向量的维度
attn_output_weights:注意力系数a。形状是 (N,L,S)
代码示例如下:
# nn.MultiheadAttention 输入第0维为length
# batch_size 为 64,有 12 个词,每个词的 Query 向量是 300 维
query = torch.rand(12,64,300)
# batch_size 为 64,有 10 个词,每个词的 Key 向量是 300 维
key = torch.rand(10,64,300)
# batch_size 为 64,有 10 个词,每个词的 Value 向量是 300 维
value= torch.rand(10,64,300)
embed_dim = 299
num_heads = 1
# 输出是 (attn_output, attn_output_weights)
multihead_attn = nn.MultiheadAttention(embed_dim, num_heads)
attn_output,attn_output_weights = multihead_attn(query, key, value)[0]
# output: torch.Size([12, 64, 300])
# batch_size 为 64,有 12 个词,每个词的向量是 300 维
print(attn_output.shape)
3.5 手动实现attention
def forward(self, query, key, value, mask=None):
bsz = query.shape[0]
Q = self.w_q(query)
K = self.w_k(key)
V = self.w_v(value)
1.#计算attention score
attention = torch.matmul(Q, K.permute(0, 1, 3, 2)) / self.scale
if mask isnotNone:
attention = attention.masked_fill(mask == 0, -1e10)# mask 不为空,那么就把 mask 为 0 的位置的 attention 分数设置为 -1e10
2.#计算上一步结果的最后一维做 softmax,再经过 dropout,得attention。
attention = self.do(torch.softmax(attention, dim=-1))
3.attention结果与V相乘,得到多头注意力的结果
# [64,6,12,10] * [64,6,10,50] = [64,6,12,50]
x = torch.matmul(attention, V)
4.转置x并拼接多头结果
x = x.permute(0, 2, 1, 3).contiguous()#转置
x = x.view(bsz, -1, self.n_heads * (self.hid_dim // self.n_heads))#拼接
x = self.fc(x)
return x
# batch_size 为 64,有 12 个词,每个词的 Query 向量是 300 维
query = torch.rand(64, 12, 300)
# batch_size 为 64,有 12 个词,每个词的 Key 向量是 300 维
key = torch.rand(64, 10, 300)
# batch_size 为 64,有 10 个词,每个词的 Value 向量是 300 维
value = torch.rand(64, 10, 300)
attention = MultiheadAttention(hid_dim=300, n_heads=6, dropout=0.1)
output = attention(query, key, value)
## output: torch.Size([64, 12, 300])
print(output.shape)
具体的多头注意力代码可以参考《Transformer源代码解释之PyTorch篇》
3.6 手动实现多头注意力
这部分解析见《Transformer代码解读(Pytorch)》
4. 图解transformer
阅读此部分也可以对照我翻译的另一篇文章《《The Annotated Transformer》翻译————注释和代码实现《Attention Is All You Need》》
4.1 自注意力模型的缺点及transformer的提出
虽然自注意力模型有很多优势,但是,要想真正取代循环神经网络,自注意力模型还需要解决如下问题:.
- 在计算自注意力时,没有考虑输入的位置信息,因此无法对序列进行建模;.
- 输入向量 T ,同时承担了Q、K、V三种角色,导致其不容易学习;
- 只考虑了两个输入序列单元之间的关系,无法建模多个输入序列单元之间更复杂的关系;
- 自注意力计算结果互斥,无法同时关注多个输入
2017 年,Google 提出了 Transformer 模型,综合解决了以上问题。Transformer也使用了用 Encoder-Decoder框架。为了提高模型能力,每个编码解码块不再是由RNN网络组成,而是由Self Attention+FFNN 的结构组成(前馈神经网络)。 从本质上讲,transformer是将序列转换为序列,所以叫这个名字。可以翻译为转换器,也有人叫变压器。
概括起来就是transformer使用了位置编码 ( P o s i t i o n a l E n c o d i n g ) (Positional Encoding) (PositionalEncoding)来理解语言的顺序, 使用自注意力机制和全连接层来进行计算。
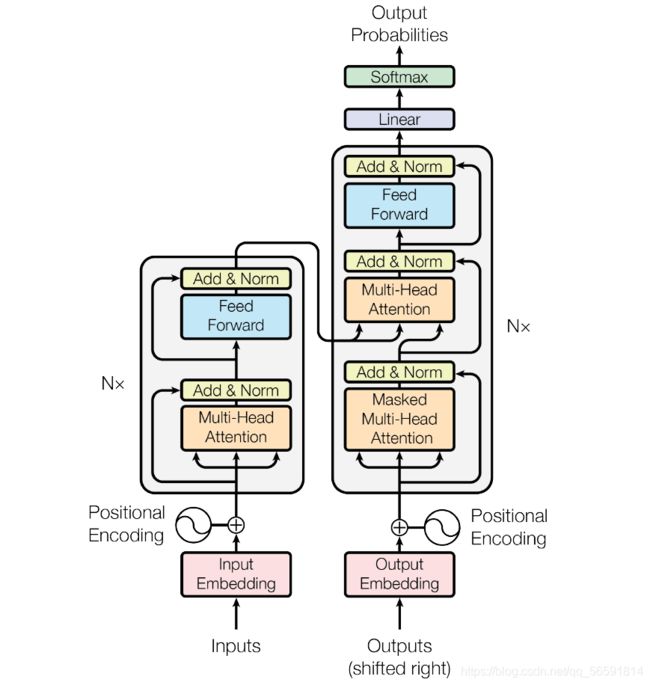
Transformer 可以拆分为 2 部分:左边是编码部分(encoding component),右边是解码部分(decoding component)。
4.2 transformer的改进
4.2.1 融入位置信息
为了解决Self-Attention词袋模型问题,除了词向量,还应该给输入向量引入不同的位置信息。有两种引人位置信息的方式:
1.位置嵌入( Position Embeddings ):与词嵌入类似,即为序列中每个绝对位置赋予一个连续、低维、稠密的向量表示。
2.位置编码( Position Encodings ):使用函数 f : N → R d f:\mathbb{N}\rightarrow \mathbb{R}^{d} f:N→Rd ,直接将一个整数(位置索引值)映射到一个 d 维向量上。映射公式为:
P o s E n c ( p , i ) = { s i n ( p 1000 0 i d ) c o s ( p 1000 0 i − 1 d ) } PosEnc(p,i)= \begin{Bmatrix} sin(\frac{p}{10000^{\frac{i}{d}}})\\ cos(\frac{p}{10000^{\frac{i-1}{d}}})\end{Bmatrix} PosEnc(p,i)={sin(10000dip)cos(10000di−1p)}
其中,p为序列中位置索引值,代表词的位置信息。d为位置向量的维度, 0 ⩽ i < d 0\leqslant i< d 0⩽i<d是位置编码向量中的索引值,即d维位置向量第i维。
在《The Annotated Transformer》中说道:我们还尝试使用位置嵌入(可学习的Position Embeddings(cite))来代替固定的位置编码,结果发现两种方法产生了几乎相同的效果。于是我们选择了正弦版本,因为它可以使模型外推到,比训练集序列更长的序列。(例如:当我们的模型需要翻译一个句子,而这个句子的长度大于训练集中所有句子的长度,这时,这种位置编码的方法也可以生成一样长的位置编码向量。)
注:在transformer中用的是位置编码,在bert中用的是位置嵌入。
class PositionalEncoding(nn.Module):
"Implement the PE function."
def __init__(self, d_model, dropout, max_len=5000):
super(PositionalEncoding, self).__init__()
self.dropout = nn.Dropout(p=dropout)
# Compute the positional encodings once in log space.
pe = torch.zeros(max_len, d_model)#序列位置编码初始化
position = torch.arange(0, max_len).unsqueeze(1)#unsqueeze表示在某一维增加一个dim=1的维度
div_term = torch.exp(torch.arange(0, d_model, 2) *
-(math.log(10000.0) / d_model))
pe[:, 0::2] = torch.sin(position * div_term)
pe[:, 1::2] = torch.cos(position * div_term)
pe = pe.unsqueeze(0)
self.register_buffer('pe', pe)
#embedding和位置编码的和再加一个dropout。对于基本模型,drop比例为0.1
def forward(self, x):
x = x + Variable(self.pe[:, :x.size(1)],
requires_grad=False)#位置编码维度和词embedding维度一致?
return self.dropout(x)
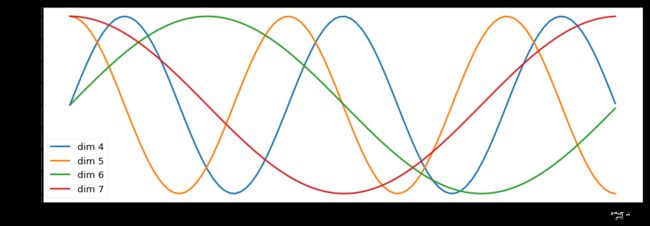
如下图,根据上述公式,我们可以得到第p位置的d维位置向量。下图中,我们画出了一种位置向量在第4、5、6、7维度、不同位置的的数值大小。横坐标表示位置下标,纵坐标表示数值大小。
plt.figure(figsize=(15, 5))
pe = PositionalEncoding(20, 0)
y = pe.forward(Variable(torch.zeros(1, 100, 20)))
plt.plot(np.arange(100), y[0, :, 4:8].data.numpy())
plt.legend(["dim %d"%p for p in [4,5,6,7]])
4.2.2 输入向量角色信息
原始的自注意力模型在计算注意力时,直接使用两个输入向量计算注意力系数a,然后使用得到的注意力对同一个输入向量加权,这样导致一个输入向量同时承担了三种角色:査询( Query )键( Key )和值( Value )。(见上面2.6节)
更好的做法是,对不同的角色使用不同的向量。即使用不同的参数矩阵对原始的输人向量做线性变换,从而让不同的变换结果承担不同的角色(qkv)。
4.2.3 多层自注意力(多层编码解码结构、FFNN、Norm+Add)
-
多层自注意力模型:通过堆叠多层自注意力模型,建模更多输入序列单元之间的高阶关系(类似于图模型中的消息传播机制( Message Propogation ))。原始的自注意力模型仅考虑的任意两个输人序列单元之间的关系。而如果直接建模高阶关系,会导致模型的复杂度过高。
-
FFNN层加入非线性损失函数,增强模型的表示能力。(注意力计算一般使用线性函数,只是简单的加权求和,只是线性变换)。如果将自注意力模型看作特征抽取器,那么FFNN就是最终的分类器。
-
为了使模型更容易学习,还可以使用层归一化( Layer Normalization )残差连接( Residual Connections )等深度学习的训练技巧。
这些都加在一起,叫Transformer块(Block)
4.2.4 多头自注意力( Multi - head Self - attention )
使用多头自注意力的好处:
-
多语义匹配
本身缩放点积注意力是没什么参数可以学习的,就是计算点积、softmax、加权和而已。但是使用Multi-head attention之后,投影到低维的权重矩阵 W Q W^Q WQ, W K W^K WK , W V W^V WV是可以学习的,而且有h=8次学习机会。使得模型可以在不同语义空间下学到不同的的语义表示,也扩展了模型关注不同位置的能力。类似卷积中多通道的感觉。
例如,“小明养了一只猫,它特别调皮可爱,他非常喜欢它”。“猫”从指代的角度看,与“它”的匹配度最高,但从属性的角度看,与“调皮”“可爱”的匹配度最高。标准的 Attention 模型无法处理这种多语义的情况 -
解决注意力结果互斥
自注意力结果需要经过softmax归一化,导致自注意力结果之间是互斥的,无法同时关注多个输人。 使用多组自注意力模型产生多组不同的注意力结果,则不同组注意力模型可能关注到不同的输入上,从而增强模型的表达能力。 -
相当于多个不同的自注意力模型的集成( Ensemble ),增强模型的效果。也类似卷积神经网络中的多个卷积核,抽取不同类型的特征。
具体来说,只需要设置多组映射矩阵即可。然后将产生的多个输出向量拼接,再乘以 W O W^O WO。映射回 d 维向量输入FFNN层。
4.3 Encoder
4.3.1 Encoder层结构
Encoder由多层编码器组成,每层编码器在结构上都是一样的,但不同层编码器的权重参数是不同的。每层编码器里面,主要由以下两部分组成:
1.Self-Attention Layer
2.Feed Forward Neural Network(前馈神经网络,缩写为 FFNN)
输入编码器的文本数据,首先会经过一个 Self Attention 层,这个层处理一个词的时候,不仅会使用这个词本身的信息,也会使用句子中其他词的信息(你可以类比为:当我们翻译一个词的时候,不仅会只关注当前的词,也会关注这个词的上下文的其他词的信息)。
接下来,Self Attention 层的输出会经过前馈神经网络FFNN。
Self-Attention模型的作用是提取语义级别的信息(不存在长距离依赖),而FFNN是在各个时序上对特征进行非线性变换,提高网络表达能力。
FFNN有两层,是将attention层输出先扩维4倍再降维。为什么这么做?神经网络中线性连接可以写成 d l = W l ⋅ x d^l=W^{l}\cdot x dl=Wl⋅x。其中三者维度分别是m×1、m×n、n×1。
- m>n:升维,将特征进行各种类型的特征组合,提高模型分辨能力
- m
更进一步讲解可以看GPT-2里的self-attention讲解。
4.3.2残差连接和标准化
编码器的每个子层(Self Attention 层和FFNN)都有一个Add&normalization层。如下如所示:

Add&normalization的意思是LayerNorm(X+Z)。即残差连接和标准化。
Add残差连接是 用到Shortcut 技术,解决深层网络训练时退化问题。具体解释可以看文章《Transformer相关——(5)残差模块》
LayerNorm 用于提高网络的训练速度,防止过拟合。具体可以参考《Transformer相关——(6)Normalization方式》
(再写下去感觉这篇文章绷不住了,太长抓不住主线)
4.3.3 Transformer-encoder结构梳理——数学表示.
经过前面部分的讲解,我们已经知道了很多知识点。下面用公式把一个 t r a n s f o r m e r b l o c k transformer \ block transformer block的计算过程整理一下:
1). 字向量与位置编码:
X = E m b e d d i n g L o o k u p ( X ) + P o s i t i o n a l E n c o d i n g (eq.2) X = EmbeddingLookup(X) + PositionalEncoding \tag{eq.2} X=EmbeddingLookup(X)+PositionalEncoding(eq.2) X ∈ R b a t c h s i z e ∗ s e q . l e n . ∗ e m b e d . d i m . X \in \mathbb{R}^{batch \ size \ * \ seq. \ len. \ * \ embed. \ dim.} X∈Rbatch size ∗ seq. len. ∗ embed. dim.
2). 自注意力机制:
Q = L i n e a r ( X ) = X W Q Q = Linear(X) = XW_{Q} Q=Linear(X)=XWQ K = L i n e a r ( X ) = X W K (eq.3) K = Linear(X) = XW_{K} \tag{eq.3} K=Linear(X)=XWK(eq.3) V = L i n e a r ( X ) = X W V V = Linear(X) = XW_{V} V=Linear(X)=XWV X a t t e n t i o n = S e l f A t t e n t i o n ( Q , K , V ) (eq.4) X_{attention} = SelfAttention(Q, \ K, \ V) \tag{eq.4} Xattention=SelfAttention(Q, K, V)(eq.4)
3). 残差连接与Layer Normalization: X a t t e n t i o n = X + d r o p o u t ( X a t t e n t i o n ) (eq.5) X_{attention} = X + dropout(X_{attention} )\tag{eq.5} Xattention=X+dropout(Xattention)(eq.5) X a t t e n t i o n = L a y e r N o r m ( X a t t e n t i o n ) (eq. 6) X_{attention} = LayerNorm(X_{attention}) \tag{eq. 6} Xattention=LayerNorm(Xattention)(eq. 6)
4). 下面进行 t r a n s f o r m e r b l o c k transformer \ block transformer block结构图中的第4部分, 也就是 F e e d F o r w a r d FeedForward FeedForward, 其实就是两层线性映射并用激活函数激活, 比如说 R e L U ReLU ReLU:
X h i d d e n = L i n e a r 2 ( d r o p o u t ( A c t i v a t e ( L i n e a r 1 ( X a t t e n t i o n ) ) ) ) (eq. 7) X_{hidden} = Linear_2(dropout(Activate(Linear_1(X_{attention})))) \tag{eq. 7} Xhidden=Linear2(dropout(Activate(Linear1(Xattention))))(eq. 7)
残差连接+Norm:
X h i d d e n = X a t t e n t i o n + X h i d d e n X_{hidden} = X_{attention} + X_{hidden} Xhidden=Xattention+Xhidden
X h i d d e n = L a y e r N o r m ( X h i d d e n ) X_{hidden} = LayerNorm(X_{hidden}) Xhidden=LayerNorm(Xhidden) X h i d d e n ∈ R b a t c h s i z e ∗ s e q . l e n . ∗ e m b e d . d i m . X_{hidden} \in \mathbb{R}^{batch \ size \ * \ seq. \ len. \ * \ embed. \ dim.} Xhidden∈Rbatch size ∗ seq. len. ∗ embed. dim.
encoder层前向传播代码表示为:
def forward(self, src: Tensor, src_mask: Optional[Tensor] = None, src_key_padding_mask: Optional[Tensor] = None) -> Tensor:
#attention层:
src = positional_encoding(src, src.shape[-1])
src2 = self.self_attn(src, src, src, attn_mask=src_mask,
key_padding_mask=src_key_padding_mask)[0]
src = src + self.dropout1(src2)
src = self.norm1(src)
#FFNN层:
src2 = self.linear2(self.dropout(self.activation(self.linear1(src))))
src = src + self.dropout2(src2)
src = self.norm2(src)
return src
4.4 Decoder(解码器)
解码器也具有这两层,但是这两层中间还插入了一个 Encoder-Decoder Attention 层。编码器输出最终向量,将会输入到每个解码器的Encoder-Decoder Attention层,用来帮解码器把注意力集中中输入序列的合适位置。
在解码器的子层里面也有层标准化(layer-normalization)。假设一个 Transformer 是由 2 层编码器和两层解码器组成的,如下图所示。
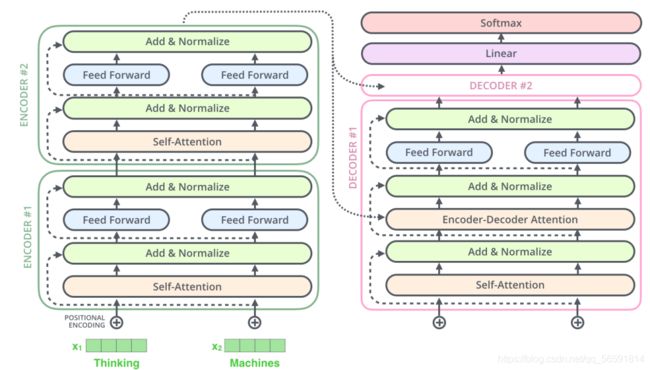
在完成了编码(encoding)阶段之后,我们开始解码(decoding)阶段。解码(decoding )阶段的每一个时间步都输出一个翻译后的单词。接下来会重复这个过程,直到输出一个结束符,Transformer 就完成了所有的输出。Decoder 就像 Encoder 那样,从下往上一层一层地输出结果,每一步的输出都会输入到下面的第一个解码器。和编码器的输入一样,我们把解码器的输入向量,也加上位置编码向量,来指示每个词的位置。
和编码器中的 Self Attention 层不太一样,在解码器里,Self Attention 层只允许关注到输出序列中早于当前位置之前的单词。具体做法是:在 Self Attention 分数经过 Softmax 层之前,屏蔽当前位置之后的那些位置。所以decoder-block的第一层应该叫masked -Self Attention。
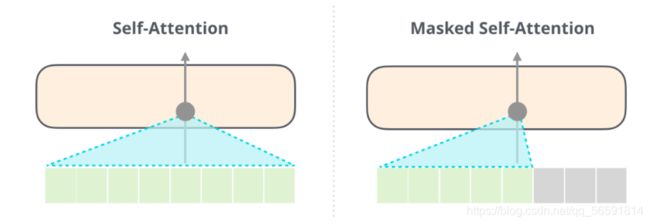
这个屏蔽(masking)经常用一个矩阵来实现,称为 attention mask。想象一下有 4 个单词的序列(例如,机器人必须遵守命令)。在一个语言建模场景中,这个序列会分为 4 个步骤处理–每个步骤处理一个词(假设现在每个词是一个 token)。由于这些模型是以 batch size 的形式工作的,我们可以假设这个玩具模型的 batch size 为 4,它会将整个序列作(包括 4 个步骤)为一个 batch 处理。

在矩阵的形式中,我们把 Query 矩阵和 Key 矩阵相乘来计算分数。让我们将其可视化如下,不同的是,我们不使用单词,而是使用与格子中单词对应的 Query 矩阵(或Key 矩阵)。
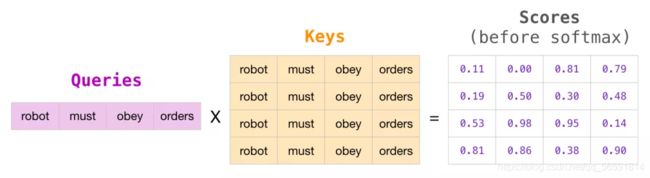
在做完乘法之后,我们加上一个下三角形的 attention mask矩阵。它将我们想要屏蔽的单元格设置为负无穷大或者一个非常大的负数(例如 GPT-2 中的 负十亿):

然后对每一行应用 softmax,会产生实际的分数,我们会将这些分数用于 Self Attention。

这个分数表的含义如下:
当模型处理数据集中的第 1 个数据(第 1 行),其中只包含着一个单词 (robot),它将 100% 的注意力集中在这个单词上。
当模型处理数据集中的第 2 个数据(第 2 行),其中包含着单词(robot must)。当模型处理单词 must,它将 48% 的注意力集中在 robot,将 52% 的注意力集中在 must。
诸如此类,继续处理后面的单词。在文末,会加一些更多关于mask 预训练模型的介绍。
Encoder-Decoder Attention层的原理和多头注意力(multiheaded Self Attention)机制类似,不同之处是:Encoder-Decoder Attention层是使用前一层的输出来构造 Query 矩阵,而 Key 矩阵和 Value 矩阵来自于编码器最终的输出。
所以encoder-decoder attention层可以使解码器在每个时间步,把注意力集中到输入序列中感兴趣的位置。比如英译中‘hello world’,解码器在输出‘好’的时候,解码器的输入q对'hello'的相似度应该是最高的,这样模型就将注意力主要集中在’hello’上,即生成单词时更关注源语言序列中更相关的词。(这就是attention如何在encoder传递信息到decoder时起到作用)
4.5 最后的线性层和 Softmax 层
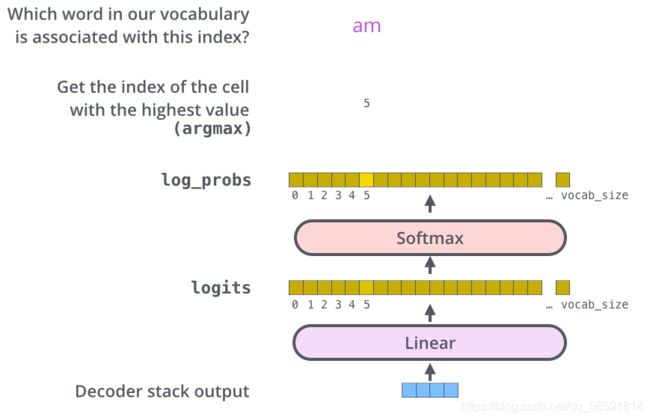
Decoder 最终的输出是一个向量,其中每个元素是浮点数。输出向量经过线性层(普通的全连接神经网络)映射为一个更长的向量,这个向量称为 logits 向量。
现在假设我们的模型有 10000 个英语单词(模型的输出词汇表),这些单词是从训练集中学到的。因此logits 向量有 10000 个数字,每个数表示一个单词的得分。经过Softmax 层归一化后转换为概率。概率值最大的词,就是这个时间步的输出单词。
Transformer 是深度学习的集大成之作,融合了多项实用技术,不仅在自然语言处理领域的许多问题中得到了应用,在计算机视觉、推荐系统等领域也得到了广泛应用。
但是Transformer也有一个缺点,就是参数量过大。三个角色映射矩阵、多头注意力机制,FFNN,以及多个block的堆叠,导致一个实用的Transformer含有巨大的参数量,模型变得不容易训练,尤其是数据集小的时候。基于这种情况,BERT应运而生。
4.6 Transformer 的输入
和通常的 NLP 任务一样,我们首先会使用词嵌入算法(embedding algorithm),将每个词转换为一个词向量。实际中向量一般是 256 或者 512 维。整个输入的句子是一个向量列表,其中有 n个词向量。
在实际中,每个句子的长度不一样,我们会取一个适当的值,作为向量列表的长度。如果一个句子达不到这个长度,那么就填充全为 0 的词向量;如果句子超出这个长度,则做截断。句子长度是一个超参数,通常是训练集中的句子的最大长度。
编码器中,每个位置的词都经过 Self Attention 层,得到的每个输出向量都单独经过前馈神经网络层,每个向量经过的前馈神经网络都是一样的。第一 个层 编码器的输入是词向量,而后面的编码器的输入是上一个编码器的输出。
5. Transformer 的训练过程
假设输出词汇只包含 6 个单词(“a”, “am”, “i”, “thanks”, “student”, and “”(“”表示句子末尾))。我们模型的输出词汇表,是在训练之前的数据预处理阶段构造的。当我们确定了输出词汇表,我们可以用向量来表示词汇表中的每个单词。这个表示方法也称为 one-hot encoding
5.1 损失函数
用一个简单的例子来说明训练过程,比如:把“merci”翻译为“thanks”。这意味着我们希望模型最终输出的概率分布,会指向单词 ”thanks“(在“thanks”这个词的概率最高)。但模型还没训练好,它输出的概率分布可能和我们希望的概率分布相差甚远。
由于模型的参数都是随机初始化的。模型在每个词输出的概率都是随机的。我们可以把这个概率和正确的输出概率做对比,然后使用反向传播来调整模型的权重,使得输出的概率分布更加接近正确输出。比较概率分布的差异可以用交叉熵。
在实际中,我们使用的句子不只有一个单词。例如–输入是:“je suis étudiant” ,输出是:“i am a student”。这意味着,我们的模型需要输出多个概率分布,满足如下条件:
每个概率分布都是一个向量,长度是 vocab_size(我们的例子中,向量长度是 6,但实际中更可能是 30000 或者 50000)
第一个概率分布中,最高概率对应的单词是 “i”
第二个概率分布中,最高概率对应的单词是 “am”
以此类推,直到第 5 个概率分布中,最高概率对应的单词是 “”,表示没有下一个单词了。
5.2 贪婪解码和集束搜索
贪婪解码(greedy decoding):模型每个时间步只产生一个输出,可以认为:模型是从概率分布中选择概率最大的词,并丢弃其他词。
集束搜索(beam search):每个时间步保留两个最高概率的输出词,然后在下一个时间步,重复执行这个过程:假设第一个位置概率最高的两个输出的词是”I“和”a“,这两个词都保留,然后根据第一个词计算第二个位置的词的概率分布,再取出 2 个概率最高的词,对于第二个位置和第三个位置,我们也重复这个过程。
在我们的例子中,beam_size 的值是 2(含义是:在所有时间步,我们保留两个最高概率),top_beams 的值也是 2(表示我们最终会返回两个翻译的结果)。beam_size 和 top_beams 都是你可以在实验中尝试的超参数。
2.4 从机器翻译推广到attention的一般模式
(本来不想写的,想到一个问题,还是把这节补了)
Attention不止是用来做机器翻译,甚至是不止用在NLP领域。换一个更一般点的例子,来说明Attention的一般模式。
比如有一个场景是家长带小孩取玩具店买玩具,用模型预测最后玩具是否会被购买。每个玩具有两类特征,1-形状颜色功能等,用来吸引孩子;第二类特征是加个、安全、益智性等,用来决定家长是否购买。
假设孩子喜好用特征向量q表示,玩具第一类特征用向量k表示,第二类特征用向量v表示,模型结果如下:
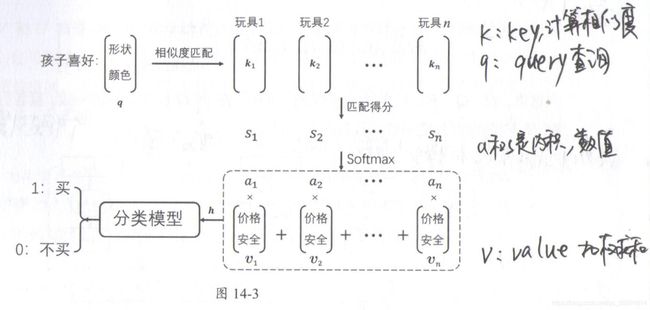
首先计算q和k的相似度 s 1 − s n s_{1}-s_{n} s1−sn,并归一化到 a 1 − a n a_{1}-a_{n} a1−an,a反映了孩子对玩具的喜好程度(权重)。接下来a对特征v进行加权求和(家长角度考虑),得到向量h。最后家长是否购买玩具是由向量h决定的。
上述过程就是Attention的标准操作流程。Attention模型三要素是 q 、 K 、 V q、K、 V q、K、V。 K 、 V K、 V K、V矩阵分别对应向量序列 k 1 k_1 k1到 k n k_n kn和 v 1 v_1 v1到 v n v_n vn。由于中间涉及到加权求和,所以这两个序列长度一致,而且元素都是对应的。即 k j k_j kj对应 v j v_j vj。但是k和v分别表示两类特征,所以向量长度可以不一致。
为了运算方便,可以将Attention操作计算为: h = A t t e n t i o n ( q 、 K 、 V ) h=Attention(q、K、 V) h=Attention(q、K、V)。q也可以是一个向量序列Q(对应机器翻译中输入多个单词),此时输出也是一个向量序列H。Attention通用标准公式为: H = A t t e n t i o n ( Q , K , V ) = [ A t t e n t i o n ( q 1 , K , V ) . . . A t t e n t i o n ( q m , K , V ) ] H=Attention(Q,K,V)=\begin{bmatrix} Attention(q_{1},K,V)\\ ...\\ Attention(q_{m},K,V)\end{bmatrix} H=Attention(Q,K,V)=⎣ ⎡Attention(q1,K,V)...Attention(qm,K,V)⎦ ⎤
这里, Q 、 K 、 V 、 H Q、K、 V、H Q、K、V、H均为矩阵(向量序列)。其中, H H H和 Q Q Q序列长度一致,各行一一对应(一个输入对应一个输出), K K K和 V V V序列长度一致,各行一一对应。
输出向量h会输入到前馈神经网络。在实际的代码实现中,Self Attention 的计算过程是使用矩阵来实现的,这样可以加速计算,一次就得到所有位置的输出向量。
6. 花式Mask预训练(我悟了)
本节选自苏剑林的文章:《从语言模型到Seq2Seq:Transformer如戏,全靠Mask》
篇幅太长,改到帖子《苏神文章解析(6篇)》
背景
从Bert、GPT到XLNet等等,各种应用transformer结构的模型不断涌现,有基于现成的模型做应用的,有试图更好地去解释和可视化这些模型的,还有改进架构、改进预训练方式等以得到更好结果的。总的来说,这些以预训练为基础的工作层出不穷,有种琳琅满目的感觉