项目实训第一周(车道线检测)
项目实训我主要负责计算机视觉方面,识别出车道线并据此导航。相关内容也更新在我的个人博客上个人网站
相关介绍
车道线检测如果用传统方法,识别速度较慢,效果不够好,容易受到多种因素的干扰,因此我们打算开发并使用深度学习的相关模型,看了许多相关的论文,得知有关SCNN,CNN等扩展模型的车道线检测效果很好,因此准备研究开发,训练测试相关的模型。
首先对于深度学习车道线相关检测,我初步决定采用pytorch或者tensorflow框架来进行模型的建立。
对于车道线检测方面,国际上有大量的研究和模型,我准备研读一下这其中的论文,采取其中的优劣,对其中的模型进行改进。首先我阅读了比较有名的LaneNet模型相关论文,并在Ubuntu下复现了该模型。LaneNet设计了多任务的网络,第一个任务是将背景和车道线进行区分,也就是语义分割。第二个任务则是进行区分不同的车道,从而对于车道线进行实例分割。而在这些任务做完后,需要进一步处理LaneNet输出的每个像素的集合(机器学习中聚类方法),在这里训练了H-Net模型来适应视角等变化进行拟合。
环境配置和代码复现
第一步我先配置了相关环境,python版本为3.5
glog==0.3.1
loguru==0.2.5
tensorflow_gpu==1.15.0
tqdm==4.28.1
matplotlib==2.2.4
opencv_contrib_python==4.2.0.32
numpy==1.16.4
scikit_learn==0.24.1
tensorflow==1.15.0
PyYAML==5.4.1
Python版本最好为3.5,其他版本没试过,安装tensorflow可能会爆出各种问题。可以到官网查看python,tensorflow的相关对应情况。
安装过程中有几个坑,tensorflow需要gpu版进行加速训练,因为我的训练集会较大。同时tenserflow的版本问题一定要注意,2.0版本和1.0版本有较大的区别。一定要注意1.0和2.0版本下使用函数的各种区别。
我pip install并没有找到1.15.0版本的tensorflow,应该换源,但是懒得换了直接用了tensorflow 1.14.0,实测可行。
代码分析和模型训练测试
LaneNet论文中呈现的主要的网络结构为
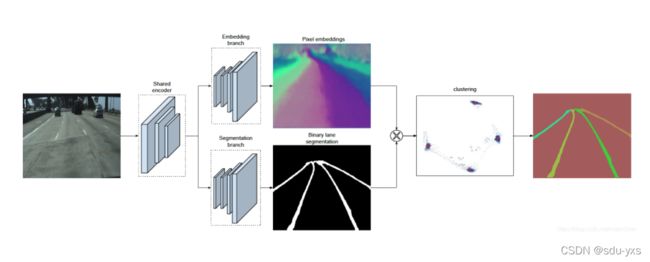
该网络为典型的编码-解码网络进行实例分割,作者提供的基础的编码网络为ENet网络,而复现的模型中使用了VGG16作为编码网络,主要呈现在源码中的lanenet_front_end.py和vgg16_based_fcn.py,解码网络主干为FCN,主要呈现在lanenet_back_end.py和vgg16_based_fcn.py中,这又分为两个分支,一个是嵌入分支,一个是分割分支.。
嵌入分支用于在该网络解码得到的输出图中每一个像素对应一个N维的向量,在该N维嵌入空间中同一车道线的像素距离更接近,而不同车道线的像素的向量距离较大,从而区分像素属于哪一条车道线,该分支使用基于one-hot的方法做距离度量学习
分割分支主要用于产生一个二分图,表明哪一部分为背景,哪一部分为车道线,由于正负样本不均衡,文中作者使用了bounded inverse class weighting方法来改变权重
在lanenet_back_end.py中关于计算嵌入分支和分割分支损失的主要源码如下:
##计算损失,两分支的损失
def compute_loss(self, binary_seg_logits, binary_label,
instance_seg_logits, instance_label,
name, reuse):
"""
compute lanenet loss
:param binary_seg_logits:
:param binary_label:
:param instance_seg_logits:
:param instance_label:
:param name:
:param reuse:
:return:
"""
## 代入到解码后预测的值和原来的label值,采用相应的损失计算方式
with tf.variable_scope(name_or_scope=name, reuse=reuse):
# calculate class weighted binary seg loss
with tf.variable_scope(name_or_scope='binary_seg'):
binary_label_onehot = tf.one_hot(
tf.reshape(
tf.cast(binary_label, tf.int32),
shape=[binary_label.get_shape().as_list()[0],
binary_label.get_shape().as_list()[1],
binary_label.get_shape().as_list()[2]]),
depth=self._class_nums,
axis=-1
)
binary_label_plain = tf.reshape(
binary_label,
shape=[binary_label.get_shape().as_list()[0] *
binary_label.get_shape().as_list()[1] *
binary_label.get_shape().as_list()[2] *
binary_label.get_shape().as_list()[3]])
unique_labels, unique_id, counts = tf.unique_with_counts(binary_label_plain)
counts = tf.cast(counts, tf.float32)
# 作者使用的权重计算方式
inverse_weights = tf.divide(
1.0,
tf.log(tf.add(tf.divide(counts, tf.reduce_sum(counts)), tf.constant(1.02)))
)
## 两分支的损失计算
if self._binary_loss_type == 'cross_entropy':
binary_segmenatation_loss = self._compute_class_weighted_cross_entropy_loss(
onehot_labels=binary_label_onehot,
logits=binary_seg_logits,
classes_weights=inverse_weights
)
elif self._binary_loss_type == 'focal':
binary_segmenatation_loss = self._multi_category_focal_loss(
onehot_labels=binary_label_onehot,
logits=binary_seg_logits,
classes_weights=inverse_weights
)
else:
raise NotImplementedError
# 计算加权后的seg损失
with tf.variable_scope(name_or_scope='instance_seg'):
pix_bn = self.layerbn(
inputdata=instance_seg_logits, is_training=self._is_training, name='pix_bn')
pix_relu = self.relu(inputdata=pix_bn, name='pix_relu')
pix_embedding = self.conv2d(
inputdata=pix_relu,
out_channel=self._embedding_dims,
kernel_size=1,
use_bias=False,
name='pix_embedding_conv'
)
pix_image_shape = (pix_embedding.get_shape().as_list()[1], pix_embedding.get_shape().as_list()[2])
instance_segmentation_loss, l_var, l_dist, l_reg = \
lanenet_discriminative_loss.discriminative_loss(
pix_embedding, instance_label, self._embedding_dims,
pix_image_shape, 0.5, 3.0, 1.0, 1.0, 0.001
)
l2_reg_loss = tf.constant(0.0, tf.float32)
for vv in tf.trainable_variables():
if 'bn' in vv.name or 'gn' in vv.name:
continue
else:
l2_reg_loss = tf.add(l2_reg_loss, tf.nn.l2_loss(vv))
l2_reg_loss *= 0.001
total_loss = binary_segmenatation_loss + instance_segmentation_loss + l2_reg_loss
ret = {
'total_loss': total_loss,
'binary_seg_logits': binary_seg_logits,
'instance_seg_logits': pix_embedding,
'binary_seg_loss': binary_segmenatation_loss,
'discriminative_loss': instance_segmentation_loss
}
return ret
做这两方面的工作是为了训练一个聚类网络,代码中采用的DBSCAN的模型。为了将车道线的像素聚类到所属的车道线上,实现实例分割。
聚类损失计算:
def discriminative_loss_single(
prediction,
correct_label,
feature_dim,
label_shape,
delta_v,
delta_d,
param_var,
param_dist,
param_reg):
"""
discriminative loss
:param prediction: inference of network
:param correct_label: instance label
:param feature_dim: feature dimension of prediction
:param label_shape: shape of label
:param delta_v: cut off variance distance
:param delta_d: cut off cluster distance
:param param_var: weight for intra cluster variance
:param param_dist: weight for inter cluster distances
:param param_reg: weight regularization
"""
# 像素对齐
correct_label = tf.reshape(
correct_label, [label_shape[1] * label_shape[0]]
)
reshaped_pred = tf.reshape(
prediction, [label_shape[1] * label_shape[0], feature_dim]
)
# 统计实例个数
unique_labels, unique_id, counts = tf.unique_with_counts(correct_label)
counts = tf.cast(counts, tf.float32)
num_instances = tf.size(unique_labels)
#计算pixel embedding均值向量
segmented_sum = tf.unsorted_segment_sum(
reshaped_pred, unique_id, num_instances)
mu = tf.div(segmented_sum, tf.reshape(counts, (-1, 1)))
mu_expand = tf.gather(mu, unique_id)
distance = tf.norm(tf.subtract(mu_expand, reshaped_pred), axis=1, ord=1)
distance = tf.subtract(distance, delta_v)
distance = tf.clip_by_value(distance, 0., distance)
distance = tf.square(distance)
# loss(var)
l_var = tf.unsorted_segment_sum(distance, unique_id, num_instances)
l_var = tf.div(l_var, counts)
l_var = tf.reduce_sum(l_var)
l_var = tf.divide(l_var, tf.cast(num_instances, tf.float32))
# loss(dist)
mu_interleaved_rep = tf.tile(mu, [num_instances, 1])
mu_band_rep = tf.tile(mu, [1, num_instances])
mu_band_rep = tf.reshape(
mu_band_rep,
(num_instances *
num_instances,
feature_dim))
mu_diff = tf.subtract(mu_band_rep, mu_interleaved_rep)
intermediate_tensor = tf.reduce_sum(tf.abs(mu_diff), axis=1)
zero_vector = tf.zeros(1, dtype=tf.float32)
bool_mask = tf.not_equal(intermediate_tensor, zero_vector)
mu_diff_bool = tf.boolean_mask(mu_diff, bool_mask)
mu_norm = tf.norm(mu_diff_bool, axis=1, ord=1)
mu_norm = tf.subtract(2. * delta_d, mu_norm)
mu_norm = tf.clip_by_value(mu_norm, 0., mu_norm)
mu_norm = tf.square(mu_norm)
l_dist = tf.reduce_mean(mu_norm)
l_reg = tf.reduce_mean(tf.norm(mu, axis=1, ord=1))
param_scale = 1.
l_var = param_var * l_var
l_dist = param_dist * l_dist
l_reg = param_reg * l_reg
loss = param_scale * (l_var + l_dist + l_reg)
return loss, l_var, l_dist, l_reg
最终可以得到属于车道线的像素,然采用H-Net和曲线拟合将车道线画出
当我把项目跑起来时并代入我自己制作的数据集在Google的Colab上进行训练时,发现LaneNet的一些问题:
1.训练过于慢,导致需要跑相当长的时间,训练时间和资源成本很大。
2.测试效果并不是很好,会出现很多的噪点,根据此,我运用了闭运算等方法进行处理,去掉相关的噪点,效果还是比较好的。
3.测试效果不够稳定,这也是该模型的一大缺点,聚类的方法应该会产生极大的不稳定性,而我的任务是增强这个模型的鲁棒性,使得在车道线导航过程中的
原图像:

预测的车道线:
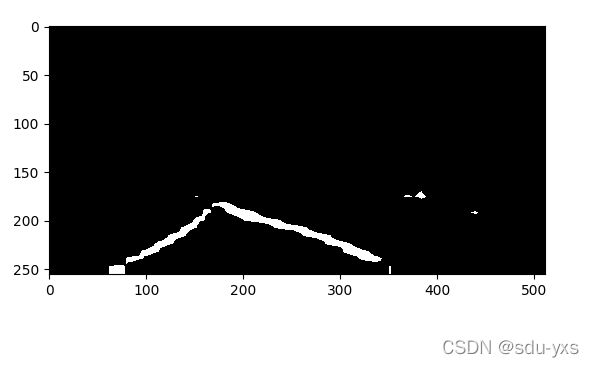
经过图像处理方法处理后的图像:
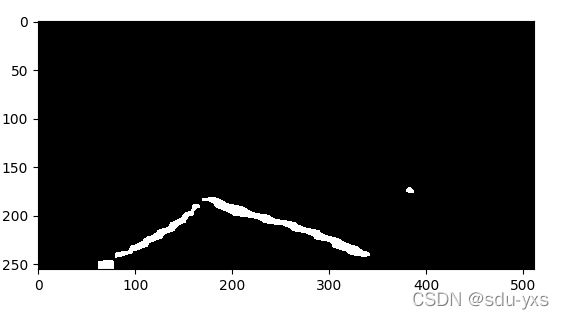
可以看出处理之后的效果还是可以的。同时我也测试了模型预测的时间,在我的虚拟机上,只用CPU,我预测一帧的时间是0.15s,这在速度30cm/s的小车上应该完全够用
下一周我计划查看最近当前国际上接近sota水平的模型的相关论文,同时改进LaneNet模型使得稳定性更高。我不仅仅需要考虑模型的正确性,还需要考虑预测时所要运行的时间,同时观测预测时要耗费的资源,得到最佳的模型。
以下还有几个问题没有解决:
1.小车的高度以及摄像头的高度是否可以调节,这将会是比较关键的一点。
2.摄像头成像的像素和一些参数。
3.是否可以提供训练的机器,预估单个GPU需要30小时左右。