[Gurobi] 简单模型的建立
特殊的Gurobi扩展对象 tuplelist和tupledict
在建模过程中,经常要对下标数据进行挑选,不同下标进行组合。这样面临着两种处理方法。
(1)全部循环,多维下标意味着多重循环 + if 条件
这样的处理方法没有效率
(2)采用特殊的Gurobi扩展对象TupleList 和 TupleDict
Python Tuple有着与列表类似,不同之处在于元组的元素不能修改
tuplelist,意思就是采取List容器,内容为Tuple类型
例如
Cites = [ (‘A’,‘B’) , (‘A’,‘C’) , (‘B’,‘C’) , (‘B’,‘D’) , (‘C’,‘D’)]
以这个为例,Cites表示两城市之间的连接
需要寻找以A城市开头的所有连接
全部循环方法:
![[Gurobi] 简单模型的建立_第1张图片](http://img.e-com-net.com/image/info8/69b6c8c4a7dc48709bedbf69deffaa37.png)
使用Gurobi TupleList 的 select 方法:
首先我们得需要引入Gurobi的扩展包,再使用select方法:
![[Gurobi] 简单模型的建立_第2张图片](http://img.e-com-net.com/image/info8/c7d81216a1784f9193f885775211cb6e.jpg)
最后我们可以看一下Spyder的类型显示:
![[Gurobi] 简单模型的建立_第3张图片](http://img.e-com-net.com/image/info8/abef53bd8f0341679380eddc4a7695f8.jpg)
而TupleDict意思就是,Dictionary的容器,不过键为Tuple类型

一个常用的函数multidict()创建 tuplelist 和 tupledict 的快捷方法
![[Gurobi] 简单模型的建立_第4张图片](http://img.e-com-net.com/image/info8/bffa56dd56344e1d92d64229e869c246.jpg)
其实也很容易看出来,cites的元素是键的值,supply是键加值的第一个元素,而demand是键加值的第二个元素
![[Gurobi] 简单模型的建立_第5张图片](http://img.e-com-net.com/image/info8/0e62d38aa25a4e15a0ff9fa5cdec0a6e.jpg)
Python 语法:创建list(列表解析 LIst Comprehension)
(1)
![]()
![]()
(2)
![]()
![]()
(3)
![]()
![]()
Python语法:Generator(生成器)

Gurobi中采取quicksum,效率更高
例如:
obj = quicksum(cost[i,j]*x[i,j] for i,j in arcs)
这个表达式有点像加法里面的∑
Gurobi 建模过程
![[Gurobi] 简单模型的建立_第6张图片](http://img.e-com-net.com/image/info8/def4a8f926ee4282b8f421d535b0c806.jpg)
教程里的第一个例子:
用Gurobi,导入扩展包
![]()
建立一个模型m
![]()
添加变量
![]()
3,4表示x是 3维 * 4维
vtype表示的是变量的类型:GRB.BINARY表示的是二进制
name为变量名
添加约束条件
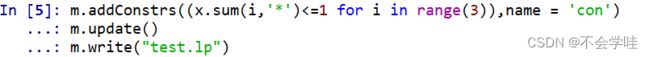
直接给写出文件内容吧:
![[Gurobi] 简单模型的建立_第7张图片](http://img.e-com-net.com/image/info8/781e175a22574452a1b8b484fbc5c11b.jpg)
Gurobi (gurobi的变量一般都是tupledict类型)的prod函数:用于变量与系数相乘后累加
下面两个表达式等效:(x 和 cost 要有相同的键值 )x是变量 cost是系数
obj = quicksum(cost[i,j] * x[i,j] for i,j in arcs)
obj = x.prod(cost)
具体建模过程
![[Gurobi] 简单模型的建立_第8张图片](http://img.e-com-net.com/image/info8/89884620021549ed89ced57079061d93.jpg)
m.Model()建立模型框架
![[Gurobi] 简单模型的建立_第9张图片](http://img.e-com-net.com/image/info8/1da88c8833e34c11b95be89a6fd46676.jpg)
添加变量
![[Gurobi] 简单模型的建立_第10张图片](http://img.e-com-net.com/image/info8/33e005fb10c44bfcb9e4165d23662db4.jpg)
设置目标函数
![[Gurobi] 简单模型的建立_第11张图片](http://img.e-com-net.com/image/info8/5edc06092c2d4a05bd8d8d1fee97cd54.jpg)
设置约束条件
![[Gurobi] 简单模型的建立_第12张图片](http://img.e-com-net.com/image/info8/5d9b64f3fb3943b499286ff63ec63a87.jpg)
设置下标的集合
![[Gurobi] 简单模型的建立_第13张图片](http://img.e-com-net.com/image/info8/6a6bd98477274a519bf1ab40f0ea4410.jpg)
对部分下表进行索引或者进行搜索
![[Gurobi] 简单模型的建立_第14张图片](http://img.e-com-net.com/image/info8/a9c6b7f52d9e438c9a3ff36f7be53a74.jpg)
进行加减乘除
![[Gurobi] 简单模型的建立_第15张图片](http://img.e-com-net.com/image/info8/4666d741cd8f45dd8dfa5f60570632ee.jpg)
比较符号
![[Gurobi] 简单模型的建立_第16张图片](http://img.e-com-net.com/image/info8/6f241933218448dfacf17a88c6f11427.jpg)
Gurobi 建模举例1
![[Gurobi] 简单模型的建立_第17张图片](http://img.e-com-net.com/image/info8/a73c23d01b2646b8888bc313fa80af6d.jpg)
# 导入gurobi包
from gurobipy import *
try:
# 创建一个新的模型
m = gurobipy.Model("class_1_1")
# 增添变量
x = m.addVar(vtype = GRB.BINARY,name ="x")
y = m.addVar(vtype = GRB.BINARY,name ="y")
z = m.addVar(vtype = GRB.BINARY,name ="z")
# 设置目标
m.setObjective(x + y +2*z,GRB.MAXIMIZE)
# 增加限制条件
m.addConstr(x + 2*y + 3*z <=4,"c0")
m.addConstr(x + y >= 1)
# 执行优化
m.optimize()
# 结果显示
# 查看变量取值
#变量名为VarName 变量值为X
for v in m.getVars():
print('%s %g' % (v.VarName, v.X))
#单查看目标函数值,用ObjVal
print('Obj: %g' % m.ObjVal)
except GurobiError as e:
print('Error code '+ str(e.errno) + ' : '+ str(e))
except AttributeError:
print('Encountered an attribute error')
Gurobi 建模举例2
![[Gurobi] 简单模型的建立_第18张图片](http://img.e-com-net.com/image/info8/47c7157cc34146fc845947722ef226d4.jpg)
营养吸收每天有上限和下限。
那么Gurobi的搜索形式可以为
营养种类可以用tuplelist存储
[‘calories’, ‘protein’, ‘fat’, ‘sodium’]
各个营养的每日摄入最小量可以采用tupledict存储
{‘calories’: 1800, ‘protein’: 91, ‘fat’: 0, ‘sodium’: 0}
各个营养的每日摄入最大量也采用tupledict存储
{‘calories’: 2200, ‘protein’: 1e+100, ‘fat’: 65, ‘sodium’: 1779}
此时我们便可以采用函数multidict函数
# 营养吸收每天有上下限
categories, minNutrition, maxNutrition = multidict({
'calories':[1800, 2200],
'protein':[91,GRB.INFINITY],
'fat':[0,65],
'sodium':[0,1779]
})
单位重量的食品价格不同
同理我们既想获得食品的列表,又同时想要获取该食品的价格,那么对于单位食品价格,也可以使用multidict函数
foods,cost = multidict({
'hamburger': 2.49,
'chicken': 2.89,
'hot dog': 1.50,
'fries': 1.89,
'macaroni': 2.09,
'pizza': 1.99,
'salad': 2.49,
'milk': 0.89,
'ice cream': 1.59
})

单位食品的不同营养成分不同
通过二维的键便可以表达
(‘食品’,‘营养类别’):成分含量;
nutritionValues = {
('hamburger', 'calories'): 410,
('hamburger', 'protein'): 24,
('hamburger', 'fat'): 26,
('hamburger', 'sodium'): 730,
('chicken', 'calories'): 420,
('chicken', 'protein'): 32,
('chicken', 'fat'): 10,
('chicken', 'sodium'): 1190,
('hot dog', 'calories'): 560,
('hot dog', 'protein'): 20,
('hot dog', 'fat'): 32,
('hot dog', 'sodium'): 1800,
('fries', 'calories'): 380,
('fries', 'protein'): 4,
('fries', 'fat'): 19,
('fries', 'sodium'): 270,
('macaroni', 'calories'): 320,
('macaroni', 'protein'): 12,
('macaroni', 'fat'): 10,
('macaroni', 'sodium'): 930,
('pizza', 'calories'): 320,
('pizza', 'protein'): 15,
('pizza', 'fat'): 12,
('pizza', 'sodium'): 820,
('salad', 'calories'): 320,
('salad', 'protein'): 31,
('salad', 'fat'): 12,
('salad', 'sodium'): 1230,
('milk', 'calories'): 100,
('milk', 'protein'): 8,
('milk', 'fat'): 2.5,
('milk', 'sodium'): 125,
('ice cream', 'calories'): 330,
('ice cream', 'protein'): 8,
('ice cream', 'fat'): 10,
('ice cream', 'sodium'): 180}
添加变量
变量应该是每种食品的购买的个数
buy = m.addVars(foods, name = “buy”)

![]()
buy的类别为tupledict,而key的类型为tuplelist。

解释一下,Awaiting model update,在添加完变量的时候,我们需要对模型进行更新

这样就没有了
字典是另一种可变容器模型,且可存储任意类型对象。
那么key为每种商品的名称,而value我们可以当作买该商品的数量

设置目标函数:花费的价格最少
m.setObjective(quicksum(cost[f]*buy[f] for f in foods),GRB.MINIMIZE)
这种写法比较容易理解
当下标相同的元素相乘时,可以用Gurobi的prod函数。
m.setObjective(cost.prod(buy), GRB.MINIMIZE)
设置约束条件:各个营养的每日摄入在上下限之间
m.addConstrs((quicksum(nutritionValues[f,c] * buy[f] for f in foods) == [minNutrition, maxNutrition] for c in categories),“con”)
结果显示
def PrintSolution():
if m.status == GRB.OPTIMAL:#如果求出最优解
print('Cost %g' % m.ObjVal)
for f in foods:
if buy[f].x > 0.0001:#这里得注意buy[f]得加.x表示其值
print('%s %g'%(f,buy[f].x))
else:
print('No solution')
PrintSolution()