pytorch 笔记:DDPG (datawhale 代码解读)
理论部分可见:强化学习笔记:双延时确定策略梯度 (TD3)_UQI-LIUWJ的博客-CSDN博客
源代码路径:easy-rl/codes/DDPG at master · datawhalechina/easy-rl (github.com)
1 task0.py
1.1 库导入
import sys,os
import datetime
import gym
import torch
from env import NormalizedActions,OUNoise
from ddpg import DDPG
from utils import save_results,make_dir
from utils import plot_rewards
curr_time = datetime.datetime.now().strftime("%Y%m%d-%H%M%S")
# 获取当前时间
curr_path = os.path.dirname(os.path.abspath(__file__))
# 当前文件所在绝对路径
1.2 Config 类——一些环境变量和算法变量的配置
class Config:
def __init__(self):
################################## 环境超参数 ###################################
self.algo_name = 'DDPG'
# 算法名称
self.env_name = 'Pendulum-v1'
# 环境名称,gym新版本(约0.21.0之后)中Pendulum-v0改为Pendulum-v1
self.device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
# 检测是否有GPU
self.seed = 10
# 随机种子,置0则不设置随机种子
self.train_eps = 300
# 训练的回合数(多少个episode)
self.test_eps = 20
# 测试的回合数(多少个episode)
################################################################################
################################## 算法超参数 ###################################
self.gamma = 0.99
# 折扣因子
self.critic_lr = 1e-3
# critic网络的学习率
self.actor_lr = 1e-4
# actor网络的学习率
self.memory_capacity = 8000
# 经验回放的容量
self.batch_size = 128
# mini-batch SGD中的批量大小(每一次从经验回放中提取多少的样本出来)
self.hidden_dim = 256
# 网络隐藏层维度
self.soft_tau = 1e-2
# 软更新参数
################################################################################
################################# 保存结果相关参数###############################
self.result_path = curr_path + "/outputs/" + self.env_name + '/' + curr_time + '/results/'
# 保存结果的路径
self.model_path = curr_path + "/outputs/" + self.env_name + '/' + curr_time + '/models/'
# 保存模型的路径
self.save = True
# 是否保存图片
################################################################################1.3 env_agent_config函数——设置环境和智能体
def env_agent_config(cfg,seed=1):
env0=gym.make(cfg.env_name)
'''
print(env0.observation_space)
print(env0.action_space)
Box([-1. -1. -8.], [1. 1. 8.], (3,), float32)
Box([-2.], [2.], (1,), float32)
'''
env = NormalizedActions(env0)
'''
print(env.observation_space)
print(env.action_space)
Box([-1. -1. -8.], [1. 1. 8.], (3,), float32)
Box([-2.], [2.], (1,), float32)
尚未调用action函数,所以封装前后目前是一样的
'''
env.seed(seed) # 随机种子
n_states = env.observation_space.shape[0] #3
n_actions = env.action_space.shape[0] #1
agent = DDPG(n_states,n_actions,cfg)
return env,agent1.4 train
def train(cfg, env, agent):
print('开始训练!')
print(f'环境:{cfg.env_name},算法:{cfg.algo_name},设备:{cfg.device}')
ou_noise = OUNoise(env.action_space)
# 动作噪声(OU噪声,相邻时间片的噪声满足AR(1))
rewards = []
# 记录所有回合的奖励
ma_rewards = []
# 记录所有回合的滑动平均奖励
for i_ep in range(cfg.train_eps):
state = env.reset()
#即observation
ou_noise.reset()
done = False
ep_reward = 0
i_step = 0
while not done:
i_step += 1
action = agent.choose_action(state)
#根据actor网络计算action
#注意:此时action的取值范围是[-1,1],因为tanh是最后一层的激活函数
action = ou_noise.get_action(action, i_step)
#添加了OU noise之后的action(OU noise 可以看成是一个ar(1)的noise)
#注意:此时action的取值范围虽然是[-2,2],但主体(去噪之后的信号)还是[-1,1]
#——>和action的实际取值范围还是有一定的出入
next_state, reward, done, _ = env.step(action)
#由于之前算出来的action是[-1,1](再往外伸出一点点)
#但实际的action范围是[-2,2],所以需要ActionWrapper来进行封装,使得action整体乘个2
#然后拿乘了2的action和环境做交互
ep_reward += reward
#这一个episode的reward
agent.memory.push(state, action, reward, next_state, done)
#将这一时刻的transition(st,at,rt,s_{t+1})存入经验回放中
agent.update()
#更新actor和critic的参数,同时对相应的目标网络进行软更新
state = next_state
if (i_ep+1)%10 == 0:
print('回合:{}/{},奖励:{:.2f}'.format(i_ep+1, cfg.train_eps, ep_reward))
#每10个episode 输出一次结果,这一个episode的累计奖励
rewards.append(ep_reward)
if ma_rewards:
ma_rewards.append(0.9*ma_rewards[-1]+0.1*ep_reward)
else:
ma_rewards.append(ep_reward)
#滑动平均奖励
print('完成训练!')
return rewards, ma_rewards
1.5 test
def test(cfg, env, agent):
#注意:测试的时候,就不用OU noise了,因为加噪声的目的只是为了让结果更robost
print('开始测试!')
print(f'环境:{cfg.env_name}, 算法:{cfg.algo_name}, 设备:{cfg.device}')
rewards = []
# 记录所有回合的奖励
ma_rewards = []
# 记录所有回合的滑动平均奖励
for i_ep in range(cfg.test_eps):
state = env.reset()
#即observation
done = False
ep_reward = 0
i_step = 0
while not done:
i_step += 1
action = agent.choose_action(state)
#根据actor网络计算action
#注意:此时action的取值范围是[-1,1],因为tanh是最后一层的激活函数
next_state, reward, done, _ = env.step(action)
#由于之前算出来的action是[-1,1]
#但实际的action范围是[-2,2],所以需要ActionWrapper来进行封装,使得action整体乘个2
#然后拿乘了2的action和环境做交互
ep_reward += reward
#这一个episode的reward
state = next_state
#测试的时候不用update的
rewards.append(ep_reward)
if ma_rewards:
ma_rewards.append(0.9*ma_rewards[-1]+0.1*ep_reward)
else:
ma_rewards.append(ep_reward)
#滑动平均奖励
print(f"回合:{i_ep+1}/{cfg.test_eps},奖励:{ep_reward:.1f}")
print('完成测试!')
return rewards, ma_rewards1. 6 main 函数部分
if __name__ == "__main__":
cfg = Config()
#初始化一些环境和算法变量
########################### 训练部分 ##################################
env,agent = env_agent_config(cfg,seed=1)
#配置环境和agent
#agent是DDPG
rewards, ma_rewards = train(cfg, env, agent)
#训练DDPG
make_dir(cfg.result_path, cfg.model_path)
#创建result的路径和model的路径
agent.save(path=cfg.model_path)
#由于决策的时候只需要actor,所以我们保存parameter的时候,只需要保存actor的参数即可
save_results(rewards, ma_rewards, tag='train', path=cfg.result_path)
#将训练的结果rewards和ma_rewards保存下来
plot_rewards(rewards, ma_rewards, cfg, tag="train")
#将训练的结果rewards和ma_rewards画出来,并保存
########################### 训练部分 ##################################
########################### 测试部分 ##################################
env,agent = env_agent_config(cfg,seed=10)
#换一个随机种子,生成一个环境
agent.load(path=cfg.model_path)
#将训练的actor参数load进来
rewards,ma_rewards = test(cfg,env,agent)
save_results(rewards,ma_rewards,tag = 'test',path = cfg.result_path)
#将测试的结果rewards和ma_rewards保存下来
plot_rewards(rewards, ma_rewards, cfg, tag="test")
#将测试的结果rewards和ma_rewards画出来,并保存
########################### 测试部分 ##################################
2 ddpg.py
2.1 导入库
import random
import numpy as np
import torch
import torch.nn as nn
import torch.optim as optim
import torch.nn.functional as F2.2 ReplayBuffer
class ReplayBuffer:
def __init__(self, capacity):
self.capacity = capacity # 经验回放的容量
self.buffer = [] # 缓冲区
self.position = 0
def push(self, state, action, reward, next_state, done):
''' 缓冲区是一个队列,容量超出时去掉开始存入的转移(transition)
'''
if len(self.buffer) < self.capacity:
self.buffer.append(None)
#如果经验回放没满的话,直接append,否则替代掉position时刻的经验回放
self.buffer[self.position] = (state, action, reward, next_state, done)
self.position = (self.position + 1) % self.capacity
def sample(self, batch_size):
batch = random.sample(self.buffer, batch_size)
# 随机采出一个batch的transition
state, action, reward, next_state, done = zip(*batch)
# 将这个batch里面的state, action, reward, next_state, done分别拼起来
#每一个是一个tuple
return state, action, reward, next_state, done
def __len__(self):
''' 返回当前存储的量
'''
return len(self.buffer)2.3 Actor
class Actor(nn.Module):
def __init__(self, n_states, n_actions, hidden_dim, init_w=3e-3):
super(Actor, self).__init__()
self.linear1 = nn.Linear(n_states, hidden_dim)
self.linear2 = nn.Linear(hidden_dim, hidden_dim)
self.linear3 = nn.Linear(hidden_dim, n_actions)
self.linear3.weight.data.uniform_(-init_w, init_w)
self.linear3.bias.data.uniform_(-init_w, init_w)
def forward(self, x):
x = F.relu(self.linear1(x))
x = F.relu(self.linear2(x))
x = torch.tanh(self.linear3(x))
return x
#[batch_size,3]——>[batch_size,1]2.4 Critic
class Critic(nn.Module):
def __init__(self, n_states, n_actions, hidden_dim, init_w=3e-3):
super(Critic, self).__init__()
self.linear1 = nn.Linear(n_states + n_actions, hidden_dim)
self.linear2 = nn.Linear(hidden_dim, hidden_dim)
self.linear3 = nn.Linear(hidden_dim, 1)
# 随机初始化为较小的值
self.linear3.weight.data.uniform_(-init_w, init_w)
self.linear3.bias.data.uniform_(-init_w, init_w)
def forward(self, state, action):
# 按维数1拼接
x = torch.cat([state, action], 1)
x = F.relu(self.linear1(x))
x = F.relu(self.linear2(x))
x = self.linear3(x)
return x
#[batch_size,3],[batch_size,1]——>[batch_size,1]2.5 DDPG
2.5.1 __init__
class DDPG:
def __init__(self, n_states, n_actions, cfg):
self.device = cfg.device
self.critic = Critic(n_states, n_actions, cfg.hidden_dim).to(cfg.device)
#critic——输入state和actor的输出(action),得到一个scalar
self.actor = Actor(n_states, n_actions, cfg.hidden_dim).to(cfg.device)
#actor——输入state,输出离散的action
self.target_critic = Critic(n_states, n_actions, cfg.hidden_dim).to(cfg.device)
self.target_actor = Actor(n_states, n_actions, cfg.hidden_dim).to(cfg.device)
#actor,critic以及对应的目标函数
for target_param, param in zip(self.target_critic.parameters(), self.critic.parameters()):
target_param.data.copy_(param.data)
for target_param, param in zip(self.target_actor.parameters(), self.actor.parameters()):
target_param.data.copy_(param.data)
# 初始化的时候,复制参数到目标网络
self.critic_optimizer = optim.Adam(self.critic.parameters(), lr=cfg.critic_lr)
self.actor_optimizer = optim.Adam(self.actor.parameters(), lr=cfg.actor_lr)
#actor和critic的优化器
self.memory = ReplayBuffer(cfg.memory_capacity)
#经验回放,一个数组
self.batch_size = cfg.batch_size
self.soft_tau = cfg.soft_tau
# 软更新参数
self.gamma = cfg.gamma
#折扣系数2.5.2 choose_action
def choose_action(self, state):
state = torch.FloatTensor(state).unsqueeze(0).to(self.device)
#一维Tensor (shape为[3])变成二维Tensor(shape为[1,3])
action = self.actor(state)
#[1,3]——>[1,1]
return action.detach().cpu().numpy()[0, 0]
#返回action对应的float
2.5.3 update
def update(self):
if len(self.memory) < self.batch_size:
return
# 当经验回放中transition的数量不满一个batch时,不更新策略
state, action, reward, next_state, done = self.memory.sample(self.batch_size)
# 从经验回放中(replay memory)中随机采样一个批量的转移(transition)
state = torch.FloatTensor(np.array(state)).to(self.device)
#[batch_size,3]
next_state = torch.FloatTensor(np.array(next_state)).to(self.device)
#[batch_size,3]
action = torch.FloatTensor(np.array(action)).to(self.device)
#[batch_size,1]
reward = torch.FloatTensor(reward).unsqueeze(1).to(self.device)
#[batch_size,1]
done = torch.FloatTensor(np.float32(done)).unsqueeze(1).to(self.device)
#[batch_size,1]
########################计算Actor的loss ############################
policy_loss = self.critic(state, self.actor(state))
#当前时刻的critic预测值
#[batch_size,1]
policy_loss = -policy_loss.mean()
#由于policy network是梯度上升,所以这里需要加一个负号
####################################################################
########################计算 Critic的TD loss########################
next_action = self.target_actor(next_state)
target_value = self.target_critic(next_state, next_action.detach())
#next action是target network的结果,所以不用梯度下降(不用更新参数),这里需要detach掉
expected_value = reward + (1.0 - done) * self.gamma * target_value
#如果这个episode还没有结束,那么就加上后面的target value
expected_value = torch.clamp(expected_value, -np.inf, np.inf)
#这两步是计算TD target
value = self.critic(state, action)
value_loss = nn.MSELoss()(value, expected_value.detach())
#TD loss
##################################################################
self.actor_optimizer.zero_grad()
policy_loss.backward()
self.actor_optimizer.step()
#更新actor
'''
可以发现这里用pytorch实现的时候 并没有按照DDPG公式那样计算两个内容的偏导,而是直接对policy_loss求导
因为actor_optimizer在初始化的时候,存进去的是self.actor.parameters()
所以进行zero_grad和step的时候,会自动计算这些系数(也就是θμ)的梯度,不用按照算法中实际公式那样地计算
'''
self.critic_optimizer.zero_grad()
value_loss.backward()
self.critic_optimizer.step()
#更新critic
for target_param, param in zip(self.target_critic.parameters(), self.critic.parameters()):
target_param.data.copy_(
target_param.data * (1.0 - self.soft_tau) +
param.data * self.soft_tau
)
#每一次training 软更新target_critic
for target_param, param in zip(self.target_actor.parameters(), self.actor.parameters()):
target_param.data.copy_(
target_param.data * (1.0 - self.soft_tau) +
param.data * self.soft_tau
)
#每一次training 软更新target_actor2.5.4 save & load
def save(self,path):
torch.save(self.actor.state_dict(), path+'checkpoint.pt')
#由于决策的时候只需要actor,所以我们保存parameter的时候,只需要保存actor的参数即可
def load(self,path):
self.actor.load_state_dict(torch.load(path+'checkpoint.pt')) 3 env.py
3.1 NormalizedActions
import gym
import numpy as np
class NormalizedActions(gym.ActionWrapper):
def action(self, action):
low_bound = self.action_space.low
upper_bound = self.action_space.high
action = low_bound + (action + 1.0) * 0.5 * (upper_bound - low_bound)
action = np.clip(action, low_bound, upper_bound)
#翻译一下,这边做的事情就是把action的数值乘个2,然后clip到action合理的数值内
return action
def reverse_action(self, action):
low_bound = self.action_space.low
upper_bound = self.action_space.high
action = 2 * (action - low_bound) / (upper_bound - low_bound) - 1
action = np.clip(action, low_bound, upper_bound)
return action3.2 OUNoise
class OUNoise(object):
'''Ornstein–Uhlenbeck噪声
'''
def __init__(self, action_space, mu=0.0, theta=0.15, max_sigma=0.3,\
min_sigma=0.3, decay_period=100000):
self.mu = mu
# OU噪声的参数(均值)
self.theta = theta
# OU噪声的参数(均值项的系数)
self.sigma = max_sigma
# OU噪声的参数(布朗运动项的系数)
self.max_sigma = max_sigma
self.min_sigma = min_sigma
self.decay_period = decay_period
self.n_actions = action_space.shape[0]
self.low = action_space.low
#2
self.high = action_space.high
#-2
self.reset()
def reset(self):
self.obs = np.ones(self.n_actions) * self.mu
def evolve_obs(self):
x = self.obs
dx = self.theta * (self.mu - x) + self.sigma * np.random.randn(self.n_actions)
#注:这里的OU noise中dt为1(Atari游戏的dt),所以看起来少了一项
#标准的OU noise中的dx,第一项要乘一个dt,第二项要乘一个sqrt(dt)
self.obs = x + dx
#更新OU noise (加上dx的部分)
return self.obs
def get_action(self, action, t=0):
ou_obs = self.evolve_obs()
#加了noise的action
self.sigma = self.max_sigma - (self.max_sigma - self.min_sigma) \
* min(1.0, t / self.decay_period)
# sigma会逐渐衰减,直到衰减到min_sigma
# 但这里默认max_sigma和min_sigma是一样大的,所以sigma这里是不会变化的
return np.clip(action + ou_obs, self.low, self.high)
# 动作加上噪声后进行剪切(在action合理的区间内)4 utils
4.1 导入库
import os
import numpy as np
from pathlib import Path
import matplotlib.pyplot as plt
import seaborn as sns4.2 make_dir
def make_dir(*paths):
''' 创建文件夹
'''
for path in paths:
Path(path).mkdir(parents=True, exist_ok=True)4.3 save_resulrs
def save_results(rewards, ma_rewards, tag='train', path='./results'):
''' 保存奖励
'''
np.save(path+'{}_rewards.npy'.format(tag), rewards)
np.save(path+'{}_ma_rewards.npy'.format(tag), ma_rewards)
print('结果保存完毕!')4.4 plot_rewards
def plot_rewards(rewards, ma_rewards, plot_cfg, tag='train'):
sns.set()
plt.figure()
plt.title("learning curve on {} of {} for {}".format(
plot_cfg.device, plot_cfg.algo_name, plot_cfg.env_name))
plt.xlabel('epsiodes')
plt.plot(rewards, label='rewards')
plt.plot(ma_rewards, label='ma rewards')
plt.legend()
if plot_cfg.save:
plt.savefig(plot_cfg.result_path+"{}_rewards_curve".format(tag))
plt.show()5 result
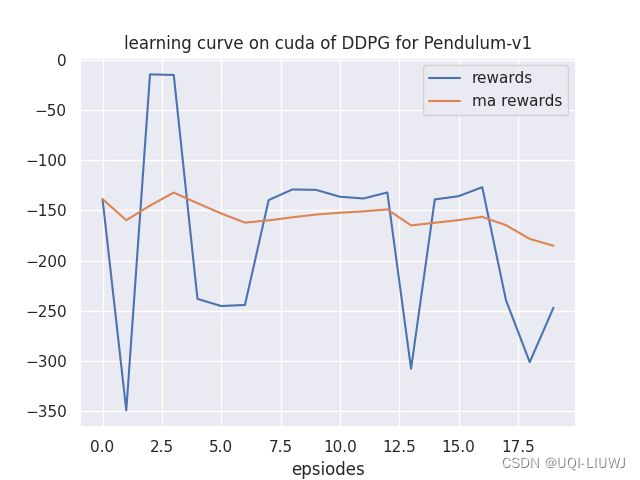
5.1 命令行输出部分
开始训练!
环境:Pendulum-v1,算法:DDPG,设备:cuda
回合:10/300,奖励:-769.95
回合:20/300,奖励:-245.85
回合:30/300,奖励:-359.45
...
回合:280/300,奖励:-731.29
回合:290/300,奖励:-256.56
回合:300/300,奖励:-883.17
完成训练!
结果保存完毕!
开始测试!
环境:Pendulum-v1, 算法:DDPG, 设备:cuda
回合:1/20,奖励:-138.7
回合:2/20,奖励:-349.4
回合:3/20,奖励:-14.5
...
回合:18/20,奖励:-239.6
回合:19/20,奖励:-301.3
回合:20/20,奖励:-247.0
完成测试!
结果保存完毕!5.2 绘图部分