RNN循环神经网络(吴恩达《序列模型》笔记一)
1、为什么选择序列模型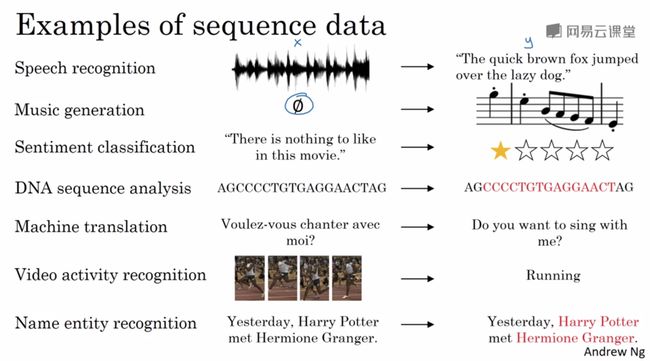
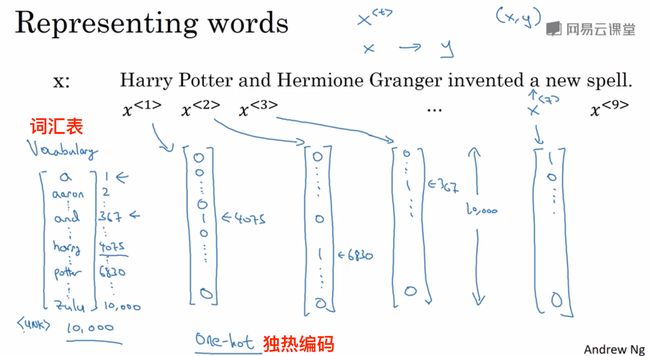
2、数学符号
用1来代表人名,0来代表非人名,句子x便可以用y=[1 1 0 1 1 0 0 0 0]来表示

3、循环网络模型

值得一提的是,共享特征还有助于减少神经网络中的参数数量,一定程度上减小了模型的计算复杂度。
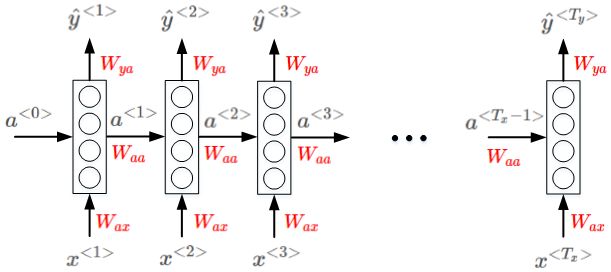
RNN模型包含三类权重系数,分别是Wax,Waa,Wya。
优点:不同元素之间同一位置共享同一权重系数。
缺点:它只使用了这个序列中之前的信息来做出预测。比如作出预测y<3>的时候没有用到之后x<4> 、x<5>的信息。
4、正向传播

简化RNN标记

5、反向传播
6、循环神经网络的其他结构
吴恩达参考的论文《The Unreasonable Effectiveness of Recurrent Neural Networks》
- many-to-many :Name entity recognition、Machine translation
- many-to-one : Sentiment Classification
- one-to-one : 之前学习的网络
- one-to-many : Music generation

7、构建语言模型
在单词表中对句子中的每个单词进行one-hot编码,句子结尾用< EOS >进行编码,如果有不在单词表中的单词出现,用< UNK >进行编码。

输入a<0>和x<1>都是零向量,用softmax输出预测值y^ <1>代表第一个词可能是词汇表中每个词的概率p(a)、p(an)、p(be)…p(< unk>)、p(< EOS>),接下来x<2>等于真实值y<1>:cats作为输入,得到预测值y^ <2>代表在第一个词是cats的情况下第二个词可能是词汇表中每个词的概率p(a|cats)、p(an|cats)、p(be|cats)…p(< unk>|cats)、p(< EOS>|cats)。
最后这句话是“cats average 15 hours of sleep a day.< EOS>”的的概率p(y<1>,y<2>,···y<9>)可以用条件概率公式计算得到。
对语料库的每条语句进行RNN模型训练,最终得到的模型可以根据给出语句的前几个单词预测其余部分,将语句补充完整。例如给出“Cats average 15”,RNN模型可能预测完整的语句是“Cats average 15 hours of sleep a day.”。

7、对新序列进行采样
利用训练好的RNN语言模型,可以进行新的序列采样,从而随机产生新的语句。
 基于字符的语言模型
基于字符的语言模型
优点:不会出现不在词汇表中的单词
缺点:会得到太多太长的序列

8、RNN中的梯度消失
RNN缺点:不擅长处理长期依赖
语句中可能存在跨度很大的依赖关系,即某个单词可能与它距离较远的某个单词具有强依赖关系。例如下面这两条语句:
- The
cat, which already ate fish,wasfull. - The
cats, which already ate fish,werefull.
由于跨度很大,普通的RNN网络容易出现梯度消失,捕捉不到它们之间的依赖,造成语法错误。
另一方面,RNN也可能出现梯度爆炸的问题,即gradient过大。常用的解决办法是设定一个阈值,一旦梯度最大值达到这个阈值,就对整个梯度向量进行尺度缩小。这种做法被称为梯度修剪(gradient clipping)。
9、门控制循环单元(GRU)
门控制循环单元(Gated Recurrent Unit):有效解决梯度消失问题,使RNN能捕获更长的依赖。
RNN的隐层单元结构如下:

其中a< t >的表达式为:
![]()
为解决上述问题,对上述单元进行修改,增加了记忆单元C:memory cell,提供了记忆功能,GRU单元如下所示:

相关公式如下:

Γu意为update gate,更新门,是一个从0到1的数字。当Γu=1时,代表更新;当Γu=0时,代表记忆,保留之前的模块输出。
比如:The cat, which already ate…,was full.
在cat处会产生一个c< t > 将猫是单数的信息传播到was处的Γu中,根据公式第三行,如果此时计算出来的Γu=0,则c< t >=c< t -1>不进行更新,谓词为was,如果Γu=1,则c< t >=c~< t >谓词更新为were。
由于Γu 使用了sigma激活函数,这个激活函数的特点是对于大部分输入的数来说,其对应的函数值都接近零,这样就能很大程度的保留之前的信息,这样就能很好的解决梯度消失的问题。
这一点跟CNN中的ResNets的作用有点类似。因此,Γu能够保证RNN模型中跨度很大的依赖关系不受影响,消除梯度消失问题。
上面介绍的是简化的GRU模型,完整的GRU添加了另外一个gate,即Γr,这个 Γr 告诉计算出的下一个c< t >的候选值跟c< t-1 >有多大的相关性。
表达式如下:

GRU特点:模型简单,计算速度快,易于构建大规模神经网络,出现在LSTM之后,现在逐渐在被人们采用。
10、长短期记忆(LSTM)
Long Short Term Memory甚至比GRU更加高效,对应的RNN隐层结构如图所示:

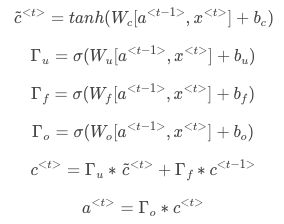
如果考虑c
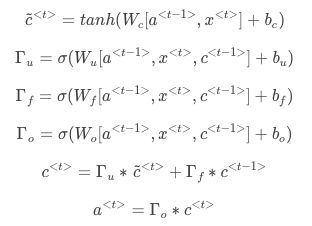
GRU可以看成是简化的LSTM,两种方法都具有各自的优势。
11、双向循环网络(BRNN)
Bidirectional RNN:这个模型可以让你在序列的某点处,不仅可以获取之前的信息,还可以获取未来的信息。每个单元可以采用GRU或LSTM结构。BRNN的结构图如下:

这样网络就构成了无环图Acyclic graph:给定一个输入序列x^<1> 到 x^<3>, 这个序列首先计算前向的a^<1> 、a^<2>、 a^<3>, 而反向序列由a^<3> 开始计算到a^<1>,把这些所有激活值计算完后就可以计算预测结果了,比如下面的计算公式:
![]()
BRNN缺点:需要完整的数据的序列,才能预测任意位置。
比如:语音识别中,需要人完整的说完话,然后获取整段语音,才能处理这段语音进行识别。
12、深度循环网络(DRNN)
Deep RNN:当需要解决很复杂的问题时,可以将上面的一些RNN进行整合形成DRNN。
三层深度循环网络的结构示意图如下,其中 []:表示层数,<>:表示时间序
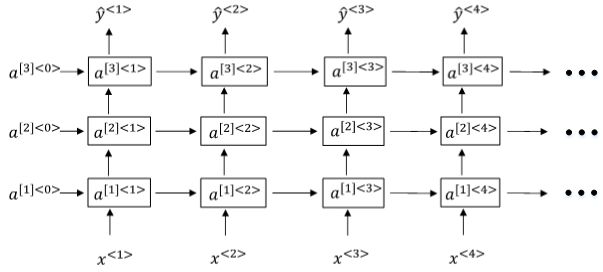
某个单元激活值的计算方式如下:
![]()
我们知道DNN层数可达100多,而Deep RNNs一般没有那么多层,3层RNNs已经较复杂了。
另外一种比较常用的Deep RNNs结构是每个输出层上还有一些垂直单元,如下图所示:

同样,每个单元可以是RNN、GRU、LSTM、BRNN。