lstm和gru
深度学习 , 自然语言处理 (Deep Learning, Natural Language Processing)
In my last article, I have introduced Recurrent Neural Networks and the complications it carries. To combat the drawbacks we use LSTMs & GRUs.
在上一篇文章中,我介绍了递归神经网络及其带来的复杂性。 为了克服这些缺点,我们使用LSTM和GRU。
障碍,短期记忆 (The obstacle, Short-term Memory)
Recurrent Neural Networks are confined to short-term memory. If a long sequence is fed to the network, they’ll have a hard time remembering the information and might as well leave out important information from the beginning.
递归神经网络仅限于短期记忆。 如果将较长的时间馈入网络,他们将很难记住信息,并且一开始可能会遗漏重要的信息。
Besides, Recurrent Neural Networks faces Vanishing Gradient Problem when backpropagation comes into play. Due to the conflict, the updated gradients are much smaller leaving no change in our model and thus not contributing much in learning.
此外,当反向传播起作用时,递归神经网络将面临消失梯度问题。 由于存在冲突,更新后的梯度要小得多,因此我们的模型没有任何变化,因此对学习没有太大贡献。

“When we perform backpropagation, we calculate weights and biases for each node. But, if the improvements in the former layers are meager then the adjustment to the current layer will be much smaller. This causes gradients to dramatically diminish and thus leading to almost NULL changes in our model and due to that our model is no longer learning and no longer improving.”
“当我们进行反向传播时,我们将计算每个节点的权重和偏差。 但是,如果前几层的改进很少,那么对当前层的调整将小得多。 这将导致梯度急剧减小,从而导致我们的模型几乎为NULL更改,并且由于我们的模型不再学习并且不再改进。”
为什么选择LSTM和GRU? (Why LSTMs and GRUs?)
Let us say, you’re looking at reviews for Schitt’s Creek online to determine if you could watch it or not. The basic approach will be to read the review and determine its sentiments.
让我们说,您正在在线查看Schitt's Creek的评论,以确定是否可以观看。 基本方法是阅读评论并确定其观点。

When you look for the review, your subconscious mind will try to remember decisive keywords. You will try to remember more weighted words like “Aaaaastonishing”, “timeless”, “incredible”, “eccentric”, and “capricious” and will not focus on regular words like “think”, “exactly”, “most” etc.
当您寻找评论时,您的潜意识将设法记住决定性的关键字。 您将尝试记住更重的单词,例如“ Aaaaastonishing”,“永恒”,“令人难以置信”,“古怪”和“任性”,而不会专注于常规单词,例如“思考”,“完全”,“多数”等。
The next time you’ll be asked to recall the review, you probably will be having a hard time, but, I bet you must remember the sentiment and few important and decisive words as mentioned above.
下次要求您回顾该评论时,您可能会遇到困难,但是,我敢打赌,您必须记住上述观点以及很少提及的重要和决定性的词语。

And that’s what exactly LSTM and GRU are intended to operate.
这正是LSTM和GRU的确切目标。
Learn and Remember only important information and forget every other stuff.
仅学习和记住重要信息,而忘记其他所有内容。
LSTM(长期短期记忆) (LSTM (Long short term memory))
LSTMs are a progressive form of vanilla RNN that were introduced to combat its shortcomings. To implement the above-mentioned intuition and administer the significant information due to finite-sized state vector in RNN we employ selectively read, write, and forget gates.
LSTM是香草RNN的进步形式,旨在克服其缺点。 为了实现上述直觉并由于RNN中有限大小的状态向量而管理重要信息,我们采用选择性的读,写和遗忘门。

The abstract concept revolves around cell states and various gates. The cell state can transfer relative information to the sequence chain and is capable of carrying relevant information throughout the computation thus solving the problem of Short-term memory. As the process continues, the more relevant information is added and removed via gates. Gates are special types of neural networks that learn about relevant information during training.
抽象概念围绕着细胞状态和各种门。 单元状态可以将相对信息传递到序列链,并且能够在整个计算过程中携带相关信息,从而解决了短期记忆的问题。 随着过程的继续,将通过门添加和删除更相关的信息。 闸门是特殊类型的神经网络,可在训练过程中了解相关信息。
选择性写 (Selective Write)
Let us assume, the hidden state (sₜ), previous hidden state (sₜ₋₁), current input (xₜ), and bias (b).
让我们假设隐藏状态( sₜ ),先前的隐藏状态( sₜ₋₁ ),当前输入( xₜ )和偏置( b )。

Now, we are accumulating all the outputs from previous state sₜ₋₁ and computing output for current state sₜ
现在,我们将累加先前状态sₜ₋₁的所有输出,并计算当前状态s output的输出

Using Selective Write, we are interested in only passing on the relevant information to the next state sₜ. To implement the strategy we could assign a value ranging from 0 to 1 to each input to determine how much information is to be passed on to the next hidden state.
使用选择性写入,我们只希望将相关信息传递到下一个状态sₜ。 为了实现该策略,我们可以为每个输入分配一个介于0到1之间的值,以确定将多少信息传递给下一个隐藏状态。

We can store the fraction of information to be passed on in a vector hₜ₋₁ that can be computed by multiplying previous state vector sₜ₋₁ and oₜ₋₁ that stores the value between 0 and 1 for each input.
我们可以存储的信息的部分,以在一个矢量hₜ₋₁吨帽子被传递可以通过以前的状态向量sₜ₋₁相乘并oₜ₋₁,存储0和1之间的值对每个输入进行计算。
The next issue we encounter is, how to get oₜ₋₁?
我们遇到的下一个问题是,如何获得oₜ₋₁?
To compute oₜ₋₁ we must learn it and the only vectors that we have control on, are our parameters. So, to continue computation, we need to express oₜ₋₁ in the form of parameters.
要计算oₜ₋₁,我们必须学习它,而我们唯一可以控制的向量就是我们的参数。 因此,要继续计算,我们需要以参数的形式表示oₜ₋₁ 。
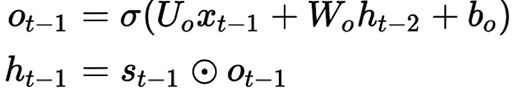
After learning Uo, Wo, and Bo using Gradient Descent, we can expect a precise prediction using our output gate (oₜ₋₁) that is controlling how much information will be passed to the next gate.
在使用梯度下降学习了Uo,Wo和Bo之后 ,我们可以期望使用输出门( oₜ₋₁ )进行精确的预测,该输出门控制将多少信息传递到下一个门。
选择性阅读 (Selective Read)
After passing the relevant information from the previous gate, we introduce a new hidden state vector Šₜ (marked in green).
从前一门传递了相关信息之后,我们引入了一个新的隐藏状态向量Šₜ (标记为绿色)。

Šₜ captures all the information from the previous state hₜ₋₁ and the current input xₜ.
Šₜ捕获先前状态hₜ₋₁和当前输入xₜ的所有信息。

But, our goal is to remove as much unimportant stuff as possible and to continue with our idea we will selectively read from the Šₜ to construct a new cell stage.
但是,我们的目标是尽可能多地删除不重要的内容,并继续我们的想法,我们将选择性地从Šₜ中读取内容以构建一个新的细胞阶段。
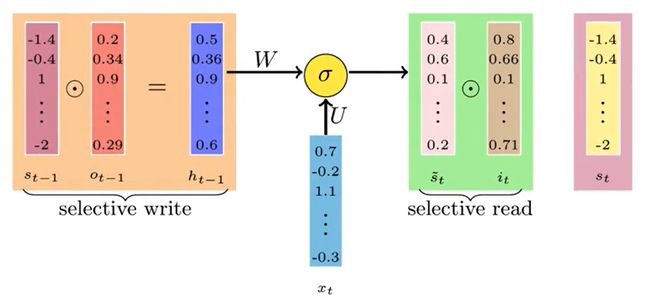
To store all-important pieces of content, we will again roll back to 0–1 strategy where we will assign a value between 0–1 to each input defining the proportion that we will like to read.
要存储所有重要的内容,我们将再次回滚到0–1策略,在该策略中,我们将为每个输入分配介于0–1之间的值,以定义我们希望读取的比例。
Vector iₜ will store the proportional value for each input that will later be multiplied with Šₜ to control the information flowing through current input, which is called the Input Gate.
向量iₜ将存储每个输入的比例值,以后将与Šₜ相乘以控制流经当前输入的信息,这称为输入门。
To compute iₜ we must learn it and the only vectors that we have control on are our parameters. So, to continue computation, we need to express iₜ in the form of parameters.
要计算iₜ,我们必须学习它,而我们唯一可以控制的向量就是我们的参数。 因此,要继续计算,我们需要的参数的形式来表达iₜ。
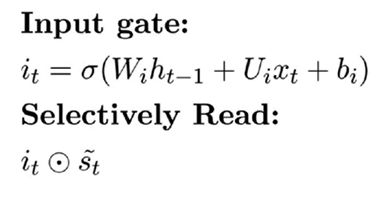
After learning Ui, Wi, and Bi using Gradient Descent, we can expect a precise prediction using our input gate (iₜ) that is controlling how much information will be catered to our model.
在使用梯度下降学习Ui,Wi和Bi之后 ,我们可以期望使用输入门( iₜ )进行精确的预测,该输入门将控制将要满足我们模型的信息量。
Summing up the parameters that were learned till now:
总结到目前为止所学的参数:

有选择地忘记 (Selectively Forget)
After selectively reading and writing the information, now we are aiming to forget all the irrelevant stuff that could help us to cut the clutter.
在选择性地读取和写入信息之后,现在我们的目标是忘记所有可以帮助我们减少混乱的无关紧要的东西。
To discard all the squandered information from sₜ₋₁ we use Forget gate fₜ.
为了丢弃sₜ₋₁中所有浪费的信息,我们使用“忘记门” fₜ。

Following the above-mentioned tradition, we will introduce forget gate fₜ that will constitute a value ranging from 0 to 1 which will be used to determine the importance of each input.
遵循上述传统,我们将引入遗忘门fₜ ,它将构成一个介于0到1之间的值,该值将用于确定每个输入的重要性。
To compute fₜ we must learn it and the only vectors that we have control on are our parameters. So, to continue computation, we need to express fₜ in form of provided parameters.
要计算fₜ,我们必须学习它,而我们唯一可以控制的向量就是我们的参数。 因此,要继续计算,我们需要以提供的参数的形式表示fₜ 。

After learning Uf, Wf, and Bf using Gradient Descent, we can expect a precise prediction using our forget gate (fₜ) that is controlling how much information will be discarded.
在使用梯度下降学习了Uf,Wf和Bf之后 ,我们可以期望使用我们的遗忘门( f a )进行精确的预测,该遗忘门控制着将丢弃多少信息。
Summing up information from forgetting gate and input gate will impart us about current hidden state information.
从忘记门和输入门中总结信息将为我们提供有关当前隐藏状态信息的信息。

最终模型 (Final Model)

The full set of equations looks like:
全套方程看起来像:

The parameters required in LSTM are way more than that required in vanilla RNN.
LSTM中所需的参数远远超出了香草RNN中所需的参数。

Due to the large variation of the number of gates and their arrangements, LSTM can have many types.
由于门数量及其排列方式的巨大差异,LSTM可以具有多种类型。
GRU(门控循环单位) (GRUs (Gated Recurrent Units))
As mentioned earlier, LSTM can have many variations and GRU is one of them. Unlikely LSTM, GRU tries to implement fewer gates and thus helps to lower down the computational cost.
如前所述,LSTM可以有多种变体,GRU就是其中之一。 与LSTM不同,GRU尝试实现较少的门,从而有助于降低计算成本。
In Gated Recurrent Units, we have an output gate that controls the proportion of information that will be passed to the next hidden state, besides, we have an input gate that controls information flow from current input and unlike RNN we don’t use forget gates.
在门控循环单元中,我们有一个输出门来控制将传递到下一个隐藏状态的信息的比例,此外,我们还有一个输入门来控制来自当前输入的信息流,与RNN不同,我们不使用忘记门。
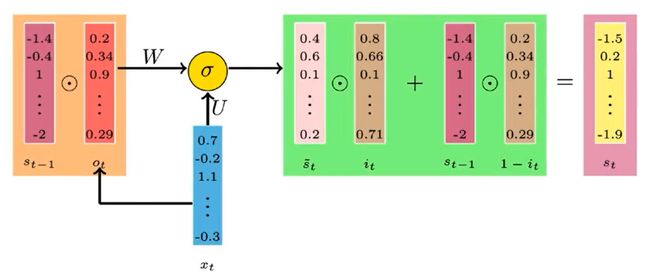
To lower down the computational time we remove forget gate and to discard the information we use compliment of input gate vector i.e. (1-iₜ).
为了降低计算时间,我们删除了遗忘门,并使用输入门矢量(1- iₜ )的补充来丢弃信息。
The equations implemented for GRU are:
为GRU实施的公式为:

关键点 (Key Points)
- LSTM & GRU are introduced to avoid short-term memory of RNN. 引入LSTM和GRU是为了避免RNN的短期记忆。
- LSTM forgets by using Forget Gates. LSTM通过使用“忘记门”来忘记。
- LSTM remembers using Input Gates. LSTM记得使用输入门。
- LSTM keeps long-term memory using Cell State. LSTM使用“单元状态”保持长期记忆。
- GRUs are fast and computationally less expensive than LSTM. GRU比LSTM速度快且计算成本更低。
- The gradients in LSTM can still vanish in case of forward propagation. 在向前传播的情况下,LSTM中的梯度仍会消失。
- LSTM doesn’t solve the problem of exploding gradient, therefore we use gradient clipping. LSTM不能解决梯度爆炸的问题,因此我们使用梯度削波。
实际用例 (Practical Use Cases)
- Sentiment Analysis using RNN 使用RNN进行情感分析
- AI music generation using LSTM 使用LSTM生成AI音乐
结论 (Conclusion)
Hopefully, this article will help you to understand about Long short-term memory(LSTM) and Gated Recurrent Units(GRU) in the best possible way and also assist you to its practical usage.
希望本文能以最佳方式帮助您了解长短期记忆(LSTM)和门控循环单位(GRU),并帮助您实际使用。
As always, thank you so much for reading, and please share this article if you found it useful!
与往常一样,非常感谢您的阅读,如果发现有用,请分享这篇文章!
Feel free to connect:
随时连接:
LinkedIn ~ https://www.linkedin.com/in/dakshtrehan/
领英(LinkedIn)〜https: //www.linkedin.com/in/dakshtrehan/
Instagram ~ https://www.instagram.com/_daksh_trehan_/
Instagram〜https: //www.instagram.com/_daksh_trehan_/
Github ~ https://github.com/dakshtrehan
Github〜https: //github.com/dakshtrehan
Follow for further Machine Learning/ Deep Learning blogs.
关注更多机器学习/深度学习博客。
Medium ~ https://medium.com/@dakshtrehan
中〜https ://medium.com/@dakshtrehan
想了解更多? (Want to learn more?)
Detecting COVID-19 Using Deep Learning
使用深度学习检测COVID-19
The Inescapable AI Algorithm: TikTok
不可避免的AI算法:TikTok
An insider’s guide to Cartoonization using Machine Learning
使用机器学习进行卡通化的内部指南
Why are YOU responsible for George Floyd’s Murder and Delhi Communal Riots?
您为什么要为乔治·弗洛伊德(George Floyd)的谋杀和德里公社暴动负责?
Recurrent Neural Network for Dummies
递归神经网络
Convolution Neural Network for Dummies
卷积神经网络
Diving Deep into Deep Learning
深入学习
Why Choose Random Forest and Not Decision Trees
为什么选择随机森林而不是决策树
Clustering: What it is? When to use it?
聚类:是什么? 什么时候使用?
Start off your ML Journey with k-Nearest Neighbors
从k最近邻居开始您的ML旅程
Naive Bayes Explained
朴素贝叶斯解释
Activation Functions Explained
激活功能介绍
Parameter Optimization Explained
参数优化说明
Gradient Descent Explained
梯度下降解释
Logistic Regression Explained
逻辑回归解释
Linear Regression Explained
线性回归解释
Determining Perfect Fit for your ML Model
确定最适合您的ML模型
Cheers!
干杯!
翻译自: https://medium.com/towards-artificial-intelligence/understanding-lstms-and-gru-s-b69749acaa35
lstm和gru