Predicting Depth, Surface Normals and Semantic Labels with a Common Multi-Scale Convolutional Archit
Predicting Depth, Surface Normals and Semantic Labels with a Common Multi-Scale Convolutional Architecture论文阅读笔记
本文发表于2015ICCV。代码在http://cs.nyu.edu/ ̃deigen/dnl/
1.Introduction
本文用一个模型解决了三个问题:
1.深度估计
2.表面法向估计
3.语义标注
像素图可以直接从输入中产生,不需要low-level的超像素或者轮廓,并且能够使用一系列的卷积栈在越来越高的分辨率上对齐图像细节。
注:超像素就是把一幅像素级(pixel-level)的图,划分成区域级(district-level)的图,是对基本信息元素进行的抽象。
(a) 是原始图片,(b)是基于人类视角的分割图,也就是groundtruth,(c)就是超像素分割的图片,(d)是基于(c)进行分割的图片。
为像素图回归设计通用神经网络有很多好处:
1.仅需要少量的修改,就可以在不同任务、应用中切换
2.简化了多任务系统的实现
3.在某些任务中网络结构能够共用
在不同任务中使用通用神经网络的主要的工作是设计合适的损失函数和找到合适的数据集。
2.Related work
- 大部分的系统用ConvNets只是去找局部特征,或者产生离散的候选区域的描述符。而本文既用了局部的又用了全局的视角去预测输出的类型。前人的方法最多解决一两个任务,而本文解决了三个任务。
- 本文基于Eigen(作者自己)在单图像深度图预测中使用了两层卷积网络,而本文用了三种不同的尺度去生成特征并且改善预测到更高的分辨率。
- 之前的语义分割方法是使用RGB数据和RGB-D数据。 大多数使用局部特征来对过度分割的区域进行分类,这是通过全局一致性优化(如CRF)来实现的。而本文先进行一致的全局预测, 然后进行迭代局部细化。这么做可以让局部网络意识到他们在全局场景上的地位, 并且可在他们预测的改进中使用这些信息。
- 与本文在语义分割方面的方法最相关的是使用卷积网络的方法。本文与他们不同的是, 模型在最粗糙的范围内具有大的全图像视野,且没有使用超像素或者后处理的平滑——网络自己可以为它产生平滑。
3.Model Architecture
本文的模型是一个多尺度的网络,先基于整个图像的区域预测了一个粗略的全局输出,然后用一个更精细的局部网络改进它。
基于作者本人之前的文章,但有三点改进:
1.网络更深(更多卷积层)
2.三块网络,前两个是原有架构,增加了第三个尺度的网络,能够输出更高分辨率的图,最终的输出分辨率为输入图片的一半,相比之前工作中的 1/4 有了提高
3.与之前的思路有点不同,之前采用的方式是,先训练scale1,训练完成后,以scale 1的输出作为scale 2的输入。现在所采用的方式是:scale 1和scale 2联合训练,最后固定这两个尺度CNN,在训练scale 3。
网络结构及相关参数如下图所示:


Scale 1: Full-Image View

第一尺度网络是整个网络最重要的一环,后面实验部分也证明了这点。它预测出的是一个模糊但是反映图像空间变换的全局特征图,因为后接了两个全连接层,因此其感受野是全局的,最终的输出尺度是原始图像的 1/16,但是有 64 个特征通道,之后上采样到 1/4 作为第二尺度网络的输入。
网络的输入:原始图片,输入图片大小为三通道彩色图片。网络的输出:19*14大小的图片. 然后上采样到74X55。
训练了两个不同大小的模型,一个基于AlexNet,一个基于VGG network,用来评估模型大小的影响。
Scale 2: Predictions

第二尺度网络的目标:产生中点分辨率的预测图。
想法:用【一个更有细节但是视野更狭窄的图】和【Scale1提供的整张图的信息】来训练。
输入:由原图经过简单的卷积加池化形成的特征图以及第一尺度网络输出上采样后的特征图连接而成。
输出:原始图片 1/4 分辨率大小的预测图(深度图等)。
Scale 3: Higher Resolution

第三尺度网络进一步改善预测结果,使其拥有更高的分辨率,其输入与第二层类似,看图就能理解,最终的输出分辨率为原图的 1/2,且获得了更多的细节信息。
串联"scale2的输出特征"和"卷积池化后的原图特征"进行卷积训练。
4.Tasks
应用相同的架构在这三个任务中,但使用不同的损失函数和数据。
1.深度估计

D:预测的深度图(对每个深度取log)
D*:真实的深度图(对每个深度取log)
d=D-D*

2.表面法向量
表面法向量是三维的,因此最终的输出通道要从一个通道改成三个,最终输出的法向量在计算损失函数之前要先归一化,定义损失函数如下。

其中N,N*是经过归一化后的估计表面法向量图和真实表面法向量图,同样这里只针对有效点计算损失。只看损失函数,其目的是希望估计的法向量和真实的法向量点乘结果大,那么两者角度就小,相似性就高。对于真实的表面法向量,作者用 Silberman 的方法,从实际深度值得到真实的表面法向量。
3.语义标注
每个像素点对应一个类别,因此网络的输出通道数与类别数一致,损失函数使用交叉熵损失,如下所示:

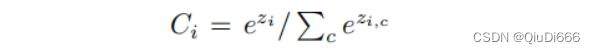
Ci是像素点 i 的类别预测结果。
输入:真实的深度图及表面法向量图。
具体来讲,在第一尺度网络仅使用 RGB 图作为输入,在第二尺度网络在原有网络输入基础上新增深度图以及表面法向量图,但是三者并非直接通道相连作为网络输入,而是分别一个网络进行训练,最后将三个网络的输出通道相连,作为第二尺度网络的输出。这么做是为了保证三者在低层次特征上保持相对独立性。
5.Training
1.训练过程
两阶段,用随机梯度下降法SGD:
第一阶段联合训练Scale1和Scale2,第二阶段固定住1和2的参数,训练Scale3。为了加快训练速度,作者在实际训练第三尺度网络时,将输入的特征图和原图随机裁剪成 74 * 55 大(NYUDepth数据集上,原始输入的一半),在不太影响结果精度的情况下提高了 3 倍左右的速度。
2.数据增强
作者采用了尺度、旋转、裁剪、颜色、翻转及对比的方式进行数据增强,在对原始 RGB 进行数据增强的同时,对于 ground truth 也要进行相应的操作来匹配输入的 RGB 图。
3.合并深度估计和表面法向量估计
为了减小计算量,作者将深度估计和表面法向量估计这两个任务合并在一起训练,即输入一张 RGB 图能同时得到其深度图和表面法向量图。实际操作中两者共用第一尺度网络,而后面两个网络则完全独立。合并后的网络训练速度是两个完全独立网络训练速度的 1.6 倍左右。
6.Performance Experiments
1.深度估计


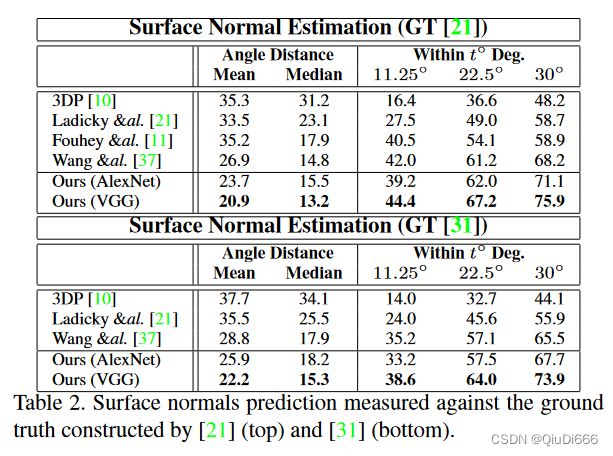
2.表面法向估计
3.语义标注




7.Probe Experiments
1.Contributions of Scales

2.Effect of Depth and Normals Inputs

8.Discussion
本文的方法又快又好。代码在http://cs.nyu.edu/ ̃deigen/dnl/
参考博客:(26条消息) Predicting Depth, Surface Normals and Semantic Labels with a Common Multi-Scale... 论文笔记__Suraimu_的博客-CSDN博客
(26条消息) Predicting Depth,Surface Normals and Semantic Labels with a Common Multi-Scale Convolutional Archite_TWSF的博客-CSDN博客
【论文笔记】用通用多尺度卷积预测深度,表面法线和语义标签 - 知乎 (zhihu.com)