《 MultiGrain: a unified image embedding for classes and instances》论文阅读笔记
《 MultiGrain: a unified image embedding for classes and instances》论文阅读笔记
- 1 简介
- 2 相关工作
- 3 结构设计
-
- 3.1 空间池化操作
- 3.2 训练目标
- 3.3 使用数据增强的batch训练
- 3.4 白化
- 3.5 输入大小
- 4 实验和结果
-
- 4.1 实验设置
-
- 训练设置
- 4.2 使用不同分辨率的图像,找最佳的P*值
- 4.3 损失函数 λ的影响
- 4.4分类结果
- 4.5 检索结果
主要亮点:
(1)无论是用于分类任务还是检索任务,使用的特征是相同的,并且各自的表现都不错。但是对于分类任务是额外训练了一个线性分类器,而检索任务使用余弦距离。并不是我之前以为返回一系列图片,有完全一样的排在前面, 相似的在后面。
(2)RA的增强方式对提高检索精度有用的。RA即每个batch中有同一实例的不同增强版本。注意,分类任务训练时都是不同实例,同一实例的不同增强版本是在训练检索任务时加入的数据。
(3)通过简单地在ResNet后加一个GeM的池化层,使得可以用低分辨率的图片训练,然后测试时可以用高分辨率的图片,并且对于分类任务的精度会大大提升。
1 简介
使用了两个loss,交叉熵for classify,ranking loss / contrastive lossesfor instance。
使用GeM,这样使用低分辨率训练,但也能使用高分辨率图像作为检索图像。
分类的任务都达到了top1 79.3%的历史新高。
图像识别任务从粗到细分为:classes, instances, copies(对原图拷贝并且编辑了一些)
将这三个任务特化是专业做法,但对日常任务造成了瓶颈,因为人们在使用一个系统检索时可能希望进行着三种检索。
检索系统的表现主要由特征决定,它需要平衡数据库大小,匹配和检索速度、检索效率。
但如果只是将三个任务的特征狭隘地一起使用,其实等同于数据库翻了三倍,这是不可取的。
本篇文章提出了新的表示,能实现三个任务合一,尽管他们的语义细粒度不同。
这三个任务是相互有逻辑关系的,同一实例一定是同一类,同一拷贝一定是同一实例。所以类别、实例、拷贝一致时都会导致描述子在特征空间是靠近的。
但每个任务的相似程度是不同的,类别需要更多对类内差异的包容,而拷贝需要对微小的图片改动敏感。
使用了一个带指数参数p的广义平均池化 (generalized mean pooling ,GeM)将空间响应map转化成固定大小。p用于调节辨别性和不变性。这也是一种有效的学习,能学习到测试时接受不同分辨率的图片。
而且训练实例部分没有用新的标签。
2 相关工作
图像搜索:从局部特征到CNN。可能的提升可以使用几何验证,扩展查询,或者数据库这边的预处理和增强。
多任务训练:比较火的,因为神经网络被发现具有较好的迁移能力。尤其是训练被发现还有很多压缩空间。
数据集增强:对于本文的SGD,发现数据库中不仅包含不同的实例,当包含多个数据集增强的同一实例,很好地增强了数据达到了泛化的效果。
batch augmented (BA) sampling和本文提出的数据集增强很像。他们在对数据集增强时发现,当对于batch比较大时,增添同一图片的增强copy比较有用,而且减少了实践,因为copy处理操作相比增强要简单。
但本文使用的batch数目是固定的,但是其中不同实例的图片比较少。也叫 repeated augmentations (RA)。作者认为RA的方式对增强NN泛化能力的普遍适用的。
3 结构设计
给出了分类任务和检索任务的不同点以及如何弥补不同。因为本来就是希望给出分类和检索都适用的网络。
| 分类 | 检索 | |
|---|---|---|
| 空间池化 | 平均池化 | RMAC及GeM |
| 损失函数 | 交叉熵 | 三元损失triplet |
| 批采样 | 多种多样 | 每批图片数量相同 |
| 白化操作 | 否 | 是 |
| 分辨率 | 小(2242-3002) | 大(800-1k) |
3.1 空间池化操作
分类:池化是为了得到对于局部变化的不变性。
检索:需要更多局部几何信息,有时候给出的查询图像可能没有相似的训练图像训练过网络。
介绍 generalized mean pooling GeM
和普通池化一样都是在一层特征图上进行的,只是MAC是整张图的最大,而这里是整张图的带指数的平均。
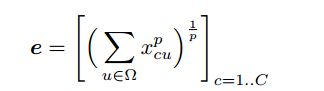
也就是整张图的每个像素的p次方求和再开p次方。
p>1时会增大输入特征图的对比度,专注于输入特征图突出、跳跃的部分。这个在后面实验会详细说。
为什么叫generalized,因为p=1时是平均池化,p=无穷是max pooling。
来来,复习下R-MAC。
MAC就是对特征图CHW,每张图求最大值,得到一个值,最终是C维向量。
首先R-MAC采样特征图的形状是正方形,它有个scale参数l,l=1时,在特征图上以overlap 40%左右能采到的正方形个数记为参数m.
对于第l层,采样的正方形区域个数为l*(l+m-1)个,区域大小为2*min(H,W)/(l+1)。
然后对这些块进行MAC,拉成向量,L2归一化,PCA,L2归一化… 再按照每 N 个(深度的维度数)相加后在 L2 归一化,最终大小和原本的MAC相同。这就是R-MAC。
嘛,GeM是用在了检索,但没用在分类,所以文章说是第一次把这个池化用在了分类任务上。而且后续将证明,这个参数的调整是对任何任务都可以高效调整训练、测试图片分辨率的一种手段。
3.2 训练目标
使用了结合两种损失函数的loss。
交叉熵对于分类。
而检索使用的对比损失, contrastive loss,是要求正样本相似距离小于某个值,而与负样本的距离需要更大。
triplet loss只是要求样本离正样本比负样本进。
但实现这些loss需要调整很多参数?尤其是如何采样 pairs and triplets。第一个对比损失是找pair,而后一个是找三元组。
所以使用文献[47]的一种loss,是一种有一些triplet损失好处的变种的对比损失。这个文献有个博客分析过了,附上链接:https://zhuanlan.zhihu.com/p/27748177。
博客中说的模型坍塌在文献[47]中定义是:all images have the same embedding.
损失函数具体如下:
![]()
其中:![]()
采样的时候,正样本是已知的,负样本的采样是通过一个和上面距离D函数和embding维度相关的一个PDF,来采样。
最后使用一个加权因子将两个loss结合:
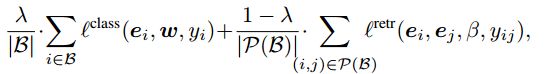
这里的|B|是batch大小,也就是平均损失。
3.3 使用数据增强的batch训练
这里只使用一个数据集训练分类,每类可以有多个实例,但每个实例只有一个图片,然后对数据集进行增强,即每个实例可以有多张图片,来进行检索任务的训练。这样不需要额外的label。
新的采样/增强方法: repeated augmentations,RA。对于用于训练检索的数据集,每个batch是直接sample |B|/m个不同图片,然后使用增强的方法将batch数量乘m倍。这样如果原图是相似的,那么增强后的两个图片也是相似的,即yij=1.
与平常标准SGD采样不同在于,增强后的图片与原图是相关的,以前是希望增强出的图片与原图不像,这样来增多数据。但这种有可能导致收敛慢。
但对于batch数比较大的时候比原本的IID(独立同分布)的采样表现要好,对于本任务来说是这样。我们猜测是因为有利于学习到对重复图片具有不变性的特征。而SGD的标准采样,同一图片的增强版本只会在不同epoch中见到。
3.4 白化
PCA白化,会在分类最后一层被抵消,所以分类也可以直接用白化后的特征!
直观上来看,本来分类层就是一个FC,也就是一个PCA白化的操作,所以可以抵消。
白化操作:
![]()
证明如下:
![]()
其中:![]() ,该过程可以用下面内积的性质证明得到。
,该过程可以用下面内积的性质证明得到。
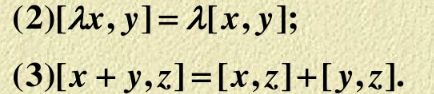
3.5 输入大小
分类任务一般分辨率较小,因为分类不需要高分辨率,低分辨率还可以减少开销。比如224
但检索任务需要更好的分辨率,比如800,1024.
这么高的分辨率想要联合训练是不切实际的。所以只在训练用224,测试再用高分辨率。这是由于GeM。
最终,网络结构如下:

4 实验和结果
4.1 实验设置
训练设置
优化方法:SGD
学习率:初始为0.1,在第30,60,90个epoch时学习率衰减10倍,共120个epoch。//这是个标准的配置
怎么跑:跑多少个epoch,每个epoch跑多少个batch,每个batch大小,总共多少个batch:5005,512,5005/2(也就是每个epoch跑两次training set。)
等训练检索任务时,使用了RA,m=3,所以每次epoch跑了2/3个数据集。
数据集增强:使用了标准的翻转、随机剪裁、随机亮度噪声、亮度、对比度和饱和度的颜色抖动。
池化指数:使用的池化要么是P=1或者P=3。发现对于图中物体比较小,当P=3时,提高分辨率会显著提高GeM响应。而且高分辨率时P=3也减少了假阳。所以后续都使用P=3训练。
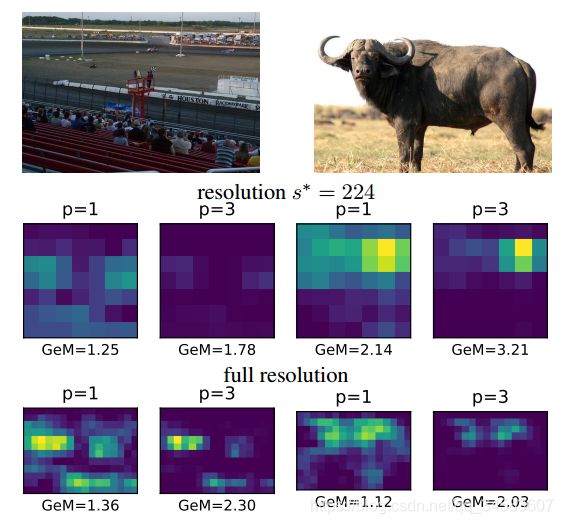
输入大小和剪裁:训练都是224,测试时候有225,500,和800.但测试的时候,为了得到224分辨率,采用经典的分类任务的方法:将短边缩放到256,然后裁取出中心的224*224.但对于高分辨率(500,800),采用经典的检索的方法:直接将长边缩放到希望的分辨率,如果是方形也直接输入,不做裁剪。
间隔损失和批采样:参数配置如下:
数据集:分类在IMAGENET上,检索在INRIA、UKB(2550*4)上,以及在copy类的 INRIA Copydays数据集,并且从YFCC100M(大规模无标签图片集)中抽取了10k个干扰的图片,叫C10K。
而PCA的参数是从YFCC100K中20k图片中学习到的。我个人不明白为什么不直接对已有数据集学PCA,要在从它里面学,因为数据多?希望得到大家的解答。
//YFCC 100M数据库是2014年来基于雅虎Flickr的影像数据库。该库由1亿条产生于2004年至2014年间的多条媒体数据组成,其中包含了9920万的照片数据以及80万条视频数据。不过其中只有4800多万张照片和大约10万条视频记录带有地理坐标信息。
4.2 使用不同分辨率的图像,找最佳的P*值
s=224时,和预料的一致,是在训练时的P*=3时取得最佳。
但当s>224时,不论是分类还是检索任务,都需要p*>3。
然后我们从IMAGENET中抽取了2k个图片作为检索数据集,叫做IN-aug,每类两张图片,然后使用m=5的RA
实验:在ImageNet上做分类acc,在UKB上做检索acc,然后发现在IN-aug上的acc表现和UKB很相似,所以接下来就使用在IN-aug上各个分辨率表现最佳的P*:
| s∗ | 224 | 500 | 800 |
|---|---|---|---|
| p∗ | 3 | 4 | 5 |
4.3 损失函数 λ的影响
λ分别取{0:1; 0:3; 0:5; 0:7; 0:9; 1:0},在0.1得到最好的检索表现但很差的分类表现(0.1时检索loss占主要),1时检索表现很好但检索很差,在0.5时候分类比1时好,同时检索不错。所以之后的实验中λ=0.5.此时在224和500分辨率下得到了最好的分类acc。
4.4分类结果
认为表现好的原因有四点:
(1)RA,+0.6%
(2)Margin loss:检索Loss有助于数据集增强后的良好泛化,+0.2%
(3)P=3的GeM,通过让目标处的特征响应更强让Loss能更好,+0.4%
(4)分辨率的加大:在500、P=3时,+1.2%。或许是P=3训练得到了稀疏、泛化能力在各个分辨率都更好的特征。
但当s=800时,由于和原训练数据分辨率差别较大,acc开始下降。
为了进一步说明GeM单独就会让低分辨率训练、高分辨率测试表现好,使用了AA的数据集增强进行测试,结果得到了使用res-50目前最高的top1正确率。
4.5 检索结果
RA是重要成功因素,虽然表现没有是最佳,只差一些。
但认为自己的方法好在对于分类和检索产生的是一个特征,而且对于低分辨率就能有良好的表现。很适合大规模、低分辨率的应用。