Flink系列之Flink 流式编程模式总结
title: Flink系列
一、Flink 流式编程模式总结
1.1 基础总结
官网: https://flink.apache.org/
Apache Flink® — Stateful Computations over Data Streams

三个任意:
任意的数据源 Source
任意的计算类型 Transformation
任务的数据目的地 Sink
其中关于 Flink 的编程:

所有的计算,都是这样的大流程:
- 从哪里读取数据
- 读取到了数据执行什么样的计算
- 计算得到结果之后,输出到哪里
Flume + DataX(从哪里收集?内部的处理?数据输出到哪里?)
总结一下:

通过 Flink WordCount 总结出来的编程模式:
01、获得一个执行环境:(Execution Environment)
02、加载/创建初始数据:(Source)
03、指定转换这些数据:(Transformation)
04、指定放置计算结果的位置:(Sink)
05、触发程序执行:(Action)
1.2 提交到集群上面运行流程
1.2.1 通过页面方式提交
1、测试程序如下
package com.aa.flinkscala
import org.apache.flink.api.java.utils.ParameterTool
import org.apache.flink.streaming.api.scala._
/**
* @Author AA
* @Project bigdatapre
* @Package com.aa.flinkscala
* 动态参数形式测试
*/
object WordCountScalaStreamWithParameter {
def main(args: Array[String]): Unit = {
//1、获取执行环境
val env: StreamExecutionEnvironment = StreamExecutionEnvironment.getExecutionEnvironment
//修改成动态参数
val parameterTool = ParameterTool.fromArgs(args)
val hostname = parameterTool.get("hostname")
val port = parameterTool.getInt("port")
//2、获取数据源
val textStream: DataStream[String] = env.socketTextStream(hostname, port)
//3、数据计算处理逻辑
val wordCountStreamRes: DataStream[(String, Int)] = textStream.flatMap(_.split(" "))
.map((_, 1))
.keyBy(line => line._1)
//.keyBy(0) //过期的方法,将来可能不支持啦
.sum(1)
//4、打印输出结果
wordCountStreamRes.print()
//5、启动应用程序
env.execute("WordCountScalaStreamWithParameter")
}
}
2、打成jar
直接通过idea右侧的maven方式打包即可

打包完了之后如下:

3、启动集群进行测试即可
在hadoop10上面启动:
[root@hadoop10 bin]# cd /software/flink/bin/
[root@hadoop10 bin]# start-cluster.sh
Starting cluster.
Starting standalonesession daemon on host hadoop10.
Starting taskexecutor daemon on host hadoop11.
Starting taskexecutor daemon on host hadoop12.
[root@hadoop10 bin]#
页面如下:

4、在页面中提交
(1)点击Submit New Job

(2)点击Add New
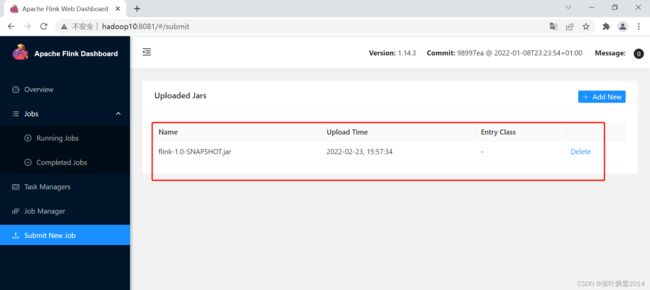
(3)选择上传之后如下:
(4)单击jar包的名字,填写参数
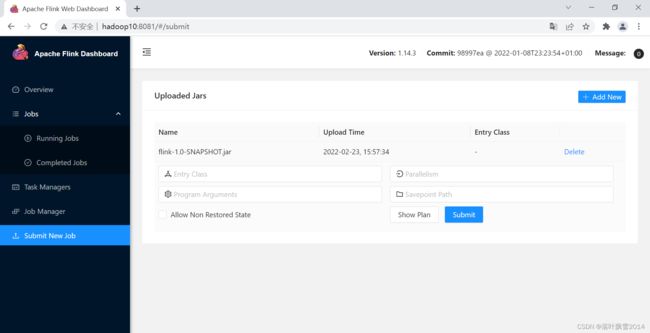
(4)填写完参数如下:

(5)记得先启动 hadoop12 上面的 9999 端口 。 否则报错连接不上。
[root@hadoop12 software]# nc -lk 9999
(6)点击Submit提交运行
然后去运行中查看对应程序

(7)到hadoop12 的 9999 端口中输入数据进行测试
[root@hadoop12 software]# nc -lk 9999
hello world hello hadoop hello flink
hello
(8)去页面中查看

(9)取消程序
点击页面中的左上角的Cancel Job即可

或者使用命令取消:
[root@hadoop10 bin]# flink list
Waiting for response...
------------------ Running/Restarting Jobs -------------------
23.02.2022 16:11:02 : 9aab4c22c946dc0bfeb1546741fca390 : WordCountScalaStreamWithParameter (RUNNING)
--------------------------------------------------------------
No scheduled jobs.
[root@hadoop10 bin]# flink cancel 9aab4c22c946dc0bfeb1546741fca390
Cancelling job 9aab4c22c946dc0bfeb1546741fca390.
Cancelled job 9aab4c22c946dc0bfeb1546741fca390.
[root@hadoop10 bin]# flink list
Waiting for response...
No running jobs.
No scheduled jobs.
[root@hadoop10 bin]#
截图如下:

4、通过命令显示所有历史任务
[root@hadoop10 bin]# flink list -a
Waiting for response...
No running jobs.
No scheduled jobs.
---------------------- Terminated Jobs -----------------------
23.02.2022 16:04:45 : 550fe2157ca70d796aeca4cf8b4dc622 : WordCountScalaStreamWithParameter (FAILED)
23.02.2022 16:11:02 : 9aab4c22c946dc0bfeb1546741fca390 : WordCountScalaStreamWithParameter (CANCELED)
23.02.2022 16:24:33 : b2fdf9e8b8cb122a235d2948a307b244 : WordCountScalaStreamWithParameter (CANCELED)
23.02.2022 16:30:26 : 67e18591ba85782bde8dd3a49e1488cb : WordCountScalaStreamWithParameter (CANCELED)
23.02.2022 16:31:24 : 52d672e2f628badf42a2fee396ffaf18 : WordCountScalaStreamWithParameter (FAILED)
--------------------------------------------------------------
[root@hadoop10 bin]#
1.2.2 通过代码方式提交
1、基础理论
去到flink的bin目录下面:
flink run -c com.aa.flinkscala.WordCountScalaStreamWithParameter /home/data/flink-1.0-SNAPSHOT.jar --hostname hadoop12 --port 9999
或者:
flink run \
-c com.aa.flinkscala.WordCountScalaStreamWithParameter \
/home/data/flink-1.0-SNAPSHOT.jar \
--hostname hadoop12 --port 9999
2、实践
[root@hadoop10 bin]# flink run -c com.aa.flinkscala.WordCountScalaStreamWithParameter /home/data/flink-1.0-SNAPSHOT.jar --hostname hadoop12 --port 9999
Job has been submitted with JobID b2fdf9e8b8cb122a235d2948a307b244
去页面中查看
正在运行的如下:
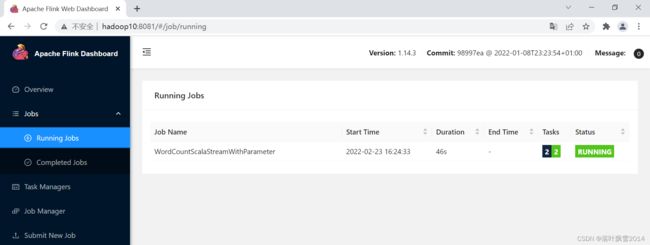
同理输入测试就一样了。
3、小总结
提交 Flink 应用程序到 Flink Cluster 中运行:
搭建 Flink 集群!
编写 wordcount,打成 jar 包,提交到 flink 集群运行
flink run \
--c 全类路径名 \
jar包绝对路径 \
--hostname hadoop10 \
--port 6789
当你需要提交一个 jar 包到 flink standalone 集群或者 YARN 中运行的时候,其实是通过 flink run … 搞定的 ==>
这个 shell 命令的底层就是: java CliFrontend
提交完程序之后,在另外一个节目里面通过jps,可以看到这个CliFrontend 。

在源码中的全路径名为:
flink-clients/src/main/java/org/apache/flink/client/cli/CliFrontend.java
在源码中的位置如下:

声明:
文章中代码及相关语句为自己根据相应理解编写,文章中出现的相关图片为自己实践中的截图和相关技术对应的图片,若有相关异议,请联系删除。感谢。转载请注明出处,感谢。
By luoyepiaoxue2014
B站: https://space.bilibili.com/1523287361 点击打开链接
微博地址: http://weibo.com/luoyepiaoxue2014 点击打开链接