混淆矩阵及其可视化
混淆矩阵(Confusion Matrix)是机器学习中用来总结分类模型预测结果的一个分析表,是模式识别领域中的一种常用的表达形式。它以矩阵的形式描绘样本数据的真实属性和分类预测结果类型之间的关系,是用来评价分类器性能的一种常用方法。
我们可以通过一个简单的例子来直观理解混淆矩阵。
通过分类模型我们得到的预测结果以及真实的属性可以通过列表的形式展现,
y_pred=["ant", "ant", "cat", "cat", "ant", "cat"] #预测
y_true=["cat", "ant", "cat", "cat", "ant", "bird"] #真实
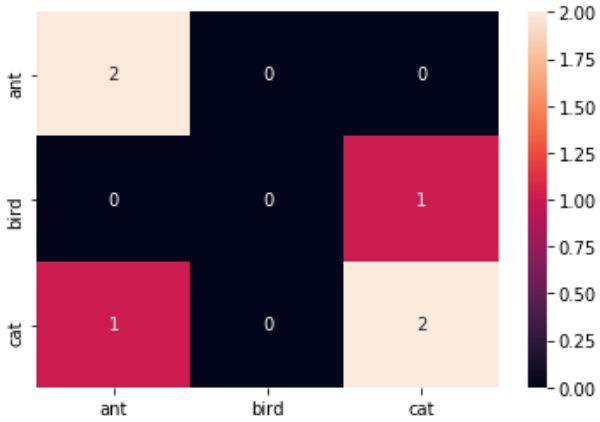
数轴的标签表示真实属性,而横轴的标签表示分类的预测结果。此矩阵的第一行第一列这个数字2表示ant被成功分类成为ant的样本数目,第三行第一列的数字1表示cat被分类成ant的样本数目,诸如此类。
混淆矩阵的每一行数据之和代表该类别的真实的数目,每一列之和代表该类别的预测的数目,矩阵的对角线上的数值代表被正确预测的样本数目。
那么这个混淆矩阵是如何绘制的呢?
这里给出两种简单的方法,一是使用seaborn的热力图来绘制,可以直接将混淆矩阵可视化;
C=confusion_matrix(y_true, y_pred, labels=["ant", "bird", "cat"])
df=pd.DataFrame(C,index=["ant", "bird", "cat"],columns=["ant", "bird", "cat"])
sns.heatmap(df,annot=True)
另外一种是使用matplotlib的matshow来绘制。
plt.matshow(C, cmap=plt.cm.Greens)
plt.colorbar()
for i in range(len(C)):
for j in range(len(C)):
plt.annotate(C[i,j], xy=(i, j), horizontalalignment='center', verticalalignment='center')
plt.ylabel('True label')
plt.xlabel('Predicted label')
plt.show()
效果如下:
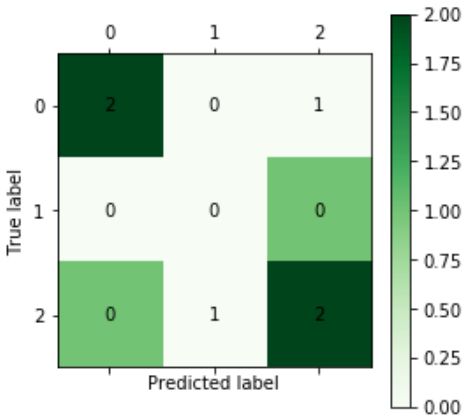
利用混淆矩阵的可视化,我们能够分析类别误判的结果,从而对机器学习的模型进行调整。