论文笔记&翻译——Enhanced LSTM for Natural Language Inference(ESIM)
文章目录
-
- 0.前言
- 1. 模型结构
-
- 1.1 input encoding
- 1.2 local inference modeling
- 1.3 inference composition
- 2. 模型实现
0.前言
在Query 扩召回项目中,通过各种手段挖掘出一批同义词,想对其进行流程化,所以考虑加上语义推断,在同事的推荐下使用了 ESIM 模型,据了解这个模型在近两年横扫了好多比赛,算是 NLI (Natural Language Inference) 领域未来几年一个很难绕过的超强 baseline 了,单模型的效果可以达到 88.0% 的 Acc。
ESIM模型出自 Qian Chen 等人发表在 ACL2017 上的 Enhanced LSTM for Natural Language Inference
顾名思义,一种专为自然语言推断而生的加强版 LSTM,从文中得出主要改进在于
Unlike the previous top models that use very complicated network
architectures, we first demonstrate that carefully designing sequential inference
models based on chain LSTMs can outperform all previous models.
Based on this, we further show that by explicitly considering recursive
architectures in both local inference modeling and inference composition,
we achieve additional improvement.
总结一下主要是:
- 精细的设计序列式的推断结构。
- 考虑局部推断和全局推断。
接下来看看模型结构
1. 模型结构
文中给出的模型结构如下:
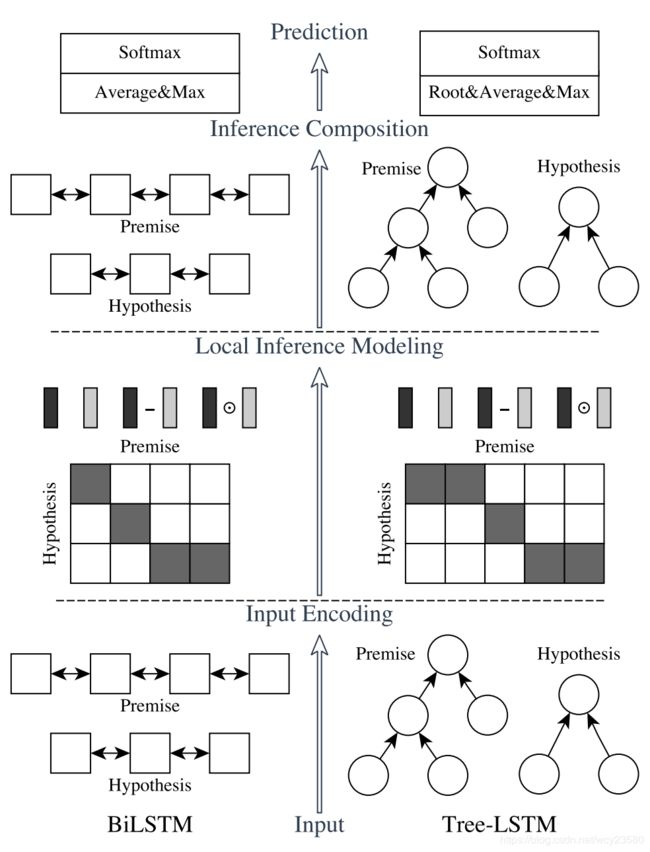
ESIM主要分为三部分:input encoding,local inference modeling 和 inference composition。如上图所示,ESIM 是左边一部分。
1.1 input encoding
Input Encoding 就是输入两句话分别接 embeding+ BiLSTM, 使用复用的 双向LSTM(biLSTM )单元分别对 p ( 前提 Premise)和 h (假设 Hypothesis)进行编码,得到 a ˉ \bar{a} aˉ, b ˉ \bar{b} bˉ。
a ˉ i = B i L S T M ( a , i ) , ∀ i ∈ [ 1 , 2 , . . . , l a ] \bar{a}_i = BiLSTM(a, i), \forall i \in [1, 2, ..., l_a] aˉi=BiLSTM(a,i),∀i∈[1,2,...,la]
b ˉ j = B i L S T M ( b , j ) , ∀ j ∈ [ 1 , 2 , . . . , l b ] \bar{b}_j = BiLSTM(b, j), \forall j \in [1, 2, ..., l_b] bˉj=BiLSTM(b,j),∀j∈[1,2,...,lb]
使用 BiLSTM 可以学习如何表示一句话中的 word 和它上下文的关系,我们也可以理解成这是 在 word embedding 之后,在当前的语境下重新编码,得到新的 embeding 向量。
1.2 local inference modeling
使用 Decomposable Attention 分别对 p 和 h 做权重计算,得到 attention 权重 a ^ \hat{a} a^ , b ^ \hat{b} b^
a i ^ = ∑ j = 1 l b exp e i j ∑ k = 1 l b exp ( e i k ) b ˉ , ∀ i ∈ [ 1 , 2 , . . . , l a ] \hat{a_i} = \sum_{j=1}^{l_b} \frac{\exp{e_{ij}}}{\sum_{k=1}^{l_b} \exp(e_{ik})} \bar{b}, \forall i \in [1, 2, ..., l_a] ai^=j=1∑lb∑k=1lbexp(eik)expeijbˉ,∀i∈[1,2,...,la]
b j ^ = ∑ i = 1 l a exp e i j ∑ k = 1 l a exp ( e k j ) a ˉ , ∀ j ∈ [ 1 , 2 , . . . , l b ] \hat{b_j} = \sum_{i=1}^{l_a} \frac{\exp{e_{ij}}}{\sum_{k=1}^{l_a} \exp(e_{kj})} \bar{a}, \forall j \in [1, 2, ..., l_b] bj^=i=1∑la∑k=1laexp(ekj)expeijaˉ,∀j∈[1,2,...,lb]
原文Decomposable Attention 在输入编码时候是直接用前馈神经网络对预训练的词向量做操作,这样会损失掉一些上下文信息,所以对其进行了改进。
1.3 inference composition
在 local inference 之后,进行 Enhancement of local inference information。这里的 enhancement 就是计算 a ^ \hat{a} a^ 和 a ˉ \bar{a} aˉ 的差和乘积, 体现了一种差异性吧,更利用后面的学习, b ^ \hat{b} b^和 b ˉ \bar{b} bˉ也做差和乘积操作。之后再将四个进行聚合拼接操作,
m a = [ a ˉ ; a ^ ; a ˉ − a ^ ; a ˉ ⊙ a ^ ] m_a = [\bar{a}; \hat{a}; \bar{a} - \hat{a}; \bar{a} \odot \hat{a}] ma=[aˉ;a^;aˉ−a^;aˉ⊙a^]
m b = [ b ˉ ; b ^ ; b ˉ − b ^ ; b ˉ ⊙ b ^ ] m_b = [\bar{b}; \hat{b}; \bar{b} - \hat{b}; \bar{b} \odot \hat{b}] mb=[bˉ;b^;bˉ−b^;bˉ⊙b^]
最后做一个求最大值和均值的操作再将 p,h 拼接起来,过一下biLSTM、FFN 和 softmax 得到最终结果。
v a , i = B i L S T M ( m a , i ) v_{a,i} = BiLSTM(m_a, i) va,i=BiLSTM(ma,i)
v b , j = B i L S T M ( m b , j ) v_{b,j} = BiLSTM(m_b, j) vb,j=BiLSTM(mb,j)
v a , a v e = ∑ i = 1 l a v a , i l a v_{a,ave} = \sum_{i=1}^{l_a} \frac{v_{a,i}}{l_a} va,ave=i=1∑lalava,i
v a , m a x = max i = 1 l a v a , i v_{a,max} = \max_{i=1}^{l_a} v_{a,i} va,max=i=1maxlava,i
v b , a v e = ∑ j = 1 l b v b , j l b v_{b,ave} = \sum_{j=1}^{l_b} \frac{v_{b,j}}{l_b} vb,ave=j=1∑lblbvb,j
v b , m a x = max j = 1 l b v b , j v_{b,max} = \max_{j=1}^{l_b} v_{b,j} vb,max=j=1maxlbvb,j
v = [ v a , a v e ; v a , m a x ; v b , a v e ; v b , m a x ] v = [v_{a,ave}; v_{a,max}; v_{b,ave}; v_{b,max} ] v=[va,ave;va,max;vb,ave;vb,max]
2. 模型实现
模型核心代码见Python实战——ESIM 模型搭建(keras版)