跨境支付平台 XTransfer 的实时数仓之路:深度参与开源才能不被淘汰
近两年新冠肺炎疫情对各行各业造成重大冲击,但对于跨境电商行业来说则是机大于危,跨境支付赛道也因此备受关注。其中,受疫情影响,大量 B2B 外贸交易转到线上,相比起 B2C,B2B 跨境交易支付场景更为复杂,因为其业务场景也往往更为复杂、周期长、贸易参与角色众多。
另一方面,支付业务天然地对风险识别的及时性和准确性要求非常高,因此数据的采集、加工、计算就需要前置在每个业务节点、前瞻性地做好数据资产的维护工作。实时数仓和实时模型引擎,就是当前解决上述问题最合适的基础设施。近日,InfoQ 有幸接触到面向中小微外贸企业提供 B2B 跨境支付和风控服务的平台 XTransfer(上海夺畅网络技术有限公司),并通过采访得以了解其自行搭建实时数仓的实践过程和背后的思考,以及深度参与开源的方式。
采访嘉宾:
刘艳芳,XTransfer 联合创始人兼 CTO
康伟,XTransfer 技术专家
技术发展三阶段
XTransfer 于 2017 年创立,聚焦于 B2B 跨境支付,为从事跨境电商 B2B 出口的中小微企业提供外贸收款服务,以及风控服务,解决贸易风险问题。
从创立至今,XTransfer 的技术发展历程可大致分为三个阶段:
-
第一阶段(2017 年 7 月-2018 年 10 月):创业初期,需要先打造出基础平台,并把业务链路跑通,确保基础平台能够支撑业务的发展。在这个过程中,公司完成了整个基础平台体系的搭建。
-
第二阶段(2018 年 6 月-2021 年 7 月):提效,利用大数据等技术提升效率。例如在公司内部通过算法模型去提升风险审核的效率,降低人工工单审核的比例。此外,运用 OCR(光学字符识别)等机器学习技术帮助客户做一些数据处理工作。在这个阶段,公司开始推出新的产品。
-
第三阶段(2021 年 7 月至今):平台纵深发展,从单点的金融服务平台往更智能化、数字化的方向发展。比如,今年新推出外贸 CRM,总结出一套新的产品模式,帮助中小微外贸企业数字化转型。该阶段的重点在于如何将公司内部所沉淀积累的能力输出给中小微企业。
XTransfer 的技术平台和众多服务都是基于云基础设施来打造的,目前主要用的是阿里云,但包括华为云、腾讯云和百度云在内的云服务也都有在用。“企业发展到一定阶段,无论是出于成本还是稳定性的考虑,肯定要做多云方案。我们现阶段最大的考量点不是成本,而是打造更优质的产品和业务。”刘艳芳表示。
目前,公司研发团队大致分为两部分,一部分是业务职能团队,包括前端、后端、测试、运维等,另一部分是大数据和算法团队。无论是业务平台还是数据平台的开发,都是先做开源框架选型,再以自研工作为主。技术选型方面,以稳定性为第一出发点,并确保平台的稳定性、安全性和数据精确性。
实时数仓建设实践
自建方案更灵活
相较于 ToC 的场景,ToB 业务的数据量相对要少很多。刘艳芳指出,目前市场上流行的方案大多数能够有效解决大数据量计算和处理的问题,但是在安全性、稳定性和准确性上并没有达到金融级别的要求。
跨境支付+B 类支付结算场景所涉及的业务链路非常长,从询盘到最终成交,当中涉及物流条款、支付条款,需要在每个节点上做风险管控。跨境资金交易监管愈发严格。外贸企业进行收款和资金周转,这一过程受到金融机构及监管严格的反洗钱风险管理。以上种种因素对 XTransfer 的数据处理安全性和准确性都提出了更高的要求。
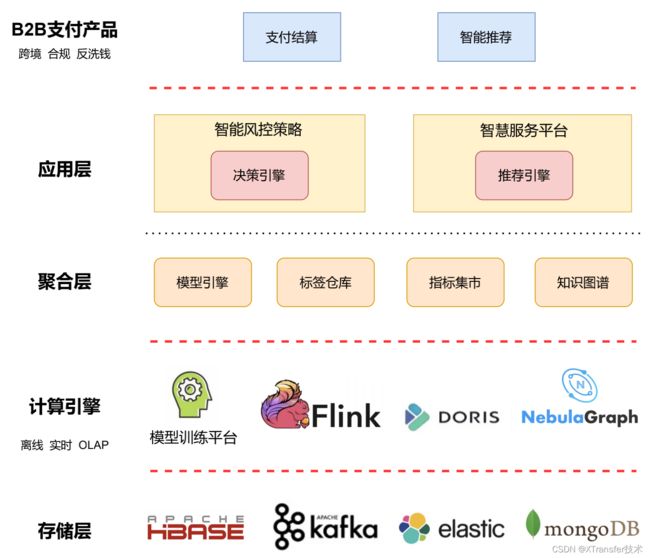
XTransfer 所打造的大数据风控基础设施架构图
据了解,XTransfer 在全球部署了 3 个数据中心,搭建了自己的实时数据仓库,能够有效地保障在跨境 B2B 业务全链路上,数据可以被有效采集、加工和计算,并满足高安全、低延时、高精度等需求。
对于初创型(用户量在百万以下)企业来说,对实时数仓的需求往往是部署和运维成本低、易开发、架构灵活简单、开箱即用,仅投入较少的人力和时间成本就能满足业务需求。
虽然市面上不少厂商都在推各种各样的实时数仓解决方案,但刘艳芳认为目前市场上所推出的实时数仓解决方案,多数针对 2C 营销类的场景,不能完全支撑 2B 跨境支付的复杂场景以及满足个性化需求。而自建的方案更灵活,能整合更多的框架和技术,去满足特定的业务场景。
因此,XTransfer 根据自身的 OLAP 场景需求,在自建数仓的基础上,支持灵活连接多种 OLAP 数据库,例如 Clickhouse、Doris 等,以满足不同需求。
设计思路
XTransfer 建设实时数据仓库的设计思路是以开源项目为基础,叠加二次开发。目前数据平台采用了 Lambda 架构,同时构建了流处理和批处理两种架构进行数据处理,并正在向流批一体数仓的方向演进:
-
在业务起步的早期,团队采用了批处理架构,数据仓库处理时效是 T+1(即:今天产生的数据分析结果明天才能看到)。随着业务的发展,通过更频繁的任务调度,提升批处理的时效,可以达到小时级。
-
当业务进入快速发展阶段,对数据的实时性要求越来越高,团队开始采用流处理架构,数据处理时效达到秒级。
-
对大数据量的离线数仓数据同步,采用 CDC(Change Data Capture) + Merge 的技术方案将数据同步至离线数仓 ODS 层,整体流程:进行一次性快照制作,将存量数据同步至 ODS;每天基于存量数据和当日的增量变更进行 Merge 还原。
技术选型
在数据仓库的维度建模中,XTransfer 选择了星型模型,使用分层设计方案来建设实时数仓,分层架构如下图所示:
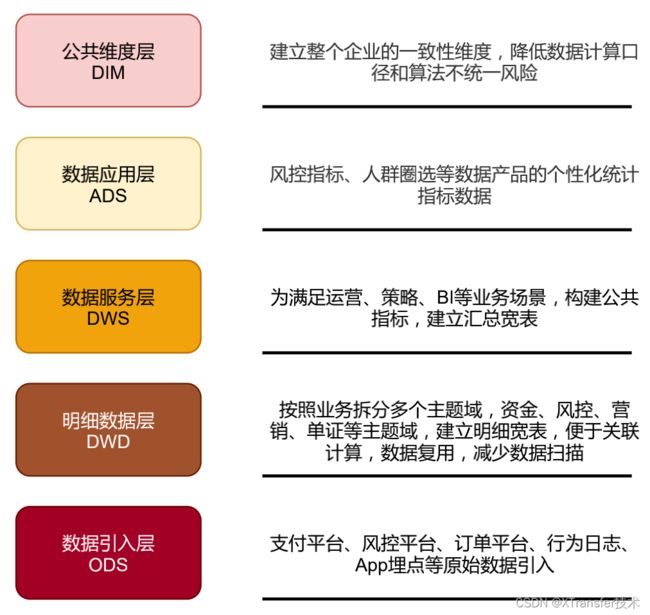
在做技术选型的过程中,往往会出现两种声音,一种是希望能从 0 到 1 建设,另一种是希望直接选用成熟的方案。XTransfer 也不例外,在这种情况下,解决方法是把各团队集结到一起去做深入探讨和研究,把关键路径分析出来,确定哪些需要自己去做、哪些是可以引用的、哪些是可以自己去做补充和完善的。
具体的技术选型方面,XTransfer 在实时数仓计算引擎上选择了开源流处理框架 Flink,因为它具备高吞吐、低延迟、高性能等优点,且技术成熟、社区活跃。做风控需要对全量数据进行捕捉,CDC(Change Data Capture,用于捕捉数据库表的增删改查操作) 是内部比较倾向的方案,因此最终使用了 Flink CDC Connectors,这是 Flink 的一组 Source 连接器,是 Flink CDC 的核心组件,这些连接器负责从 MySQL、PostgreSQL、Oracle、MongoDB 等数据库读取存量历史数据和增量变更数据。
实时数仓存储方面选择了 Kafka,使用 Kafka compacted topic 存储数仓 ODS、DWD、DWS 层的数据。使用 upsert-kafka 连接器以 upsert 方式从 Kafka topic 中读取数据并将数据写入 Kafka topic。作为 source,upsert-kafka 连接器生产 changelog 流,其中每条数据记录代表一个更新或删除事件。作为 sink,upsert-kafka 连接器可以消费 changelog 流。它会将 INSERT/UPDATE 数据作为正常的 Kafka 消息写入,并将 DELETE 数据以 value 为空的 Kafka 消息写入,表示对应 key 的消息被删除。
在 OLAP 引擎的选型上,团队结合 XTransfer 的研发资源情况、业务需求以及使用场景,选择了 Apache Doris,具体有以下几点考虑:
-
选择 ROLAP 模式,模型简化,模型复用率高,开发效率高,低冗余,省空间;
-
同时支持离线批量导入和实时数据导入,支持事务和幂等性导入;
-
采取分区分桶的机制,支持多种索引技术,满足 PB 级的存储和分析能力;
-
使用列式存储和压缩技术,提升查询性能;
-
兼容 MySQL 访问协议,简单、易用;
-
运维更简单,内置分布式协议,支持集群的在线动态扩缩容,故障节点自动恢复;
-
一站式的分析解决方案,只需少量投入研发资源,开箱即用。
深度参与开源
从开源中受益,并力所能及地反哺社区,是 XTransfer 技术团队所遵循的原则。前面提到他们使用了 Flink CDC Connectors,这也是一个独立的开源项目。日前,Flink 社区已经正式发布 Flink CDC 2.1 版本,重点提升 MySQL CDC 连接器的性能和生产稳定性,并新增了 Oracle CDC 连接器和 MongoDB CDC 连接器,其中,XTransfer 技术专家孙家宝贡献了 MongoDB CDC 连接器。
MongoDB CDC 连接器支持从 MongoDB 数据库获取全量历史数据和增量变更数据。借助 Flink 的集成能力,用户可以非常方便地将 MongoDB 中的数据实时同步到 Flink 支持的所有下游存储。
在数据捕获的整个过程中,用户不需要学习 MongoDB 的副本机制和原理,大大简化了流程,降低了使用门槛。MongoDB CDC 也支持两种启动模式:默认的 initial 模式是先同步表中的存量的数据,然后同步表中的增量数据;latest-offset 模式则是从当前时间点开始只同步表中增量数据。
此外,MongoDB CDC 还提供了丰富的配置和优化参数,对于生产环境来说,这些配置和参数能够极大地提升实时链路的性能和稳定性。
康伟表示,XTransfer 大数据团队目前也在关注 Flink Connector、Flink Table API、Flink + Iceberg 等领域的建设。接下来,XTransfer 会持续优化 MongoDB CDC,比如提升并行度,优化对大表同步的支撑等。在与社区其他开发者的交流中,团队发现大家对于 MongoDB 在 Sink Connector 方面也有很大的需求,因此也正在做这部分开发。
目前,XTransfer 团队已经向社区提报并解决的相关 issue:
FLINK-6573 Flink MongoDB ConnectorFLINK-21172 “canal-json format include es field”FLINK-21949 Support collect to array aggregate functionDBZ-3966 JsonTableChangeSerializer support serialization for defaultValue
正在关注跟进的 issue:
FLINK-22793 HybridSource Table ImplementationICEBERG-1639 Flink: write the CDC records into apache iceberg tables.
写在最后
在交流中,InfoQ 了解到 XTransfer 选择自行搭建实时数仓的原因也和公司所坚持的“长期有耐心”的理念息息相关——“必须要做长期的解决方案,不做不断推倒重来的事。”对此,刘艳芳进一步解释道,“目前我们的方案能针对性解决我们遇到的问题,同时我们能充分掌握里面的核心技术,而它也是符合未来社区发展趋势的解决方案,我们从社区的发展中获益之余也能够贡献给社区,这能保证我们不被淘汰。”
至于“不被淘汰”的衡量标准,则跟社区贡献有关。刘艳芳对团队有两点要求,一要跟上社区的变化;二是“能给社区贡献”,能贡献就说明被社区接纳,自身是处于和社区同步发展的轨道。
总的来说,XTransfer 正试图用一种更务实的方式去深度参与社区,并紧跟社区的脚步。“当下,我们可能没有那么大的力量,不像大厂能一下子贡献一整个模块,但我们也有能力去贡献差异化的产出。未来,我们会持续探索,创造更多可能性。”