linux服务器配置深度学习环境,看这一篇就够了
文章目录
- 一、root登录服务器
- 二、挂载磁盘
-
- 1、挂载概念
- 2、查看磁盘情况(已挂载的信息)
- 3、查看当前磁盘分区状况
- 4、分区
- 5、格式化
- 7、挂载
- 8、查看挂载后的情况
- 9、实现自动挂载
- 10、重启验证
- 三、创建新用户
-
- 1、添加新用户,用于以后登录,避免使用root用户出现误操作情况
- 2、修改用户登录shell
- 3、修改用户的附加组
- 四、安装英伟达驱动
-
- 1、查看Linux系统是否已经安装了Nvidia驱动
- 2、下载Nvidia官方驱动程序
- 五、创建软链接
- 六、安装Anaconda
-
- 1、Anaconda的下载
- 2、Anaconda的安装
- 3、anaconda换国内源
- 七、安装cuda和cudnn
-
- 1、验证系统内部是否已经安装了cuda:
- 2、进行cuda安装包与cudnn的下载
- 3、进行cuda安装
- 4、进行cudnn的安装
- 八、pytorch环境搭建
- 九、docker安装
-
- nvidia-docker安装
- 1. 安装Dokcer-CE
- 2. 安装NVIDIA Container Toolkit
- 3、更换docker镜像源
- 4、修改Docker默认存储位置
一、root登录服务器
安装xshell,并root登录服务器
第一步 去官方下载界面
https://www.netsarang.com/zh/free-for-home-school/
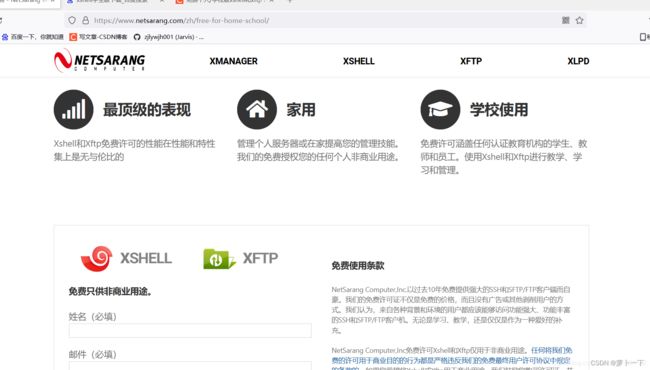
第二步 填写正确的手机号和密码,之后会有一个下载链接
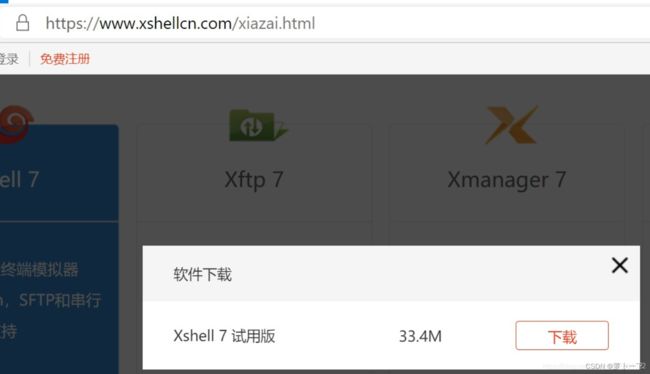
免费版的下载地址
https://www.netsarang.com/zh/free-for-home-school/

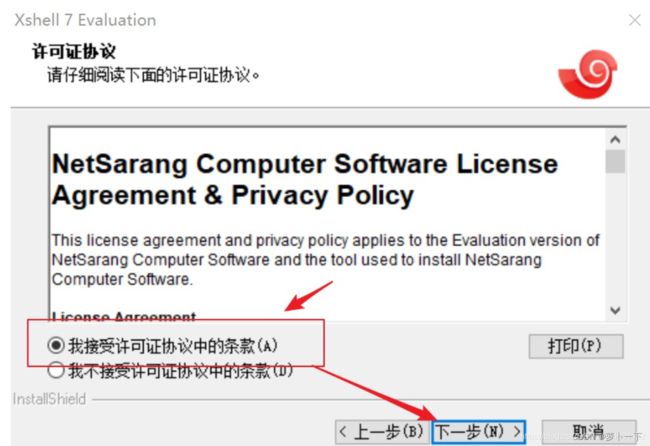
第三步 安装Xshell
双击exe文件,进入安装界面

接受统一许可证书
选择安装路径
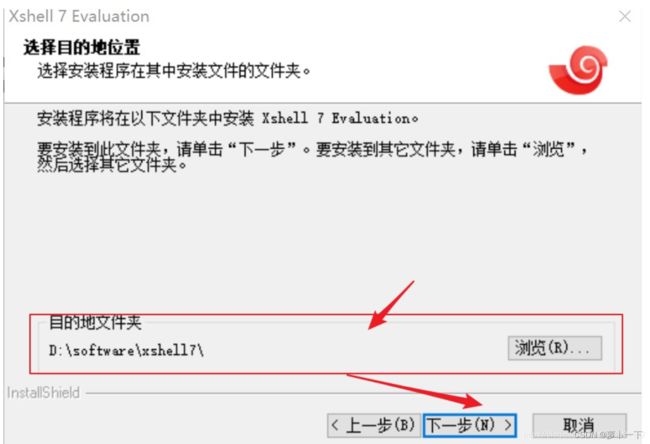
随便选择一个图画的目录
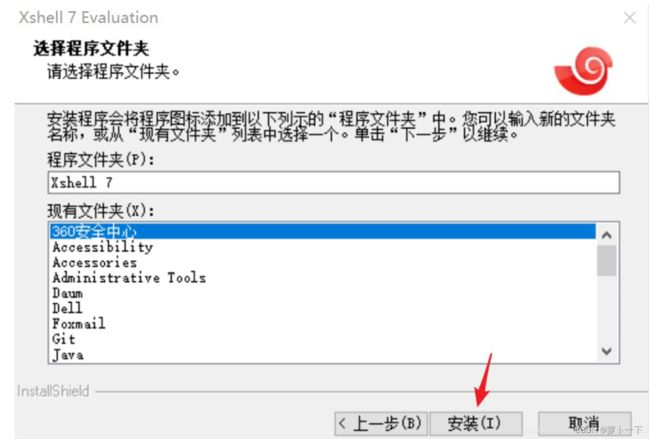
进入安装界面,等待安装完成


第四步 设置ssh配置链接
设置名称、主机、端口

设置链接方式,我选的账号和密码
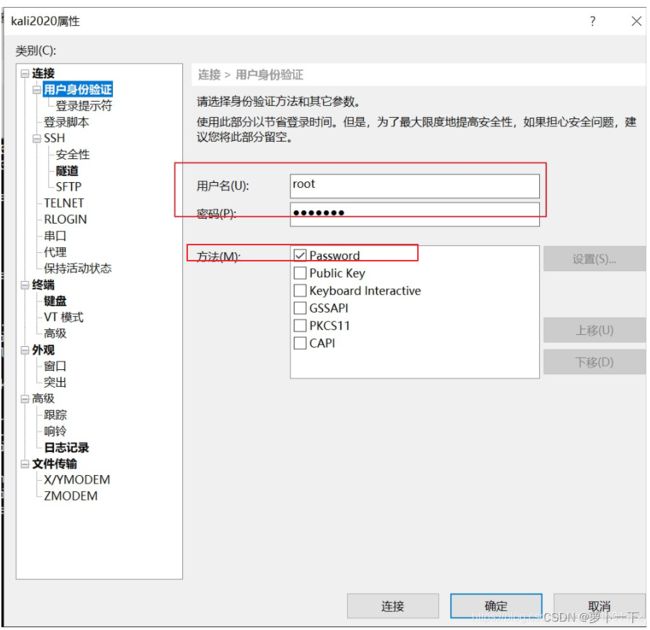
选择接受密钥
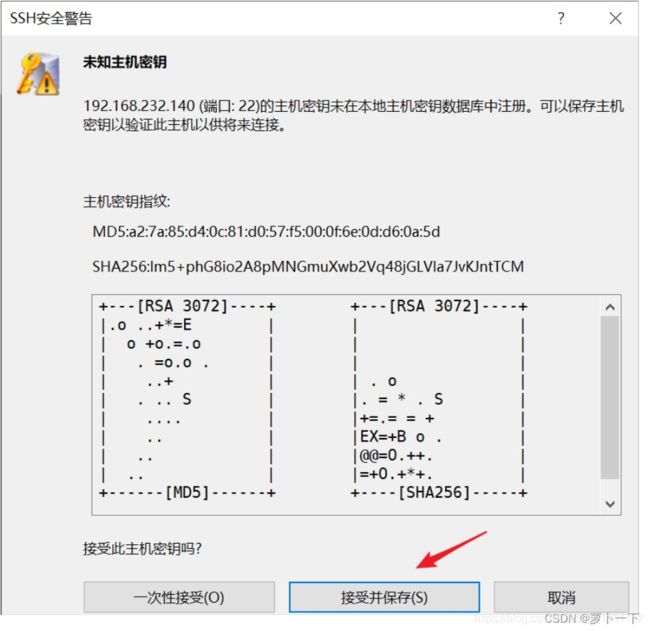
成功链接主机

二、挂载磁盘
1、挂载概念
挂载(mounting)是指由操作系统使一个存储设备(诸如硬盘、CD-ROM或共享资源)上的计算机文件和目录可供用户通过计算机的文件系统访问的一个过程。
在windows操作系统中:挂载通常是指给磁盘分区(包括被虚拟出来的磁盘分区)分配一个盘符。
在linux操作系统中:它指将一个设备(通常是存储设备)挂接到一个已存在的目录上。
2、查看磁盘情况(已挂载的信息)
df -h

3、查看当前磁盘分区状况
若无输出内容,此情况为用户权限不够,需要使用root用
fdisk -l
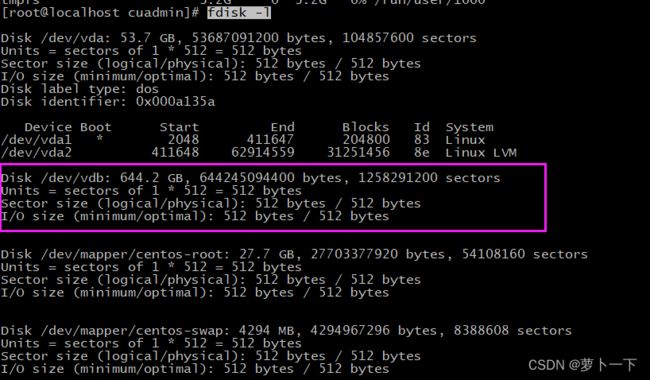
可以明显看到/dev/vdb中还有很多空间没有使用
4、分区
fdisk /dev/vdb

查看分区情况
lsblk

5、格式化
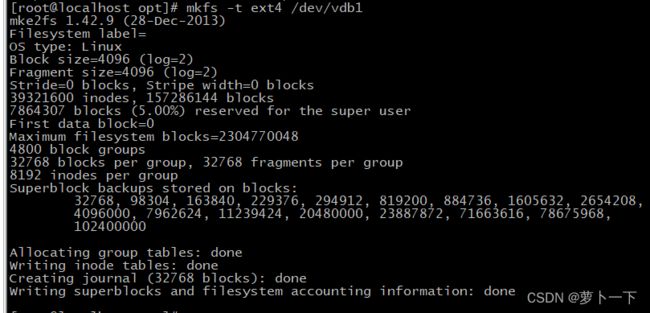
mkfs.xfs /dev/vdb1
# 或者
mkfs -t ext4 /dev/vdb1

7、挂载
将设备 /dev/vdb1 挂载到 /data目录
mkdir /data
mount /dev/vdb1 /data
8、查看挂载后的情况
df -h
fdisk -l
lsblk -f

9、实现自动挂载
通过修改/etc/fstab实现自动挂载,添加完成后,执行mount -a 即可生效
vim /etc/fstab
# 添加一行
/dev/vdb1 /data ext4 defaults 0 0

10、重启验证
挂载后,一定要重启验证一下,如果你挂载的不消失,则可以进行下一步安装,否则你安装的东西会全被格式化
如果重启之后,发现挂载消失了,检查一下 vim /etc/fstab里面配置的和挂载的是不是一致。
![]()
![]()
参考:linux磁盘挂载
三、创建新用户
1、添加新用户,用于以后登录,避免使用root用户出现误操作情况
useradd 选项 用户名
参数说明:
选项:
-c comment 指定一段注释性描述。
-d 目录 指定用户主目录,如果此目录不存在,则同时使用-m选项,可以创建主目录。
-g 用户组 指定用户所属的用户组。
-G 用户组,用户组 指定用户所属的附加组。
-s Shell文件 指定用户的登录Shell。
-u 用户号 指定用户的用户号,如果同时有-o选项,则可以重复使用其他用户的标识号。
用户名:
指定新账号的登录名。
例如:
创建asd用户,并创建asd的用户主目录。该目录为/home/asd。默认添加用户所属的用户组为asd。
useradd -m asd
查看用户信息
cat /etc/passwd|grep asd
![]()
2、修改用户登录shell
usermod -s /bin/bash 用户名
这样下次登录asd用户时可以直接进入shell命令
3、修改用户的附加组
当我们不添加用户的sudo附加组时,创建的新用户会报错,没有权限使用sudo命令

这时,我们需要给用户添加附加组,使我们的新用户可以以root身份执行相关命令。
usermod -G 组 用户名
默认使用 useradd 添加的用户是没有权限使用 sudo 以 root 身份执行命令的,可以使用以下命令,将用户添加到 sudo 附加组中
usermod -G sudo asd
这样asd用户就可以使用sudo命令以root身份执行命令了。
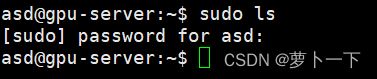
没有报错,说明可以使用该命令了。
四、安装英伟达驱动
1、查看Linux系统是否已经安装了Nvidia驱动
输入命令:
nvidia-smi
进行查看。
如果输出以下信息,则Linux系统中已经安装了Nvidia驱动。

如果没有以上的输出信息,则开始进行Nvidia驱动的安装。
2、下载Nvidia官方驱动程序
第一步.
查看自己的显卡型号,下载对应的驱动。命令行输入:lspci | grep NVIDIA
lspci | grep NVIDIA
对应输出以下信息:
![]()
有的不显示具体显卡名称。比如
![]()
我们可以通过该网址:The PCI ID Repository,查询具体显卡型号。
参考:
Linux(Ubuntu)系统查看显卡型号
Ubuntu系统查看显卡型号NVIDIA Corporation [10DE:1E82] -display UNCLAIMED

第二步.
去NVDIA driver search page查看支持显卡的驱动最新版本及下载,下载之后是.run后缀。
从该网址下载与显卡型号对应的显卡驱动程序:英伟达驱动下载
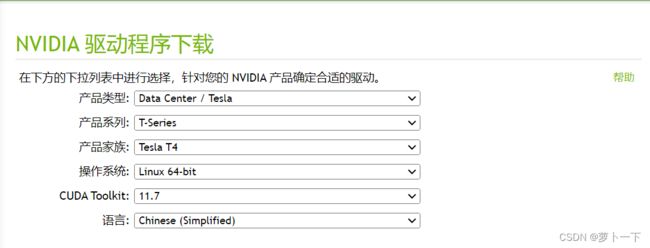
第三步.
把驱动文件拷贝到/tmp目录下,然后cd /tmp进入目录。
第四步.
我的安装文件名为:NVIDIA-Linux-x86_64-515.65.01.run。执行以下命令进行安装,文件名替换为自己的。
sudo sh NVIDIA-Linux-x86_64-515.65.01.run -no-x-check -no-nouveau-check -no-opengl-files
代码注释:
-no-x-check #安装驱动时关闭X服务
-no-nouveau-check #安装驱动时禁用nouveau
-no-opengl-files #只安装驱动文件,不安装OpenGL文件
第五步.
安装提示进行安装,点yes、ok什么的,安装完之后输入nvidia-smi,显示如下: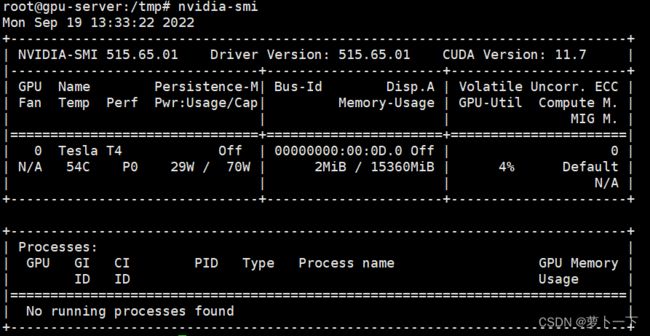
如果提示以上信息,则安装成功。
参考:CentOS7.4安装Nvidia Tesla T4驱动
Linux下Nvidia驱动的安装
五、创建软链接
缓解空间不足,用软链接可以,以下为大致思路:
假设系统只有一个/分区。另加一块硬盘也只有一个分区,挂载在/data目录中
/中的/usr和/home占用空间最多,想把这两个目录内容都转移到新硬盘中,但又不想挂载两个分区,可以用软链接。
就是用root身份登录,不启动其他程序,把/usr和/home移动到/data中。然后在/中建立两个软链接。
cd / # 回到主目录
mv /home/asd/software /data # 将usr文件夹移到data目录下
mv /home/asd/project /data # 将home文件夹移到data目录下
ln -s /data/software /home/asd/software # 建立软链接
ln -s /data/project /home/asd/project # 建立软链接
这样,/home/asd/software和/home/asd/project目录中的东东就都移到新硬盘中了。
六、安装Anaconda
Anaconda的安装主要是为了方便环境管理,可以同时在一个电脑上安装多种环境,不同环境放置不同框架:pytorch、tensorflow、keras可以在不同的环境下安装,只需要使用conda create –n创建新环境即可。
1、Anaconda的下载
如果具有可视化界面的系统,可以直接进入首先登录Anaconda的官网:https://www.anaconda.com/distribution/。直接下载对应安装包就可以。
一般是下载64位的,下载完成后打开。
除此之外,也可以通过wget指令直接在终端中进行下载。具体如图所示。

下载完成后,目录下会出现对应的sh文件。即anaconda的安装文件。
2、Anaconda的安装
首先通过指令将sh文件设置成可执行的。
sudo chmod -R 777 Anaconda3-2022.05-Linux-x86_64.sh

然后利用下列指令执行sh文件。
./Anaconda3-2022.05-Linux-x86_64.sh
执行后就是一堆需要遵守的协议,一般这个时候啊对对对就可以了。
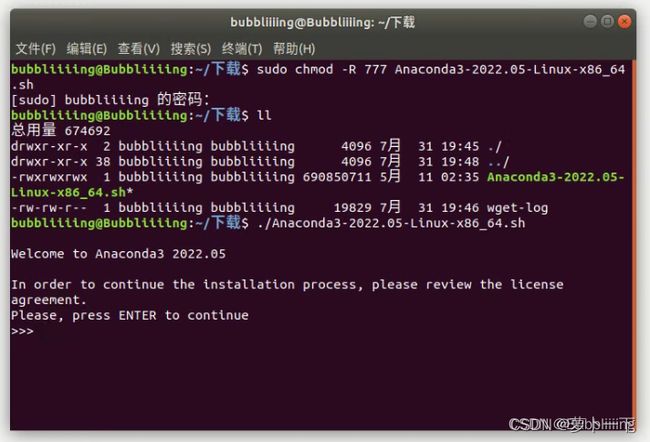
中间有一大串的协议,按空格会跳过的快一些。然后输入yes,否则不会正常安装。
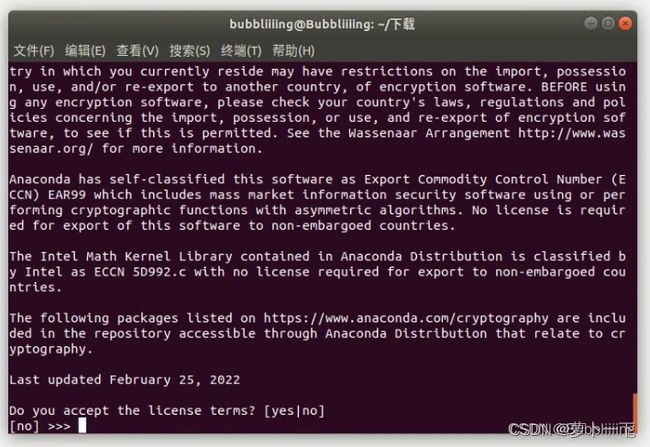
然后选择安装路径,这个同学们根据自己的需求进行安装就可以了,默认会安装在~文件夹下。输入地址,如/home/asd/software/anaconda3,然后点击Enter,Anaconda会开始自动安装。

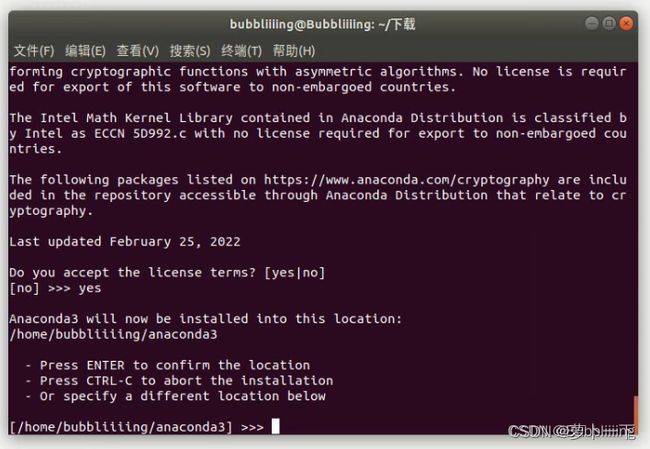
这一步建议选择yes,conda环境会自动初始化,可以去掉一些繁琐的步骤。

再次打开就有base的环境了。

![]()
参考:深度学习环境配置10——Ubuntu下的torch==1.7.1环境配置
3、anaconda换国内源
Linux 下换清华源,(windows应该也可以用,未测试)直接执行一下命令
conda config --add channels https://mirrors.tuna.tsinghua.edu.cn/anaconda/pkgs/free/
conda config --add channels https://mirrors.tuna.tsinghua.edu.cn/anaconda/cloud/conda-forge
conda config --add channels https://mirrors.tuna.tsinghua.edu.cn/anaconda/cloud/msys2/
conda config --set show_channel_urls yes
或者将一下内容写入~/.condarc
channels:
- https://mirrors.ustc.edu.cn/anaconda/pkgs/main/
- https://mirrors.ustc.edu.cn/anaconda/cloud/conda-forge/
- https://mirrors.tuna.tsinghua.edu.cn/anaconda/pkgs/free/
- defaults
show_channel_urls: true
输入conda info可以查看
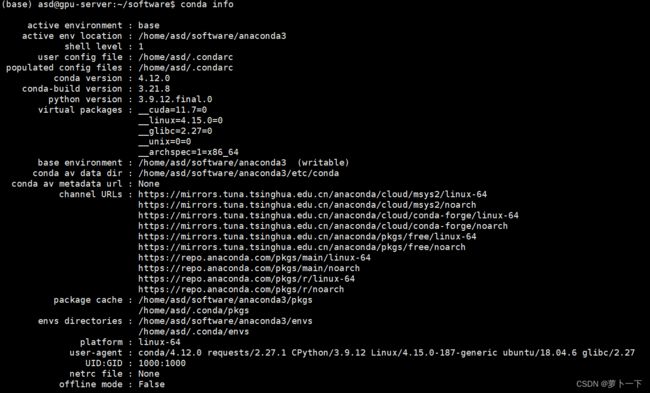
七、安装cuda和cudnn
1、验证系统内部是否已经安装了cuda:
nvcc -V
若出现以下输出,则系统内部没有安装cuda。

2、进行cuda安装包与cudnn的下载
cuda的下载链接:cuda下载链接
选择cuda版本11.0.3。cudnn版本8.0.4,具体自己试着查找。查看对应版本
cudnn的下载链接:cudnn下载链接
在下载这两个文件的时候,需要注意cudnn的版本需要与cuda的版本相匹配。
3、进行cuda安装
在进行cuda安装之前,我们需要先安装cuda的相关依赖库,防止cuda安装出现错误。命令行输入以下命令,进行相关依赖库的安装:
sudo apt-get install freeglut3-dev build-essential libx11-dev libxmu-dev libxi-dev libgl1-mesa-glx libglu1-mesa libglu1-mesa-dev
随后,输入以下命令进行cuda的安装:
sudo sh cuda_11.0.3_450.51.06_linux.run //其中cuda_11.0.3_450.51.06_linux.run是我们下载的cuda安装文件
输入上述命令后,稍有卡顿,随后出现以下界面:
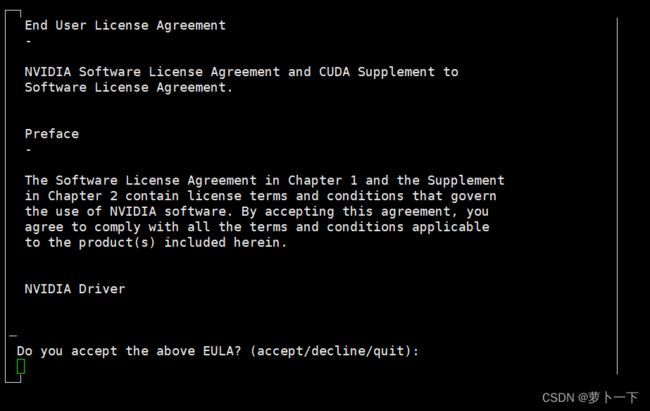
输入accept进行后续操作,随即出现以下界面:


因为我们在安装cuda之前已经安装了Nvidia的驱动,因此这里的第一项我们必须取消勾选,选择不安装驱动,随后选择Install进行后续操作。
后续出现的一系列选项,我们都可以选择yes,最终出现以下界面:
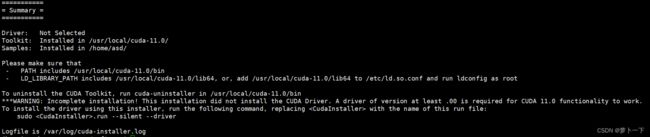
随后,我们开始进行环境变量的配置:
打开命令行输入以下命令进行~/.bashrc文件的修改:
vim ~/.bashrc
如果使用的是zsh,则修改~/.zshrc
在文件的末尾加入下面三行:
export LD_LIBRARY_PATH=$LD_LIBRARY_PATH:/usr/local/cuda/lib64
export PATH=$PATH:/usr/local/cuda/bin
export CUDA_HOME=$CUDA_HOME:/usr/local/cuda
随后命令行输入以下命令保存并退出:
wq!
在添加完环境变量后,需要更新一下环境变量,命令行输入以下命令进行环境变量的更新:
source ~/.bashrc
命令行输入以下命令,验证cuda是否安装成功:
nvcc -V
如果出现以下输出,则cuda安装成功:

4、进行cudnn的安装
进入到cudnn下载的安装路径下,命令行输入以下命令进行解压操作:
tar -xzvf cudnn-11.0-linux-x64-v8.0.4.30.tgz //这里cudnn-11.0-linux-x64-v8.0.4.30.tgz是我们下载的cudnn的压缩包
随后在当前路径的命令行终端输入以下三条命令进行cudnn的安装:
sudo cp cuda/include/cudnn.h /usr/local/cuda/include
sudo cp cuda/lib64/libcudnn* /usr/local/cuda/lib64
sudo chmod a+r /usr/local/cuda/include/cudnn.h /usr/local/cuda/lib64/libcudnn*
至此cuda与cudnn全部安装成功。
如果安装了多个版本的cuda和cudnn,可以参考Linux下安装cuda和对应版本的cudnn,查看多个cuda版本切换的方法。
八、pytorch环境搭建
进入pytorch官网,根据官方推荐下载对应版本pytorch
# CUDA 11.0
conda install pytorch==1.7.1 torchvision==0.8.2 torchaudio==0.7.2 cudatoolkit=11.0 -c pytorch
这是官方给的下载版本,我们下载对应的cuda版本
0、建立虚拟环境
conda create –n pytorch python=3.8
激活环境
conda activate pytorch
1、
# CUDA 11.0
pip install torch==1.7.1+cu110 torchvision==0.8.2+cu110 torchaudio==0.7.2 -f https://download.pytorch.org/whl/torch_stable.html
2、
conda install cudatoolkit=11.0 -c pytorch
3、新建requirements.txt文件,输入以下内容
scipy==1.7.1
numpy==1.21.2
matplotlib==3.4.3
opencv_python==4.5.3.56
torch==1.7.1
torchvision==0.8.2
tqdm==4.62.2
Pillow==8.3.2
h5py==2.10.0
PyYAML>=5.3.1
tensorboard>=2.4.1
seaborn>=0.11.0
pandas
pycocotools>=2.0
coremltools>=4.1
onnx>=1.8.1
scikit-learn==0.19.2 # for coreml quantization
4、
pip install -r requirements.txt -i https://pypi.tuna.tsinghua.edu.cn/simple
九、docker安装
nvidia-docker安装
Nvidia-Docker安装需要安装两个部分,Docker-CE和NVIDIA Container Toolkit。
1. 安装Dokcer-CE
Docker-CE on Ubuntu can be setup using Docker’s official convenience script:
官方的快速安装脚本,具体安装的版本应该是最新版,如果用此脚本安装Docker,以后还可以使用此脚本更新:
curl https://get.docker.com | sh \
&& sudo systemctl --now enable docker
注意:如果你的机器已经有安装Docker,那么使用这个脚本可能会出错,要是你本机的Docker就是用这个脚本安装的,那么你可以再次用这个脚本进行更新。
安装成功后出现这个界面

激活docker
sudo /lib/systemd/systemd-sysv-install enable docker
激活后查看docker版本
docker --version
出现以下界面说明安装成功。
![]()
2. 安装NVIDIA Container Toolkit
设置稳定版本的库及GPG密钥
distribution=$(. /etc/os-release;echo $ID$VERSION_ID) \
&& curl -s -L https://nvidia.github.io/nvidia-docker/gpgkey | sudo apt-key add - \
&& curl -s -L https://nvidia.github.io/nvidia-docker/$distribution/nvidia-docker.list | sudo tee /etc/apt/sources.list.d/nvidia-docker.list
Optional:如果想要使用实验特性,需要加入experimental分支到库下:
curl -s -L https://nvidia.github.io/nvidia-container-runtime/experimental/$distribution/nvidia-container-runtime.list | sudo tee /etc/apt/sources.list.d/nvidia-container-runtime.list
更新好包列表之后,安装nvidia-docker2包及其依赖:
sudo apt-get update
sudo apt-get install -y nvidia-docker2
安装完毕…
然后进入/etc/docker/daemon.json文件
sudo vim /etc/docker/daemon.json
添加以下内容
{
"registry-mirrors": ["https://sx1pmhon.mirror.aliyuncs.com"],
"runtimes": {
"nvidia": {
"path": "nvidia-container-runtime",
"runtimeArgs": []
}
}
}
上述默认运行时设置好后,重启Docker后台驻留程序:
sudo systemctl daemon-reload
sudo systemctl restart docker
3、更换docker镜像源
sudo mkdir -p /etc/docker
sudo tee /etc/docker/daemon.json <<-'EOF'
{
"registry-mirrors": ["https://sx1pmhon.mirror.aliyuncs.com"]
}
EOF
sudo systemctl daemon-reload
sudo systemctl restart docker
现在可以通过运行base CUDA container来测试一个working setup
sudo docker run --rm --gpus all nvidia/cuda:11.0-base nvidia-smi
会pull下nvidia/cuda:11.0-base这个镜像
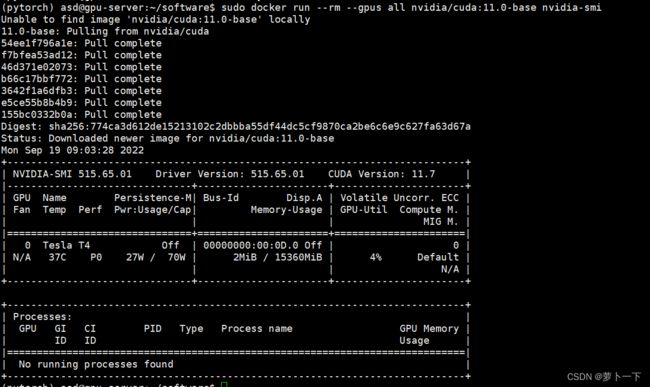
此时这个实例就已经在Docker的镜像库中了:使用sudo docker images -a查看已下载的镜像:

4、修改Docker默认存储位置
在 ubuntu系统中,docker 默认安装存储位置为 /var/lib/docker。当镜像多了以后,会占用大量的存储空间,当所在的分区存储空间不足时,我们可以通过扩展磁盘空间,或者修改 docker 配置中的存储位置来解决上述问题。
零 确定存储位置
我们可以通过 docker info | grep "Docker Root Dir"命令查看docker的默认存储位置,下面以 ubuntu18.04 系统上的 /var/lib/docker 为例。
Note: 写本博客时使用的 docker 版本为 20.10.18,系统版本为 ubuntu18.04
① 软链接
软链接 (Symbolic Link),也称符号链接,这里不再详细介绍。最简单的修改方法是将原docker 目录下的文件迁移到新的目录,然后将原目录链接到新的目录,这种方法的好处是不用修改 docker 配置,从系统文件操作的层面来解决。方法如下:
(1) 首先停止 docker 服务:
systemctl stop docker
(2) 然后移动整个 /var/lib/docker 目录到目的路径(/data/docker):
mv /var/lib/docker /data/docker
(3) 创建软链接
ln -s /data/docker /var/lib/docker
Note:命令的意思是 /var/lib/docker 是链接文件名,其作用是当进入/var/lib/docker目录时,实际上是链接进入了 /data/docker 目录
(4) 重启 docker
systemctl start docker
② 修改 docker 配置文件
也可以通过修改 docker.service 文件,使用 --graph newPath 参数指定存储位置,方法如下:
(1) 首先停止 docker 服务:
systemctl stop docker
(2) 然后移动整个 /var/lib/docker 目录到目的路径(/data/docker):
mv /var/lib/docker /data/docker
(3) 修改 docker.service 文件
ubuntu下默认路径为 /usr/lib/systemd/system/docker.service
vim /usr/lib/systemd/system/docker.service
在 ExecStart=/usr/bin/dockerd 后面添加参数 --graph /data/docker
结果如下
ExecStart=/usr/bin/dockerd --graph /data/docker -H fd:// --containerd=/run/containerd/containerd.sock
(4) 重启 docker 服务
systemctl daemon-reload
systemctl start docker
(5) 查看配置是否生效
docker info | grep "Docker Root Dir"
Docker Root Dir: /data/docker