零基础搭建基于知识图谱的电影问答系统
零基础搭建基于知识图谱的电影问答系统
-
- 一、项目准备
- 二、项目数据
- 三、训练问题分类器
- 四、准备问答模板
- 五、搭建webapp
- 六、问题预处理
一、项目准备
- 首先需要一款python编译器,本人选用的是PyCharm,搭建好Python环境;
- 安装第三方依赖库,源码文件夹中的
requirements.txt文件中说明了需要用到的第三方库和对应版本; - 本项目采用图数据库进行存储,利用Neo4j图像数据库,可以参照本人博客:全网最详细的Neo4j安装教程进行安装。
那么至此,Python环境和知识图谱的存储环境已经搭建完成,接下来需要获取数据。
二、项目数据
数据采用的是IMDB互联网电影资料库中的数据,IMDB是一个关于电影演员、电影、电视节目、电视明星和电影制作的在线数据库,包括了影片的众多信息、演员、片长、内容介绍、分级、评论等。对于电影的评分使用最多的就是IMDb评分。
利用爬虫获取数据如下:

其中movie、person、genre为数据表,movie_to_genre、person_to_movie两张关系表建立起电影与类型、电影与角色之间的关系。表中相关字段如下:
1.movie.csv(mid:电影序号;title:电影标题;introduction:电影简介;rating:电影评分;releasedate:发布日期)
![]()
2.person.csv(pid:演员序号;birth:出生日期;death:离世日期;name:演员姓名;biography:生平简介;birthplace:出生地)
![]()
3.person_to_movie.csv(pid:演员序号;mid:电影序号)
 4.genre.csv(gid:类型序号;gname:类型名称)
4.genre.csv(gid:类型序号;gname:类型名称)
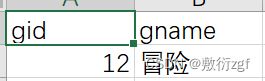
5.movie_to_genre.csv(mid:电影序号;gid:角色序号)

数据获取完成后,将其导入Neo4j图形数据库中。
1.首先将五张数据表放入Neo4j安装目录中的import文件夹下
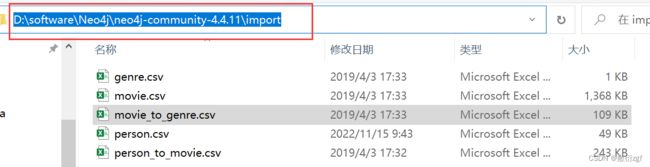
2.打开Neo4j,依次执行以下代码
建立连接,此时经常会连接不上,原因是7474端口被占用,查看被占用端口:netstat -ano |findstr 7474

关闭端口:taskkill /t /f /pid 9244

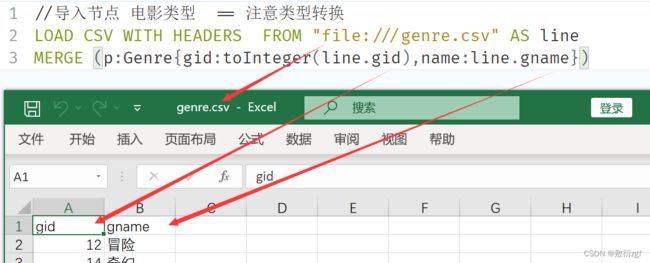
(1)导入电影类型genre.csv
//导入节点 电影类型 == 注意类型转换
LOAD CSV WITH HEADERS FROM "file:///genre.csv" AS line
MERGE (p:Genre{gid:toInteger(line.gid),name:line.gname})

(2)导入演员数据person.csv
//导入节点 演员信息
LOAD CSV WITH HEADERS FROM 'file:///person.csv' AS line
CREATE (p:Person { pid:toInteger(line.pid),birth:line.birth,
death:line.death,name:line.name,
biography:line.biography,
birthplace:line.birthplace})


(3)导入电影数据movie.csv
// 导入节点 电影信息
LOAD CSV WITH HEADERS FROM "file:///movie.csv" AS line
MERGE (p:Movie{mid:toInteger(line.mid),title:line.title,introduction:line.introduction,
rating:toFloat(line.rating),releasedate:line.releasedate})


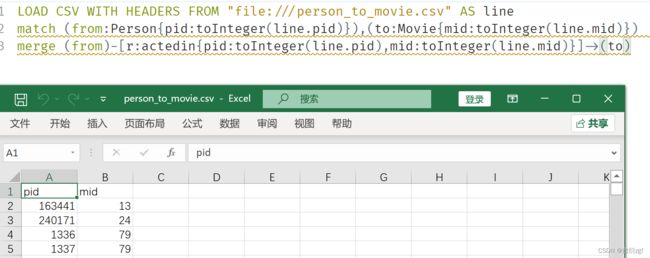
(4)创建电影与演员之间的关系person_to_movie.csv
// 创建电影与演员之间的关系 actedin 电影是谁参演的 1对多
LOAD CSV WITH HEADERS FROM "file:///person_to_movie.csv" AS line
match (from:Person{pid:toInteger(line.pid)}),(to:Movie{mid:toInteger(line.mid)})
merge (from)-[r:actedin{pid:toInteger(line.pid),mid:toInteger(line.mid)}]->(to)

(5)创建电影与类型之间的关系movie_to_genre.csv
//导入关系 电影是什么类型 == 1对多
LOAD CSV WITH HEADERS FROM "file:///movie_to_genre.csv" AS line
match (from:Movie{mid:toInteger(line.mid)}),(to:Genre{gid:toInteger(line.gid)})
merge (from)-[r:is{mid:toInteger(line.mid),gid:toInteger(line.gid)}]->(to)


至此,知识图谱的数据存储已经建立完毕!

三、训练问题分类器
针对用户提出的不同问题,需要给与对应的答案,因此需要对问题进行分类。如何识别用户的问题属于那一类,因此需要选择分类器,训练分类器的数据可以从github中下载:https://gitcode.net/mirrors/irvingbei/simple_movie_qa_with_kg?utm_source=csdn_github_accelerator

四、准备问答模板
![]()

五、搭建webapp
基于下图目录结构,将文件资源导入即可


六、问题预处理
输入框接收到用户提出的问题后,首先需要获取问题中的询问对象是什么,即主语,是人还是电影,这就涉及到自然语言处理中的命名实体识别;接着还需要从问题中了解到用户的意图,这就涉及到文本表示问题,最基本的文本表示方法是one-hot形式,在项目中使用的是sklearn中的TF-IDF工具。
1.关键信息抽取
通过命名实体识别来获取用户问题中的人名,电影名等信息,在本项目中,通过词性标注工具可以把人名标注出来,通过自定义字典,把所涉及到的所有电影,所有人名和所有电影类型名称都加到了这个字典中,jieba分词的时候就会参考字典里面的词来进行分词和词性标注了,自定义词典的格式如下:
# 电影名称 nm
Forrest Gump 15 nm
Kill Bill: Vol. 1 15 nm
英雄 15 nm
......
# 演员名称 nr
张学友 15 nr
刘德华 15 nr
林雪 15 nr
......
# 电影类型 ng
冒险 15 ng
奇幻 15 ng
动画 15 ng
......
分词与词性标注同步进行,代码实现如下:
def question_posseg(self):
# 加载自定义词库
jieba.load_userdict("./data/userdict3.txt")
# 去除问题中的特殊符号
clean_question = re.sub("[\s+\.\!\/_,$%^*(+\"\')]+|[+——()?【】“”!,。?、~@#¥%……&*()]+","",self.raw_question)
self.clean_question=clean_question
# 调用jieba 进行分词
# 例如 clean_question = '章子怡的生日'
question_seged=jieba.posseg.cut(str(clean_question))
result=[]
question_word, question_flag = [], []
for w in question_seged:
# '章子怡/nr' 每一个word后拼接 / 词性
temp_word=f"{w.word}/{w.flag}"
result.append(temp_word)
# 预处理问题
word, flag = w.word,w.flag
print('word:', word)
print('flag:' ,flag)
question_word.append(str(word).strip())
print('question_word:', question_word)
question_flag.append(str(flag).strip())
print('question_flag:', question_flag)
# 最终得到 question_word: ['章子怡', '的', '生日'] 对应 question_flag: ['nr', 'uj', 't']
assert len(question_flag) == len(question_word) # 两个列表长度相等
self.question_word = question_word
self.question_flag = question_flag
print(result) # ['章子怡/nr', '的/uj', '生日/t']
return result
2.问题分类和模板填充
接下来需要对用户的问题进行分类,获取对应问题模板,从而明白用户的意图,首先要根据用户习惯构造的各种各样的问题来训练一个分类器,该项目使用的sklearn中的贝叶斯分类器。
(1)获取训练数据:
# 获取训练数据
def read_train_data(self):
# 存放抽象问题
train_x=[]
# 存放抽象问题 对应的类别序号 0-13
train_y=[]
# 读入所有的问题分类数据 0-13
file_list=getfilelist("./data/question/")
# 遍历所有文件
for one_file in file_list:
# 获取文件名中的数字
num = re.sub(r'\D', "", one_file)
# 如果该文件名有数字,则读取该文件
if str(num).strip()!="":
# 设置当前文件下的数据标签
label_num=int(num)
# 读取文件内容
with(open(one_file,"r",encoding="utf-8")) as fr:
data_list=fr.readlines()
for one_line in data_list:
word_list=list(jieba.cut(str(one_line).strip()))
# 将这一行加入结果集
train_x.append(" ".join(word_list))
train_y.append(label_num)
print(train_x) # 问题列表
print(train_y) # 问题序号列表
return train_x,train_y
['nm 的 评分 是 多少', 'nm 得 了 多少 分', 'nm 的 评分 有 多少', 'nm 的 评分', 'nm 的 分数 是', 'nm 电影 分数 是 多少', 'nm 评分', 'nm 的 分数 是 多少', 'nm 这部 电影 的 评分 是 多少', 'nnt 演过 哪些 风格 的 电影', 'nnt 演过 的 电影 都 有 哪些 风格', 'nnt 演过 的 电影 有 哪些 类型', 'nnt 演过 风格 的 电影', 'nnt 演过 类型 的 电影', 'nnt 演过 题材 的 电影', '\ufeff nnt 和 nnr 合作 的 电影 有 哪些', 'nnt 和 nnr 一起 拍 了 哪些 电影', 'nnt 和 nnr 一起 演 过 哪些 电影', 'nnt 与 nnr 合拍 了 哪些 电影', 'nnt 和 nnr 合作 了 哪些 电影', '\ufeff nnt 一共 参演 过 多少 电影', 'nnt 演过 多少 部 电影', 'nnt 演过 多少 电影', 'nnt 参演 的 电影 有 多少', 'nnt 的 出生日期', 'nnt 的 生日', 'nnt 生日 多少', 'nnt 的 出生 是 什么 时候', 'nnt 的 出生 是 多少', 'nnt 生日 是 什么 时候', 'nnt 生日 什么 时候', 'nnt 出生日期 是 什么 时候', 'nnt 什么 时候 出生 的', 'nnt 出 生于 哪一天', 'nnt 的 出生日期 是 哪一天', 'nnt 哪一天 出生 的', 'nm 的 上映 时间 是 什么 时候', 'nm 的 首映 时间 是 什么 时候', 'nm 什么 时候 上映', 'nm 什么 时候 首映', 'nm 什么 时候 在 影院 上线', '什么 时候 可以 在 影院 看到 nm', 'nm 什么 时候 在 影院 放映', 'nm 什么 时候 首播', 'nm 的 风格 是 什么', 'nm 是 什么 风格 的 电影', 'nm 的 格调 是 什么', 'nm 是 什么 格调 的 电影', 'nm 是 什么 类型 的 电影', 'nm 的 类型 是 什么', 'nm 是 什么 类型 的', 'nm 的 剧情 是 什么', 'nm 主要 讲 什么 内容', 'nm 的 主要 剧情 是 什么', 'nm 主要 讲 什么 故事', 'nm 的 故事 线索 是 什么', 'nm 讲 了 什么', 'nm 的 剧情简介', 'nm 的 故事 内容', 'nm 的 主要 情节', 'nm 的 情节 梗概', 'nm 的 故事梗概', 'nm 有 哪些 演员 出演', 'nm 是 由 哪些 人演 的', 'nm 中 参演 的 演员 都 有 哪些', 'nm 中 哪些 人演 过', 'nm 这部 电影 的 演员 都 有 哪些', 'nm 这部 电影 中 哪些 人演 过', 'nnt', 'nnt', 'nnt', 'nnt', 'nnt', 'nnt 是', 'nnt 是 谁', 'nnt 的 介绍', 'nnt 的 简介', '谁 是 nnt', 'nnt 的 详细信息', 'nnt 的 信息', 'nnt 演过 哪些 ng 电影', 'nnt 演 哪些 ng 电影', 'nnt 演过 ng 电影', 'nnt 演过 什么 ng 电影', 'nnt 演过 ng 电影', 'nnt 演过 的 ng 电影 有 哪些', 'nnt 出演 的 ng 电影 有 哪些', 'nnt 演了 什么 电影', 'nnt 出演 了 什么 电影', 'nnt 演过 什么 电影', 'nnt 演过 哪些 电影', 'nnt 过去 演 过 哪些 电影', 'nnt 以前 演 过 哪些 电影', 'nnt 演过 的 电影 有 什么', 'nnt 有 哪些 电影', '\ufeff nnt 参演 的 评分 大于 x 的 电影 有 哪些', 'nnt 参演 的 电影 评分 大于 x 的 有 哪些', 'nnt 参演 的 电影 评分 超过 x 的 有 哪些', 'nnt 演 的 电影 评分 超过 x 的 有 哪些', 'nnt 演 的 电影 评分 大于 x 的 都 有 哪些', 'nnt 演 的 电影 评分 在 x 以上 的 都 有 哪些', '\ufeff nnt 参演 的 评分 小于 x 的 电影 有 哪些', 'nnt 参演 的 电影 评分 小于 x 的 有 哪些', 'nnt 参演 的 电影 评分 低于 x 的 有 哪些', 'nnt 演 的 电影 评分 低于 x 的 有 哪些', 'nnt 演 的 电影 评分 小于 x 的 都 有 哪些', 'nnt 演 的 电影 评分 在 x 以下 的 都 有 哪些']
[0, 0, 0, 0, 0, 0, 0, 0, 0, 10, 10, 10, 10, 10, 10, 11, 11, 11, 11, 11, 12, 12, 12, 12, 13, 13, 13, 13, 13, 13, 13, 13, 13, 13, 13, 13, 1, 1, 1, 1, 1, 1, 1, 1, 2, 2, 2, 2, 2, 2, 2, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 4, 4, 4, 4, 4, 4, 5, 5, 5, 5, 5, 5, 5, 5, 5, 5, 5, 5, 6, 6, 6, 6, 6, 6, 6, 7, 7, 7, 7, 7, 7, 7, 7, 8, 8, 8, 8, 8, 8, 9, 9, 9, 9, 9, 9]
(2)训练多分类贝叶斯分类器模型
# 训练并测试模型-NB
def train_model_NB(self):
X_train, y_train = self.train_x, self.train_y
# 调用sklearn中的TF-IDF
self.tv = TfidfVectorizer()
# fit_transform(trainData)对部分数据先拟合fit,找到该part的整体指标,
# 如均值、方差、最大值最小值等等(根据具体转换的目的),
# 然后对该trainData进行转换transform,从而实现数据的标准化、归一化等等。
train_data = self.tv.fit_transform(X_train).toarray()
# alpha:浮点型,可选项,默认1.0,添加拉普拉斯/Lidstone平滑参数。
# 当α=1时,称作Laplace平滑,当0<α<1时,称作Lidstone平滑,α=0时不做平滑。
# MultinomialNB多项式朴素贝叶斯
clf = MultinomialNB(alpha=0.01)
clf.fit(train_data, y_train)
return clf
(3)利用训练好的模型来对新问题进行分类预测
# 预测
def predict(self,question):
# 对问题进行分词
question=[" ".join(list(jieba.cut(question)))]
# 将问题输入转换为词向量矩阵
test_data=self.tv.transform(question).toarray()
# 调用模型完成预测 返回问题编号 0 - 13
y_predict = self.model.predict(test_data)[0]
print("question type:",y_predict)
return y_predict

返回用户问题所属的类别编号,这个编号也就对应一个问题模板:
0:nm 评分
1:nm 上映时间
2:nm 类型
3:nm 简介
4:nm 演员列表
5:nnt 介绍
6:nnt ng 电影作品
7:nnt 电影作品
8:nnt 参演评分 大于 x
9:nnt 参演评分 小于 x
10:nnt 电影类型
11:nnt nnr 合作 电影列表
12:nnt 电影数量
13:nnt 出生日期
(4)替换模板中的抽象内容
数字和模板的对应关系可以提前存到一个字典中,当预测出编号后,直接通过这个编号作为字典的key值,value就是根据该模板来查询答案的方法,这样就查询出问题模板了。比如预测的结果是2,则对应的问题模板 nm 类型,表示询问某部电影的类型,再结合前一阶段获取的电影名字,则可以组成一个新的问题,比如:
def __init__(self):
self.q_template_dict={
0:self.get_movie_rating, # 电影评分
1:self.get_movie_releasedate,# 电影上映时间
2:self.get_movie_type,# 电影类型
3:self.get_movie_introduction,# 电影简介
4:self.get_movie_actor_list,# 电影演员列表
5:self.get_actor_info,# 电影简介
6:self.get_actor_act_type_movie,# 演员的该类别电影作品
7:self.get_actor_act_movie_list,# 演员的电影作品
8:self.get_movie_rating_bigger,# 演员的参演评分大于x
9:self.get_movie_rating_smaller,# 演员的参演评分小于x
10:self.get_actor_movie_type,# 电影类型
11:self.get_cooperation_movie_list,# 合作的电影列表
12:self.get_actor_movie_num, # 电影数量
13:self.get_actor_birthday# 演员出生日期
}
肖申克的救赎 类型
3.答案获取
在已知问题和答案模板之后,可以通过调用对应的方法得到结果。在对应的方法中,利用Cypher语言来构建查询语句,其基本形式是:
match(n)-[r] -(b)
项目使用python的库py2neo来操作图数据库neo4j。这里只涉及到查询操作,所以直接构造了Cypher查询语句,然后使用py2neo库的run方法来查询,数据库的链接和查询单独的写了一个类,在需要的时候调用即可:
#-*- coding: UTF-8 -*-
# @Time : 2022/11/14
# @Author : zgf
# @Site :
# @File : query.py
# @Software: PyCharm
from py2neo import Graph,Node,Relationship,NodeMatcher
class Query():
def __init__(self):
# self.graph=Graph("http://localhost:7474", username="neo4j",password="090711zgf")
# 连接图形数据库用户名和密码
self.graph=Graph("http://localhost:7474", auth=("neo4j", "090711zgf"))
# 问题类型0,查询电影得分
def run(self,cql):
# find_rela = test_graph.run("match (n:Person{name:'张学友'})-[actedin]-(m:Movie) return m.title")
result=[]
find_rela = self.graph.run(cql)
for i in find_rela:
result.append(i.items()[0][1])
return result
# if __name__ == '__main__':
# SQL=Query()
# result=SQL.run("match (m:Movie)-[]->() where m.title='卧虎藏龙' return m.rating")
# print(result)
那么接下来就是13个问题对应的实现方法,主要是构造Cypher查询语句
(1)获取电影评分
# 0:nm 电影评分
def get_movie_rating(self):
# 获取电影名称,这个是在原问题中抽取的
movie_name=self.get_movie_name()
# cql语句
# match 从数据库获取有关节点、关系和属性的数据 相当于查询
# match (节点的名称:节点标签名称)
# -[:]关系的名称:关系的标签名称
# where : Neo4j CQL在CQL match命令中提供了where子句来过滤MATCH查询的结果
# WHERE 其中condition语法为: cql比较运算符
# return m的电影评分
cql = f"match (m:Movie)-[]->() where m.title='{movie_name}' return m.rating"
print(cql)
# 执行sql语句
answer = self.graph.run(cql)[0]
print(answer)
answer = round(answer, 2) # 用于数字的四舍五入,保留两位小数
final_answer=movie_name+"电影评分为"+str(answer)+"分!"
return final_answer
(2)上映时间
# 1:nm 上映时间
def get_movie_releasedate(self):
movie_name = self.get_movie_name()
cql = f"match(m:Movie)-[]->() where m.title='{movie_name}' return m.releasedate"
print(cql)
answer = self.graph.run(cql)[0]
final_answer = movie_name + "的上映时间是" + str(answer) + "!"
return final_answer
(3)电影类型
# 2:nm 类型
def get_movie_type(self):
movie_name = self.get_movie_name()
cql = f"match(m:Movie)-[r:is]->(b) where m.title='{movie_name}' return b.name"
print(cql)
answer = self.graph.run(cql)
answer_set=set(answer)
answer_list=list(answer_set)
answer="、".join(answer_list)
final_answer = movie_name + "是" + str(answer) + "等类型的电影!"
return final_answer
(4)电影简介
# 3:nm 简介
def get_movie_introduction(self):
movie_name = self.get_movie_name()
cql = f"match(m:Movie)-[]->() where m.title='{movie_name}' return m.introduction"
print(cql)
answer = self.graph.run(cql)[0]
final_answer = movie_name + "主要讲述了" + str(answer) + "!"
return final_answer
(5)演员列表
# 4:nm 演员列表
def get_movie_actor_list(self):
movie_name=self.get_movie_name()
cql = f"match(n:Person)-[r:actedin]->(m:Movie) where m.title='{movie_name}' return n.name"
print(cql)
answer = self.graph.run(cql)
answer_set = set(answer)
answer_list = list(answer_set)
answer = "、".join(answer_list)
final_answer = movie_name + "由" + str(answer) + "等演员主演!"
return final_answer
(6)演员介绍
# 5:nnt 介绍
def get_actor_info(self):
actor_name = self.get_name('nr')
cql = f"match(n:Person)-[]->() where n.name='{actor_name}' return n.biography"
print(cql)
answer = self.graph.run(cql)[0]
final_answer = answer
return final_answer
(7)演员出演作品类型
# 6:nnt ng 电影作品
def get_actor_act_type_movie(self):
actor_name = self.get_name("nr")
type=self.get_name("ng")
# 查询电影名称
cql = f"match(n:Person)-[]->(m:Movie) where n.name='{actor_name}' return m.title"
print(cql)
movie_name_list = list(set(self.graph.run(cql)))
# 查询类型
result=[]
for movie_name in movie_name_list:
movie_name=str(movie_name).strip()
try:
cql=f"match(m:Movie)-[r:is]->(t) where m.title='{movie_name}' return t.name"
# print(cql)
temp_type=self.graph.run(cql)
if len(temp_type)==0:
continue
if type in temp_type:
result.append(movie_name)
except:
continue
answer="、".join(result)
print(answer)
final_answer = actor_name+"演过的"+type+"电影有:\n"+answer+"。"
return final_answer
(8)演员出演作品
# 7:nnt 电影作品
def get_actor_act_movie_list(self):
actor_name = self.get_name("nr")
answer_list=self.get_actorname_movie_list(actor_name)
answer = "、".join(answer_list)
final_answer = actor_name + "演过" + str(answer) + "等电影!"
return final_answer
def get_actorname_movie_list(self,actorname):
# 查询电影名称
cql = f"match(n:Person)-[]->(m:Movie) where n.name='{actorname}' return m.title"
print(cql)
answer = self.graph.run(cql)
answer_set = set(answer)
answer_list = list(answer_set)
return answer_list
(9)作品评分
def get_movie_rating_bigger(self):
actor_name=self.get_name('nr')
x=self.get_num_x()
cql = f"match(n:Person)-[r:actedin]->(m:Movie) where n.name='{actor_name}' and m.rating>={x} return m.title"
print(cql)
answer = self.graph.run(cql)
answer = "、".join(answer)
answer = str(answer).strip()
final_answer=actor_name+"演的电影评分大于"+x+"分的有"+answer+"等!"
return final_answer
def get_movie_rating_smaller(self):
actor_name = self.get_name('nr')
x = self.get_num_x()
cql = f"match(n:Person)-[r:actedin]->(m:Movie) where n.name='{actor_name}' and m.rating<{x} return m.title"
print(cql)
answer = self.graph.run(cql)
answer = "、".join(answer)
answer = str(answer).strip()
final_answer = actor_name + "演的电影评分小于" + x + "分的有" + answer + "等!"
return final_answer
(10)其他问题
def get_actor_movie_type(self):
actor_name = self.get_name("nr")
# 查询电影名称
cql = f"match(n:Person)-[]->(m:Movie) where n.name='{actor_name}' return m.title"
print(cql)
movie_name_list = list(set(self.graph.run(cql)))
# 查询类型
result = []
for movie_name in movie_name_list:
movie_name = str(movie_name).strip()
try:
cql = f"match(m:Movie)-[r:is]->(t) where m.title='{movie_name}' return t.name"
# print(cql)
temp_type = self.graph.run(cql)
if len(temp_type) == 0:
continue
result+=temp_type
except:
continue
answer = "、".join(list(set(result)))
print(answer)
final_answer = actor_name + "演过的电影有" + answer + "等类型。"
return final_answer
def get_cooperation_movie_list(self):
# 获取演员名字
actor_name_list=self.get_name('nr')
movie_list={}
for i,actor_name in enumerate(actor_name_list):
answer_list=self.get_actorname_movie_list(actor_name)
movie_list[i]=answer_list
result_list=list(set(movie_list[0]).intersection(set(movie_list[1])))
print(result_list)
answer="、".join(result_list)
final_answer=actor_name_list[0]+"和"+actor_name_list[1]+"一起演过的电影主要是"+answer+"!"
return final_answer
def get_actor_movie_num(self):
actor_name=self.get_name("nr")
answer_list=self.get_actorname_movie_list(actor_name)
movie_num=len(set(answer_list))
answer=movie_num
final_answer=actor_name+"演过"+str(answer)+"部电影!"
return final_answer
(11)演员生日
def get_actor_birthday(self):
actor_name = self.get_name('nr')
cql = f"match(n:Person)-[]->() where n.name='{actor_name}' return n.birth"
print(cql)
answer = self.graph.run(cql)[0]
final_answer = actor_name+"的生日是"+answer+"。"
return final_answer
