ResNet网络解析及实战案例
网络越深,获取的信息就越多,特征也越丰富。但是在实践中,随着网络的加深,优化效果反而越差,测试数据和训练数据的准确率反而降低了。如下图所示,56层和20层的神经网络对训练误差和测试误差的对比
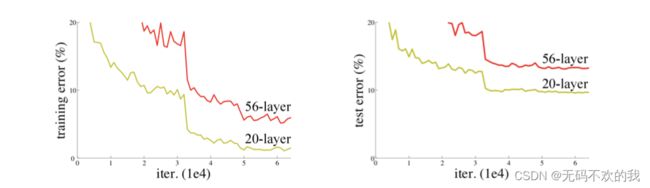
针对这种深层网络退化的问题,何恺明等人提出了残差网络(ResNet)在2015年的ImageNet图像识别挑战赛夺魁,并深刻影响了后来的深度神经网络的设计。
1 残差块
假设 F(x) 代表某个只包含有两层的映射函数, x 是输入, F(x)是输出。假设他们具有相同的维度。在训练的过程中我们希望能够通过修改网络中的 w和b去拟合一个理想的 H(x)(从输入到输出的一个理想的映射函数)。也就是我们的目标是修改预测值F(x) 中的 w和b以便逼近真实值 H(x) 。如果我们改变思路,用F(x) 来逼近 H(x)-x ,那么我们最终得到的输出就变为 F(x)+x(这里的加指的是对应位置上的元素相加,也就是element-wise addition),这里将直接从输入连接到输出的结构也称为shortcut,那整个结构就是残差块,ResNet的基础模块。
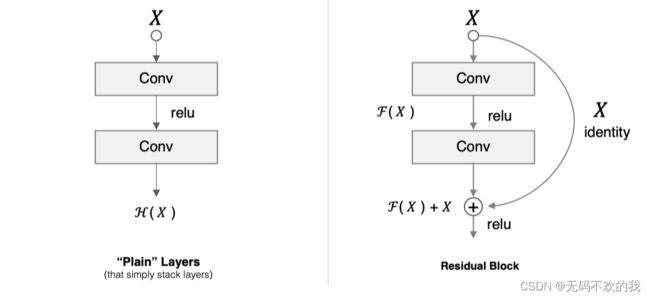
假设网络结构如下图所示,在19层中加上一个短连接,绕过20层和21层,在网络的训练过程中,假如第20,21层的效果不好,那么它们对应的权重参数会在迭代训练中不断变小,甚至直接置零,也就是此时网络已经放弃了第20,21层,直接通过短连接绕过它们;假如第20,21层的效果表现很好,那么那么它们对应的权重参数会在迭代训练中不断增大,也就是说让网络自己来选择是重视第20,21层还是放弃这两层。所以何凯明曾经说过:“ResNet能达到什么效果呢,多高我不敢说,但是至少不比原来差“。在实际场景中,这种残差块通常会做很多个,即便是有其中几层表现效果很差也没有关系,只要有其中一层表现好就可以提升原来的性能。

残差结构由主分支和捷径分支(也称为短连接)组成,它有两种形式:分别是基础模块(BasicBlock)和瓶颈模块(Bottleneck),分别对应下图中的左半部分和右半部分。

这两种结构分别用于ResNet18/34(左图)和ResNet50/101/152(右图),其中右图中的瓶颈模块,目的就是为了降低参数量。
在瓶颈模块中,第一个1x1卷积下降了1/4通道数,第二个1x1卷积提升了4倍通道数,在pytorch官方代码实现中,设置超参数expansion=4来实现这一功能

resnet在pytorch 官网的实现位置是:anaconda\envs\Lib\site-packages\torchvision\models\resnet.py
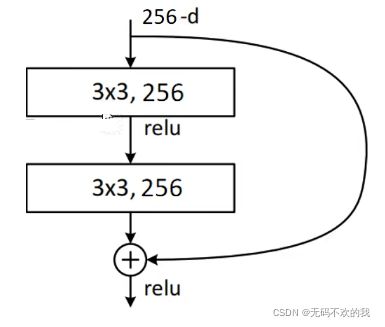
瓶颈模块将两个3x3的卷积层替换为1x1 + 3x3 + 1x1,新结构中的中间3x3的卷积层首先在一个降维1x1卷积层下减少了计算,然后在另一个1x1的卷积层下做了还原。第一个1x1的卷积把256维通道降到64维,然后在最后通过1x1卷积恢复,整体上用的参数数目:1x1x256x64 + 3x3x64x64 + 1x1x64x256 = 69632,而不使用bottleneck的话,就是两个3x3x256的卷积,如下图所示,此时的参数数目: 3x3x256x256x2 = 1179648,是前者的16.94倍。
2 不同层的网络
常见的resnet结构主要有resnet18,34,50,101和152,下表给出了它们具体的结构:
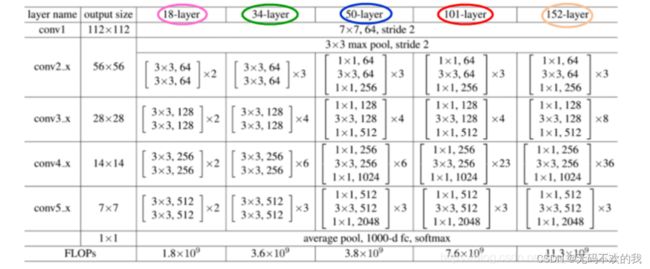
首先看表的最左侧,所有的网络都分成5部分,分别是:conv1,conv2_x,conv3_x,conv4_x,conv5_x, 例如:101-layer指的是101层网络,首先有个输入7x7x64的卷积,然后经过3 + 4 + 23 + 3 = 33个残差块,每个残差块为3层,所以有33 x 3 = 99层,最后有个全连接层(用于分类),所以1 + 99 + 1 = 101层,一共是101层网络; 我们看下50-layer和101-layer这两列,可以发现,它们唯一的不同在于conv4_x,ResNet50有6个block,而ResNet101有23个block,两者之间差了17个block,也就是17 x 3 = 51层。
注意:网络层仅仅指卷积或者全连接层,而激活层或者Pooling层并没有计算在内。
下图一是图中的符号说明,图二是resnet18和resnet34的结构图:


表中将所有的残差结构划分成4个模块,分别是conv2_x,conv3_x, conv4_x, conv5_x(上图中用不同的颜色表示不同的模块)。其中conv3_x, conv4_x, conv5_x这三个模块中的第一层残差结构将输入特征图进行2倍下采样,并且将channel调整成下一层残差结构所需要的channel,与此同时,它们的捷径分支上(图中虚线部分)使用的了1x1的卷积进行下采样和通道的调整,使得捷径分支的输出和主分支的输出尺寸相同,这样才可以将它们直接相加。 对于conv2_x模块来说,它没有进行下采样(因为conv2_x 模块前使用了步幅为2的最大池化层,所以该模块无须再减小高和宽)
需要注意的是,对于ResNet50/101/152来说,conv2_x模块的第一层残差块的捷径分支也使用了1x1的卷积,它的作用是调整通道数(并没有下采样),以方便主分支的输出和捷径分支的输出直接相加。该残差结构的捷径分支输入尺寸是[56, 56, 64],输出尺寸是 [56, 56, 256],而主分支的输出尺寸也是 [56, 56, 256],所以它们可以直接相加。
根据上面分支可知,捷径分支有两种类型,第一种是输入与输出相等(恒等映射),用实线表示;第二种是对输入通过一个1x1的卷积层然后进行输出,用虚线表示。
3 网络构建
resnet在pytorch 官网的实现位置是:anaconda\envs\Lib\site-packages\torchvision\models\resnet.py
3.1 基础残差块构建
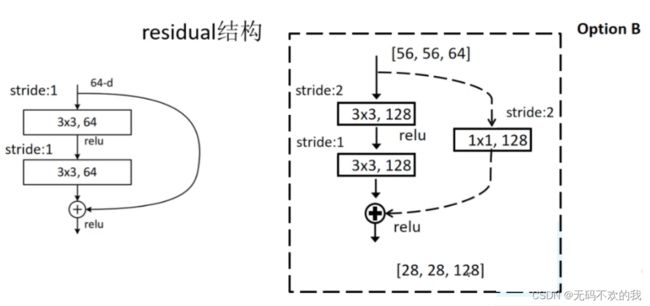
ResNet18/34网络的构建所需残差块:在下图中展示了第一个模块(即conv2_x)中的第一个残差块(左半部分)和第二个模块(即conv3_x)中第一个残差块(右半部分)的具体结构。左半部分中的短连接用实线表示,该残差块的输入通道与输出通道相同,而右半部分的短连接用实线表示,该残差块的输出通道是输入通道的两倍
主要通过类BasicBlock实现,代码如下:
class BasicBlock(nn.Module):
expansion = 1
def __init__(self, in_channel, out_channel, stride=1, downsample=None, **kwargs):
super(BasicBlock, self).__init__()
self.conv1 = nn.Conv2d(in_channels=in_channel, out_channels=out_channel,
kernel_size=3, stride=stride, padding=1, bias=False)
self.bn1 = nn.BatchNorm2d(out_channel)
self.relu = nn.ReLU()
self.conv2 = nn.Conv2d(in_channels=out_channel, out_channels=out_channel,
kernel_size=3, stride=1, padding=1, bias=False)
self.bn2 = nn.BatchNorm2d(out_channel)
self.downsample = downsample
def forward(self, x):
identity = x
if self.downsample is not None:
identity = self.downsample(x)
out = self.conv1(x)
out = self.bn1(out)
out = self.relu(out)
out = self.conv2(out)
out = self.bn2(out)
out += identity
out = self.relu(out)
return out
3.2 瓶颈模块构建
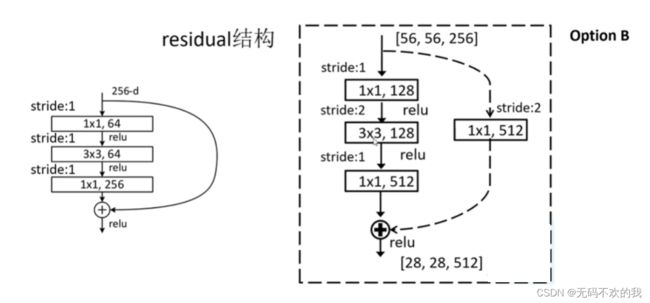
瓶颈模块用于构建层数较多的resnet50/101/152网络:在下图中展示了第一个模块(即conv2_x)中的第一个残差块(左半部分)和第二个模块(即conv3_x)中第一个残差块(右半部分)的具体结构。左半部分中的短连接用实线表示,该残差块的输入通道与输出通道相同,而右半部分的短连接用实线表示,该残差块的输出通道是输入通道的两倍

通过类Bottleneck来实现,代码如下所示:
class Bottleneck(nn.Module):
"""
注意:原论文中,在虚线残差结构的主分支上,第一个1x1卷积层的步距是2,第二个3x3卷积层步距是1。
但在pytorch官方实现过程中是第一个1x1卷积层的步距是1,第二个3x3卷积层步距是2,
这么做的好处是能够在top1上提升大概0.5%的准确率。
可参考Resnet v1.5 https://ngc.nvidia.com/catalog/model-scripts/nvidia:resnet_50_v1_5_for_pytorch
"""
expansion = 4
def __init__(self, in_channel, out_channel, stride=1, downsample=None):
super(Bottleneck, self).__init__()
self.conv1 = nn.Conv2d(in_channels=in_channel, out_channels=out_channel,
kernel_size=1, stride=1, bias=False) # squeeze channels
self.bn1 = nn.BatchNorm2d(out_channel)
# -----------------------------------------
self.conv2 = nn.Conv2d(in_channels=out_channel, out_channels=out_channel,
kernel_size=3, stride=stride, bias=False, padding=1)
self.bn2 = nn.BatchNorm2d(out_channel)
# -----------------------------------------
self.conv3 = nn.Conv2d(in_channels=out_channel, out_channels=out_channel * self.expansion,
kernel_size=1, stride=1, bias=False) # unsqueeze channels
self.bn3 = nn.BatchNorm2d(out_channel * self.expansion)
self.relu = nn.ReLU(inplace=True)
self.downsample = downsample
def forward(self, x):
identity = x
if self.downsample is not None:
identity = self.downsample(x)
out = self.conv1(x)
out = self.bn1(out)
out = self.relu(out)
out = self.conv2(out)
out = self.bn2(out)
out = self.relu(out)
out = self.conv3(out)
out = self.bn3(out)
out += identity
out = self.relu(out)
return out
3.3 Resnet网络构建
通过上述创建的残差模块来构建resnet网络,

代码如下所示:
class ResNet(nn.Module):
def __init__(self,
block, # 残差块的选择:如果定义ResNet18/34时,就选择基础模块(BasicBlock),如果定义ResNet50/101/152,就使用瓶颈模块(Bottleneck)
blocks_num, # 定义所使用的残差块的数量,它是一个列表参数
num_classes=1000, # 网络的分类个数
):
super(ResNet, self).__init__()
self.in_channel = 64
self.conv1 = nn.Conv2d(3, self.in_channel, kernel_size=7, stride=2,
padding=3, bias=False)
self.bn1 = nn.BatchNorm2d(self.in_channel)
self.relu = nn.ReLU(inplace=True)
self.maxpool = nn.MaxPool2d(kernel_size=3, stride=2, padding=1)
# 下面的 self.layer1,self.layer2,self.layer3,self.layer4分别是不同的模块,即对应着上面表格中的conv1,conv2_x,conv3_x,conv4_x,conv5_x中的残差结构
self.layer1 = self._make_layer(block, 64, blocks_num[0])
self.layer2 = self._make_layer(block, 128, blocks_num[1], stride=2)
self.layer3 = self._make_layer(block, 256, blocks_num[2], stride=2)
self.layer4 = self._make_layer(block, 512, blocks_num[3], stride=2)
self.avgpool = nn.AdaptiveAvgPool2d((1, 1)) # 自适应平均池化(即全局平均池化),它会将输入特征图池化成1x1大小
# 因为前边经过自适应平均池化后特征图大小变为1x1,并且有512 * block.expansion个通道,所以展平后的维度是512 * block.expansion,所以下面的全连接层的输入维度是512 * block.expansion
self.fc = nn.Linear(512 * block.expansion, num_classes)
#对卷积层的参数进行初始化
for m in self.modules():
if isinstance(m, nn.Conv2d):
nn.init.kaiming_normal_(m.weight, mode='fan_out', nonlinearity='relu')
def _make_layer(self, block, channel, block_num, stride=1):
downsample = None
if stride != 1 or self.in_channel != channel * block.expansion:
downsample = nn.Sequential(
nn.Conv2d(self.in_channel, channel * block.expansion, kernel_size=1, stride=stride, bias=False),
nn.BatchNorm2d(channel * block.expansion))
layers = []
layers.append(block(self.in_channel,
channel,
downsample=downsample,
stride=stride))
self.in_channel = channel * block.expansion
for _ in range(1, block_num):
layers.append(block(self.in_channel,
channel))
return nn.Sequential(*layers)
def forward(self, x):
x = self.conv1(x)
x = self.bn1(x)
x = self.relu(x)
x = self.maxpool(x)
x = self.layer1(x)
x = self.layer2(x)
x = self.layer3(x)
x = self.layer4(x)
x = self.avgpool(x) # 自适应平均池化(即全局平均池化),它会将输入特征图池化成1x1大小
x = torch.flatten(x, 1)
x = self.fc(x)
return x
3.4 构建不同层网络
在构建不同层网络时,按照下表对conv2_x,conv3_x,conv4_x,conv5_x的残差块数量进行设置,并指定使用瓶颈模块还是基础的残差模块即可

在这里我们构建了resnet18/34/50/101/152等不同层的网络
def resnet18(num_classes=1000):
#预训练权重下载链接: https://download.pytorch.org/models/resnet18-5c106cde.pth
return ResNet(BasicBlock, [2, 2, 2, 2], num_classes=num_classes)
def resnet34(num_classes=1000):
#预训练权重下载链接: https://download.pytorch.org/models/resnet34-333f7ec4.pth
return ResNet(BasicBlock, [3, 4, 6, 3], num_classes=num_classes)
def resnet50(num_classes=1000):
#预训练权重下载链接: https://download.pytorch.org/models/resnet50-19c8e357.pth
return ResNet(Bottleneck, [3, 4, 6, 3], num_classes=num_classes)
def resnet101(num_classes=1000, include_top=True):
#预训练权重下载链接: https://download.pytorch.org/models/resnet101-5d3b4d8f.pth
return ResNet(Bottleneck, [3, 4, 23, 3], num_classes=num_classes)
def resnet152(num_classes=1000):
#预训练权重下载链接: https://download.pytorch.org/models/resnet152-b121ed2d.pth
return ResNet(Bottleneck, [3, 8, 36, 3], num_classes=num_classes)
3.5 整体代码
import torch.nn as nn
import torch
class BasicBlock(nn.Module):
expansion = 1
def __init__(self, in_channel, out_channel, stride=1, downsample=None, **kwargs):
super(BasicBlock, self).__init__()
self.conv1 = nn.Conv2d(in_channels=in_channel, out_channels=out_channel,
kernel_size=3, stride=stride, padding=1, bias=False)
self.bn1 = nn.BatchNorm2d(out_channel)
self.relu = nn.ReLU()
self.conv2 = nn.Conv2d(in_channels=out_channel, out_channels=out_channel,
kernel_size=3, stride=1, padding=1, bias=False)
self.bn2 = nn.BatchNorm2d(out_channel)
self.downsample = downsample
def forward(self, x):
identity = x
if self.downsample is not None:
identity = self.downsample(x)
out = self.conv1(x)
out = self.bn1(out)
out = self.relu(out)
out = self.conv2(out)
out = self.bn2(out)
out += identity
out = self.relu(out)
return out
class Bottleneck(nn.Module):
"""
注意:原论文中,在虚线残差结构的主分支上,第一个1x1卷积层的步距是2,第二个3x3卷积层步距是1。
但在pytorch官方实现过程中是第一个1x1卷积层的步距是1,第二个3x3卷积层步距是2,
这么做的好处是能够在top1上提升大概0.5%的准确率。
可参考Resnet v1.5 https://ngc.nvidia.com/catalog/model-scripts/nvidia:resnet_50_v1_5_for_pytorch
"""
expansion = 4
def __init__(self, in_channel, out_channel, stride=1, downsample=None):
super(Bottleneck, self).__init__()
self.conv1 = nn.Conv2d(in_channels=in_channel, out_channels=out_channel,
kernel_size=1, stride=1, bias=False) # squeeze channels
self.bn1 = nn.BatchNorm2d(out_channel)
# -----------------------------------------
self.conv2 = nn.Conv2d(in_channels=out_channel, out_channels=out_channel,
kernel_size=3, stride=stride, bias=False, padding=1)
self.bn2 = nn.BatchNorm2d(out_channel)
# -----------------------------------------
self.conv3 = nn.Conv2d(in_channels=out_channel, out_channels=out_channel * self.expansion,
kernel_size=1, stride=1, bias=False) # unsqueeze channels
self.bn3 = nn.BatchNorm2d(out_channel * self.expansion)
self.relu = nn.ReLU(inplace=True)
self.downsample = downsample
def forward(self, x):
identity = x
if self.downsample is not None:
identity = self.downsample(x)
out = self.conv1(x)
out = self.bn1(out)
out = self.relu(out)
out = self.conv2(out)
out = self.bn2(out)
out = self.relu(out)
out = self.conv3(out)
out = self.bn3(out)
out += identity
out = self.relu(out)
return out
class ResNet(nn.Module):
def __init__(self,
block, # 残差块的选择:如果定义ResNet18/34时,就选择基础模块(BasicBlock),如果定义ResNet50/101/152,就使用瓶颈模块(Bottleneck)
blocks_num, # 定义所使用的残差块的数量,它是一个列表参数
num_classes=1000, # 网络的分类个数
):
super(ResNet, self).__init__()
self.in_channel = 64
self.conv1 = nn.Conv2d(3, self.in_channel, kernel_size=7, stride=2,
padding=3, bias=False)
self.bn1 = nn.BatchNorm2d(self.in_channel)
self.relu = nn.ReLU(inplace=True)
self.maxpool = nn.MaxPool2d(kernel_size=3, stride=2, padding=1)
# 下面的 self.layer1,self.layer2,self.layer3,self.layer4分别是不同的模块,即对应着上面表格中的conv1,conv2_x,conv3_x,conv4_x,conv5_x中的残差结构
self.layer1 = self._make_layer(block, 64, blocks_num[0])
self.layer2 = self._make_layer(block, 128, blocks_num[1], stride=2)
self.layer3 = self._make_layer(block, 256, blocks_num[2], stride=2)
self.layer4 = self._make_layer(block, 512, blocks_num[3], stride=2)
self.avgpool = nn.AdaptiveAvgPool2d((1, 1)) # 自适应平均池化(即全局平均池化),它会将输入特征图池化成1x1大小
# 因为前边经过自适应平均池化后特征图大小变为1x1,并且有512 * block.expansion个通道,所以展平后的维度是512 * block.expansion,所以下面的全连接层的输入维度是512 * block.expansion
self.fc = nn.Linear(512 * block.expansion, num_classes)
#对卷积层的参数进行初始化
for m in self.modules():
if isinstance(m, nn.Conv2d):
nn.init.kaiming_normal_(m.weight, mode='fan_out', nonlinearity='relu')
def _make_layer(self, block, channel, block_num, stride=1):
downsample = None
if stride != 1 or self.in_channel != channel * block.expansion:
downsample = nn.Sequential(
nn.Conv2d(self.in_channel, channel * block.expansion, kernel_size=1, stride=stride, bias=False),
nn.BatchNorm2d(channel * block.expansion))
layers = []
layers.append(block(self.in_channel,
channel,
downsample=downsample,
stride=stride))
self.in_channel = channel * block.expansion
for _ in range(1, block_num):
layers.append(block(self.in_channel,
channel))
return nn.Sequential(*layers)
def forward(self, x):
x = self.conv1(x)
x = self.bn1(x)
x = self.relu(x)
x = self.maxpool(x)
x = self.layer1(x)
x = self.layer2(x)
x = self.layer3(x)
x = self.layer4(x)
x = self.avgpool(x) # 自适应平均池化(即全局平均池化),它会将输入特征图池化成1x1大小
x = torch.flatten(x, 1)
x = self.fc(x)
return x
def resnet18(num_classes=1000):
#预训练权重下载链接: https://download.pytorch.org/models/resnet18-5c106cde.pth
return ResNet(BasicBlock, [2, 2, 2, 2], num_classes=num_classes)
def resnet34(num_classes=1000):
#预训练权重下载链接: https://download.pytorch.org/models/resnet34-333f7ec4.pth
return ResNet(BasicBlock, [3, 4, 6, 3], num_classes=num_classes)
def resnet50(num_classes=1000):
#预训练权重下载链接: https://download.pytorch.org/models/resnet50-19c8e357.pth
return ResNet(Bottleneck, [3, 4, 6, 3], num_classes=num_classes)
def resnet101(num_classes=1000, include_top=True):
#预训练权重下载链接: https://download.pytorch.org/models/resnet101-5d3b4d8f.pth
return ResNet(Bottleneck, [3, 4, 23, 3], num_classes=num_classes)
def resnet152(num_classes=1000):
#预训练权重下载链接: https://download.pytorch.org/models/resnet152-b121ed2d.pth
return ResNet(Bottleneck, [3, 8, 36, 3], num_classes=num_classes)
3.6 pytorch官方封装的resnet代码
其实在pytorch官方已经封装好了resnet代码,我们只需要一行代码就可以进行调用,不需要再自己构建模型
resnet18
- 导入resnet18的预训练模型
import torchvision
model = torchvision.models.resnet18(pretrained=True)
- 如果只需要resnet18网络结构,不需要用预训练模型的参数来初始化,那么就是
model = torchvision.models.resnet50(pretrained=False)
resnet50
- 导入resnet50的预训练模型
import torchvision
model = torchvision.models.resnet50(pretrained=True)
- 如果只需要resnet50网络结构,不需要用预训练模型的参数来初始化,那么就是
model = torchvision.models.resnet50(pretrained=False)
resnet101
- 导入resnet101的预训练模型
import torchvision
model = torchvision.models.resnet101(pretrained=True)
- 如果只需要resnet50网络结构,不需要用预训练模型的参数来初始化,那么就是
model = torchvision.models.resnet101(pretrained=False)
resnet152
- 导入resnet152的预训练模型
import torchvision
model = torchvision.models.resnet152(pretrained=True)
- 如果只需要resnet50网络结构,不需要用预训练模型的参数来初始化,那么就是
model = torchvision.models.resnet152(pretrained=False)
4 微调Resnet-18进行二分类
下面我们使用Imagenet上预训练好的Resnet-18进行Finetune (微调), 用于二分类
其中蚂蚁蜜蜂二分类数据包括:
训练集:各120~张 验证集:各70~张
每个类别的图片分别存放在不同的文件夹中,并且该文件夹名就是标签名。这里的数据数量非常少,所以只能进行微调模型
这里微调的部分是最后的全连接层,将原本的1000个神经元改为2个神经元,用于二分类

项目的所有代码,数据集和模型权重已经全部放到我的github仓库中:https://github.com/mojieok/classification
- 整体布局

- 自定义AntsDataset类,它继承torch.utils.data.Dataset类,它的位置在 tools/my_dataset文件中
import numpy as np
import torch
import os
import random
from PIL import Image
from torch.utils.data import Dataset
class AntsDataset(Dataset):
def __init__(self, data_dir, transform=None):
#每个类别的图片分别存放在不同的文件夹中,并且该文件夹名就是标签名
self.label_name = {"ants": 0, "bees": 1}#获取标签名称
self.data_info = self.get_img_info(data_dir)#data_info是一个List,里边存放图片的位置以及标签
self.transform = transform
def __getitem__(self, index):
path_img, label = self.data_info[index]
img = Image.open(path_img).convert('RGB')
if self.transform is not None:
img = self.transform(img)
return img, label
def __len__(self):
return len(self.data_info)#返回数据集的样本总数
def get_img_info(self, data_dir):#data_dir是数据所在文件夹
data_info = list()
for root, dirs, _ in os.walk(data_dir):#遍历数据所在文件夹
# 遍历类别
for sub_dir in dirs:
img_names = os.listdir(os.path.join(root, sub_dir))
img_names = list(filter(lambda x: x.endswith('.jpg'), img_names))
# 遍历图片
for i in range(len(img_names)):
img_name = img_names[i]
path_img = os.path.join(root, sub_dir, img_name)
label = self.label_name[sub_dir]
data_info.append((path_img, int(label)))
if len(data_info) == 0:
#判断data_dir文件夹中是否有图片,如果没有就抛出异常
raise Exception("\ndata_dir:{} is a empty dir! Please checkout your path to images!".format(data_dir))
return data_info
- 随机数种子函数的实现,它的位置在tools/common_tools文件中
import torch
import random
import numpy as np
def set_seed(seed=1):
random.seed(seed)
np.random.seed(seed)
torch.manual_seed(seed)
torch.cuda.manual_seed(seed)
- 模型训练,它的位置在./finetune_resnet18
import os
import numpy as np
import torch
import torch.nn as nn
from torch.utils.data import DataLoader
import torchvision.transforms as transforms
import torch.optim as optim
from matplotlib import pyplot as plt
from tools.my_dataset import AntsDataset
from tools.common_tools import set_seed
import torchvision.models as models
import torchvision
BASEDIR = os.path.dirname(os.path.abspath(__file__))
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
print("use device :{}".format(device))
set_seed(1) # 设置随机种子
label_name = {"ants": 0, "bees": 1}
# 参数设置
MAX_EPOCH = 25
BATCH_SIZE = 16
LR = 0.001
log_interval = 10
val_interval = 1
classes = 2
start_epoch = -1
lr_decay_step = 7
# ============================ step 1/5 数据 ============================
data_dir = os.path.join(BASEDIR, "data")
train_dir = os.path.join(data_dir, "train")
valid_dir = os.path.join(data_dir, "val")
norm_mean = [0.485, 0.456, 0.406]
norm_std = [0.229, 0.224, 0.225]
train_transform = transforms.Compose([
transforms.RandomResizedCrop(224),
transforms.RandomHorizontalFlip(),
transforms.ToTensor(),
transforms.Normalize(norm_mean, norm_std),
])
valid_transform = transforms.Compose([
transforms.Resize(256),
transforms.CenterCrop(224),
transforms.ToTensor(),
transforms.Normalize(norm_mean, norm_std),
])
# 构建MyDataset实例
train_data = AntsDataset(data_dir=train_dir, transform=train_transform)
valid_data = AntsDataset(data_dir=valid_dir, transform=valid_transform)
# 构建DataLoder
train_loader = DataLoader(dataset=train_data, batch_size=BATCH_SIZE, shuffle=True)
valid_loader = DataLoader(dataset=valid_data, batch_size=BATCH_SIZE)
# ============================ step 2/5 模型 ============================
# 1/3 构建模型
resnet18_ft = models.resnet18()#通过torchvision.models构建预训练模型resnet18
# 2/3 加载参数
# flag = 0
flag = 1
if flag:
path_pretrained_model = os.path.join(BASEDIR, "data/resnet18-5c106cde.pth")
state_dict_load = torch.load(path_pretrained_model)
resnet18_ft.load_state_dict(state_dict_load)#将参数加载到模型中
# 法1 : 冻结卷积层(它适用于当前任务数据量比较小,不足以训练卷积层,而只对最后的全连接层进行训练)
flag_m1 = 1
# flag_m1 = 1
if flag_m1:
for param in resnet18_ft.parameters():
param.requires_grad = False
# 打印第一个卷积层的卷积核参数,由输出结果可知,因为冻结了卷积层的参数,所以每次迭代时打印的卷积层的参数都不发生变化
# print("conv1.weights[0, 0, ...]:\n {}".format(resnet18_ft.conv1.weight[0, 0, ...]))
# 3/3 替换fc层
num_ftrs = resnet18_ft.fc.in_features#首先需要获取原模型的最后的全连接层的输入大小
resnet18_ft.fc = nn.Linear(num_ftrs, classes)#然后使用自己定义好的全连接层替换原来的输出层(即最后的全连接层),因为当前任务是2分类,所以classes=2
resnet18_ft.to(device)
# ============================ step 3/5 损失函数 ============================
criterion = nn.CrossEntropyLoss() # 选择损失函数
# ============================ step 4/5 优化器 ============================
# 法2 : 给卷积层设置较小的学习率
# flag = 1
flag = 0
if flag:
#获取最后的全连接层的参数地址,将它们存储成列表的形式,列表中的每个元素对应着每个参数的地址
fc_params_id = list(map(id, resnet18_ft.fc.parameters())) # 返回的是parameters的 内存地址
#过滤掉resnet18中最后的全连接层的参数
base_params = filter(lambda p: id(p) not in fc_params_id, resnet18_ft.parameters())
#通过上面两行代码,我们就可以分别获取resnet18的卷积层和全连接层,然后对这两部分分别设置不同的学习率
optimizer = optim.SGD([
{'params': base_params, 'lr': LR*0.1}, #卷积层设置的学习率是原始学习率的0.1倍
#{'params': base_params, 'lr': LR * 0}, #也可以将卷积层的学习率设置为0,这样就相当于固定卷积层不训练
{'params': resnet18_ft.fc.parameters(), 'lr': LR}], momentum=0.9)
else:
optimizer = optim.SGD(resnet18_ft.parameters(), lr=LR, momentum=0.9) # 选择优化器
scheduler = torch.optim.lr_scheduler.StepLR(optimizer, step_size=lr_decay_step, gamma=0.1) # 设置学习率下降策略
# ============================ step 5/5 训练 ============================
train_curve = list()
valid_curve = list()
for epoch in range(start_epoch + 1, MAX_EPOCH):
loss_mean = 0.
correct = 0.
total = 0.
resnet18_ft.train()
for i, data in enumerate(train_loader):
# forward
inputs, labels = data
inputs, labels = inputs.to(device), labels.to(device)
outputs = resnet18_ft(inputs)
# backward
optimizer.zero_grad()
loss = criterion(outputs, labels)
loss.backward()
# update weights
optimizer.step()
# 统计分类情况
_, predicted = torch.max(outputs.data, 1)
total += labels.size(0)
correct += (predicted == labels).squeeze().cpu().sum().numpy()
# 打印训练信息
loss_mean += loss.item()
train_curve.append(loss.item())
if (i+1) % log_interval == 0:
loss_mean = loss_mean / log_interval
print("Training:Epoch[{:0>3}/{:0>3}] Iteration[{:0>3}/{:0>3}] Loss: {:.4f} Acc:{:.2%}".format(
epoch, MAX_EPOCH, i+1, len(train_loader), loss_mean, correct / total))
loss_mean = 0.
# if flag_m1:
#print("epoch:{} conv1.weights[0, 0, ...] :\n {}".format(epoch, resnet18_ft.conv1.weight[0, 0, ...]))
scheduler.step() # 更新学习率
#保存模型权重
checkpoint = {"model_state_dict": resnet18_ft.state_dict(),
"optimizer_state_dict": optimizer.state_dict(),
"epoch": epoch}
PATH = f'./checkpoint_{epoch}_epoch.pkl'
torch.save(checkpoint,PATH)
# validate the model
if (epoch+1) % val_interval == 0:
correct_val = 0.
total_val = 0.
loss_val = 0.
resnet18_ft.eval()
with torch.no_grad():
for j, data in enumerate(valid_loader):
inputs, labels = data
inputs, labels = inputs.to(device), labels.to(device)
outputs = resnet18_ft(inputs)
loss = criterion(outputs, labels)
_, predicted = torch.max(outputs.data, 1)
total_val += labels.size(0)
correct_val += (predicted == labels).squeeze().cpu().sum().numpy()
loss_val += loss.item()
loss_val_mean = loss_val/len(valid_loader)
valid_curve.append(loss_val_mean)
print("Valid:\t Epoch[{:0>3}/{:0>3}] Iteration[{:0>3}/{:0>3}] Loss: {:.4f} Acc:{:.2%}".format(
epoch, MAX_EPOCH, j+1, len(valid_loader), loss_val_mean, correct_val / total_val))
resnet18_ft.train()
train_x = range(len(train_curve))
train_y = train_curve
train_iters = len(train_loader)
valid_x = np.arange(1, len(valid_curve)+1) * train_iters*val_interval # 由于valid中记录的是epochloss,需要对记录点进行转换到iterations
valid_y = valid_curve
plt.plot(train_x, train_y, label='Train')
plt.plot(valid_x, valid_y, label='Valid')
plt.legend(loc='upper right')
plt.ylabel('loss value')
plt.xlabel('Iteration')
plt.show()
- 模型预测,它的位置在 ./resnet_inference
import os
import time
import torch.nn as nn
import torch
import torchvision.transforms as transforms
from PIL import Image
from matplotlib import pyplot as plt
import torchvision.models as models
BASE_DIR = os.path.dirname(os.path.abspath(__file__))
# device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
device = torch.device("cpu")
# config
vis = True
# vis = False
vis_row = 4
norm_mean = [0.485, 0.456, 0.406]
norm_std = [0.229, 0.224, 0.225]
inference_transform = transforms.Compose([
transforms.Resize(256),
transforms.CenterCrop(224),
transforms.ToTensor(),
transforms.Normalize(norm_mean, norm_std),
])
classes = ["ants", "bees"]
def img_transform(img_rgb, transform=None):
"""
将数据转换为模型读取的形式
:param img_rgb: PIL Image
:param transform: torchvision.transform
:return: tensor
"""
if transform is None:
raise ValueError("找不到transform!必须有transform对img进行处理")
img_t = transform(img_rgb)
return img_t
def get_img_name(img_dir, format="jpg"):
"""
获取文件夹下format格式的文件名
:param img_dir: str
:param format: str
:return: list
"""
file_names = os.listdir(img_dir)
img_names = list(filter(lambda x: x.endswith(format), file_names))
if len(img_names) < 1:
raise ValueError("{}下找不到{}格式数据".format(img_dir, format))
return img_names
def get_model(m_path, vis_model=False):
resnet18 = models.resnet18()
num_ftrs = resnet18.fc.in_features
resnet18.fc = nn.Linear(num_ftrs, 2)
checkpoint = torch.load(m_path)
resnet18.load_state_dict(checkpoint['model_state_dict'])
if vis_model:
from torchsummary import summary
summary(resnet18, input_size=(3, 224, 224), device="cpu")
return resnet18
if __name__ == "__main__":
img_dir = os.path.join( "data/val/bees")
model_path = "./checkpoint_14_epoch.pkl"
time_total = 0
img_list, img_pred = list(), list()
# 1. data
img_names = get_img_name(img_dir)
num_img = len(img_names)
# 2. model
resnet18 = get_model(model_path, True)
resnet18.to(device)
resnet18.eval()#在模型预测阶段,一定要使用函数eval()将模型的状态设置为预测状态,而不是训练状态
with torch.no_grad(): #在模型预测阶段,一定要使用 with torch.no_grad()设置模型不去计算梯度,所以就不用保存这些梯度,这样可以既提高运算速度,又节省了显存
for idx, img_name in enumerate(img_names):
path_img = os.path.join(img_dir, img_name)
# step 1/4 :将图像转化为RGB格式
img_rgb = Image.open(path_img).convert('RGB')
# step 2/4 : 将RGB图像转化为张量的形式
img_tensor = img_transform(img_rgb, inference_transform)
#增加一个batch维度,将3维张量转化为4维张量
img_tensor.unsqueeze_(0)
img_tensor = img_tensor.to(device)
# step 3/4 : 将张量送入模型进行运算
time_tic = time.time()
outputs = resnet18(img_tensor)
time_toc = time.time()
# step 4/4 : visualization
_, pred_int = torch.max(outputs.data, 1)
pred_str = classes[int(pred_int)]
if vis:
img_list.append(img_rgb)
img_pred.append(pred_str)
if (idx+1) % (vis_row*vis_row) == 0 or num_img == idx+1:
for i in range(len(img_list)):
plt.subplot(vis_row, vis_row, i+1).imshow(img_list[i])
plt.title("predict:{}".format(img_pred[i]))
plt.show()
plt.close()
img_list, img_pred = list(), list()
time_s = time_toc-time_tic
time_total += time_s
print('{:d}/{:d}: {} {:.3f}s '.format(idx + 1, num_img, img_name, time_s))
print("\ndevice:{} total time:{:.1f}s mean:{:.3f}s".
format(device, time_total, time_total/num_img))
if torch.cuda.is_available():
print("GPU name:{}".format(torch.cuda.get_device_name()))