双目摄像头 三维坐标 python_uNetXST:将多个车载摄像头转换为鸟瞰图语义分割图像...

作者:Longway
来源:3D视觉工坊公众号
链接:uNetXST:将多个车载摄像头转换为鸟瞰图语义分割图像
项目地址:https://github.com/ika-rwth-aachen/Cam2BEV
论文地址:https://arxiv.org/pdf/2005.04078.pdf
概述
准确的环境感知对于自动驾驶来说是非常重要的,当用单目摄像头时,环境中的距离估计是一个很大的挑战。当摄像机视角转换为鸟瞰视角(BEV)时,距离能够更加容易的建立。对于扁平表面,逆透视映射能够准确的转换图像到BEV。但是对于三维物体来说,会被这种转换所扭曲,使得很难估计他们相对于传感器的位置。
这篇文章描述了一种获取360°鸟瞰图的方法,这些图像来自于多个摄像头。对校正后的BEV图像进行语义分割,并预测遮挡的部分。该方法不需要手工标注数据,而是在合成数据集上面进行训练,这样就能够在真实世界表现更好的效果。
介绍
最近,自动驾驶受到工业研究的广泛关注。自动驾驶的其中一个关键因素是准确的感知周围的环境,这对于安全来说至关重要。
不同的环境表示通过环境中的坐标信息都能够被计算出来,在用于了解环境的不同类型的传感器中,摄像机因其低成本和成熟的计算机视觉技术而流行。由于单目摄像机只能提供图像平面上位置的信息,因此可以对图像进行透视变换。
透视变换是从一个视角所看到的相同场景的近似,在这个视角中,成像平面与摄像机前面的地平面对齐。将相机图像转换为BEV的方法通常称为逆变换角度映射(IPM)。IPM假设世界是扁平的,但是任何三维物体都会违背这一假设,所以不太适用。
尽管IPM引入的错误是可以校正的,但是仍然需要在BEV中检测目标。深度学习方法对于语义分割等任务来说非常有效,但是需要标记数据,尽管模拟可以获得这些数据,和真实数据比起来还是有一些差距。从模拟中学习到的复杂任务到现实世界的归纳是困难的,为了缩小差距,许多方法都旨在使模拟数据更加真实。
在本文中,作者提出了一种不受IPM下的平度假设所带来的误差影响的BEV图像获取方法。通过计算语义分割的摄像机图像,从真实数据中去除大部分不必要的纹理。
通过语义分割的输入,该算法能够获取类信息,从而能够将这些信息纳入IPM生成的图像的校正中。模型的输出是输入场景的语义分段BEV,由于对象形状被保留,输出不仅可以用于确定自由空间,而且可以定位动态对象。
此外,语义分割的BEV图像包含了未知区域的颜色编码,这些未知区域被遮挡在原始摄像机图像中。IPM得到的图像和所需的真实BEV图像如下图所示。

这项工作的贡献如下所示:
1:提出了一种在BEV中能够将多个车载摄像机图像转换为语义分割图像的方法;
2:使用不同的神经网络架构,设计并比较了两种不同的方法,其中一种是专门为这项任务设计的;
3:在设计过程中,不需要对BEV图像进行人工标记来训练基于神经网络的模型;
4:最后展示了一个成功的实际应用的模型。
相关工作
许多文献都说到了视角到BEV的转变,大多数作品都是基于几何的,重点是对地面的精确描绘。只有少数作品将摄像机图像转换成BEV与场景理解的任务结合起来。然而,他们却忽略了物体检测可以提供物体几何形状的线索,从而使变换受益。最近,一些深度学习方法展示了复杂的神经网络帮助改进经典的IPM技术,使其有助于环境感知。
比如说移除动态和三维物体来提高对道路场景的理解【1】,或者通过一个前置摄像头,合成整个道路场景的精确BEV表示【2】,这些方法都用到了GAN网络。还有很多方法,但是在作者看来,追求将多个语义分割的图像直接转换为BEV的想法的唯一来源是一篇博客文章【3】。该文章设计的神经网络是一个全卷积的自编码器,伴随着很多缺点,比如准确的目标检测范围相对较低。
方法
该作品基于卷积神经网络(CNN)的使用,但是大多数的CNNs只处理一个输入图像。为了融合安装在车辆上的多个摄像头的图像,单输入网络可以将多个图像按其通道级联作为输入。然而,这将导致输入和输出图像之间的空间不一致,卷积层在局部操作。针对这个问题的学习方法需要能够处理多视点图像,这表明需要一种额外的机制。
就像前面说到的,IPM会引入误差,但该技术至少能够产生与地面真实BEV图像相似的图像。由于这种相似性,将IPM作为一种机制来提供输入和输出图像之间更好的空间一致性似乎是合理的。
下面将介绍基于神经网络的方法的两种变体,它们都包含IPM的应用。在介绍这两种神经网络结构之前,作者详细介绍了应用的数据预处理技术。
1、处理遮挡:当只考虑输入域和期望的输出时,会出现一个明显的难题:交通参与者和静态障碍可能会遮挡部分环境,使得在BEV图像中预测这些区域几乎不可能。举个例子,当你在卡车后面行驶时,就会出现这样的遮挡:卡车前面发生的情况不能仅从车载摄像机的图像可靠地判断出来。
如何解决这位问题?作者对于每个车辆摄像机,虚拟光线从其安装位置投射到语义分割的地面真值BEV图像的边缘。对沿着这些射线的所有像素进行处理,根据以下规则确定它们的遮挡状态:
1.1:一些语义类如建筑、卡车总是阻塞视线;
1.2:一些语义类如道路从不遮挡视线;
1.3:汽车会挡住视线,但后面较高的物体如卡车、公共汽车除外;
1.4:部分被遮挡的物体仍然完全可见;
1.5:物体只有在所有的相机透视图中都被遮挡的情况下才被标记为被遮挡。
根据这些规则修改的真实BEV图像如下图所示。

2、投影预处理:IPM技术作为方法中的一部分,作者推导了汽车摄像机框架与BEV之间的投影变换,确定了单应矩阵涉及的相机内部和外部参数,并应在下面简要说明。
世界坐标xw和图像坐标xi之间的关系由以下投影矩阵P给出:

投影矩阵将相机的内在参数如焦距编码为一个矩阵K和外参(世界坐标系中的旋转R和平移t):

假设存在从道路平面xr到世界坐标系的变换M:

就可以获得从图像坐标xi到道路平面xr的转换:
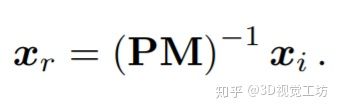
设置该变换作为捕捉与真实BEV图像相同的视野。由于这一区域被所有摄像机图像的并集覆盖,因此它们首先通过IPM分别变换,然后合并成一个单独的图像,以下称为单应图像。重叠区域中的像素,即从两个摄像机可见的区域,从变换后的图像中任意选择一个。
3、变体1-单输入模型:作者预先计算如上节所示的单应性图像,以弥补相机视图和BEV之间的很大一部分差距。作者在此提供了神经网络输入与输出在一定程度上的空间一致性,网络的任务就是纠正IPM带来的错误。
由于单应性图像和期望的目标输出图像覆盖相同的空间区域,作者使用已有的CNNS进行图像处理,这在语义分割等其他任务上已经被证明是成功的。最后作者选择了DeepLabv3+作为单网络输入的架构。
4、变体2-多输入模型:该模型处理来自车辆摄像头的所有非转换图像作为输入,在未转换的相机视图中提取特征,因此不完全受IPM引入的误差的影响。作为一种解决空间不一致性问题的方法,作者将射影变换集成到网络中。
为了构建一个多输入单输出图像的架构,作者将现有的CNN扩展为多个输入流,并在内部融合这些流。由于其简单性和易于扩展性,作者选择了流行的语义分割架构U-Net作为扩展的基础。最后简单的网络结构如下所示:

结果展示

在模拟数据集上面的测试效果

在真实世界的测试效果
总结和思考
作者提出了一种能够通过多个车载摄像头采集到的数据,获得道路状况鸟瞰图的方法。其中解决了一些不利因素的影响,如前面提到不正确的平面假设所产生的误差,并且无需人工标记BEV数据集,最后产生的效果如上图所示。
在我看来,这是一项非常棒的工作,对于自动驾驶环境感知的研究有很大帮助。但是仍然有一些不足,在模拟数据集上面的效果和标签相差无几,在真实世界的效果却不是很好。同时道路交通也是一个非常复杂的情况,需要更深层次的研究。
【1】T. Bruls, H. Porav, L. Kunze, and P. Newman, “The Right (Angled) Perspective: Improving the Understanding of Road Scenes Using Boosted Inverse Perspective Mapping,” in 2019 IEEE Intelligent Vehicles Symposium (IV), 2019, pp. 302–309.
【2】X. Zhu, Z. Yin, J. Shi, H. Li, and D. Lin, “Generative Adversarial Frontal View to Bird View Synthesis,” arXiv:1808.00327 [cs], 2019.
【3】M. Dziubinski. (2019, 05) From semantic segmentation to semantic ´ bird’s-eye view in the CARLA simulator. [Online]. Available: https://medium.com/asap-report/from-semantic-segmentationto-semantic-birds-eye-view-in-the-carla-simulator-1e636741af3f
本文仅做学术分享,如有侵权,请联系删文。
往期干货资源:
汇总 | 国内最全的3D视觉学习资源,涉及计算机视觉、SLAM、三维重建、点云处理、姿态估计、深度估计、3D检测、自动驾驶、深度学习(3D+2D)、图像处理、立体视觉、结构光等方向!
汇总 | 3D目标检测(基于点云、双目、单目)
汇总 | 6D姿态估计算法(基于点云、单目、投票方式)
汇总 | 三维重建算法实战(单目重建、立体视觉、多视图几何)
汇总 | 3D点云后处理算法(匹配、检索、滤波、识别)
汇总 | SLAM算法(视觉里程计、后端优化、回环检测)
汇总 | 深度学习&自动驾驶前沿算法研究(检测、分割、多传感器融合)
汇总 | 相机标定算法
汇总 | 事件相机原理
汇总 | 结构光经典算法
汇总 | 缺陷检测常用算法与实战技巧