半监督目标检测(五)
目录
Semi-supervised Object Detection via Virtual Category Learning
动机
1. Overview
2. Potential Category Set
1)Temporal stability
2)Cross-model verification
3. Virtual Category Learning
4. Localisation Loss
Semi-supervised Object Detection via Virtual Category Learning
动机
针对半监督目标检测(SSOD)任务存在的 confirmation bias 问题(即模型给出了高置信度的错误预测,而这些错误的预测随后转变为错误的伪标签,在训练过程中累积,而模型无法自行纠正这些错误预测),而这一现象往往是因为模型难以对那些易混淆的样本生成可靠的伪标签。在此前的 SSOD 模型中,这些样本要么被直接过滤掉,要么保留它们所有的可能类别标签。作者认为这两种策略都不是最优的,应该积极利用这些易混淆的数据训练模型,不去在意这些样本的具体标签信息,而是用一个虚拟类别标签(Virtual Category label)来代替伪标签,使它们参与模型优化,从而进一步提升检测模型的性能。

1. Overview

作者采用 Faster R-CNN(FPN + ResNet-50)作为基础检测器,在传统的教师-学生模型的基础上,生成伪标签。而针对易混淆样本,先建立一个潜在类别集合(potential category PC set),纳入易混淆样本的可能类别,之后使用 Virtual Category(VC)标签代替 PC 集合里不那么确定的伪标签,并以此为基础,调整交叉熵损失函数为 VC loss,计算梯度。
2. Potential Category Set
作者分别尝试了两种获得潜在类别集合的方法:
1)Temporal stability

训练模型时,图像在不同的迭代次数可能产生不同的伪标签集合 ![]() ,而这些变化的伪标签就包含了潜在类别的信息。具体来说,作者对比当前迭代步骤输出的
,而这些变化的伪标签就包含了潜在类别的信息。具体来说,作者对比当前迭代步骤输出的 ![]() 与模型最后一次处理某一图像生成的伪标签集合
与模型最后一次处理某一图像生成的伪标签集合 ![]() (不很确定这里的表述)。对于一个伪标签 b' (
(不很确定这里的表述)。对于一个伪标签 b' ( ![]() ),如果有一个与之相邻的
),如果有一个与之相邻的 ![]() ,但两者的类别相同,即
,但两者的类别相同,即 ![]() ,则意味该标签不存在混淆信息;否则(
,则意味该标签不存在混淆信息;否则(![]() ),则潜在类别集合更新为
),则潜在类别集合更新为 ![]() ;而若没有临近的伪标签框,则意味着可能混淆的类别为“背景”,因此
;而若没有临近的伪标签框,则意味着可能混淆的类别为“背景”,因此 ![]() 。
。
【注】作者使用 IoU 来判定两个伪包围框是否“邻近”。
2)Cross-model verification
受 Co-training 算法的启发,两个条件独立的模型对同一个样本的预测可能不同,从而可以从中挖掘潜在类别。作者用不同的参数初始化分别初始化两个模型,而且将训练样本输入模型的顺序也不同,从而确保两个模型的差异性。对于第一个检测器生成的伪包围框 ![]() 内的目标,作者用第二个检测器的伪包围框
内的目标,作者用第二个检测器的伪包围框 ![]() 来验证,PC 集合的更新方式与 Temporal stability 方法类似,不再赘述。
来验证,PC 集合的更新方式与 Temporal stability 方法类似,不再赘述。
3. Virtual Category Learning
如果 PC 集合里有不只一个类别,则意味着该样本为易混淆的样本,对于这样的样本,会在其学生分类器的权重矩阵 W 中额外增加一个虚拟权重(virtual weight)向量 ![]() 。
。![]() 取自该样本在教师模型中对应的特征向量
取自该样本在教师模型中对应的特征向量 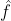 ,不同的易混淆样本的虚拟权重是不同的。
,不同的易混淆样本的虚拟权重是不同的。
【注】会对 进行缩放和标准化,从而确保 ![]() 的范数与 W 矩阵中的权重向量的范数取值范围相同。
的范数与 W 矩阵中的权重向量的范数取值范围相同。

上式中,N 为原本的类别总数,,![]() 和
和 ![]() 分别为虚拟类别和类别
分别为虚拟类别和类别  的 logits。为了计算修改后的 logits 的损失值,会在原本的独热向量标签中为虚拟类别增加一个正值标签“1”,而 PC 中包含的那些易混淆的类别则相应地被忽略。
的 logits。为了计算修改后的 logits 的损失值,会在原本的独热向量标签中为虚拟类别增加一个正值标签“1”,而 PC 中包含的那些易混淆的类别则相应地被忽略。

作者针对 VC,对标准的交叉熵(Cross Entropy CE)损失进行了修改,提出 VC loss:

式一中, ![]() 是最后一个线性层的输入特征向量,
是最后一个线性层的输入特征向量,![]() 是
是 ![]() 类别对应的最后线性层的权重向量,
类别对应的最后线性层的权重向量,![]() 是
是 ![]() 类别的 logit,N 是原本的类别总数,GT 是 ground truth(简单起见,忽略了线性层的 bias)。
类别的 logit,N 是原本的类别总数,GT 是 ground truth(简单起见,忽略了线性层的 bias)。
式二中,PC 表示 PC 集合,当 ![]() 时,表示虚拟类别,即
时,表示虚拟类别,即 ![]() 。
。![]() 则意味着 PC 集合中那些不确定的潜在类别在计算中被忽略了,从而不会在训练中误导模型。
则意味着 PC 集合中那些不确定的潜在类别在计算中被忽略了,从而不会在训练中误导模型。

上图是 VC 的一种直观解释。在特征空间中,VC 会将易混淆的训练样本推离那些不可能的类别,同时也避免它过于靠近任何一个易混淆的潜在类别。
4. Localisation Loss
作者没有使用 IoU 值过滤整个包围框(bounding box),而是将水平和垂直方向的边框解耦,分别考察它们的定位质量。作者指出,即使包围框的其余几条边定位性能良好,但只要有一条边定位不准,就会影响 IoU 的值。
以水平方向的边框为例,quality flag 的计算公式如下:

其中,![]() 分别为伪框
分别为伪框  和邻框
和邻框 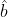 (GT box?)左、右两侧边框的横坐标,w 是伪框 的宽度,
(GT box?)左、右两侧边框的横坐标,w 是伪框 的宽度,![]() 是筛选高质量边框的阈值。
是筛选高质量边框的阈值。

