朴素贝叶斯分类【垃圾邮件检测】
**训练模型基本流程:
- 获取数据:pandas读取数据;
- 数据分析:;
- 数据处理:数据预处理,划分得到训练集测试集;
- 模型训练与测试:调用sklearn.naive_bayes;
- 模型评估:使用【f1】评估模型**
问题描述:
根据邮件文本数据预测该邮件是否为垃圾邮件。使用朴素贝叶斯分类器。
数据集:“spam_data.txt”(7148条数据)
其中垃圾邮件:960条,非垃圾邮件:6188条。
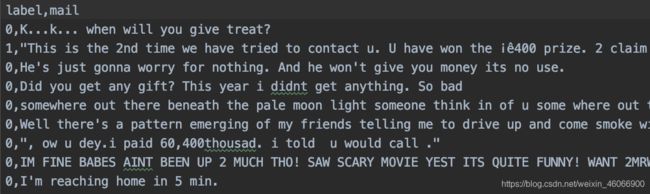
数据描述:一共7148条样本,分类标签为{0, 1}分别表示,否和是。基于文本数据,判定邮件是否为垃圾邮件。部分数据如下:
- 获取数据:pandas读取数据;
def get_Data(filename):
data = pd.read_csv(filename, sep=',', engine='python')
print(data.head())
return data
- 数据分析:;
def del_data(data):
# 分割数据
X_train, X_test, y_train, y_test = train_test_split(
data["mail"], data["label"], test_size=0.2, random_state=15)
# 清洗数据
train_data = []
test_data = []
for review in X_train:
train_data.append(' '.join(collation_data(review)))
for review in X_test:
test_data.append(' '.join(collation_data(review)))
X_train_std, X_test_std = remove_stop_words(train_data + test_data, len(train_data))
return X_train_std, X_test_std, y_train, y_test
- 数据处理:数据预处理,划分得到训练集测试集;
数据的清洗,同时去除停用词
def deal_data(review):
# 清洗html标签遗留的脏数据;
review_text = BeautifulSoup(review, "html.parser").get_text()
# 清洗非文字部分(比如标点);
review_text = re.sub("[^a-zA-Z]", " ", review_text)
# 将单词全部转换为小写;
words = review_text.lower().split()
return words
def encode(wordsData):
# One-hot编码 or Bag of words。
# 提示:可以根据实际情况定义函数 encode 或 bag_words。
# One-hot 编码
token_index = {} # 构建数据中所有标记的索引
for words in wordsData:
for word in words.split(): # 用split方法对样本进行分词,实际应用中,可能还需要考虑到标点符号
if word not in token_index:
token_index[word] = len(token_index) + 1 # 为每个唯一单词指定唯一索引,注意我们没有为索引编号0指定单词
max_length = len(token_index) # 对样本进行分词,只考虑样本前max_length单词
results = np.zeros((len(wordsData), max_length, max(token_index.values()) + 1)) # 将结果保存到results中
for i, words in enumerate(wordsData):
for j, word in list(enumerate(words.split()))[:max_length]:
index = token_index.get(word)
results[i, j, index] = 1
return results
- 模型训练与测试:调用sklearn.naive_bayes;
模型评估:
模型训练。(定义为函数 def model_fit_pred():)
def model_fit_pred(X_train_std, X_test_std, y_train, y_test):
# 多项式贝叶斯
model = MultinomialNB(alpha=1.0, class_prior=None, fit_prior=True)
# 伯努利贝叶斯
# model = BernoulliNB(alpha=1, binarize=0.0, class_prior=None, fit_prior=True)
model.fit(X_train_std, y_train)
pred = model.predict(X_test_std)
print("准确率:", model.score(X_test_std, y_test))
return pred
#模型评估。(定义为函数: def evaluate(): )
def evaluate(y_test, pred):
print("f1_score:", f1_score(y_test, pred))
print("classification_report: \n", classification_report(y_test, pred))
调用函数
# 数据路径
file_name = r"D:/pyCharm/例子/机器语言/spam_data.txt"
# 读取数据
data = get_Data(file_name)
# 数据处理
X_train_std, X_test_std, y_train, y_test = del_data(data)
# 模型预测
pred = model_fit_pred(X_train_std, X_test_std, y_train, y_test)
# 模型评估
evaluate(y_test, pred)
运行结果:
