图神经网络关系抽取论文阅读笔记(五)
1 依赖驱动的注意力图卷积网络关系抽取方法(Dependency-driven Relation Extractionwith Attentive Graph Convolutional Networks)
论文:Dependency-driven Relation Extraction with Attentive Graph Convolutional Networks.ACL 2021
1.1 引言
现有的研究已经广泛使用句法信息,特别是依赖树,来改进关系提取,为分析与给定实体相关的上下文信息提供更好的语义指导。
然而,现有的研究大多存在依赖树噪声的问题,特别是当依赖树自动生成时,过度利用依赖信息可能会给关系分类带来混乱,必要的修剪在这一任务中非常重要。本文提出了一种依赖驱动的关注图卷积网络(A-GCN)关系提取方法。在这种方法中,一种基于图卷积网络的注意机制应用于从现成的依赖解析器获得的依赖树中的不同上下文单词,以区分不同单词依赖的重要性。
考虑到单词之间的依赖类型也包含重要的上下文指导,这可能有助于关系提取,我们还在A-GCN建模中包含了类型信息。在两个英语基准数据集上的实验结果证明了我们的A-GCN的有效性,在两个数据集上都达到了最先进的性能
1.2 创新点
1.2.1 之前的研究:
- 使用功能强大的编码器(如CNN、RNN和transformer)显著提高了RE的模型性能,而不需要任何精心设计的系统或手动构造的特征。
- 在所有不同的知识来源中,句法信息,特别是依赖树,在许多研究中被证明是有益的(Miwa和Bansal, 2016;张等,2018;孙等,2020;Chen et al, 2021),因为它们提供了有用单词之间的远距离单词连接,从而相应地指导系统更好地提取实体对之间的关系。
1.2.2 现有问题
- 然而,密集利用依赖信息可能并不总是能带来良好的正则性能,因为依赖树中的噪声可能会潜在地给关系分类带来混淆,特别是当这些树是自动生成的。
- 以往的研究在通过LSTM (Xu et al, 2015)或图卷积网络(GCN) (Zhang et al, 2018)等特定模型编码依赖信息之前,总是需要必要的修剪策略。由于固定修剪策略不能保证得到包含所有重要上下文信息和过滤所有噪声的子树,因此有必要设计一种适当的方法来区分依赖树中的噪声并相应地建模。(有突破口,只考虑了设计一种方法来区分依赖树中的噪声并相应地建模,并没有考虑合理的包含所有重要上下文信息,只考虑了尽可能过滤噪声,可不可以两者兼顾,拼接一下呢?)

1.2.3 本文提出的
- 在本文中,我们提出了一种依赖驱动的神经网络方法,其中注意图神经网络(A-GCN)用于区分该任务的重要上下文信息。
- 先从现成的工具中获取输入句子的依赖树,然后在依赖树上构建图,并为任意两个单词之间的不同标记依赖连接分配不同的权重,根据连接及其依赖类型计算权重,最后根据学习到的权重由AGCN预测关系。
- 优点:考虑到与依赖连接相关的依赖类型(例如,名义主语);A-GCN不仅能够从依赖树中区分重要的上下文信息并相应地利用它们,这样就不需要依赖修剪策略了,而且A-GCN还可以利用大多数之前的研究(特别是也使用了注意机制的研究(Guo et al, 2019))忽略的依赖类型信息。
1.3 A-GCN
1.3.1 问题定义
模型的整体架构如下图所示。具体来说,给定一个非结构化输入语句 X = x1,···,xn,其中有n个单词并让 E1 和 E2 表示 X 中的两个实体,我们的方法通过以下方式预测 E1 和 E2 之间的关系 :
r ^ = arg max r ∈ R p ( r ∣ A − G C N ( X , T X ) ) \widehat{r}=\underset{r \in \mathcal{R}}{\arg \max } p\left(r \mid \mathrm{A}-\mathrm{GCN}\left(\mathcal{X}, \mathcal{T}_{\mathcal{X}}\right)\right) r =r∈Rargmaxp(r∣A−GCN(X,TX))
其中Tx是从现成的工具包中获得的x的依赖树,R是关系类型集; P计算给定两个实体的特定关系r的概率,而是r以X和Tx为输入的A-GCN的输出。
1.3.2 传统图卷积
在标准的GCN中,单词之间的连接被平等对待(即ai,j为0或1)。因此,基于GCN的正则模型无法区分不同连接的重要性,因此对它们进行修剪对正则非常重要。传统图卷积计算公式如下:
h i ( l ) = σ ( ∑ j = 1 n a i , j ( W ( l ) ⋅ h j ( l − 1 ) + b ( l ) ) ) \mathbf{h}_i^{(l)}=\sigma\left(\sum_{j=1}^n a_{i, j}\left(\mathbf{W}^{(l)} \cdot \mathbf{h}_j^{(l-1)}+\mathbf{b}^{(l)}\right)\right) hi(l)=σ(j=1∑nai,j(W(l)⋅hj(l−1)+b(l)))
1.3.3 模型架构
我们的方法通过使用A-GCN和合并依赖信息来遵循这个范式,以提高模型性能,其中我们的模型的总体架构如图2所示。

因此,我们提出了A-GCN,它使用一种注意机制来计算不同连接的权重,使模型能够相应地利用不同的依赖连接。
1.3.4 依赖类型矩阵
此外,标准GCN和大多数以前的研究忽略了与依赖连接相关的依赖类型,这些类型包含对RE非常有用的信息,在本文中被引入到A-GCN中。我们首先用类型矩阵在 T X T_X TX中表示依赖类型 T = ( t i , j ) n × n \mathbf{T}=\left(t_{i, j}\right)_{n \times n} T=(ti,j)n×n,其中ti,j是xi和xj之间的有向依赖连接相关的依赖类型(如nsubj);接下来,我们将每种类型ti,j映射到它的嵌入eti,j。然后,在第l- GCN层,计算xi和xj之间连接的权值。
p i , j ( l ) = a i , j ⋅ exp ( s i ( l ) ⋅ s j ( l ) ) ∑ j = 1 n a i , j ⋅ exp ( s i ( l ) ⋅ s j ( l ) ) p_{i, j}^{(l)}=\frac{a_{i, j} \cdot \exp \left(\mathbf{s}_i^{(l)} \cdot \mathbf{s}_j^{(l)}\right)}{\sum_{j=1}^n a_{i, j} \cdot \exp \left(\mathbf{s}_i^{(l)} \cdot \mathbf{s}_j^{(l)}\right)} pi,j(l)=∑j=1nai,j⋅exp(si(l)⋅sj(l))ai,j⋅exp(si(l)⋅sj(l))
其中,ai,j为领接矩阵A,“.”表示内积,si和sj是xi和xj的两个辅助矩阵,计算方法如下:
s i ( l ) = h i ( l − 1 ) ⊕ e i , j t \mathbf{s}_i^{(l)}=\mathbf{h}_i^{(l-1)} \oplus \mathbf{e}_{i, j}^t si(l)=hi(l−1)⊕ei,jt和 s j ( l ) = h j ( l − 1 ) ⊕ e i , j t \mathbf{s}_j^{(l)}=\mathbf{h}_j^{(l-1)} \oplus \mathbf{e}_{i, j}^t sj(l)=hj(l−1)⊕ei,jt;表示向量拼接。
1.3.5 A-GCN
我们对xi和xj之间的关联依赖连接施加权重p(i,j),通过以下方式训练得到xi的输出表示:
h i ( l ) = σ ( ∑ j = 1 n p i , j ( l ) ( W ( l ) ⋅ h ~ j ( l − 1 ) + b ( l ) ) ) \mathbf{h}_i^{(l)}=\sigma\left(\sum_{j=1}^n p_{i, j}^{(l)}\left(\mathbf{W}^{(l)} \cdot \widetilde{\mathbf{h}}_j^{(l-1)}+\mathbf{b}^{(l)}\right)\right) hi(l)=σ(j=1∑npi,j(l)(W(l)⋅h j(l−1)+b(l)))
其中W和b是权重矩阵和偏置, h ~ j ( l − 1 ) \tilde{\mathbf{h}}_j^{(l-1)} h~j(l−1)是x的一种加强表示,计算方法如下:
h ~ j ( l − 1 ) = h j ( l − 1 ) + W T ( l ) ⋅ e i , j t \tilde{\mathbf{h}}_j^{(l-1)}=\mathbf{h}_j^{(l-1)}+\mathbf{W}_T^{(l)} \cdot \mathbf{e}_{i, j}^t h~j(l−1)=hj(l−1)+WT(l)⋅ei,jt
其中 W T W_T WT是为了将依赖类型embdding映射为跟h一样的维度。
1.3.6 A-GCN用于知识抽取
现将句子放入BERT中,并加入[CLS]开始标记位,得到隐藏向量表示h,之后放入A-GCN(L层)获得 h i ( L ) \mathbf{h}_i^{(L)} hi(L),然后,我们将最大池机制应用于属于一个实体提及(即 E k E_k Ek,K=1,2)的词的输出隐藏向量,以计算实体表示(表示为 h E k h_Ek hEk)
h E k = MaxPooling ( { h i ( L ) ∣ x i ∈ E k } ) \mathbf{h}_{E_k}=\operatorname{MaxPooling}\left(\left\{\mathbf{h}_i^{(L)} \mid x_i \in E_k\right\}\right) hEk=MaxPooling({hi(L)∣xi∈Ek})
之后,我们将句子 h x h_x hx和两个实体 h E 1 和 h E 2 h_E1和h_E2 hE1和hE2的表示连接起来,并将一个可训练矩阵 W R W_R WR应用于计算的向量,以通过以下步骤将其映射到输出空间:
o = W R ⋅ ( h X ⊕ h E 1 ⊕ h E 2 ) \mathbf{o}=\mathbf{W}_R \cdot\left(\mathbf{h}_{\mathcal{X}} \oplus \mathbf{h}_{E_1} \oplus \mathbf{h}_{E_2}\right) o=WR⋅(hX⊕hE1⊕hE2)
其中,o是一个| R |维向量,其每个值都表示关系类型集R中的关系类型。最后,我们通过o的softmax函数通过以下公式预测E1和E2之间的关系:
r ^ = arg max exp ( o u ) ∑ u = 1 ∣ R ∣ exp ( o u ) \widehat{r}=\arg \max \frac{\exp \left(o^u\right)}{\sum_{u=1}^{|\mathcal{R}|} \exp \left(o^u\right)} r =argmax∑u=1∣R∣exp(ou)exp(ou)
1.4 实验部分
1.4.1 数据集
在实验中,我们为模型准备了两个英文基准数据集,即 ACE2005EN和 SemEval 2010 。对于 ACE05,我们对其进行预处理(删除两个小子集 cts 和 un)并将文档拆分成训练集、开发集和测试集。下图中显示了 ACE05 和 SemEval 基准数据集的训练/开发/测试集的实例数(即实体对数)。
1.4.2 依赖图构建
为了构造A-GCN的图,我们使用标准的CorenLP Toolkits(SCT)来获得每个输入句子x的依赖关系树Tx。虽然我们的方法能够通过注意力机制来区分不同依赖关系的重要性,但如果我们能够通过特定的剪枝策略过滤掉那些给RE带来混乱的依赖关系,则仍然是有益的。 本文通过包含两组依赖连接,即局部连接和全局连接,构造了A-GCN的图。 具体来说,局部连接包括直接连接到两个实体头部的所有依赖项,全局连接包括沿着两个实体头部之间的最短依赖路径(SDP)的所有依赖项,在许多情况下,也涉及到不直接连接到两个实体的字。 通过一个包括两个实体(即“公司”和基准测试)的示例语句,下图说明了两组依赖关系以及由这两组关系构建的邻接矩阵。 值得注意的是,当SDP较短时,本地组中的连接可能比全局组中的连接多。

1.4.3 具体实施
我们在输入句子中插入四个特殊标记(即“”、“”、“”和“”)来标记两个实体的边界,这使得编码器在编码过程中能够区分实体的位置,从而提高模型性能。对于编码器,我们使用 BERT。对于A-GCN,我们随机初始化所有可训练参数和依赖类型嵌入。 为了评估方便,我们遵循以前的研究,使用标准的微观F1分数在ACE05数据集上,使用宏观平均F1分数在Semeval数据集上。 在我们的实验中,我们尝试了不同的超参数组合,并在DEV集上对它们进行调整,然后用在DEV集上获得最高F1分数的模型对测试集进行评估。
1.4.4 实验结果

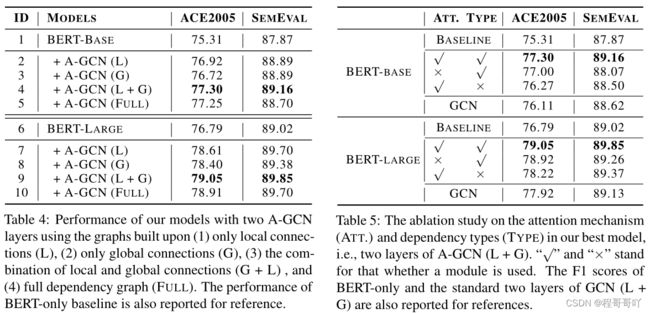
我们的A-GCN模型的F1分数和基线(即仅Bert-only,标准GAT,标准GCN)在不同设置下,使用Bert-Base(A)和Bert-Large(B)。 所有基于图的模型(即GAT、GCN和A-GCN)都使用两种设置进行测试:第一种是使用包含所有依赖连接的全图(FULL),第二种是使用局部和全局连接的组合(L+G)。 我们还运行具有不同层数(即1到3层)的GCN和A-GCN,以进行公平的比较。

在ACE05和Semeval上使用两层的A-GCN和Bert-Large编码器将前人研究和我们的最佳模型进行了比较(F1评分)。
使用 BERT-large 编码器在来自 SemEval 的三组测试实例上的不同模型(即仅 BERT、两层标准 GCN 和两层 A-GCN)的性能(F1 分数),其中每组是基于生成的关于实例中两个实体之间的距离(即单词数)。
1.4.5 分析
模型利用不同类型依存信息,在两个基准数据集上的性能、不同设定下模型在两个基准数据集上的性能如下:
下图中为示例输入分配给A-GCN(full)和AGCN(L+G)不同依赖连接的权重的可视化,其中较深和较粗的线表示具有较高权重的连接。

1.5 总结
本文提出了利用依赖信息进行关系提取的A-GCN方法,即对依赖连接应用注意机制,对连接和类型同时施加权重,以便更好地区分重要的依赖信息并进行相应的利用。在这样做的过程中,A-GCN能够动态地从不同的依赖连接中学习,从而巧妙地修剪信息较少的依赖。在两个用于关系提取的英语基准数据集上的实验结果和分析证明了我们的方法的有效性,特别是对于长单词序列距离的实体,在两个数据集上都获得了最先进的性能。
1.6 个人点评
该论文主要创新点提出了一种依赖驱动的神经网络方法,利用依赖树建图,引入注意力机制获得注意力权重矩阵,可以用于区分该任务的重要上下文信息,从而达到依存语法树降噪的效果;此外,本文一大创新点是考虑到与依赖连接相关的依赖类型(例如,名义主语)对RE也可能有用,因为它们包含连接词之间的语法指令,通过向A-GCN中引入类型信息来进一步改进模型。
1.7 文章参考
https://blog.csdn.net/weixin_41545327/article/details/126966157?spm=1001.2014.3001.5502
论文地址:https://aclanthology.org/2021.acl-long.344.pdf
论文代码:GitHub - cuhksz-nlp/RE-AGCN
[博客参考]:本文为ACL2021中的一篇论文,从实验结果来看,使用GCN是有增益的,尤其是加入了attention 系数的GCN,但是增益不会很大,且GCN并不需要太多层,2层性能就不错,甚至使用Full信息的时候,也就是 依存关系全保留的情况下,使用GCN反而有坏处,如图中的 +1 GCN Layer FULL效果都比Baseline差,精简了信息以后,才有一定的正向增益。相比于使用GAT模型,作者由于引入了entity type信息,故整体的效果还是可以的。GNN模型本身的思想是信息的传播与聚合,在这个过程中,信息会进行流动,相同类别的数据会趋同,不同类别的数据差异会拉大,故GNN非常适用于分类任务,经典的任务如在cora上进行半监督学习。但是用于其他的任务,这种信息的聚合流动不一定能带来收益。由此观之,Graph的信息并不是越多越好,去掉噪声信息,保留核心信息便于模型“突出重点”,而不是全局平均化。