全连接神经网络单层模型原理
前言
深度学习是学习样本数据的内在规律和表示层次,在学习过程中获得的信息对诸如文字,图像和声音等数据的解释有很大的帮助。全连接神经网络(MLP)便是基础的网络类型的之一,充分体现深度学习方法相比于传统机器学习算法的特点,即大数据驱动、公式推导、自我迭代更新、黑匣子训练等。
单层MLP
单层神经网络训练依据是找到一组感知器的权重,使得这组感知器的输出与期望输出之间的误差最小。实现步骤如下:
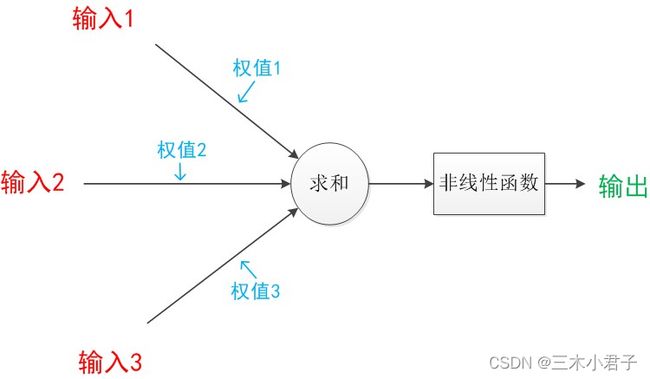
※第一步:初始化一个随机权重矩阵
※第二步:输入特征数据计算感知器的输出,即前向传播
※第三步:计算感知器输出向量与样本期望输出之间的误差,即损失函数
※第四步:根据计算的误差,计算权重矩阵的更新梯度,即梯度下降
※第五步:用更新梯度,更新权重矩阵。
※第六步:从第二步反复执行,直到训练结束(训练次数根据经验自由确定)
1. 前向传播
给每一个输入向量分配权值,计算出一个结果向量 。一般为了使神经网络具有非线性特点,引入激活函数来处理线性变换得到的数值。
线性变换(加权和偏置): z = w T x + b z = w^T x + b z=wTx+b
非线性变换(激活函数sigmoid): δ ( x ) = 1 1 + e − z \delta (x) = \frac{1}{{1 + e^{ - z} }} δ(x)=1+e−z1
上式中 w w w为权值, b b b为偏置, x x x为输入值, z z z 为线性输出值, δ \delta δ为非线性输出值。
2. 激活函数
那么为什么要引入激活函数呢?
答:如果网络中缺少了激活函数,神经网络会变成一个线性分类器,且当层次数增多越靠后的神经元获得的值会非常大,如果这个数远远大于前面神经元的值,前面神经元将对整个网络的表达显得毫无意义。因此,需要在每创建一层网络时就要对 进行一次约束。
下面是几种常见的激活函数。
2.1 Sigmoid函数
S ( x ) = 1 1 + e − x S(x) = \frac{1}{{1 + e^{ - x} }} S(x)=1+e−x1
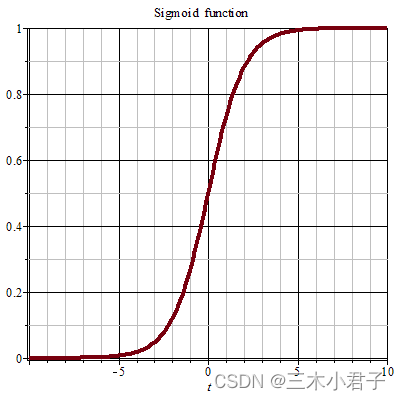
Sigmoid函数在输入值大于5的时候,其输出接近1,在输入值小于-5的时候,其输出接近0,输入的值会被压缩到(0,1)之间。
特点:输出大于0,且不是中心对称
2.2 tanh函数
tanh是双曲函数中的一个,tanh()为双曲正切。在数学中,双曲正切“tanh”是由基本双曲函数双曲正弦和双曲余弦推导而来。
tanh x = sinh x cosh x = e x − e − x e x + e − x \tanh x = \frac{{\sinh x}}{{\cosh x}} = \frac{{e^x - e^{ - x} }}{{e^x + e^{ - x} }} tanhx=coshxsinhx=ex+e−xex−e−x
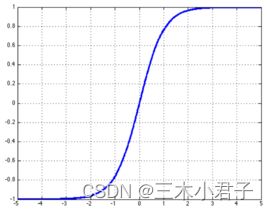
tanh函数在输入值大于2.5的时候,其输出接近1,在输入值小于-2.5的时候,其输出接近-1,输入的值会被压缩到(-1,1)之间。
特点:输出有正有负,且中心对称
2.3 ReLu函数
通常意义下,ReLu函数指代数学中的斜坡函数,即
f ( x ) = max ( 0 , x ) f(x) = \max (0,x) f(x)=max(0,x)
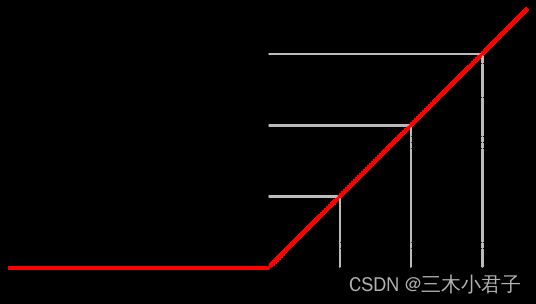
ReLu函数在输入值大于0的时候,其输出原值,在输入值小于0的时候,其输出为0
而在神经网络中,定义该神经元在线性变换之后的非线性输出结果。换言之,对于进入神经元的来自上一层神经网络的输入向量,使用ReLu激活函数的神经元会输出至下一层神经元或作为整个神经网络的输出(取决现神经元在网络结构中所处位置)。
max ( 0 , w T x + b ) \max (0,w^T x + b) max(0,wTx+b)
2.4 Leaky ReLu函数
在输入值为负的时候,Leaky ReLU的梯度为一个常数,而不是0。在输入值为正的时候,Leaky ReLU函数和普通斜坡函数保持一致。即 f ( x ) = { x i f x > 0 λ x i f x ≤ 0 f(x) = \left\{ \begin{array}{l} x~~~~~~~ifx > 0 \\ \\ \lambda x~~~~ifx \le 0 \\ \end{array} \right. f(x)=⎩⎨⎧x ifx>0λx ifx≤0
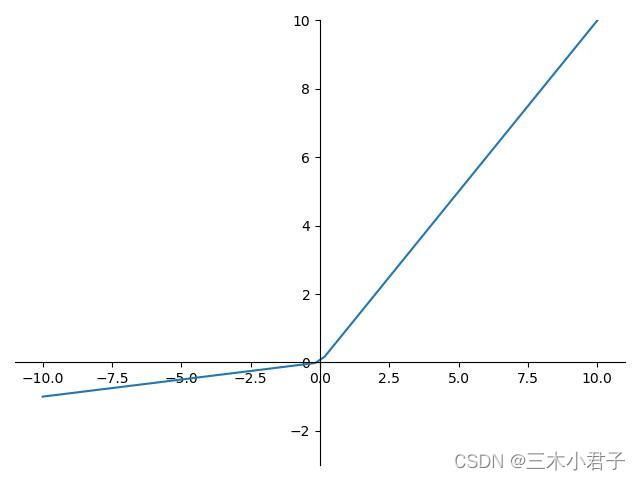
Leaky ReLu函数相较于ReLu函数,其在输入值小于0时,并不使输出值直接为0 ,而是把输入值缩小10倍。
3. 损失函数
损失函数(loss function)是用来评测模型的计算值 与真实值 的相似程度,损失函数越小,就代表模型的鲁棒性越好。当然其核心是对参数 和 进行优化,另外损失函数的选择需要具体问题具体分析,以下为几种常见损失函数计算公式。
◎L2损失函数: L ( y ′ , y ) = ∑ i = 1 n ( y i ′ − y i ) 2 L(y'^~,y) = \sum\limits_{i = 1}^n {(y' _i - y_i )^2 } L(y′ ,y)=i=1∑n(yi′−yi)2
◎均方差损失函数: { L ( y ′ , y ) = 1 2 n ∑ i = 1 n ( y i ′ − y i ) 2 多 样 本 L ( y ′ , y ) = 1 2 ( y i ′ − y i ) 2 单 样 本 \left\{ \begin{array}{l} L(y'^~ ,y) = \frac{1}{{2n}}\sum\limits_{i = 1}^n {(y' _i - y_i )^2 } ~~~~~多样本\\ \\ L(y'^~ ,y) = \frac{1}{2}(y' _i - y_i )^2 ~~~~~~~~~~~~单样本 \\ \end{array} \right. ⎩⎪⎪⎨⎪⎪⎧L(y′ ,y)=2n1i=1∑n(yi′−yi)2 多样本L(y′ ,y)=21(yi′−yi)2 单样本
◎交叉熵函数: L ( y ′ , y ) = [ y log y ′ + ( 1 − y ) log ( 1 − y ′ ) ] L(y'^~,y) = [y\log y'^ ~ + (1 -y)\log (1 - y')] L(y′ ,y)=[ylogy′ +(1−y)log(1−y′)]
上式中 y ′ y' y′是计算值, y y y是真实值
4.梯度下降
梯度下降是一种前反馈计算方法,反映的是一种“以误差来修正误差”的思想,亦是神经网络进行迭代更新的核心过程。
◎迭代更新 w 1 = w 0 − η d L ( w ) d w b 1 = b 0 − η d L ( b ) d b \begin{array}{l} w_1 = w_0 - \eta \frac{{dL(w)}}{{dw}} \\ \\ b_1 = b_0 - \eta \frac{{dL(b)}}{{db}} \\ \end{array} w1=w0−ηdwdL(w)b1=b0−ηdbdL(b)
其中 w 0 w_0 w0和 b 0 b_0 b0是我们目前的实际值, − η - \eta −η是步长(一定的值),当 L L L取极值 w w w时, w 1 w_1 w1是梯度下降求出的值
◎ 当对损失函数梯度下降时需要链式法则求解
d L ( a , y ) d w = d L ( a , y ) d a ⋅ d a d z ⋅ d z d w \frac{{dL(a,y)}}{{dw}} = \frac{{dL(a,y)}}{{da}} \cdot \frac{{da}}{{dz}} \cdot \frac{{dz}}{{dw}} dwdL(a,y)=dadL(a,y)⋅dzda⋅dwdz
以上是对单层神经网络的介绍,后续会不断更新完善~~~