数据分析-Pandas基础
关于数据分析
数据分析,宽泛地理解就是对海量数据进行处理、分析等操作,从数据中得到价值。选择这个方向,你可以往数据分析师、数据挖掘、数据产品经理等方向发展。
Pandas
1.Pandas核心数据结构
Pandas是基于NumPy 构建的含有更高级数据结构和分析能力的工具包。在 NumPy 中数据结构是围绕 ndarray 展开的;而Pandas中核心数据结构是Series和DataFrame。
- Series 是个定长的字典序列,有2个基础属性:index和Values。
import pandas as pd
from pandas import Series, DataFrame
x2 = Series(data=[1,2,3,4], index=['a', 'b', 'c', 'd'])
print (x2)
a 1
b 2
c 3
d 4
dtype: int64
- DataFrame类型数据结构类似数据库表,它包括了行索引和列索引,我们可以将 DataFrame 看成是由相同索引的 Series 组成的字典类型。
import pandas as pd
from pandas import Series, DataFrame
data = {'Chinese': [66, 95, 93, 90,80],'English': [65, 85, 92, 88, 90],'Math': [30, 98, 96, 77, 90]}
df1 = DataFrame(data, index=['zf', 'gy', 'zy', 'hz', 'dw'], columns=['English', 'Math', 'Chinese'])
print (df1)
English Math Chinese
zf 65 30 66
gy 85 98 95
zy 92 96 93
hz 88 77 90
dw 90 90 8
2.Pandas数据的导入导出
Pandas 允许直接从 xlsx,csv 等文件中导入数据,也可以输出到 xlsx, csv 等文件。
# 以excel为例,其它类似
import pandas as pd
df = pd.read_excel('C:/Users/zyf/Desktop/test.xlsx',index_col=0) # 读取导入
print(df)
df.loc['we','math']=12
print(df)
df.to_excel('C:/Users/zyf/Desktop/test1.xlsx') # 导出存储
chinese english math
姓名
zz 66 65 NaN
zf 95 85 32.0
we 95 34 56.0
chinese english math
姓名
zz 66 65 NaN
zf 95 85 32.0
we 95 34 12.0
index_col=0 就是告诉 Pandas,让它使用第一个 column(学号)的数据当做 row 索引
3.Pandas数据的常用操作
# 后续操作以此作为样例
import pandas as pd
import numpy as np
data = np.arange(-6, 6).reshape((4, 3))
df = pd.DataFrame(
data,
index=list("abcd"),
columns=list("ABC"))
print(df)
A B C
a -6 -5 -4
b -3 -2 -1
c 0 1 2
d 3 4 5
3.1 选列Column
df['B'] # 选一列
df[['B','C']] #多列
3.2 选行-loc函数
通过行索引 “Index” 中的具体值来取行数据(如取"Index"为"a"的行)
#loc函数是基于行标签和列标签进行索引的,其基本用法为:DataFrame.loc[行标签,列标签],如下
data[1:2,1:3] # numpy中选取数据
df.loc['b':'c','B':'C'] #DataFrame中使用loc函数选取数据
df.loc[['d', 'b'], :] #选取多行数据
array([[-2, -1]]) #numpy结果
B C #pandas结果
b -2 -1
c 1 2
上述两行代码,pandas为了贴近excel使用原则,得出的结果会包含’c’、'C’对应的数据,而numpy中则是不包含的。
3.3 iloc函数
通过行号来取行数据(如取第二行的数据)。iloc函数可以让我们直接用位置信息来筛选数据(类似numpy的思维)
# iloc函数是基于行和列的位置进行索引的,索引值从0开始,并且得到的结果不包括最后一个位置的值,其基本用法为DataFrame.iloc[行位置,列位置],如下:
data[1:2,1:3] #numpy方式
print(df.iloc[1:2,1:3]) # pandas中iloc函数
3.4 loc与iloc函数的混搭
比如现在需要取第1到第3位数据的A C两组数据,可以采用索引转换的方式
df.index和df.columns来调取到全部的标签,然后在用像 Numpy index 索引的方式把这些标签给筛选出来,放到.loc里面用
row_lables= df.index[1:3]
print(df.loc[row_lables,['A','C']])
col_labels = df.columns[[0, 2]]
print(df.loc[row_labels, col_labels]) # column的labels同理
A C
b -3 -1
c 0 2
- 通过
lable获取对应的index信息
col_index = df.columns.get_indexer(["A", "B"])
print(df.iloc[:2, col_index])
同理,df.index.get_indexer(["a", "b"]) 也可以这样获取到 label 对应的 index 信息。
3.5 条件筛选
df[df['A']<0] # 选取在A中小于0的数据
# 选在第一行数据不小于 -5 的数据
df.loc[:,df.iloc[0]>=-5] # 方式1:采用~,表示非什么
df.loc[:,~(df.iloc[0]<-5)] # 方式2:直接用 >=-5 来筛选
#用或 | 来表示 or 的意思, & 表述 and,选取选在第一行数据不小于 -4 或小于 -5 的数据
i0 = df.iloc[0]
df.loc[:, ~(i0 < -4) | (i0 < -5)]
Series和DataFrame类似,可以参考https://mofanpy.com/tutorials/data-manipulation/pandas/data-selection 后半部分
4.数据清洗
数据清洗一般是为了处理所采集数据的异常值,包括数据缺失、重复值、空行等,相当于数据预处理,使得数据标准、干净、连续,为后续数据分析、挖掘做好准备。
4.1 清洗空值
# 样例,本节以此作为例
import numpy as np
import pandas as pd
from pandas import Series, DataFrame
df = pd.read_csv('C:/Users/zyf/Desktop/property-data.csv')
print(df)
PID ST_NUM ST_NAME OWN_OCCUPIED NUM_BEDROOMS NUM_BATH SQ_FT
0 100001000.0 104.0 PUTNAM Y 3 1 1000
1 100002000.0 197.0 LEXINGTON N 3 1.5 --
2 100003000.0 NaN LEXINGTON N NaN 1 850
3 100004000.0 201.0 BERKELEY 12 1 NaN 700
4 NaN 203.0 BERKELEY Y 3 2 1600
5 100006000.0 207.0 BERKELEY Y NaN 1 800
6 100007000.0 NaN WASHINGTON NaN 2 HURLEY 950
7 100008000.0 213.0 TREMONT Y 1 1 NaN
8 100009000.0 215.0 TREMONT Y na 2 1800
- 查看空值
df.isnull() # 查询整个数据表含空值的情况
df['PID'].isnull() # 查询某个列含空值的情况
- 处理空值
(1)# dropna()函数:用于找到DataFrame类型数据的空值(缺失值),将空值所在的行/列删除后,将新的DataFrame作为返回值返回
new_df = df.dropna() #dropna() 方法返回一个新的 DataFrame,不会修改源数据
print(new_df)
df.dropna(inplace= True) # 使用 inplace = True 参数后,会直接修改原数据,并不会返回新的DataFrame
print(df)
(2)#subset参数:设置去重参照列
df.dropna(subset=['ST_NUM'], inplace = True) # 指定ST_NUM列进行空值删除
(3)# fillna()方法:替换空字段
df.fillna(12345, inplace = True) # 使用12345 全表替换
df['PID'].fillna(12345, inplace = True) # 使用12345 替换某一指定列的空值
print(df)
(4)#计算均值/中位数/众数 替换空值
x = df["ST_NUM"].mean() # 计算均值
x = df["ST_NUM"].median() # 计算中位数
x = df["ST_NUM"].mode() # 计算众数
df["ST_NUM"].fillna(x, inplace = True)
4.2 数据删除
df1 =df.drop(columns = ['PID']) # 删除指定列
df2 =df.drop(index = 0) # 删除指定行
4.3 清洗错误数据
主要是对错误数据进行替换修改
# 修改 第一行第一列数据为10086
df.loc[0,'PID'] = 10086 #采用loc函数,[行标签,列标签]定位数据
df.iloc[0,0] = 10086 # 采用iloc函数,[行索引值,列索引值]定位数据
print(df)
# 条件语句修改
for x in df.index:
if df.loc[x,'PID']>10086:
df.loc[x,'PID']=2022 # 修改数据
#df.drop(x,inplace =True) 删除数据
print(df)
4.4 删除重复数据
清洗重复数据,可以使用 duplicated() 和 drop_duplicates() 方法,如果对应的数据是重复的,duplicated() 会返回 True,否则返回 False。
df1 = df.duplicated() # 返回True Flase
df2 = df.drop_duplicates() # 返回删除后的新数据表
5.数据可视化
使用python进行数据可视化分析时,会用到较多可视化库,如Matplotlib、Seaborn等:
- Matplotlib 是 Python 的可视化基础库,作图风格和 MATLAB 类似;
- Seaborn 是一个基于 Matplotlib 的高级可视化效果库,针对 Matplotlib 做了更高级的封装,让作图变得更加容易
5.1 散点图
散点图(scatter plot),它将两个变量的值显示在二维坐标中,非常适合展示两个变量之间的关系
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns
# 数据准备
N = 1000
x = np.random.randn(N)
y = np.random.randn(N)
# 用Matplotlib画散点图
plt.scatter(x, y,marker='x') # x,y是数据坐标,marker代表标记符号,可选择不同标记,如“o”、“>”等
plt.show()
# 用Seaborn画散点图
df = pd.DataFrame({'x': x, 'y': y}) # Seaborn所传入的数据,一般为DataFrame类型
sns.jointplot(x="x", y="y", data=df, kind='scatter'); # kind=scatter,代表散点;也可以取其它值
plt.show()


5.2 折线图
折线图可以用来表示数据随着时间变化的趋势。在 Matplotlib 中,我们可以直接使用 plt.plot() 函数,当然需要提前把数据按照 x 轴的大小进行排序,要不画出来的折线图就无法按照 x 轴递增的顺序展示
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns
# 数据准备
x = [2010, 2011, 2012, 2013, 2014, 2015, 2016, 2017, 2018, 2019]
y = [5, 3, 6, 20, 17, 16, 19, 30, 32, 35]
# 使用Matplotlib画折线图
plt.plot(x, y)
plt.show()
# 使用Seaborn画折线图
df = pd.DataFrame({'x': x, 'y': y})
sns.lineplot(x="x", y="y", data=df)
plt.show()
# 两种方式效果图基本一致
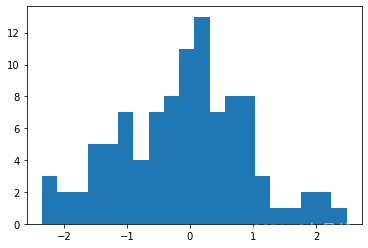
5.3 直方图
- Matplotlib 中,使用
plt.hist(x, bins=10)函数,其中参数x是一维数组,bins代表直方图中的箱子数量,默认是 10; - Seaborn 中,使用
sns.distplot(x, bins=10, kde=True)函数。其中参数x是一维数组,bins代表直方图中的箱子数量,kde代表显示核密度估计,默认是True,我们也可以把kde设置为False,不进行显示。核密度估计是通过核函数帮我们来估计概率密度的方法。
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns
# 数据准备
a = np.random.randn(100)
s = pd.Series(a)
# 用Matplotlib画直方图
plt.hist(s) # 输入数据需为一维数组;x轴表示数据,y轴表示数据频次
plt.show() #图1与图3一样
# 用Seaborn画直方图
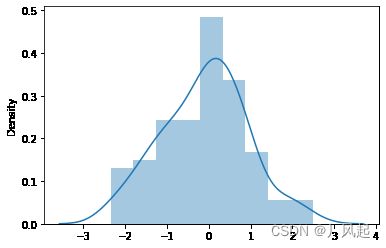
sns.distplot(s, kde=False)
plt.show() # 图3
sns.distplot(s, kde=True)
plt.show() # 图2
5.4 条形图
- Matplotlib 中,我们使用
plt.bar(x, height)函数,其中参数 x 代表 x 轴的位置序列,height 是 y 轴的数值序列,也就是柱子的高度; - Seaborn 中,我们使用
sns.barplot(x=None, y=None, data=None)函数。其中参数 data 为 DataFrame 类型,x、y 是 data 中的变量
import matplotlib.pyplot as plt
import seaborn as sns
# 数据准备
x = ['Cat1', 'Cat2', 'Cat3', 'Cat4', 'Cat5']
y = [5, 4, 8, 12, 7]
# 用Matplotlib画条形图
plt.bar(x, y)
plt.show()
# 用Seaborn画条形图
sns.barplot(x, y)
plt.show()
5.5 箱形图
箱线图,又称盒式图,由五个数值点组成:最大值 (max)、最小值 (min)、中位数 (median) 和上下四分位数 (Q3, Q1)。它可以帮我们分析出数据的差异性、离散程度和异常值等。
- Matplotlib 中,我们使用
plt.boxplot(x, labels=None)函数,其中参数 x 代表要绘制箱线图的数据,labels 是缺省值,可以为箱线图添加标签; - Seaborn 中,我们使用
sns.boxplot(x=None, y=None, data=None)函数。其中参数 data 为 DataFrame 类型,x、y 是 data 中的变量。
import numpy as np
import matplotlib.pyplot as plt
import seaborn as sns
import pandas as pd
# 数据准备
# 生成10*4维度数据
data=np.random.normal(size=(10,4)) # 生成0-1之间10*4维度的数据
labels = ['A','B','C','D']
# 用Matplotlib画箱线图
plt.boxplot(data,labels=labels)
plt.show()
# 用Seaborn画箱线图
df = pd.DataFrame(data, columns=labels)
sns.boxplot(data=df)
plt.show()


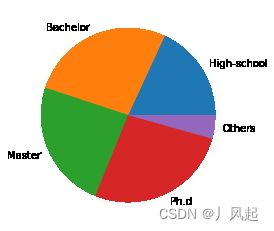
5.6 饼图
饼图常用于统计学模块,可以显示每个部分大小与总和之间的比例。主要采用Matplotlib 的 pie 函数实现它:plt.pie(x, labels=None) ,其中参数 x 代表要绘制饼图的数据,labels 是缺省值,可以为饼图添加标签。
import matplotlib.pyplot as plt
# 数据准备
nums = [25, 37, 33, 37, 6]
labels = ['High-school','Bachelor','Master','Ph.d', 'Others']
# 用Matplotlib画饼图
plt.pie(x = nums, labels=labels)
plt.show()
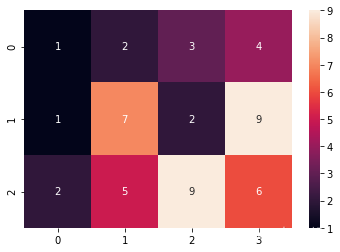
5.7 热力图
热力图(heat map)是一种矩阵表示方法,其中矩阵中的元素值用颜色来代表,不同的颜色代表不同大小的值。一般使用 Seaborn 中的 sns.heatmap(data) 函数,其中 data 代表需要绘制的热力图数据。
import matplotlib.pyplot as plt
import seaborn as sns
import numpy as np
# 数据准备
data = np.array([[1,2,3,4],[1,7,2,9],[2,5,9,6]])
# 用Seaborn画热力图
sns.heatmap(data,annot=True) # annot =True 会在格子上显示数字
plt.show()
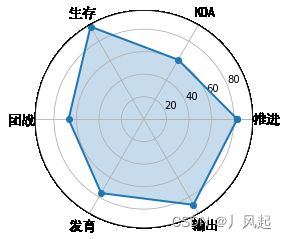
5.8 蜘蛛图
蜘蛛图是一种显示一对多关系的方法。在蜘蛛图中,一个变量相对于另一个变量的显著性是清晰可见的。
import numpy as np
import matplotlib.pyplot as plt
import seaborn as sns
from matplotlib.font_manager import FontProperties
# 数据准备
labels=np.array([u"推进","KDA",u"生存",u"团战",u"发育",u"输出"])
stats=[83, 61, 95, 67, 76, 88]
# 画图数据准备,角度、状态值
angles=np.linspace(0, 2*np.pi, len(labels), endpoint=False)
stats=np.concatenate((stats,[stats[0]]))
angles=np.concatenate((angles,[angles[0]]))
# 用Matplotlib画蜘蛛图
fig = plt.figure()
ax = fig.add_subplot(111, polar=True)
ax.plot(angles, stats, 'o-', linewidth=2)
ax.fill(angles, stats, alpha=0.25)
# 设置中文字体
font = FontProperties(fname=r"C:\Windows\Fonts\simhei.ttf", size=14)
ax.set_thetagrids(angles * 180/np.pi, labels, FontProperties=font)
plt.show()
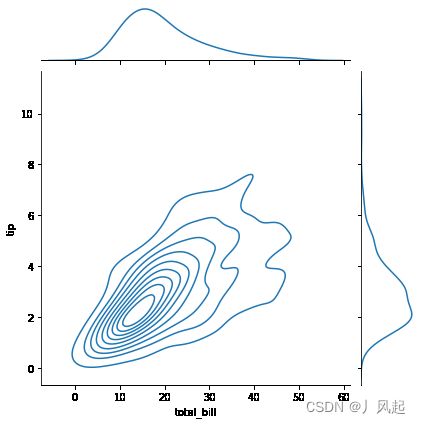
5.9 二元变量分布
主要用于展现两个变量之间的关系。在 Seaborn 里,使用二元变量分布是非常方便的,直接使用 sns.jointplot(x, y, data=None, kind) 函数即可。其中用 kind 表示不同的视图类型:“kind=‘scatter’”代表散点图,“kind=‘kde’”代表核密度图,“kind=‘hex’ ”代表 Hexbin 图,它代表的是直方图的二维模拟。
import matplotlib.pyplot as plt
import seaborn as sns
# 数据准备
tips = sns.load_dataset("tips") # Seaborn 自带数据集tips
print(tips.head(10))
# 用Seaborn画二元变量分布图(散点图scatter,核密度图kde,Hexbin图)
sns.jointplot(x="total_bill", y="tip", data=tips, kind='scatter') # kind可选择不同图
sns.jointplot(x="total_bill", y="tip", data=tips, kind='kde') # x , y取自数据表的2列
sns.jointplot(x="total_bill", y="tip", data=tips, kind='hex')
plt.show()


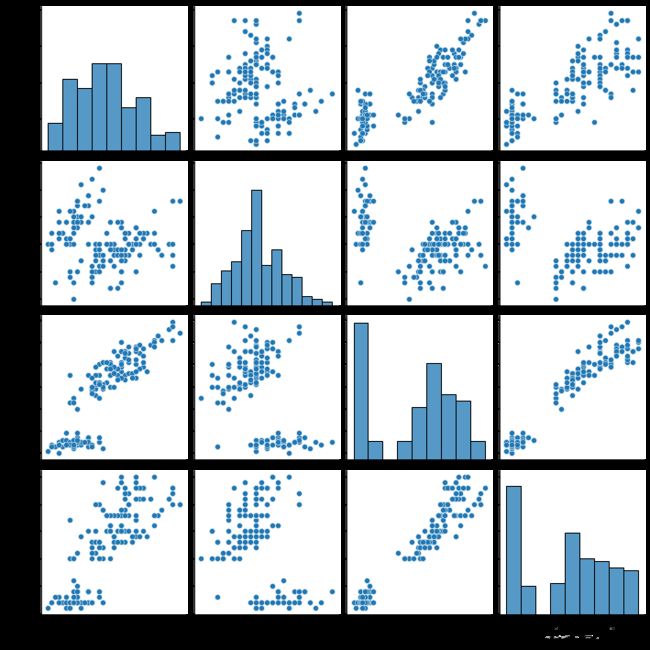
5.10 成对关系
数据集中的多个成对双变量的分布,可以直接采用 sns.pairplot() 函数。它会同时展示出 DataFrame 中每对变量的关系,另外在对角线上,你能看到每个变量自身作为单变量的分布情况。
使用 Seaborn 中自带的 iris 数据集,这个数据集也叫鸢尾花数据集。鸢尾花可以分成 Setosa、Versicolour 和 Virginica 三个品种,在这个数据集中,针对每一个品种,都有 50 个数据,每个数据中包括了 4 个属性,分别是花萼长度、花萼宽度、花瓣长度和花瓣宽度。通过这些数据,需要你来预测鸢尾花卉属于三个品种中的哪一种。
import matplotlib.pyplot as plt
import seaborn as sns
# 数据准备
iris = sns.load_dataset('iris')
print(iris.head(10))
# 用Seaborn画成对关系
sns.pairplot(iris)
plt.show()
sepal_length sepal_width petal_length petal_width species
0 5.1 3.5 1.4 0.2 setosa
1 4.9 3.0 1.4 0.2 setosa
2 4.7 3.2 1.3 0.2 setosa
3 4.6 3.1 1.5 0.2 setosa
4 5.0 3.6 1.4 0.2 setosa
6.常见数据分析算法
6.1决策树
决策树(decision tree):是一种基本的分类与回归方法。主要包含构造与剪枝两个阶段。
- 构造:构造的过程就是选择什么属性作为节点的过程;
- 剪枝:主要是为了防止过拟合现象的发生。
在构建决策树时,会基于纯度来构建;经典的”不纯度“指标有三种:信息增益(ID3 算法)、信息增益率(C4.5 算法)以及基尼指数(Cart 算法)。
6.1.1 信息增益(ID3算法)
信息增益指的就是划分可以带来纯度的提高,信息熵的下降。它的计算公式,是父亲节点的信息熵减去所有子节点的信息熵。在计算的过程中,我们会计算每个子节点的归一化信息熵,即按照每个子节点在父节点中出现的概率,来计算这些子节点的信息熵。
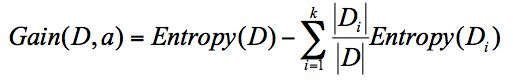
6.1.2 信息增益率(C4.5算法)
它是ID3的改进版本。主要包括4方面的改进:
- 采用信息增益率:ID3 在计算的时候,倾向于选择取值多的属性。为了避免这个问题,C4.5 采用信息增益率的方式来选择属性。信息增益率 = 信息增益 / 属性熵;
- 采用悲观剪枝:ID3 构造决策树的时候,容易产生过拟合的情况。在 C4.5 中,会在决策树构造之后采用悲观剪枝(PEP),这样可以提升决策树的泛化能力;
- 离散化处理连续属性;
- 处理缺失值

6.1.3 CART算法
classification and regression tree(分类回归树,CART),既可以用于分类也可以用于回归。
CART分类树与C4.5类似,只是属性选择的是基尼系数(GINI)。基尼系数本身反应了样本的不确定度。当基尼系数越小的时候,说明样本之间的差异性小,不确定程度低。
GINI系数公式:
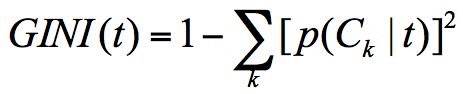

6.2 朴素贝叶斯
6.2.1 原理介绍
朴素贝叶斯是一种简单但强大的预测建模算法。之所以成为朴素贝叶斯,是因为它假设每个输入变量是独立的。
朴素贝叶斯模型由两种类型的概率组成:
(1)每个类别的概率P(Cj);
(2)每个属性的条件概率P(Ai|Cj)。
朴素贝叶斯分类于文本分类,尤其是对于英文等语言来说,分类效果很好。它常用于垃圾文本过滤、情感预测、推荐系统等
工程流程如下:


6.2.2 应用场景
朴素贝叶斯适合用于文本分类、情感分析、垃圾邮件识别,这些场景都是通过文本来进行判断的。
Sklearn机器学习包提供3个朴素贝叶斯分类算法:分别是高斯朴素贝叶斯(GaussianNB)、多项式朴素贝叶斯(MultinomialNB)和伯努利朴素贝叶斯(BernoulliNB)。
高斯朴素贝叶斯:特征变量是连续变量,符合高斯分布,比如说人的身高,物体的长度。
多项式朴素贝叶斯:特征变量是离散变量,符合多项分布,在文档分类中特征变量体现在一个单词出现的次数,或者是单词的 TF-IDF 值等。
伯努利朴素贝叶斯:特征变量是布尔变量,符合 0/1 分布,在文档分类中特征是单词是否出现。

6.3 支持向量机
SVM是一种有监督的学习模型,可用于模式识别、分类、回归分析。多用于文本分类尤其是二分类任务。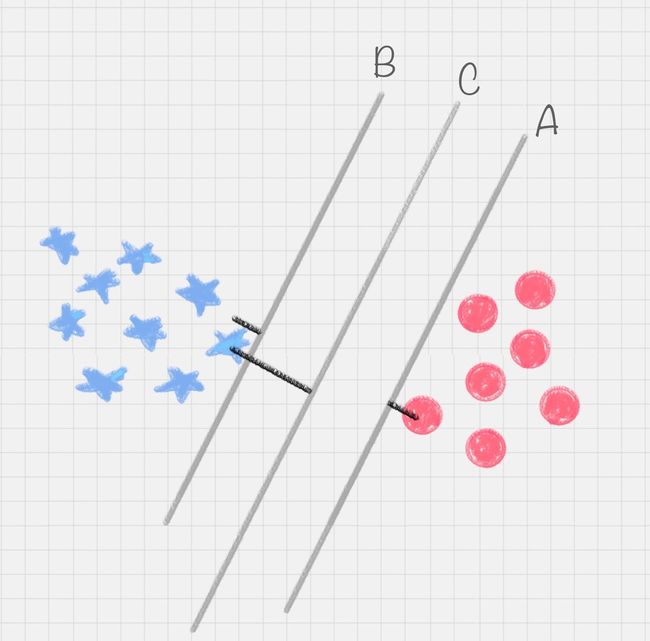
SVM 就是帮我们找到一个超平面,这个超平面能将不同的样本划分开,同时使得样本集中的点到这个分类超平面的最小距离(即分类间隔)最大化。
超平面表达式:

在这个公式里,w、x 是 n 维空间里的向量,其中 x 是函数变量;w 是法向量。法向量这里指的是垂直于平面的直线所表示的向量,它决定了超平面的方向。
支持向量就是离分类超平面最近的样本点,实际上如果确定了支持向量也就确定了这个超平面。所以支持向量决定了分类间隔到底是多少,而在最大间隔以外的样本点,其实对分类都没有意义。
SVM 就是求解最大分类间隔的过程:
首先,我们定义某类样本集到超平面的距离是这个样本集合内的样本到超平面的最短距离。我们用 di 代表点 xi 到超平面 wxi+b=0 的欧氏距离。因此我们要求 di 的最小值,用它来代表这个样本到超平面的最短距离。di 可以用公式计算得出:
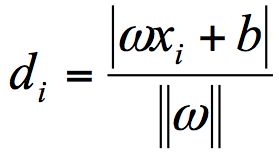
其中||w||为超平面的范数
不同SVM应用情况:
- 完全线性可分情况下的线性分类器,也就是线性可分的情况,用最原始的 SVM,它最核心的思想就是找到最大的分类间隔;
- 大部分线性可分情况下的线性分类器,引入了软间隔的概念。软间隔,就是允许一定量的样本分类错误;
- 线性不可分情况下的非线性分类器,引入了核函数。它让原有的样本空间通过核函数投射到了一个高维的空间中,从而变得线性可分。
6.4 KNN
k-Nearest Neighbor,其工作过程可分类三步:
1.计算待分类物体与其他物体之间的距离;
2.统计距离最近的 K 个邻居;
3.对于 K 个最近的邻居,它们属于哪个分类最多,待分类物体就属于哪一类
K值的选取:一般采用交叉验证的思路,即把样本集中的大部分样本作为训练集,剩余的小部分样本用于预测,来验证分类模型的准确性。所以在 KNN 算法中,我们一般会把 K 值选取在较小的范围内,同时在验证集上准确率最高的那一个最终确定作为 K 值。
距离的计算
两个样本点之间的距离代表了这两个样本之间的相似度。距离越大,差异性越大;距离越小,相似度越大。(以下是5种距离计算方法,前3种KNN常用)
欧氏距离;曼哈顿距离;闵可夫斯基距离;切比雪夫距离;余弦距离
6.5 K-means
K-Means 是一种非监督学习,解决的是聚类问题。K 代表的是 K 类,Means 代表的是中心,你可以理解这个算法的本质是确定 K 类的中心点,当你找到了这些中心点,也就完成了聚类。
K-means工作原理:
1.选取 K 个点作为初始的类中心点,这些点一般都是从数据集中随机抽取的;
2.将每个点分配到最近的类中心点,这样就形成了 K 个类,然后重新计算每个类的中心点;
3.重复第二步,直到类不发生变化,或者你也可以设置最大迭代次数,这样即使类中心点发生变化,但是只要达到最大迭代次数就会结束。
6.6 EM聚类
EM聚类,Expectation Maximization,也叫最大期望算法。

EM 算法是一种求解最大似然估计的方法,通过观测样本,来找出样本的模型参数。 EM 算法中的 E 步骤就是通过旧的参数来计算隐藏变量。然后在 M 步骤中,通过得到的隐藏变量的结果来重新估计参数。直到参数不再发生变化,得到我们想要的结果。
EM 算可以理解成为是一个框架,在这个框架中可以采用不同的模型来用 EM 进行求解。常用的 EM 聚类有 GMM 高斯混合模型和 HMM 隐马尔科夫模型。
6.7 关联规则挖掘
关联规则挖掘可以让我们从数据集中发现项与项(item 与 item)之间的关系,基于关联规则的Apriori 算法是关联规则挖掘中的重要算法。
关联规则中3个概念:
1.支持度:支持度是个百分比,它指的是某个商品组合出现的次数与总次数之间的比例(以购物为例)。支持度越高,代表这个组合出现的频率越大。
2.置信度:置信度是个条件概念,就是说在 A 发生的情况下,B 发生的概率是多少。
3.提升度:提升度 (A→B)= 置信度 (A→B)/ 支持度 (B)
Apriori 算法其实就是查找频繁项集 (frequent itemset) 的过程。
Apriori 算法的递归流程:
1.K=1,计算 K 项集的支持度;
2.筛选掉小于最小支持度的项集;
3.如果项集为空,则对应 K-1 项集的结果为最终结果。
4.否则 K=K+1,重复 1-3 步。
6.8 PageRank
PageRank是google搜索引擎的重要技术之一,旨在提高搜索结果得质量。多用于社交影响力评估的应用中,如微博、网站等

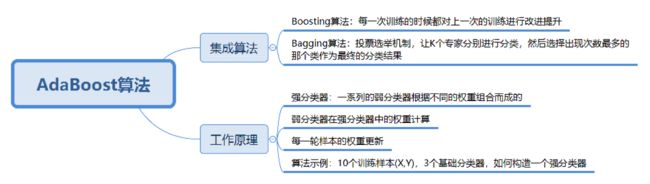
6.9 AdaBoost
AdaBoost与随机森林算法都属于分类算法中的集成算法。其基本原理就是:通过训练多个弱分类器,将它们组合成一个强分类器。如下:
通过训练不同的弱分类器,将这些弱分类器集成起来形成一个强分类器。在每一轮的训练中都会加入一个新的弱分类器,直到达到足够低的错误率或者达到指定的最大迭代次数为止。实际上每一次迭代都会引入一个新的弱分类器(这个分类器是每一次迭代中计算出来的,是新的分类器,不是事先准备好的)。