基于目标检测的海上舰船图像超分辨率研究
基于目标检测的海上舰船图像超分辨率研究
人工智能技术与咨询

来源:《 图像与信号处理》 ,作者张坤等
关键词: 目标检测;生成对抗网络;超分辨率
摘要: 针对海上舰船图像有效像素在整体像素中占比小的问题,提出一种基于目标检测网络的超分辨率方法。该方法包含两个阶段,结合bicubic变换,逐步地将图像的清晰度从粗到细地进行恢复。首先,第一阶段通过目标检测网络,检测出原图像中需要超分辨率的区域,然后,第二阶段将对应区域通过bicubic变换调整至指定分辨率,而后通过生成对抗网络增强图像细节。最终在自建数据集上的实验结果表明,与传统方法和现有基于深度神经网路的超分辨率重建算法相比,该算法不仅图像视觉效果最好,而且在数据集上的峰值信噪比(PSNR)平均提高了0.79 dB,结构相似性(SSIM)平均提高了0.04,证明了该算法的有效性。
1. 引言
近年来,图像超分辨率技术得到了长足的发展,结合比较有效的深度学习技术,该方法的精度已经得到了较大的提高,并已经广泛应用于各种领域,如视频监控、医学成像、高清晰度电视、遥感、手机与数码相机等 [1] [2]。本文算法的应用背景为提高海上远距离舰船目标图像的分辨率,主要应用于单幅海上舰船图像的超分辨率,该问题是一个不适定的逆问题,旨在从低分辨率(Low-Resolution, LR)图像中恢复出一个高分辨率(High-Resolution, HR)图像。如图1。

Figure 1. Marine ship image
图1. 海上舰船图像
目前传统超分辨率算法在运行时存在以下问题:1) 由于远距离舰船图像的像素在整体图像所占比例较少,大部分像素为用户并不关心的海浪天空等区域,因此在运行传统算法的时,大部分运算时间应用到了无关的区域,不符合使用者的使用意图,而且运行效率低下。2) 在应用深度学习技术的超分辨率算法中,如果对整张图像进行学习,则算法使用的卷积神经网络不能有效学习舰船目标的特征,而很有可能把海浪天空的特征误认为舰船的特征,从而无法有效对舰船图像进行重建。基于以上两点原因,本文提出一种基于目标检测网络的超分辨率算法。
2. 研究背景及现状
2.1. 目标检测算法
自从AlexNet在比赛中使用卷积神经网络进而大幅度提高了图像分类的准确率,便有学者尝试将深度学习应用到目标检测中。在这方面,主要有两种主流的算法:一类是结合region proposal、CNN网络的,基于分类的R-CNN系列目标检测框架(two stage);另一类则是将目标检测转换为回归问题的算法(single stage) [3]。虽然FasterRCNN算法是目前主流的目标检测算法之一,但是速度上并不能满足实时的要求。随后出现像YOLO,SDD这一类的算法逐渐凸显出其在速度上的优势。YOLO [4] 算法的网络设计策略延续了GoogleNet [5] 的核心思想,真正意义上实现了端到端的目标检测,且发挥了速度快的优势。YOLO采用以cell为中心的多尺度区域取代region proposal,舍弃了一些精确度以换取检测速度的大幅提升,检测速度可以达到45 f/s,足以满足实时要求。
2.2. 超分辨率算法
传统的SISR的方法包括基于插值的算法,基于凸集投影法的算法等,但由于深度学习在计算机视觉领域的突破性进展,人们尝试在超分辨率问题中引入深度神经网络,通过构建深层次的网络进行端到端的训练来解决图像超分辨率重建问题 [6]。SRCNN (super-resolution convolutional neural network) [7] 是最早运用深度学习方法在LR与HR之间建立端到端映射的SISR模型,其输入图像采用了插值预处理的方法。Ledig等人 [8] 基于GAN提出了一种用于图像超分辨率的生成对抗网络SRGAN,通过生成式和判别器的交替执行,充分提取高频信息。由于海上舰船图片成对采集,因此适用于使用建立像素到像素映射关系的超分辨率算法 [9],论文借鉴pix2pix [10] 的算法设计。
3. 基于目标检测网络的超分辨率重建模型
本文所设计的模型是一种基于目标检测算法的模型,目的在于检测出整幅中用户感兴趣的区域,而后再对指定区域进行超分辨率放大,从而减少算法运行的时间,并更好的重建目标区域图像的边缘和纹理,本文的方法由两阶段组成,如图2所示。

Figure 2. Model structure
图2. 模型结构
X为原图, X′X′ 为X的退化图像,Y为X中用户感兴趣的区域,x为 中用户感兴趣的区域,y为生成网络生成的图像。T为目标检测网络,用于获取X中的(x, y, h, w, confidence)信息,G为图像生成网络,D为鉴别网络。
3.1. 目标检测卷积神经网络结构设计
目标检测网络T的结构设计借鉴了yoloV3中Darknet-53的神经网络设计,其候选框基于anchor候选框机制,其原理图如图3:
网络实际的预测值为,tx、ty、tw、bh根据上图中的四个公式计算得到预测框的中心点坐标和宽高bx,by,bw,bh。其中cx、cy为当前grid相对于左上角grid偏移的grid数量。
图3所示σ(t)函数为logistic函数,将坐标归一化到0~1之间。最终得到的bx,by为归一化后的相对于gridcell的值。pw,ph与groundtruth重合度最大的anchor框的宽和高。实际在使用中,将bw,bh也归一化到0~1,实际程序中的pw,ph为anchor的宽,高和feature map的宽,高的比值。最终得到的bw,bh为归一化后相对于anchor的值。

Figure 3. Anchor Candidate Box
图3. Anchor候选框
卷积神经网络结构如图4:
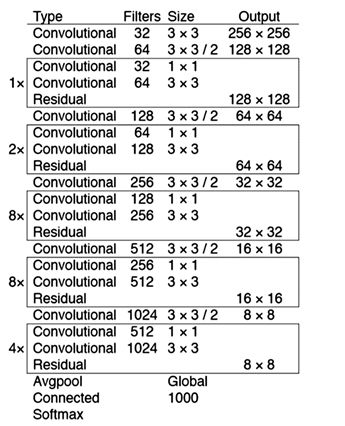
Figure 4. Convolutional neural network architecture
图4. 卷积神经网络结构
该网络的特点在于使用了连续的3 × 3和1 × 1的卷积基层,简化了resnet神经网络,减少了检测时间。
在yoloV3损失函数中,需要关注4个信息,分别为位置信息:(x, y),选中框的长宽:(w, h),识别的置信度:confidence,识别出物体的类别:class。由于在舰船的超分辨率任务中,识别的目标只有舰船一类,所以为了简化算法,提高运算速度,本文算法只是用前三项作为算式函数内容,因此的到如下公式:

其中 λcoordλcoord 为位置错误的权重, λnoobjλnoobj 为没有object的候选框的置信度权值, λobjλobj 为有object的候选框的置信度权值, 1objij1ijobj 判断第i个栅格中的第j个候选框是否包含物体,判断是否有物体的中心落在i中, xi,yixi,yi 为实际的坐标值, xˆi,yˆix^i,y^i 为预测的坐标值, wi,hiwi,hi 为实际候选框的宽和高, wˆi,hˆiw^i,h^i 为预测候选框的宽和高, CiCi 为实际的类别,为预测的类别。
3.2. 图像生成卷积神经网络结构设计
图像生成网络G的设计为U-Net结构,U-Net [11] 是德国Freiburg大学模式识别和图像处理组提出的一种全卷积结构。和常见的先降采样到低维度,再升采样到原始分辨率的编解码(Encoder-Decoder)结构的网络相比,U-Net的区别是加入skip-connection,对应的featuremaps和decode之后的同样大小的featuremaps按通道拼(concatenate)一起,用来保留不同分辨率下像素级的细节信息,U-Net对提升细节的效果非常明显。
3.3. 图像判别卷积神经网络结构设计
图像判别网络G为PatchGAN [12],该网络不是以整个图像的作为输入,而是以小的patch来进行的。把一副图像划分为N × N个patch后,对于每一块进行上述的那个操作。可以发现当N = 1的时候,相当于逐像素进行了,当N = 256 (图像大小为256的话),就是一幅图像的操作。最后将一张图片所有patch的结果取平均作为最终的判别器输出。实验发现当N = 70的时候,效果最好 [10]。
3.4. 超分辨网络的目标函数
构建好生成网络和判别网络结构后,设定目标函数。生成器G不断的尝试最小化下面的目标函数,而D则通过不断的迭代去最大化这个目标函数。目标函数分为两个部分,第一部分为生成对抗网络的损失函数,公式为:

4. 实验结果与分析
由于目前并没有针对舰船的图片数据集,本文实验使用项目自行采集的数据集作为训练集,该数据集由实际采集的舰船照片和网络爬取的舰船照片组成。其中实际采集的舰船照片为同一目标不同分辨率的图像,经测算高分辨率图像经双线性差值与高斯模糊函数相叠加的方式作为退化函数能有效的模拟低分辨率图像,而后将此退化函数应用到采集的舰船照片上,得到本文使用的数据集。舰船图像的原始像素大小的256 × 256,经退化函数处理得到不同分辨率的低分辨率图像。在4倍缩小尺度下,低分辨率图像像素为128 × 128,在9倍缩小尺度下,低分辨率图像像素为85 × 85,在16倍缩小尺度下,低分辨率图像像素为64 × 64。一张高分辨舰船图像和一张对应的低分辨率图像为一组图像。数据集分为训练图像、验证图像和测试图像三个子集,其中训练图像包含3000组图像,验证图像包含50组图像,测试图像包含50组图像。
本文实验通过Adam优化方法对网络进行训练。利用“步长”(step)策略调整学习率,初始学习率权重为2e−5,指数衰减率为0.999,调整系数gamma为0.5,最大迭代次数为10000。训练网络用机器配置为:i7-7700,16G内存,GTX1070Ti8G。
本文所提出的算法与现有的5种超分辨率的方法相比较,分别为bilinear,bicubic [13],discogan [14],pix2pix [10],pocs [15]。由于本文使用的算法只对选定的图像位置进行超分比率,因此进行图像质量评价时为保证评价的公平性,也仅对选定区域进行比较评价。利用本文算法得到的位置信息,对各类算法得的图像进行截取,而后利用峰值信噪比(PSNR)和结构相似度(Structual Similarity, SSIM)对截取的原图像和生成图像进行比较,得到重建图像的评价值,比较×4,×9,×16不同尺度下的效果,结果如表1所示。
| 算法 |
重建倍数 |
Psnr |
Ssim |
Time (ms) |
| Yolo2pix |
×4 |
24.549 |
0.791 |
77.8 |
| discogan |
23.401 |
0.724 |
13.2 |
|
| pix2pix |
23.891 |
0.731 |
12.9 |
|
| pocs |
18.948 |
0.631 |
2034 |
|
| bilinear |
23.266 |
0.752 |
8.8 |
|
| bicubic |
23.864 |
0.777 |
13.6 |
|
| Yolo2pix |
×9 |
22.791 |
0.715 |
78.2 |
| discogan |
22.031 |
0.647 |
13.3 |
|
| pix2pix |
22.154 |
0.652 |
13.1 |
|
| pocs |
17.549 |
0.581 |
2154 |
|
| bilinear |
21.815 |
0.682 |
8.8 |
|
| bicubic |
22.148 |
0.699 |
14.8 |
|
| Yolo2pix |
×16 |
21.746 |
0.675 |
78.3 |
| discogan |
21.050 |
0.627 |
13.3 |
|
| pix2pix |
21.047 |
0.636 |
13.2 |
|
| pocs |
16.758 |
0.532 |
2253 |
|
| bilinear |
20.958 |
0.629 |
9.6 |
|
| bicubic |
21.241 |
0.645 |
15.2 |
Table 1. Test results on datasets using different super-resolution methods
表1. 使用不同超分辨率方法在数据集上的测试结果
从表1中可以看出本文算法在测试集上的PSNR,SSIM超过了其他超分辨率方法,但是相比于传统算法有一步选定区域的运算,因此相比于其他超分辨率算法,运行时间稍长。但这种劣势会随着舰船在所述图像中所占像素的减小而抵消。
为了直观的比较成像效果,将本算法的生成图像和其他算法生成的图像排列对比,实验结果如图5、图6、图7所示。

Figure 5. Comparison of results of different super-resolution methods at 4-fold scaling ratio
图5. 4倍缩放比率下不同超分辨率方法的结果比对

Figure 6. Comparison of results of different super-resolution methods at 9-fold scaling ratio
图6. 9倍缩放比率下不同超分辨率方法的结果比对

Figure 7. Comparison of results of different super-resolution methods at 16-fold scaling ratio
图7. 16倍缩放比率下不同超分辨率方法的结果比对
从数据上看,排除效果较差的凸集投影(pocs)算法,本文算法相比于其他算法,在重建倍数4下,PSNR最少提高0.658 dB,平均提高0.94 dB,SSIM最少提高0.014,平均提高0.045。在重建倍数9下,PSNR最少提高0.637 dB,平均提高0.75 dB,SSIM最少提高0.016,平均提高0.045。在重建倍数16下,PSNR最少提高0.505 dB,平均提高0.67 dB,SSIM最少提高0.03,平均提高0.04。总体来说,在数据集上的峰值信噪比(PSNR)平均提高了0.79 dB,结构相似性(SSIM)平均提高了0.04。人工观察效果来看,本文方法的整体视觉效果更好,在重建倍数4下,本文算法恢复了更多的船艇结构细节,其船体部分棱角更加分明,在重建倍数16下,船体上部分窗户细节恢复的比较真实。但是船体的侧面细节纹理没有有效重建。
5. 结语
本文提出基于目标检测网络的图像超分辨率重建方法,该方法首先框选出需要超分辨率的区域,而后对选定区域使用基于GAN的超分辨率算法,从而达到提升图像清晰度的目的。第一阶段利用Darknet-53网络快速检测目标,获得目标的位置尺寸和置信度信息。第二阶段利用生成对抗模型,利用U-Net结构和PatchGAN构建了端对端的超分辨率模型。结合自建舰船数据库,让网络更有针对性的学习舰船结构特征,从而从低分辨率图像中恢复出拥有更多纹理信息的高分辨率图像。本文方法与其他超分辨率算法相比,不论是在主观重建效果还是客观评价标准上都有所提高的,且重建出的图像具有更高的质量并显示更精细的细节。在实际应用中,一幅画面中可能出现不止一艘船艇,本文使用的Darknet-53网络对图像不同部分一次性给出全部置信度参数,可以一次检测多艘船艇,因此本文算法可以满足实际使用的需求,但在检测小目标时算法效果有待考证,此为下一步研究方向。

我们的服务类型
公开课程
人工智能、大数据、嵌入式
内训课程
普通内训、定制内训
项目咨询
技术路线设计、算法设计与实现(图像处理、自然语言处理、语音识别)

