例题讲解拉格朗日乘子法、线性可分支持向量机(SVM)的推导
支持向量机(Support Vector Machine, SVM)于1995年被首次提出,在解决小样本、非线性及高维度模式识别模式中具有许多特有的优势。
1、SVM的相关概念
在介绍SVM之前需要了解一些相关概念。
最优分类超平面:分类超平面方程中的参数有无穷多解,但最优分类超平面仅有一个,且应同时具备以下两个条件:(1)最近距离最远,距离超平面最近的样本到该超平面的间隔应尽可能得远;(2)等距:距离超平面最近的两类样本到超平面的距离应是相等的。
如下图二维空间中的样本,共有蓝色和橙色两种类别。很明显,该数据集是线性可分的,即存在分类超平面(直线)将两类样本分来,但最优分类超平面只有一个,下图中红色实现对应的为最优分类(二维)超平面。

支持向量:'支持'代表的是边界支持,离最优分类超平面最近且平行于最优分类超平面的向量就叫做支持向量,可以看作“支持向量撑起了分类超平面”,故而求解支持向量和最优分类超平面的算法叫做支持向量机。
2、拉格朗日乘子法
求解支持向量的时候需要用到拉格朗日乘子法,此处先简单介绍一下拉格朗日乘子法的概念及作用。
拉格朗日乘子法的基本原理是通过引入拉格朗日乘子(λ)将原来的约束优化问题转化为无约束的方程组问题。
拉格朗日乘子法的求解过程大致分为以下步骤:
1、原问题描述:求解函数z=f(x, y)在条件φ(x, y)=0条件下的极值。
2、构造函数:F(x, y, λ) = f(x, y) + λ · φ(x, y), 其中λ为拉格朗日乘子。
3、构造函数求偏导,列出方程组。

4、求出x, y, λ的值, 代入即可得到目标函数的极值。
【例】求已知目标函数f(x, y) = x² + y², 在约束条件 xy=3 条件下的极小值。
构造函数为f(x, y, λ) = x² + y² + λ · (xy - 3),
求偏导可得方程组:
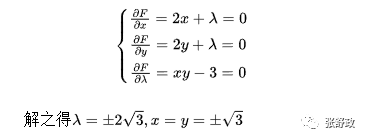
所以目标函数f(x, y)的极小值为6。
2、线性可分SVM的原理
2.1 分类决策函数
接下来会用原理和例题分别推导线性可分SVM,圆形图案⚪后面的为原理部分,三角形图案▲后面的为实例部分,
当训练样本线性可分时,对应的SVM为线性可分SVM。SVM通过求支持向量到分类超平面的最大距离来确定最优分类超平面,这是一个优化问题。我们以二维空间的线性可分二分类问题为例,推导最优超平面H。
⚪原始问题如下

▲例题中,如下图共有三个点,正例有(3,3),(4,3)两点,负例有(1,1)点。我们的目标为找到一条最优分割直线将正负例正确分类。
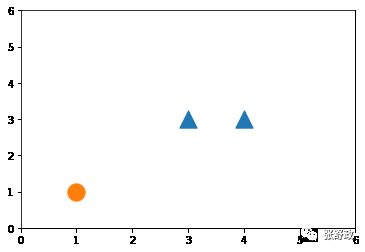
⚪在二维空间中,最优分类超平面H是一条直线,其对应的公式为wx+b=0。

2.2 分类间隔决策函数
▲在我们的例题中。如下图,红色直线代表的即为超平面H,蓝色和黄色虚线分别满足wx+b=1和wx+b=-1。最优超平面到两支持向量的距离最短且相等,y(wx+b)≥1的两侧全部为正/负例样本。
⚪将平行于H且最近的两个不同类的点即支持向量设为xi和xj,分别满足:

d及θ的关系如下图所示:
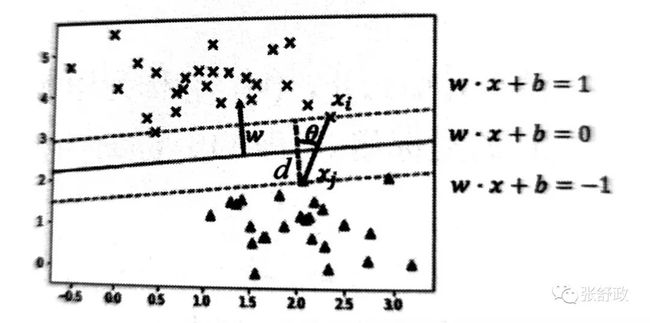
▲在我们的例题中,d以及θ的关系和上图完全相同,即我们要求解的分类间隔d=2 / ||w||。
2.3 SVM的目标函数
SVM的目标是求出最优分类超平面H,找到支持向量对分类间隔最大化。
⚪目标函数为求解分类间隔d的最大值,所以目标函数及约束条件为:

求解满足上式的w和b是我们的目标,因为目标函数有二次项,所以以上问题可看作一个凸二次规划问题,可以通过拉格朗日乘子法求解,转换后函数如下:

拉格朗日乘子法部分的推导可参照拉格朗日函数为什么要先最大化? - 知乎 (zhihu.com)。
▲在我们的例题中,w为所求最优分割超平面即红色直线的法向量。
例题中共有三个点分别为正例(3,3),正例(4,3)和负例(1,1),设w1和w2分别为向量w的两个分量,最初的目标函数及约束函数为:
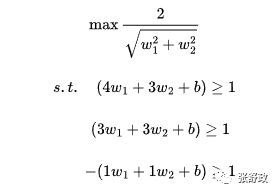
将极大化问题变为极小化问题后,原问题转换为:
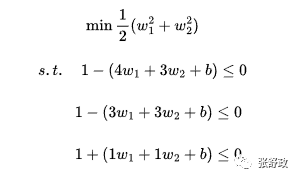
添加拉格朗日乘子α,构造无约束的拉格朗日函数为

转化为“极大极小”问题,如下:
![]()
2.4 对偶问题求解
2.4.1求minL
⚪接下来对对偶问题进行求解,先求解min L(x, y, α):

经过该步骤,所得的L(x,y,α)函数已经没有了变量w和b,只剩拉格朗日乘子α。
▲在我们的例题中,x1=(4,3), y1=1;x2=(3,3), y2=1,; x3=(1,1),y3=-1。
直接将值代入化简完成的公式中如下

经过该步骤,所得的L(x,y,α)函数已经没有了变量w和b,只剩拉格朗日乘子α。
2.4.2求maxL对应的拉格朗日乘子α
⚪接下来对对偶问题进行求解对α的极大,即“最大最小”问题的外侧:

第一条约束是因为α作为拉格朗日乘子必须满足非负性,第二条约束则是之前推导的,L函数对b的偏导=0。此时αi与训练样本(xi, yi)对应,可以利用启发式方法——序列最小优化(SMO)算法来求解拉格朗日乘子α,详细的SMO方法会在之后的文章中讲解。
上述过程满足KKT条件,即要求:

此处的f(x)即为我们最后要求的分类决策函数,当为正类时f(x)>0,为负类时f(x)<0,正类的支持向量和负类的支持向量对应的f(x)=±1,如下图所示。
求出所有的拉格朗日乘子αi后,就可以计算最优分类超平面H的参数w和b。
▲在我们的例题中,我们直接用SMO方法求出了α1=0, α2=α3=1。
2.4.3 求参数w和b
⚪依据前面部分的推导,可以直接根据下面的公式求出w:

依据以下公式求出b

此时根据w和b的公式可知,w和b的值依赖于ai>0即支持向量点,非支持向量点ai=0,对w和b取值无影响。
将w和b代入最优分类超平面H的公式wx+b=0中,可求出最优分类超平面。
▲在我们的例题中,w=0 + 1*1*(3,3) + 1*(-1)*(1,1)=(2,2)归一化后=(0.5, 0.5)
选择x3,b =yi - xi w = -1-(1,1)·(0.5,0.5)=-2
分割超平面wx+b=0即为0.5x+0.5y-2=0,即直线y=x-4。与我们目测的最优超平面完全相同。
根据最后的分割超平面对应的公式可知,所有拉格朗日乘子αi=0的向量xi均对最后的f(x)没有影响。因此当训练完后,对于f(x)可以仅仅保留支持向量。