GAN阅读论文笔记
RelGAN学习笔记
- Abstract
- Introduction
-
- challenge
- RelGAN( Relational GAN)
- Model——RelGAN
-
- relational memery based generator
- gumbel softmax relation
- <1> gumbel-Max trick (argmax操作还是不可导的)
- <2> gumbel softmax
- <3> temperature control
- <4>mutiple representation in discriminator
- pre-train
- experiment
-
- 1 synthetic data
- 2 COCO image captions dataset
- 3 EMNLP2017 WMT NEWS DATASET
- ABLATION STUDY
-
- 1 IMPACT OF RELATIONAL MEMORY and IMPACT OF GUMBEL-SOFTMAX RELAXATION
- 2 IMPACT OF MULTIPLE REPRESENTATIONS IN DISCRIMINATOR
作者开源代码https://github.com/weilinie/RelGAN

Abstract
GAN在生成真实图片的已经取得了很大的成功,但在应用于文本生成领域仍然有很多挑战。在这个工作中,作者提出了一个新的GAN结构——RelGAN用于文本生成,在生成的文本的质量和多样性方面皆优于现有方法。模型主要由3个部分组成:1、a relational memory based generator ——便于长期依赖建模
2、Gumbel-Softmax relaxation ——为了能够处理用离散数据训练GAN
3、 multiple embedded representations in the discriminator——为生成器更新提供更多的信息信号
Introduction
扩展GAN的应用用于生成离散数据(如:文本生成)
challenge
- 关于离散数据生成的不可导问题(解决方法:RL、Gummel softmax);
- GAN训练的不稳定性以及模式崩塌,包括:
训练不稳定
<1> 对随机参数初始化以及超参的设置相当敏感
<2> 将RL用于GAN来处理离散数据生成的不可导问题会让GAN的训练难上加难
模式崩塌
<1>生成的文本往往缺乏多样性,尤其是生成长文本时(可能因为生成器G缺乏表达能力——无法覆盖数据分布中的许多更复杂的模式 or 判别器D缺乏足够的指导信号——将生成器更新限制在某些模式内 )
RelGAN( Relational GAN)

Model——RelGAN
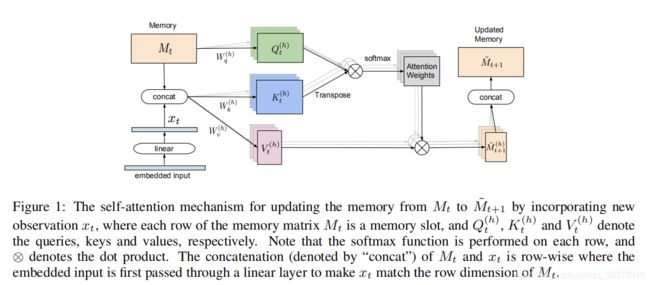
relational memery based generator
当前主要将GAN用于文本生成是通过用LSTM来建模生成器G,然而这将导致GAN的一些瓶颈。
<1> 判别器的loss值在经过几次对抗训练之后就会快速收敛,这意味着判别器的能力要比生成器强,并且能够轻易的分出真样例和假样例。
<2> GAN中的模式崩溃也可能部分表明生成器的无能,因为它的表达能力可能不足以适应所有的数据分布模式
<3> 当前的GAN在长句生成方面表现不佳,可能是因为LSTM将所有关于历史文本序列的信息打包成一个隐向量,限制了G对长距离依赖建模的能力。
因此作者提出使用relation memery来建模G(一组固定的内存插槽(例如。 内存矩阵),并使用multi heads自注意机制在内存插槽之间进行交互)


gumbel softmax relation
关于离散数据不可导问题:给定单词表V,对于上述式(2)中G的输出ot, t+1时刻生成的one hot token是从多项式分布softmax(ot)中采样出来的,这个步骤是不可导的。

gumbel softmax relation
gumbel distribution 以及gumbel softmax 的相关知识可以参考以下几篇:
Gumbel-Softmax Trick和Gumbel分布
【一文学会】Gumbel-Softmax的采样技巧
<1> gumbel-Max trick (argmax操作还是不可导的)

<2> gumbel softmax

<3> temperature control
当 β → ∞ \beta\rightarrow\infty β→∞时, y ^ t + 1 → \hat{y}_{t+1}\rightarrow y^t+1→ y t + 1 y_{t+1} yt+1,然而此时的梯度方差会很大,因为 V a r ( ∂ y ^ t + 1 ∂ y t + 1 ) ∝ β 2 Var(\frac {\partial \hat{y}_{t+1}}{\partial y_{t+1}})\propto\beta^{2} Var(∂yt+1∂y^t+1)∝β2,此时参数更新将会对输入的噪音相当敏感,将导致所生成的样本质量变差。
当 β → \beta\rightarrow β→ 0 0 0 时,生成器将会更注重于 y ^ t + 1 \hat{y}_{t+1} y^t+1的分布,因为此时 y ^ t + 1 \hat{y}_{t+1} y^t+1与 y t + 1 y_{t+1} yt+1间存在较大的近似间隙,阻碍生成器的探索。
因此更大的 β \beta β值会鼓励探索以获得更好的采样多样性,较小的 β \beta β值会更注重于利用 y ^ t + 1 \hat{y}_{t+1} y^t+1的分布以获得更好的采样质量。在训练中我们用指数策略在迭代中逐步提升逆温度 β \beta β的值: β n = β m a x n / N \beta_{n}=\beta_{max}^{n/N} βn=βmaxn/N,其中 β m a x \beta_{max} βmax为逆温度的最大值, N N N为 训练的最大迭代次数( i t e r a t i o n s iterations iterations), n n n为当前迭代次数。在指数策略中,由于你温度 β \beta β的增长率取决于 β m a x \beta_{max} βmax, β m a x \beta_{max} βmax决定了从开采阶段到勘探阶段的过渡时间。
RelGAN通过这种灵活的训练方式获得更好的采样多样性和采样质量,这是以往的GAN方式所达不到的。
<4>mutiple representation in discriminator
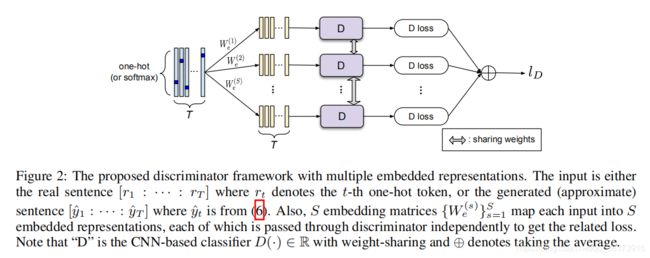
常见的文本生成鉴别器是一个基于CNN的分类器,这个基于CNN的分类器的输入是由单个嵌入矩阵 X ∈ R d ∗ T X\in\R^{d*T} X∈Rd∗T表示的长度为 T T T的句子, x t ∈ R d x_{t}\in\R^{d} xt∈Rd是每个单词的D维嵌入向量。
在此工作中,作者提出了一个新的鉴别器框架,它对每个句子应用多个嵌入表示。每种表示独立的通过上述基于CNN的分类器来获得一个独立的score, 这些单个分数的平均值将作为更新生成器的最终指导信息。(此想法假设:每种嵌入表示可以捕获输入句子的一个特定方面的特征,并且从这些不同角度来区分real 和 fake data的判别器可以为生成器更新提供更多样化和更全面的指导信息)——想法来源于 *Generative multi-adversarial networks. arXiv preprint arXiv:1611.01673, 2016.*使用多个鉴别器来改进图像生成的GAN。但区别是本文作者只使用不同的嵌入表示,但用于捕捉不同方面的基于CNN的判别器是共享参数的,可减少计算成本。
real token (onehot): [ r 1 : ⋯ : r T ] ∈ R V ∗ T \begin{bmatrix} r_{1}&:&\cdots&:& r_{T}\end{bmatrix}\in\R^{V*T} [r1:⋯:rT]∈RV∗T
generated token (onehot or softmax-like): [ y ^ 1 : ⋯ : y ^ T ] ∈ R V ∗ T \begin{bmatrix} \hat{y}_{1}&:&\cdots&:& \hat{y}_{T}\end{bmatrix}\in\R^{V*T} [y^1:⋯:y^T]∈RV∗T
S S S embedded representations (mapping):
{ W e ( s ) } s = 1 S \begin{Bmatrix} W_{e}^{\begin{pmatrix} s \end{pmatrix}} \end{Bmatrix}_{s=1}^{S} {We(s)}s=1S with W e ( s ) ∈ R d ∗ V W_{e}^{\begin{pmatrix} s \end{pmatrix}}\in\R^{d*V} We(s)∈Rd∗V
the s s s-th embedded representation of the real:
X ~ r ( s ) = W e ( s ) [ r 1 : ⋯ : r T ] \tilde{X}_{r}^{\begin{pmatrix} s \end{pmatrix}}=W_{e}^{\begin{pmatrix} s \end{pmatrix}}\begin{bmatrix} r_{1}&:&\cdots&:& r_{T}\end{bmatrix} X~r(s)=We(s)[r1:⋯:rT]
the s s s-th embedded representation of the generated:
X ~ y ( s ) = W e ( s ) [ y ^ 1 : ⋯ : y ^ T ] \tilde{X}_{y}^{\begin{pmatrix} s \end{pmatrix}}=W_{e}^{\begin{pmatrix} s \end{pmatrix}}\begin{bmatrix} \hat{y}_{1}&:&\cdots&:& \hat{y}_{T}\end{bmatrix} X~y(s)=We(s)[y^1:⋯:y^T]
loss function:
l D = 1 S ∑ s = 1 S E r 1 : T ∈ P r y ^ 1 : T ∈ P θ l o g s i g m o i d ( D ( X ~ r ( s ) ) − D ( X ~ y ( s ) ) ) l_{D}=\frac{1}{S}\sum_{s=1}^S\mathbb{E}_{\begin{matrix} r_{1:T}\in P_{r} \\ \hat{y}_{1:T}\in P_{\theta} \end{matrix}}logsigmoid(D(\tilde{X}_{r}^{\begin{pmatrix} s \end{pmatrix}})-D(\tilde{X}_{y}^{\begin{pmatrix} s \end{pmatrix}})) lD=S1∑s=1SEr1:T∈Pry^1:T∈Pθlogsigmoid(D(X~r(s))−D(X~y(s)))
l G = − l D l_{G}=-l_{D} lG=−lD
pre-train
只需要用标准的MLE 对G简单的训练几轮,而不需要预训练D。预训练结束后再进行对抗训练。
experiment
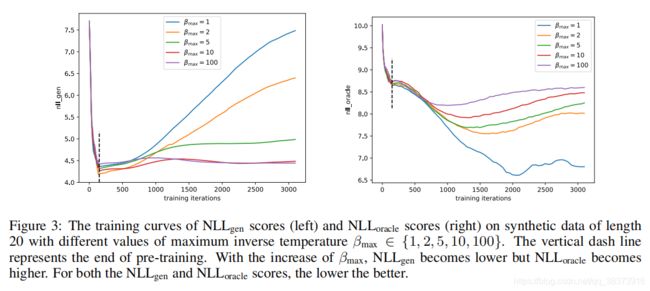
1 synthetic data
<1>

<2>
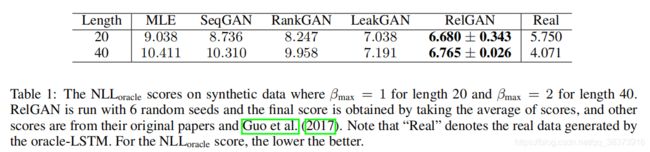
<3>
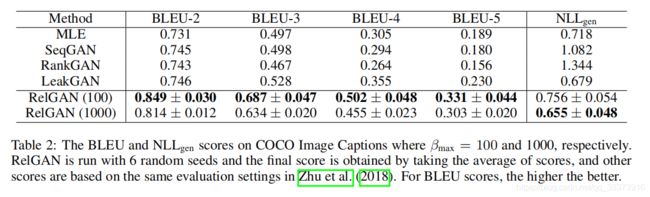
2 COCO image captions dataset
<1>
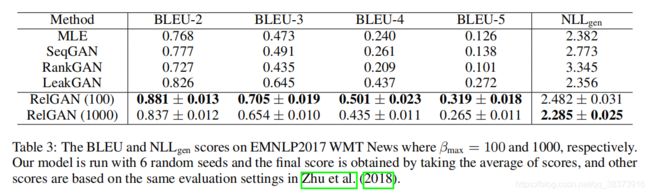
3 EMNLP2017 WMT NEWS DATASET
<1>
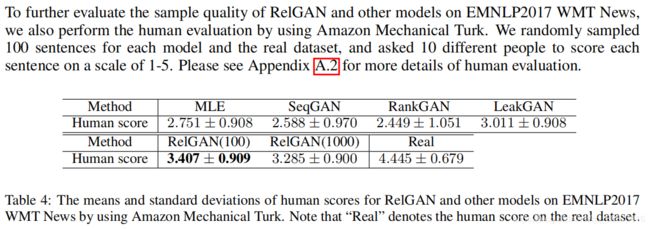
<2>
ABLATION STUDY
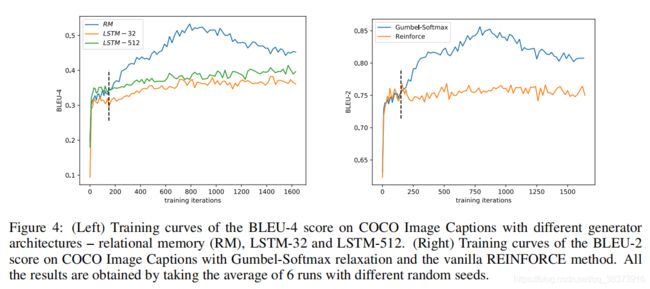
1 IMPACT OF RELATIONAL MEMORY and IMPACT OF GUMBEL-SOFTMAX RELAXATION
2 IMPACT OF MULTIPLE REPRESENTATIONS IN DISCRIMINATOR