Pandas基础题一百道(16~20)
目录
16、打印DataFrame的前后数据行
①:打印DataFrame
②:打印DataFrame前10行数据
③:打印DataFrame后十行数据
17、查看DataFrame的信息和基本数据统计
①:打印DataFrame
②:查看DataFrame的基本信息
18、 统计数据列的值出现的次数
①:数据
②:统计数据列的值出现的次数
19、DataFrame前N行存入CSV文件
①:数据
②:选取前五行数据
方法一:
方法二:
③:将筛选的数据存入CSV文件
20、读取CSV文件到DataFrame
16、打印DataFrame的前后数据行
①:打印DataFrame
df=pd.DataFrame(
data={
"norm":np.random.normal(loc=0,scale=1,size=1000),
"uniform":np.random.uniform(low=0,high=1,size=1000),
"binomial":np.random.binomial(n=2,p=0.2,size=1000)
},
index=pd.date_range(start='2022-1-1',periods=1000)
) ②:打印DataFrame前10行数据
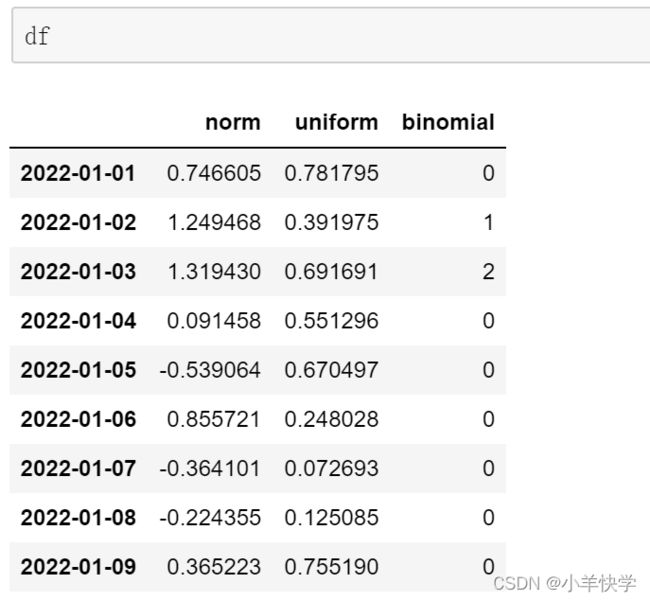
②:打印DataFrame前10行数据
#head()不加参数,默认读取前五行
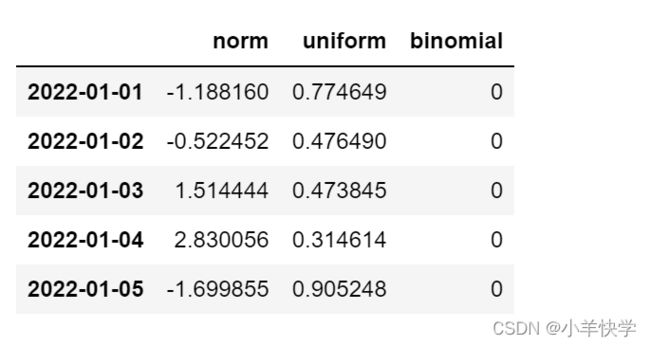
df.head(10)③:打印DataFrame后十行数据
# tail()不加参数,默认读取最后五行
df.tail(10)17、查看DataFrame的信息和基本数据统计
①:打印DataFrame
df=pd.DataFrame(
data={
"norm":np.random.normal(loc=0,scale=1,size=1000),
"uniform":np.random.uniform(low=0,high=1,size=1000),
"binomial":np.random.binomial(n=2,p=0.2,size=1000)
},
index=pd.date_range(start='2022-1-1',periods=1000)
)②:查看DataFrame的基本信息
- df.info(): # 打印摘要
- df.describe(): # 描述性统计信息
- df.values: # 转换为Adarray列表矩阵
- df.to_numpy() # 数据
(推荐) - df.shape: # 形状 (行数, 列数)
- df.columns: # 列标签
- df.columns.values: # 列标签
- df.index: # 行标签
- df.index.values: # 行标签
- df.head(n): # 前n行
- df.tail(n): # 尾n行
- pd.options.display.max_columns=n: # 最多显示n列
- pd.options.display.max_rows=n: # 最多显示n行
- df.memory_usage(): # 占用内存(字节B)
- df.sample(): #不加参数就随机查看一条数据
- df.dtypes: #查看数据类型
- df.axes: #查看索引值内容,行、列一起查看
- df.ndim: #维度数
- df.size: #行X列的总数,就是总共有多少个数据
- df.empty: #是否为空,里面有空值不算为空,完全没有东西才为True
18、 统计数据列的值出现的次数
①:数据
df=pd.DataFrame(
data={
"norm":np.random.normal(loc=0,scale=1,size=1000),
"uniform":np.random.uniform(low=0,high=1,size=1000),
"binomial":np.random.binomial(n=2,p=0.2,size=1000)
},
index=pd.date_range(start='2022-1-1',periods=1000)
)②:统计数据列的值出现的次数
df["norm"].value_counts().head()
df["uniform"].value_counts().head()
df["binomial"].value_counts().head()19、DataFrame前N行存入CSV文件
①:数据
df=pd.DataFrame(
data={
"norm":np.random.normal(loc=0,scale=1,size=1000),
"uniform":np.random.uniform(low=0,high=1,size=1000),
"binomial":np.random.binomial(n=2,p=0.2,size=1000)
},
index=pd.date_range(start='2022-1-1',periods=1000)
)②:选取前五行数据
推荐使用方法一,方法二选取多行代码相对麻烦
方法一:
df.iloc[0:5]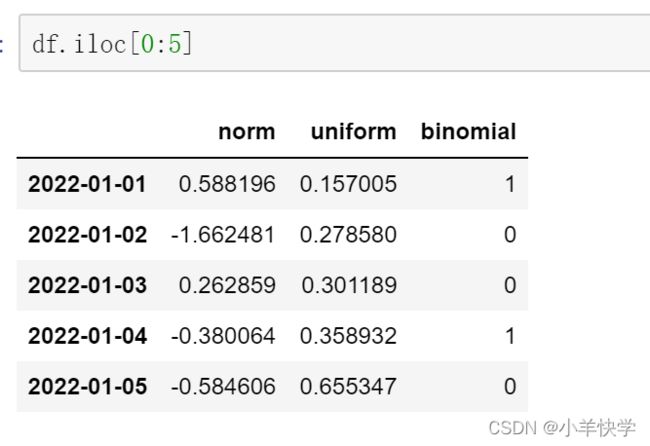
方法二:
df.loc['2022-01-01':'2022-01-05','norm':'binomial']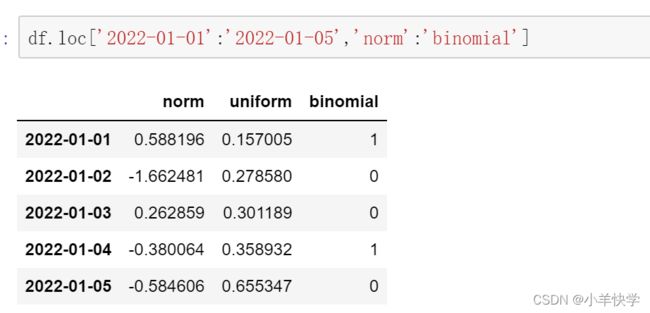
③:将筛选的数据存入CSV文件
两个方法都在后面直接加.to_csv方法
df.iloc[0:5].to_csv("数据前5行iloc方法.csv")
df.loc['2022-01-01':'2022-01-05','norm':'binomial'].to_csv("数据前5行loc方法.csv")20、读取CSV文件到DataFrame
engine:已c语言/python为分析引擎(可以理解为文件名是中文就使用它,不是中文可以不使用)
index_col:指定索引(下面的意思是用csv文件中第一列作为列索引)
pd.read_csv("数据前5行iloc方法.csv",engine='python',index_col=0)
pd.read_csv("数据前5行loc.csv方法",engine='python',index_col=0)