1.组合数据类型
实例:基本统计值计算
def getNum():
nums=[]
iNumStr=input("请输入数字(回车退出):")
while iNumStr !="":
nums.append(eval(iNumStr))
iNumStr=input("请输入数字(回车退出):")
return nums
def mean(number):
s=0.0
for num in number:
s=s+num
return s/len(number)
def dev(numbers,mean):
sdev=0.0
for num in numbers:
sdev=sdev+(num-mean)**2
return pow(sdev/(len(numbers)-1),0.5)
def median(numbers):
sorted(numbers)
size=len(numbers)
if size%2==0:
med=(numbers[size//2-1]+numbers[size//2])/2
else:
med=numbers[size//2]
return med
n=getNum()
m=mean(n)
print("平均数{},方差:{:.2},中位数:{}".format(m,dev(n,m),median(n)))
实例:文本词频统计
def getText():
txt=open("hamlet.txt","r").read()
txt=txt.lower()
for ch in '!"#$&()*+,=./:;<>=?@[\\]^_{|}~':
txt=txt.replace(cj," ")
return txt
hamletTxt=getText()
words=hamletText.split()
counts={}
for word in words:
counts[word]=counts.get(word,0)+1
items=list(counts.items())
items.sort(key=lambda x:x[1],reverse=True)
for i in range(10):
word,count=items[i]
print("{0:<10}{1:>5}".format(word,count))
import jieba
txt=open("threekingkoms.txt","r",encoding="utf-8").read()
excludes={"将军","却说","荆州","二人","不可","不能","如此"}
words=jieba.lcut(txt)
counts={}
for word in words:
if len(word)==1:
continue
elif word=="诸葛亮" or word=="孔明曰":
rword=="孔明"
elif word=="关公" or word=="云长":
rword=="关羽"
elif word=="玄德" or word=="玄德曰":
rword="刘备"
elif word=="孟德" or word=="丞相曰":
rword=="曹操"
else:
rword=word
counts[rword]=counts.get(rword,0)+1
for word in excludes:
del counts[word]
items=list(counts.items())
items.sort(key=lambda x:x[1],reverse=True)
for i in range(10):
word,count=items[i]
print("{0:<10}{1:>5}".format(word,count))
2.文件和数据格式化
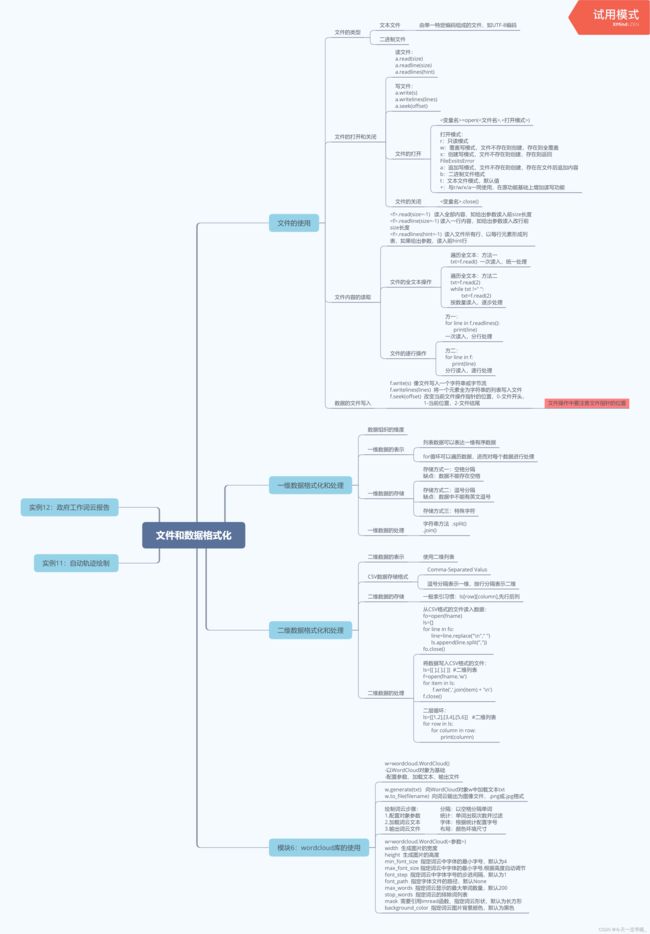
实例:自动轨迹绘制
import turtle as t
t.title("自动绘制轨迹")
t.setup(800,600,0,0)
t.pencolor("red")
t.pensize(5)
datals=[]
f.open("data.txt")
for line in f:
line=line.replace("\n","")
datals.append(list(map(eval,line.split(","))))
f.close()
for i in range(len(datals)):
t.pencolor(datals[i][3],datals[i][4],datals[i][5])
t.fd(datals[i][0])
if datals[i][1]:
t.right(datals[i][2])
else:
t.right(datals[i][2])
实例:政府工作词云报告
import jieba
import wordcloud
f=open("新时代中国特色社会主义.txt","r",encoding="utf-8")
t=f.read()
f.close()
txt=" ".join(jieba.lcut(t))
w=wordcloud.WordCloud(font_path="msyh.ttc"\
width=1000,height=700,background_color="white",\
max_words=15)
w,generate(txt)