2021.6月
7.An Image Is Worth 16X16 Words: Transformers for Image Recognition at Scale
本文章不同于以往工作的地方,就是尽可能地将NLP领域的transformer不作修改地搬到CV领域来,提出一种方式将图像这种三维数据转化为序列化的数据。文章中,图像被切割成一个个patch,这些patch按照一定的顺序排列,就成了序列化的数据.
Model Overview
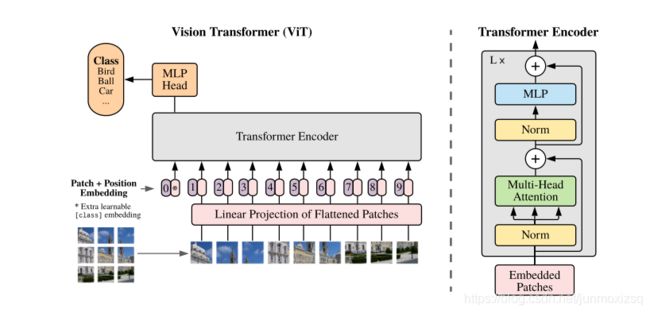
a.将图像转化为序列化数据
输入图片是H*W*C维的,用P*P大小的patch去分割图片可以得到N个patch,那么每个patch的维度就是P*P*C,转化为向量后就是P*P*C维的向量,将N个patch reshape后的向量结合在一起就得到了一个N*(P*P*C)的二维矩阵,来作为初始输入序列。
为了避免P值变化对模型结构的影响,对得到的输入向量做Linear Projection,保证这些向量长度固定,设固定为为D维.此时H*W*C的图像转化为N*D的二维矩阵.
b. Position Embedding
由于transformer模型本身是没有位置信息的我们需要用position embedding将位置信息加到模型中去。文中采用将position embedding(紫色数字圆矩框)和patch embedding(旁边粉色框)相加的方式结合position信息。
其中首部learnable embedding(记作Xclass ),这里将Xclass经过encoder后对应的结果作为整个图的表示。而这个新增的token没有语义信息(在图像中与任何的patch无关),所以不会造成上述问题,能够比较公允地反映全图的信息.

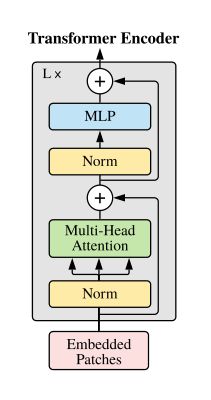
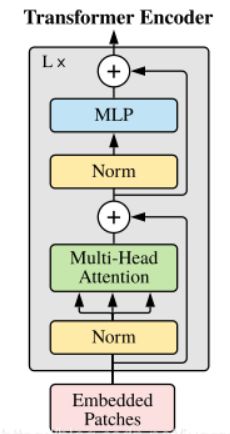
c.Transformer Encoder
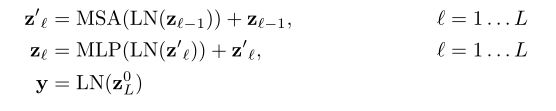
8.Rethinking Semantic Segmentation from a Sequence-to-Sequence Perspective with Transformers
本文介绍的文章中,作者旨在通过将语义分割视为序列到序列的预测任务来提供替代传统的编码-解码结构。具体而言,用一个纯transformer(即不使用卷积和不存在分辨率降低的情况)来对图像按patch的顺序进行编码。借助在transformer的每层中建模的全局上下文,在与一个简单的解码器组合起来,以提供功能强大的分割模型,简称为SETR.
给定从编码器transformer学习到的特征,然后使用解码器恢复原始图像的分辨率。关键的是,在空间分辨率上没有下采样,而是在编码器转换器的每一层进行全局上下文建模,也就是完全用注意力机制来实现了Encoder的功能,模型实质上是一个ViT+Decoder结构.
SETR OverView
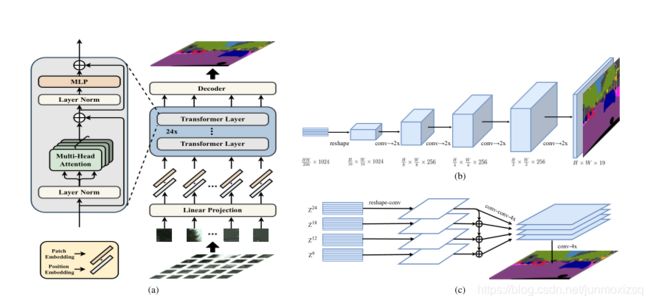
编码器部分(a):

解码器部分:作者提出两种方案
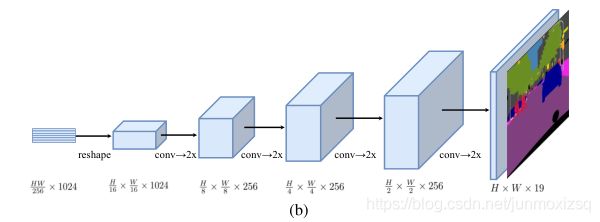
(b):Progressive UPsampling 采用渐进式上采样,交替使用卷积层和上采样操作,将上采样限制在2×总共需要4次操作,以达到完全分辨率。
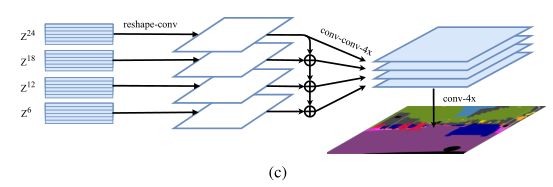
(c): Multi-Level feature Aggregation 首先将Transformer每层的输出{Z1,Z2,Z3…Z24}均匀分成4等份,每份取一个特征向量,文中例{Z6,Z12,Z18,Z24},后面的Decoder只处理这些取出的向量。从2D (H × W)/256 × C恢复到3D H/16 × W/16 × C,然后经过3层r的卷积1 × 1, 3 × 3, and 3 × 3后再经过双线性上采样4×自上而下的融合。以增强Zl 之间的相互联系.再经过3 × 3卷积后通过双线性插值4× 恢复至原分辨率.
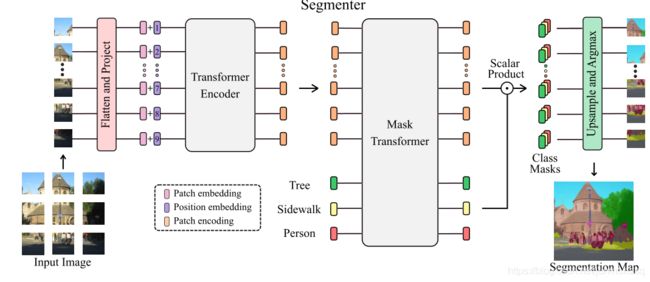
9.Segmenter: Transformer for Semantic Segmentation
基于ViT研究成果,将图像分割成patches,并将它们映射为一个线性嵌入序列,用编码器进行编码。再由Mask Transformer充当解码器将编码器的输出和类嵌入进行解码,上采样后给每个像素分好类,输出最终的像素分割图。
Segmenter Overview
编码器:
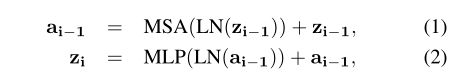
解码器:
mask transformer 目标是生成 K个masks,由patch embeddings和class embeddings作标量点积得到,令m=下式, mij代表第 i patch属于第 j class的概率.
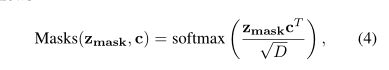
再将每个mij patch序列reshape为二维矩阵,再上采样至原分辨率![]() 双线性上采样
双线性上采样![]()
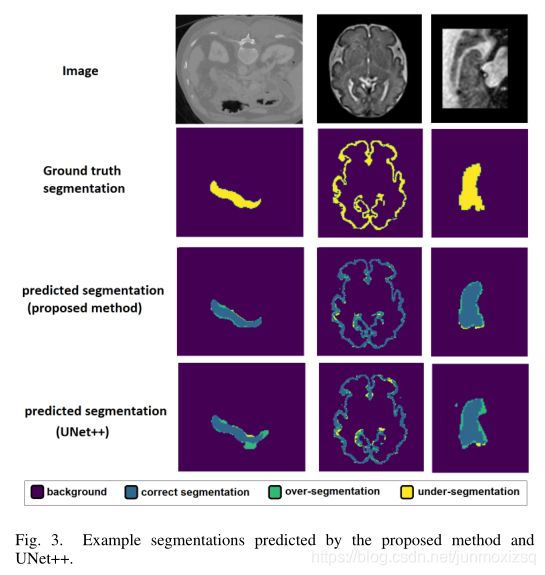
10.Convolution-Free Medical Image Segmentation using Transformers
本文提出一种3D transformer分割网络,网络的输入是一个三维块B (W×W×W×c),c是图像通道的数量。块B被分成n^3个连续的不重叠的3D patchs(w×w×w×c),其中w = W/n,N = n^3表示块中patchs的数量。本文介绍的实验中,n是3或5,分别对应于27或125个斑块。网络使用B中所有N个patch的图像信息来预测中心patch的分割。将N个patch的每一个展平成大小为w^3×c的向量,再加上position embedding构成我们网络的输入.
Network Overview
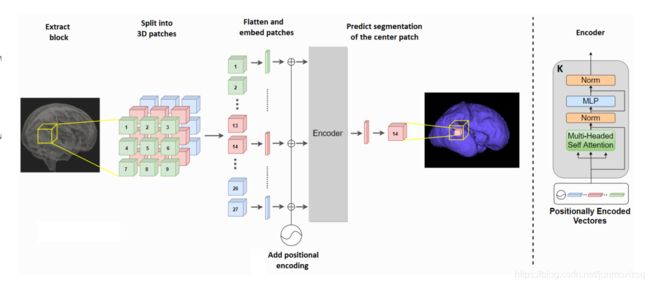
编码器部分由transformer encoder 构成,共有K层:

11.Pyramid Vision Transformer: A Versatile Backbone for Dense Prediction without Convolutions
本文提出的PVT与通与通常具有低分辨率输出和高计算和存储成本的ViT不同,PVT不仅可以在图像的密集分区上训练以获得高输出分辨率,这对于密集预测类任务很重要,还可以使用渐进缩小金字塔结构来减少大型特征地图的计算,并且不使用卷积结构.
几种不同结构对比:
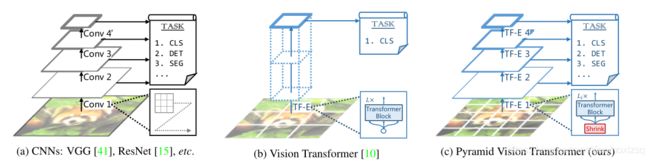
PVT OverView:

我们的方法有四个阶段来生成不同比例的特征地图。所有阶段共享一个相似的model,它由一个patch embedding层和Transformer encoder层组成。
在第一阶段,给定一幅大小为H×W ×3的输入图像,我们首先将其分成HW/4^2个patch,每个patch的大小为4×4×3。然后将每个patch映射成为向量再加上position embedding输入encoder,并且输出被reshape为特征图F1,其大小为H/4×W/4× C1。
以同样的方式,使用来自前一阶段的特征图作为输入,我们获得以下特征图F2、F3和F4。利用特征金字塔{F1,F2,F3,F4},我们的骨干方法可以很容易地应用于许多密集预测类任务,包括目标检测和语义分割。
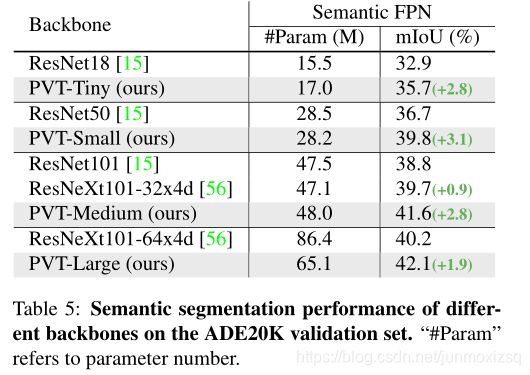
PYT应用于segmentation的实验比较:
12.TransBTS: Multimodal Brain Tumor Segmentation Using Transformer
Motivation
Transformer的成功主要体现在图像分类任务中,而对于分割这种密集型预测任务,局部信息和全局信息都同样重要,当直接将图像分割为小块作为Transformer的tokens的时候局部信息被相对忽略了。然而,对于医学三维数据,连续切片之间的局部特征建模(即深度维)也是三维分割的关键。
TransBTS Introduction
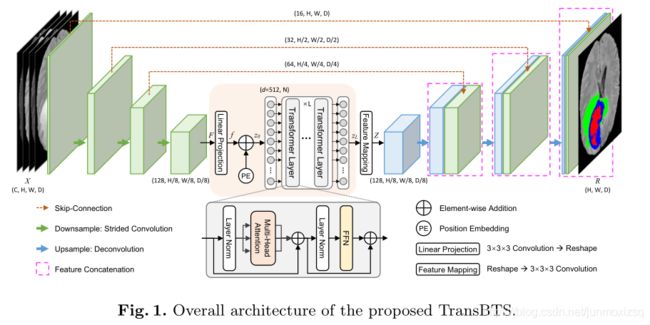
提出的TransBTS建立在一个编码-解码结构,网络的编码器首先使用3DCNN提取三维空间特征,然后同时对输入3D图像进行下采样,从而产生可以有效的捕获到局部3D上下文信息的紧凑的三维特征图。
每一个特征图被调整为一个向量( token)被输入到Transformer进行全局特征建模。3D CNN的解码器从Transformers中提取特征嵌入,并进行渐进上采样以预测全分辨率分割图。
Architecture OverView
Network Encoder
ViT将图像分割固定大小的patch,然后将每一个patch转为一个token,这样减少transformer计算复杂度。但是对于3D 的三维数据,直接像ViT那样进行直接token化,就是将数据分割为3D的块,然而这种简单的策略使得Transformer无法跨空间和深度维度对图像局部上下文信息进行建模以实现三维分割。
对于F的提取,采用3DCNN主干,使用堆叠3x3x3的卷积块,并使用步长为2的卷积进行下采样,逐渐将输入图像编码为低分辨率的具有高层特征表示的F (K=128),这只有输入尺寸对应H,W,D的1/8。再使用线性投影得到期望的序列输入(token:d×N)(其中N=8/H×8/W×8/D),再结合position embedding构成transformer的输入Z0.
Transformer Layers. Transformer 的编码器由4个Transformer层组成。每个层都有一个标准的结构,即 由一个多头注意力块MHA和一个前馈网络 FFN组成。Transformer 层输出可以通过下面的公式计算:
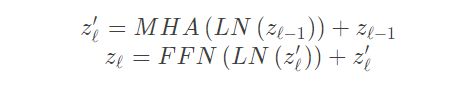
Network Decoder
Transformer层的输出序列首先被reshape为d × H/ 8 × W /8 × D/ 8 ,同时卷积块被用来减少通道维度从d到K(对称式设计)。通过这些操作,得到了特征图y∈ K × H/ 8 × W/ 8 × D/ 8 ,与在特征编码部分的F一样的维度。然后级联的上采样操作和逆卷积被用来将y逐渐的恢复到一个全分辨率的分割结果,过程中使用跳跃连接将编码特征和解码器特征进行融合,保证了更丰富的空间细节。
13.Segmenting Transparent Object in the Wild with Transformer
Contributions
提出了最大的玻璃分割数据集(Trans10K-v2),其中包含11个具有不同场景和高分辨率的细粒度玻璃图像类别。所有的图像都用精细形状的mask和面向功能的类别进行了精心注释。
本文引入了一种新的基于transformer的网络,用于透明对象分割,具有变压器编码器-解码器架构。我们的方法提供了一个全局感受野显示了很好的优势。
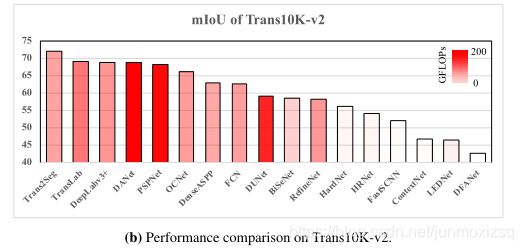
本文所提出的Trans2Seg方法与其他基于CNN的语义分割方法的比较:
Architecture Overview
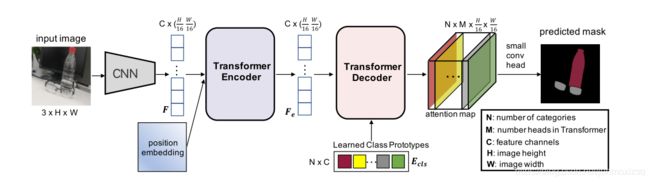
Encoder:
transformer编码器是以一个序列作为输入,因此CNN backbone提取到的feature map(H/16,W/16,C)被reshape为向量(HW/16^2,C)。再加上position embedding(以提供关于特征在序列中的相对或绝对位置的信息)作为encoder的输入(HW/16^2,C)。编码器由堆叠的transformer层组成,每个层由MHA和FFN组成,输出特征为Fe(HW/16^2,C).
Decoder:
使用具体定义的一组可学习的class embedding(Ecls)(N,C)作为Query,将编码器输出特征Fe作为Key和Value,计算attention map(N,M,HW/16^2,C).
Small Conv Head:
将deconder输出的Attention map上采样到(N,M,H /4,W/ 4),然后与CNN主干的高分辨率特征图融合为(N,M+C,H/ 4,W/ 4),最后转化为(N,H/ 4,W/ 4)的输出attention map。最终的分割是通过这个attention map来获得的。
14.Swin Transformer: Hierarchical Vision Transformer using Shifted Windows
Motivation:
将Transformer应用于计算机视觉任务中面临两个挑战,1)视觉实体的规模变化差异很大.2)以及与文本中的单词相比,图像中的像素分辨率很高,计算量巨大。
为了解决这些差异,我们提出了一种分层transformer,其表示是用移位窗口计算的。移位窗口方案通过将自关注计算限制到不重叠的局部窗口,同时还允许跨窗口连接,从而带来了更高的效率。这种分层体系结构具有在各种尺度下建模的灵活性,并且在图像尺寸方面具有线性计算复杂性。
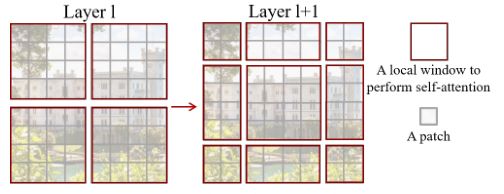
Swin Transformer的一个关键设计元素是它在连续的自我关注层之间的窗口分区的移动,如图,移位的窗口桥接了前一层的窗口,新窗口中的自我注意计算跨越了前一层中先前窗口的边界,提供了它们之间的连接,显著增强了建模能力.
Architecture OverView
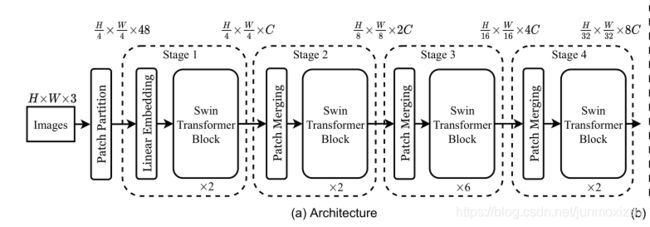
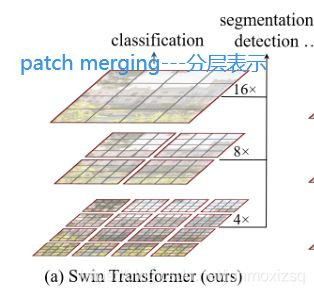
Swin Transformer总体结构如上。输入是RGB图像,首先经过一个Patch Partition模块,这里4∗4大小为一个patch,所以划分后维度变成H /4 ∗ W/ 4 ∗ 48然后经过一个Linear Embedding层,可以将特征嵌入到维度C。随后经过一个核心的Swin Transformer Block模块,token数不变。以上属于St1。
为了产生一个分层的特征表示,token的数量随着网络的加深应该不断减少,因此这里采用Patch Merging模块,来对2 ∗ 2区域内的patch进行融合,这样每一个新patch特征维度变成4C。为了减少计算量,融合后紧跟一个降维操作,将维度降到2C。随后经过Swin Transformer Block,维度保持不变。以上为St2。St3,St4以此类推.
SwinT block
其中的核心模块Swin Transformer Block如下图所示,关键之处使用W-MSA和SW-MSA取代了传统Transformer中的MSA,其他基本不变。重点是SW-MSA用到了shifted window操作,使分层特征和线性时间复杂度成为可能。



这就是本文提出的一个Transformer backbone,不仅可以产生分层多尺度的特征表示,还可以使时间复杂度降至和image size线性相关。核心部分就是window的引入降低了复杂度,patch的融合以及shifted window的引入可以提取多尺度的特征。Swin Transformer在分类、检测、分割等多个任务中达到了很高的精度,同时运算速度非常快。
15.A Novel Transformer based Semantic Segmentation Scheme for Fine-Resolution Remote Sensing Images
Swin Transformer提出了一种分层特征表示方案,线性计算复杂度大大提高了运算效率。在本文中,首先介绍了用于高分辨率遥感图像语义分割的Swin Transformer。而且,本文提出了一个密集连接的特征聚合模块(DCFAM)来提取多尺度关系增强的语义特征,用于精确分割。
所提出的整体架构DCST,是基于编码器-解码器结构构建的,其中Swin Transformer被引入作为编码器,而所提出的DCFAM被选择作为解码器。
DCST Architecture OverView
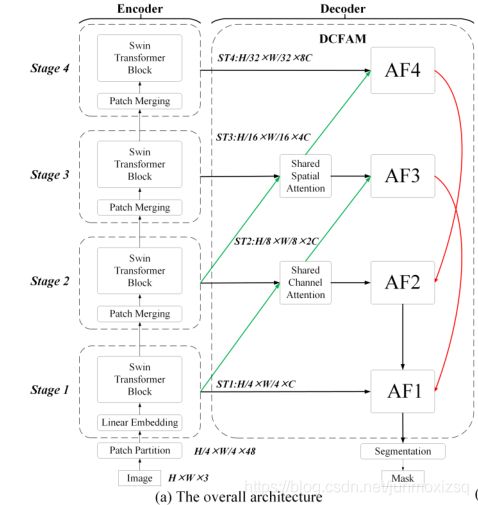
Encoder:
使用Swin Transformer块,随着网络深度的增加,通过patch merging层逐渐减少tokens的数量,以产生分层表示。通过这四个阶段,创建了四个不同大小的分层Swin Transformer(ST1,ST2,ST3,ST4)
Decoder:(DCAFM)
在编码器阶段,本文设计了共享空间注意(SSA)和共享通道注意(SCA)来增强语义特征的空间和通道关系。此外,使用下采样连接和上采样连接进一步集成了多级特征,以改善多尺度表示。
Downsample Connection:作用是连接用于融合的低级和高级特征.
Large field Upsample Connection:为了有效地捕捉多尺度上下文特征,我们将空洞卷积嵌入其中.
SSA:利用共享空间注意来建模空间维度中的长期依赖关系.
SCA:旨在提取通道维度之间的长期依赖关系.
Feature aggregation:(最终的多尺度特征聚合)
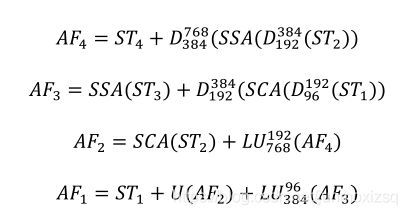
利用跨尺度连接和注意块提供的优势,AF1的最终分割特征是丰富的多尺度和上下文信息。
16.Shuffle Transformer: Rethinking Spatial Shuffle for Vision Transformer
Motivation:
基于窗口的Transformer(即在非重叠局部窗口内计算自注意力)在图像分类、语义分割以及目标检测等任务上取得极佳的成果。然而,跨窗口连接方面有所欠缺,而它会是提升表达能力的关键,例如Swin Transformer也不擅长建立长距离跨窗口连接.本文采用Spatial Shuffle提出一种有效方式构建窗口连接。我们提出了一种称之为Shuffle Transformer的架构。与此同时,我们引入深度卷积对Spatial Shuffle进行补充以增强近邻窗口连接,以提高特征表示力。
Shuffle Transformer Block
虽然Spatial Shuffle对于建立长距离跨窗口连接是有效的,但是当图像尺寸远大于窗口尺寸时,可能会出现“网格问题”。为了增强邻居窗口连接,我们在混洗变换块中引入了一个带有剩余连接的深度卷积层。总而言之它集成了Spatial Shuffle和邻居窗口连接。
Spatial Shuffle:
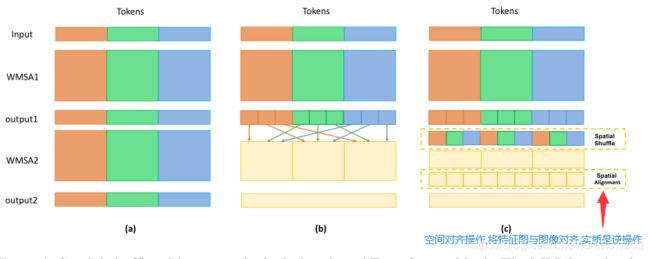
邻居窗口连接:
本文提出在WMSA模块和MLP模块之间插入了一个具有剩余连接的深度方向卷积层NWC。深度方向卷积层的内核大小与窗口大小相同。该操作可以加强附近窗口之间的信息交互,缓解“网格问题”。
Shuffle Transformer Block整体如图:


Shufflle Transformer Architecture OverView

17.CAT: Cross Attention in Vision Transformer
Motivation
针对已经提出的ViT架构,其在全局使用注意力计算,运算代价很高,本文提出了一种新的注意机制,称为cross attention,它在图像块内部而不是在整个图像中交替注意,以获取局部信息;并在图像块之间应用注意,这些图像块是从单通道feature map中分割出来的,以获取全局信息。通过交替应用内部补丁和补丁之间的注意力,我们实现了交叉注意力,以较低的计算成本保持性能,
Method:
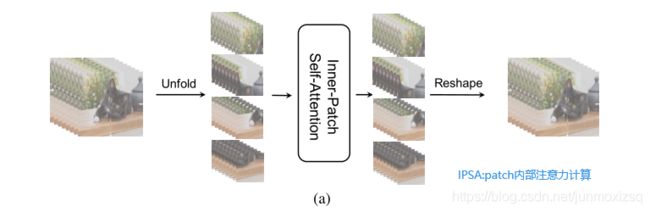
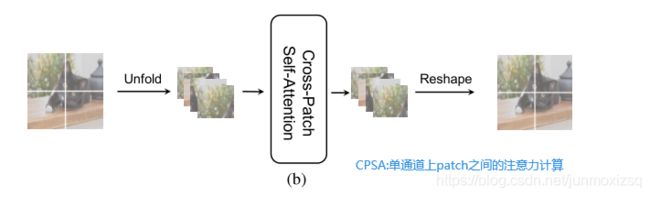
叠加IPSA块和CPSA块,提取并整合一个patch中像素之间以及一个feature map中patch之间的要素。与Swin-T中人工设计的、难以实现的、几乎没有捕获全局信息能力的移位窗口相比,本文采取的策略更合理、更容易理解。
CAT Architecture And Cross Attention Block
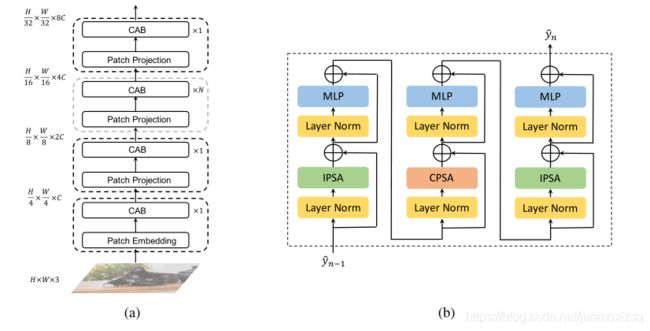
CAB模块由两个IPSA 模块和一个CPSA模块组成,运算程序步骤如下:
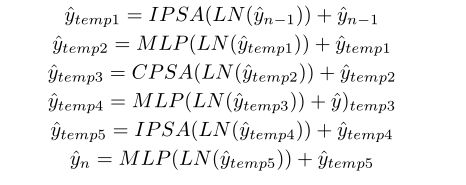
**.Dense Transformer Networks for Brain Electron Microscopy Image Segmentation
最近已经进行了许多尝试来使用CNN解决密集预测问题。这些方法的中心思想是提取以每个像素为中心的正方形patch,并在每个patch上应用CNN来计算中心像素的label。这些方法的一个共同属性是,任何像素的标签都是由以该像素为中心的正方形patch决定的。有固有的局限性,一旦网络架构被确定,用于预测每个像素的label的patch被完全确定,并且它们对于所有像素通常具有相同的大小。此外,patch通常具有规则的形状,例如正方形。
本文提出了Dense Transformer网络来解决这些限制。方法遵循编码器-解码器架构,其中编码器将输入图像转换为高级表示,解码器通过恢复原始空间分辨率来进行像素级预测。在这个框架下,每个像素的label也是由输入的局部patch决定的。但是方法的优点在于允许每个patch的大小和形状是自适应的和数据相关的。为了实现这个目标,在网络的编码器部分插入一个 spatial transformer layer。使用非线性变换。 spatial transformer layer将feature map转换到不同的空间。因此,在这个空间中执行规则卷积和pooling操作对应于在原始空间中对不同大小的不规则patch执行这些操作。由于非线性空间变换是从数据中自动学习的,这对应于学习每个patch的大小和形状,以用作卷积和pooling操作的输入.
27.Glance-and-Gaze Vision Transformer
Motivation:
Transformer的核心部分自我关注,对输入序列长度有二次复杂度。这导致在将transformer应用于需要基于高分辨率特征图的密集预测的视觉任务时带来困难。在本文中,我们提出了一种新的视觉transformer,称为Glance-Gaze Transformer(GG-Transformer),以解决上述问题。在GG-Transformer中,扫视和凝视行为是通过两个平行的分支实现的:扫视分支是通过对输入的自适应扩展的分区进行自我关注来实现的,这导致了线性复杂度,同时仍然享受全局感受野;凝视分支由一个简单的深度卷积层实现,它将局部图像上下文补偿到由扫视机制获得的特征。
Glance分支:具有自适应扩张f分区的高效全局建模
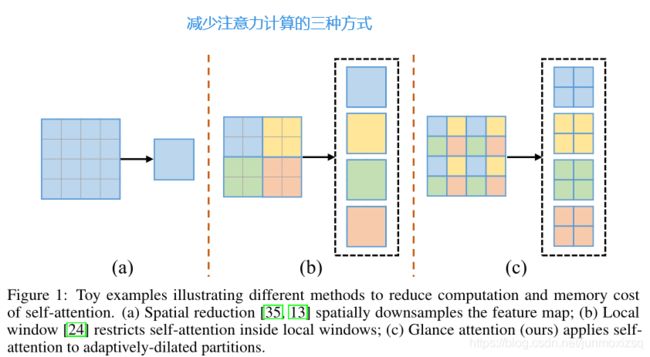
先将输入特征图分割成几个扩张的分区,即分区中的点不是来自同一个局部区域,而是来自整个输入特征图,其扩张率与特征图大小和tokens大小相适应。我们称这个操作为适应性扩张分区。计算如下:

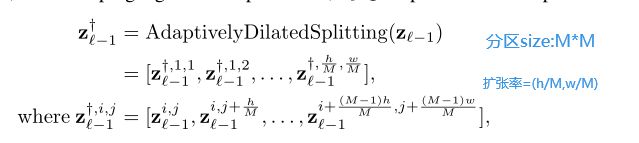
Gaze分支:用深度卷积补偿局部关系
为了补偿在Glance分支中遗漏的局部模式,本文提出以额外的深度卷积应用于Glance分支G-MSA的value中(式中Merging操作是扩张分区的逆操作):
![]()
GG Transformer OverView

28.CoTr: Efficiently Bridging CNN and Transformer for 3D Medical Image Segmentation
Motivation:
虽然Transformer的诞生就是为了解决了长距离建模,但它在处理高分辨率3D特征地图时面临着极端的计算和空间复杂性。在本文中,提出了一个新的框架,有效地桥接了CNN和Trans的精确三维医学图像分割--CoTr,以CNN来提取特征表示,并构造了一个有效的可变形Transformer(DeTrans)来对提取的feature map的长期依赖性进行建模。与平等对待所有图像位置的一般Transformer不同,DeTrans通过引入可变形的自我关注机制,只关注一小部分关键位置。使得计算和空间复杂度大大降低,便可适用于处理多尺度和高分辨率特征图.

CoTr OverView
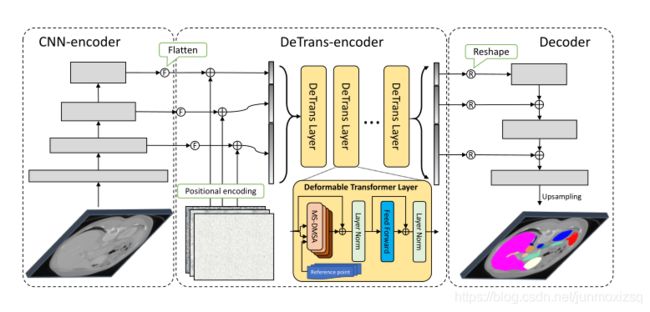
Detrans-Enconder: 它引入了多尺度可变形自我注意机制(MS-DMSA),用于在多尺度和高分辨率特征图上进行高效的远程上下文建模。
避免传统MSA计算的收敛慢,复杂度高的问题,本文设计了仅聚焦于参考位置周围的一小组关键采样位置的MS-DMSA层,而不是所有位置。
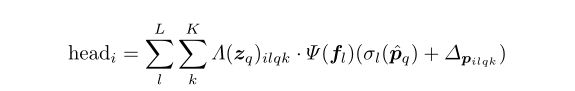
![]()
29.Fully Transformer Networks for Semantic Image Segmentation
Motivation:
目前Transformer与基于CNN的语义图像分割模型相结合是非常有前途的。然而,还没有很好地研究纯基于Transformer的方法对于图像分割能取得多好的效果。本文探索了一种新的语义图像分割框架,这是基于编码器-解码器的全变换网络(FTN)。
几种基于Transformer分割模型对比:
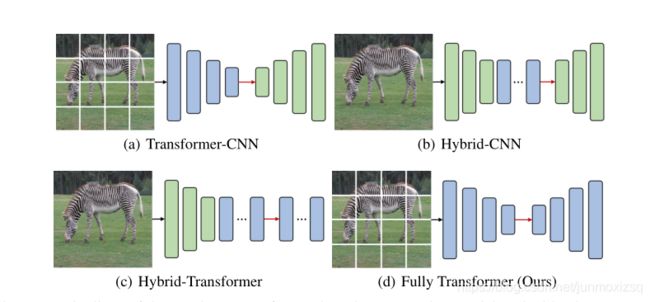
首先提出了一个金字塔组Trans(PGT),它将要素地图划分为多个空间组,并计算每个空间组的表示。这赋予了我们的模型处理空间细节或局部结构的能力.此外,PGT还降低了标准视觉Trans(ViT)的巨大计算和内存成本,此外,PGT还引入了金字塔结构原理,以降低特征分辨率,增加提取层次特征的感受野。其次,我们提出了一种特征金字塔Trans(FPT)解码器,用于融合来自PGT编码器多个层次的语义层次和空间层次的信息.
FTN OverView

通过PGT提取分层特征,通过patch transform 和merging等操作获取多尺度特征图.采用FPT解码器融合多层次的语义层和空间层信息。最后,FPT的输出被馈送到线性层,随后是简单的双线性上采样,以生成每个像素的概率图
30.DS-TransUNet: Dual Swin Transformer U-Net for Medical Image Segmentation
Motivation:
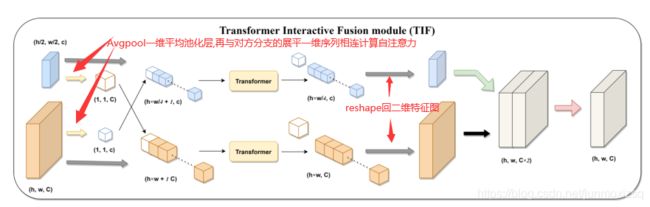
首次尝试将分层Swin Transformer结合到标准U型架构的编码器-解码器网络中,以提高不同医学图像的语义分割质量。与以往许多基于Transformer的方案不同,该方案首先采用基于Swin-T的双尺度编码器子网络来提取不同语义尺度的粗粒度和细粒度特征表示。为了充分利用这些获得的多尺度特征表示,提出了一个设计良好的transformer交互式融合模块(TIF),作为我们的核心组件,通过自关注机制有效地建立粗细两种尺度特征之间的全局依赖关系。
DS-TransUNet OverView:
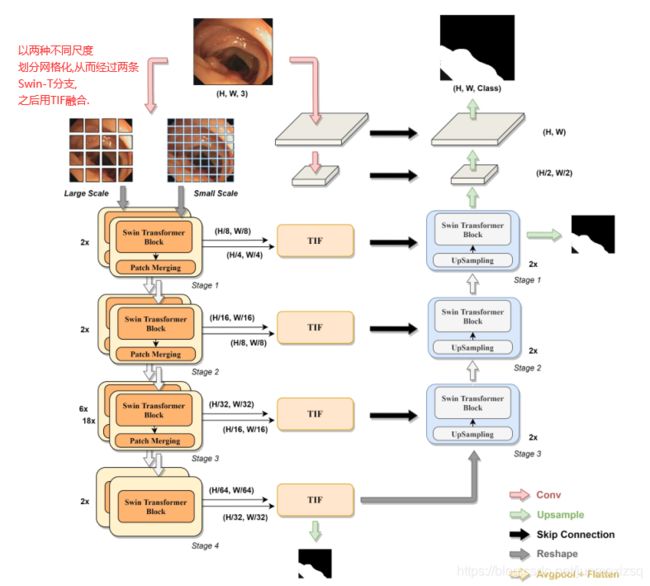
Encoder:两个不同尺度的Swin-T分支.
Decoder:对应编码器同级别特征图之间跳跃连接.在stage1 之后,如果直接使用4×上采样算子会丢失很多浅层特征,因此我们通过级联两个块来对输入图像进行下采样,以获得分辨率为H×W和H/2×W/2的低层特征.所有这些输出特征将用于通过跳过连接获得最终的掩码预测.
TIF block:
31.A Multi-Branch Hybrid Transformer Network for Corneal Endothelial Cell Segmentation
Motivation:
针对图像中对象不均匀以及边缘模糊造成的难以分割问题,需要更多的细节和上下文信息来解决这个问题。本文提出了一种基于transformer和body-edge 分支的多支路混合trans网络(MBT)。首先,我们使用卷积块来集中于局部纹理特征提取,并通过transformer和残差连接来建立空间、通道和层上的长期依赖性。此外,我们使用body-edge分支来提高局部一致性和提供边缘位置信息。
MBT OverView:
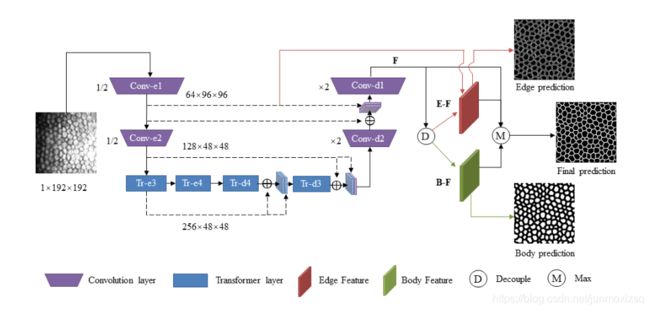
通过混合残差transformer编-解码模块提取均衡后的的输出特征F。(每个卷积层包含两个基本残差块,核大小= 3×3。每个transformer层包含两个残差trans块)。然后,特征F被解耦成两部分,主体和边缘。此外,来自Conv-e1的边缘纹理信息被融合到边缘特征中。最后,取边缘特征E-F、主体特征B-F和特征F的最大响应,得到融合特征,预测最终的分割结果。
Residual Transformer Block
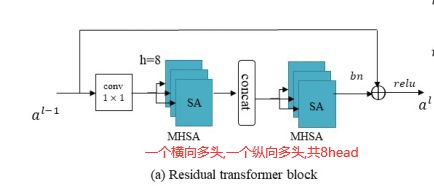
它包含两个1×1卷积来控制要计算的通道数,以及一个高度-轴向和宽度-轴向多头自关注块(MHSA),这大大减少了计算量。
Body-Edge分支:
体分支提供总体形状和整体一致性信息以促进局部一致性,边缘分支提供边缘定位信息以提高图像细节的分割精度。方法如下:
1.特征F解耦成两部分Fb和Fe (其中φ是卷积层实现)
![]()
2.来自编码器Conv-e1的低水平特征被融合到边缘特征Fe中 (其中ψ是通道操作)
![]()
3.最后,将上述三个特征图融合成最终的分割预测 (其中ϕ代表最大响应)
![]()
32.SegFormer: Simple and Efficient Design for Semantic Segmentation with Transformers
Motivation:
在Transformer在图像分割领域发展过程中,开始的ViT输出单尺度低分辨率特征,而不是多尺度特征而且在大图像上计算成本高。为了解决这些限制,后来提出了金字塔视觉Trans PVT ,这是用于密集预测的具有金字塔结构的ViT的自然扩展.然而,与其他新兴方法如Swin-T一起,这些方法主要考虑Transformer编码器的设计,忽略了解码器对进一步改进的贡献.
本文提出的框架重新设计了编码器和解码器,一种新颖的无位置编码的分层transformer编码器;轻量级MLP解码器设计,用于融合多级特征表示,无需复杂和计算要求高的模块即可产生强大的表示。
SegFormer OvreView:
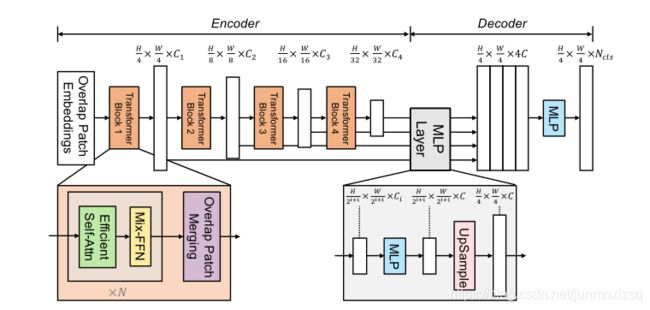
Hierarchical Transformer Encoder:
类似Swin-T的分层结构,其中包含两个新颖点:无需位置编码和高效注意力计算
Mix-FFN : 位置编码的分辨率是固定的。因此,当测试分辨率不同于训练分辨率时,需要对位置代码进行插值,这通常会导致精度下降。本文直接在FFN中使用3 × 3 Conv,本文实验中,证明了3 × 3卷积足以为Transformer提供位置信息。Mix FFN可以表述为:

Efficient Self-Attention : 编码器部分计算主要在于注意力计算方面,传统的方法是:
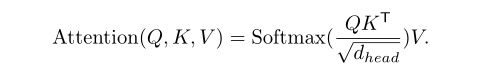
这个过程的计算复杂度是O(N^2),本文改进计算复杂度过程使用缩减率R来缩减序列的长度,改进后复杂度变为O(N^2/R)如下所示:
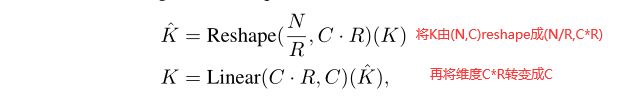
Lightweight All-MLP Decoder:
提出的MLP解码器包括四个主要步骤:

33.More than Encoder: Introducing Transformer Decoder to Upsample
Motivation:
通用分割模型对图像进行下采样,然后进行上采样,以恢复像素级预测的分辨率。在这样的模式中,上采样技术对于维护信息以获得更好的性能至关重要。在本文中提出了一种新的上采样方法,注意力上采样(AU),利用像素级的关注来建模长期依赖性和全局信息,以实现更好的重建。
它由注意力解码器(AD)和双线性上采样组成,作为补充上采样特征的剩余连接。AD采用了transformer解码器的思想,根据收缩路径的局部和详细信息对特征进行上采样。此外考虑到存储和计算开销,我们进一步提出使用窗口注意力方案.我们把我们的解码器称为窗口注意解码器,把我们的上采样方法称为窗口注意上采样。
Window Attention Upsample:
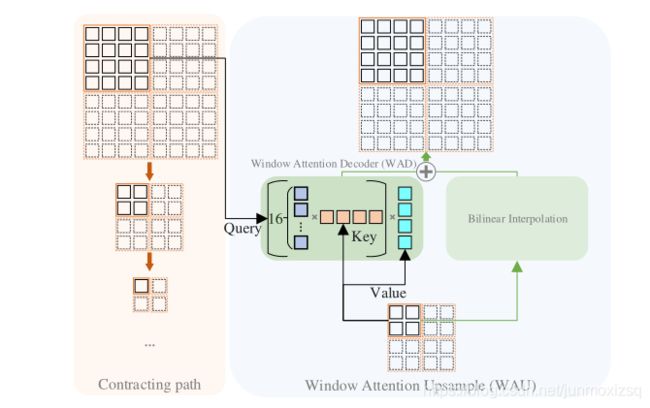
其中用卷积投影替代传统的transformer线性投影 ,可以更好的模拟局部信息:
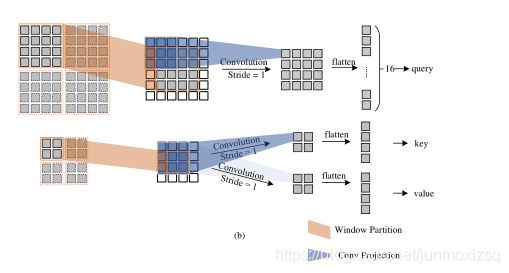
结合以上想法,提出的窗口注意解码器WAD,有两个分支,窗口注意解码器分支和双线性插值分支。所有窗口同时计算,以形成一个更大的特征地图。完成WAU和双线性插值后,两者的结果相加,作为窗口注意力上采样模块的最终输出.最后采用U型网络结构,得到最终分割预测结果.