pytorch学习笔记:进阶训练(一)损失函数、动态调整学习率
一、自定义损失函数
PyTorch在torch.nn模块为我们提供了许多常用的损失函数,比如:MSELoss,L1Loss,BCELoss… 但是随着深度学习的发展,出现了越来越多的非官方提供的Loss,比如DiceLoss,HuberLoss,SobolevLoss… 这些Loss Function专门针对一些非通用的模型,PyTorch不能将他们全部添加到库中去,因此这些损失函数的实现则需要我们通过自定义损失函数来实现。另外,在科学研究中,我们往往会提出全新的损失函数来提升模型的表现,这时我们既无法使用PyTorch自带的损失函数,也没有相关的博客供参考,此时自己实现损失函数就显得更为重要了。
1.1 以函数的方式自定义
- 求均方误差
def my_loss(output, target):
loss = torch.mean((output - target)**2)
return loss
1.2 以类的方式定义
- 实现Dice Loss,它是一种在分割领域常见的损失函数,其公式如下:详细原理
D S C = 2 ∣ X ∩ Y ∣ ∣ X ∣ + ∣ Y ∣ DSC = \frac{2|X∩Y|}{|X|+|Y|} DSC=∣X∣+∣Y∣2∣X∩Y∣
class DiceLoss(nn.Module):
def __init__(self,weight=None,size_average=True):
super(DiceLoss,self).__init__()
def forward(self,inputs,targets,smooth=1):
inputs = F.sigmoid(inputs)
inputs = inputs.view(-1) # 这边的input实际上是预测值
targets = targets.view(-1)
intersection = (inputs * targets).sum()
# 这边使用 拉普拉斯平滑,可以避免X,Y为0。
dice = (2.*intersection + smooth)/(inputs.sum() + targets.sum() + smooth)
return 1 - dice
# 使用方法
criterion = DiceLoss()
loss = criterion(inputs,targets)
二、动态调整学习率
2.1 为什么要动态调整学习率
学习率(Learning rate)作为监督学习以及深度学习中重要的超参,其决定着目标函数能否收敛到局部最小值以及何时收敛到最小值。合适的学习率能够使目标函数在合适的时间内收敛到局部最小值。
- 当学习率设置的过小时,收敛过程如下:
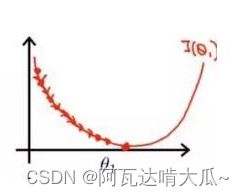
- 当学习率设置的过大时,收敛过程如下:

由上图可知,学习率过小,收敛过程缓慢,学习率过大,可能无法收敛至最小值。
2.2 pytorch提供的动态调整学习率的方法
PyTorch已经在torch.optim.lr_scheduler为我们封装好了一些动态调整学习率的方法供我们使用,如下面列出的这些scheduler。查看详情
大致有如下方法:
lr_scheduler.LambdaLR
lr_scheduler.MultiplicativeLR
lr_scheduler.StepLR
lr_scheduler.MultiStepLR
lr_scheduler.ExponentialLR
lr_scheduler.CosineAnnealingLR
lr_scheduler.ReduceLROnPlateau
lr_scheduler.CyclicLR
lr_scheduler.OneCycleLR
lr_scheduler.CosineAnnealingWarmRestarts
2.3 举例说明
我们使用lr_scheduler.StepLR作为样例,查看这些scheduler到底是如何运行的。
- 先看下StepLR的传入参数:
scheduler = lr_scheduler.StepLR(
# 优化器包装器
optimizer,
# 学习率衰退期
step_size,
# 学习率衰减的乘数,默认0。1
gamma=0.1,
# 最后一次epoch的索引,默认-1
last_epoch=-1)
- 而学习率这个参数在optimizer这个优化器中设置,使用Adam优化器
optimizer=Adam(
#可迭代的参数优化或dicts定义
params,
# 学习率(默认1e-3)
lr=1e-3,
# 用于计算的系数梯度及其平方的运行平均值
betas=(0.9, 0.999),
# 增加分母项以提高数值稳定性
eps=1e-8,
# 权重衰减
weight_decay=0,
# 是否使用“Adam and Beyond收敛”一文中该算法的AMSGrad变体`,默认False
amsgrad=False)
在优化器中我们关注2个参数,一个是params参数,一个是lr学习率。本文追踪lr如何在scheduler 中迭代。
*StepLR继承 _LRScheduler类,重写get_lr方法获取optimizer优化器的lr参数

_LRScheduler里边实现了以下几个方法:
class _LRScheduler(object):
def __init__(self, optimizer, last_epoch=-1):
# 初始化,这边有需要可以看源码进行学习
def state_dict(self):
# 保存scheduler的状态信息
def load_state_dict(self, state_dict):
# 该方法用于更新scheduler的状态
def get_last_lr(self):
# 返回当前调度程序上次计算的学习速率。
def get_lr(self):
# 继承该类方法并重写,获取lr
def step(self, epoch=None):
# step是每轮迭代真正用于更新的程序
通过以上信息可以了解get_lr方法是获取optimizer中的lr参数,那lr是以什么形式保存在optimizer中的呢?
Adam继承Optimizer类,Optimizer类中保存了param_groups参数,lr参数保存在param_groups里头,Optimizer类中也实现了state_dict方法用于保存当前优化器的状态,并保留了param_groups参数。
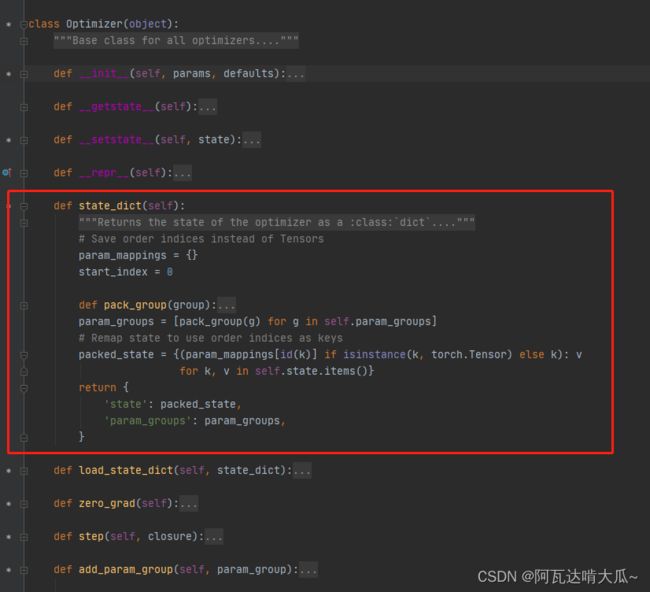
所以可以通过optimizer优化器的state_dict方法,或者scheduler 的state_dict方法获取当前学习率。以下进行可视化,初始化学习率0.01,每训练5次,学习率调整为lr * gamma .
import matplotlib.pyplot as plt
from torch import nn
import torch
from torch import optim
class Net(nn.Module):
def __init__(self):
super(Net, self).__init__()
self.net = nn.Linear(10,10)
def forward(self, input):
out = self.net(input)
return out
optimizer_lr_list = []
scheduler_lr_list = []
model = Net()
LR = 0.01
optimizer = optim.Adam(model.parameters(),lr = LR)#lr参数:学习率
scheduler = optim.lr_scheduler.StepLR(optimizer, # 包装优化器
step_size=5,# 学习衰退期
gamma = 0.8) # 学习率衰减的乘数。默认0.1
for epoch in range(100):
scheduler.step()
optimizer_lr_list.append(optimizer.state_dict()['param_groups'][0]['lr'])#优化器的状态
scheduler_lr_list.append(scheduler.state_dict()["_last_lr"][0])
#print(optimizer.state_dict()['param_groups'][0]['lr'],scheduler.state_dict()["_last_lr"][0])
#注意:源码中optimizer与scheduler都有个state_dict的方法,用来描述各自的状态。
plt.figure(figsize=(10,5))
ax=plt.subplot(1,2,1)
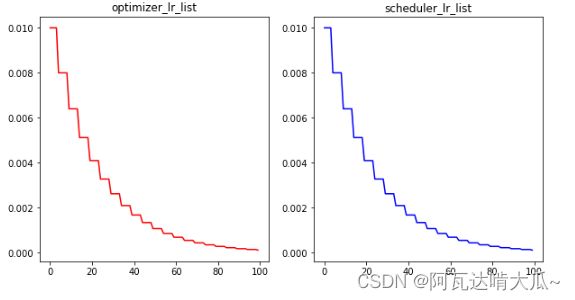
plt.plot(range(100),optimizer_lr_list,color = 'r')
plt.title("optimizer_lr_list")
ax=plt.subplot(1,2,2)
plt.plot(range(100),scheduler_lr_list,color = 'b')
plt.title("scheduler_lr_list")
plt.show()
可视化如下:
2.4 自定义调度器scheduler
lr学习率在优化器内更新,因此自定义的调度器一定要传入optimizer 参数,使用函数也行,使用类也行,下面使用类的写法
- 自定义scheduler
class myscheduler():
def __init__(self,optimizer,step_size,gamma):
"""
功能:学习率每10轮次要乘以0.5
:param optimizer: 优化器
:param step_size: 衰减周期
:param gamma: 衰减值 *0.5
"""
self.optimizer=optimizer
self.step_size=step_size
self.gamma=gamma
def get_lr(self):
"""
用于获取当前的学习率lr
"""
self.lr=self.optimizer.param_groups[-1]["lr"]
def update(self,epoch):
"""
更新学习率,与step方法类似
"""
self.get_lr()
# 每10轮就在原来的学习率上*0.5
if (epoch+1)%self.step_size==0:
lr = self.lr *self.gamma
#print(lr)
for param_group in optimizer.param_groups:
param_group['lr'] = lr
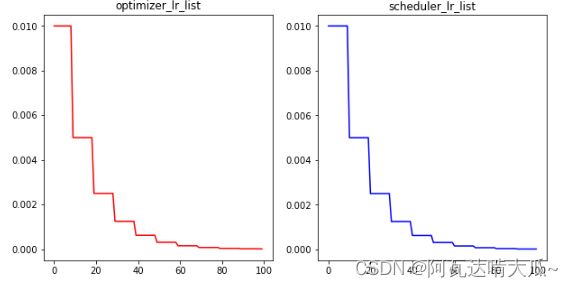
可视化验证:
optimizer_lr_list = []
scheduler_lr_list = []
model = Net()
LR = 0.01
optimizer = optim.Adam(model.parameters(),lr = LR)#lr参数:学习率
scheduler = myscheduler(optimizer,10,0.5)
for epoch in range(100):
scheduler.update(epoch)
optimizer_lr_list.append(optimizer.state_dict()['param_groups'][0]['lr'])#优化器的状态
scheduler_lr_list.append(scheduler.lr)
plt.figure(figsize=(10,5))
ax=plt.subplot(1,2,1)
plt.plot(range(100),optimizer_lr_list,color = 'r')
plt.title("optimizer_lr_list")
ax=plt.subplot(1,2,2)
plt.plot(range(100),scheduler_lr_list,color = 'b')
plt.title("scheduler_lr_list")
plt.show()
完毕!