Go kafka
Kafka
-
Kafka是分布式的:其所有的构件borker(服务端集群)、producer(消息生产)、consumer(消息消费者)都可以是分布式的。
-
可以进行分区:每一个分区都是一个顺序的、不可变的消息队列, 并且可以持续的添加。
-
高吞吐量。
结构

Producer
Producer即生产者,消息的产生者,是消息的⼊口。
kafka cluster
kafka集群,一台或多台服务器组成
Broker
Broker是指部署了Kafka实例的服务器节点。
Topic
消息的主题,可以理解为消息的分类,kafka的数据就保存在topic。在每个broker上 都可以创建多个topic。实际应用中通常是一个业务线建一个topic。
Partition
Topic的分区,每个topic可以有多个分区,分区的作用是做负载,提高kafka的吞吐量。同一个topic在不同的分区的数据是不重复的,partition的表现形式就是一个一个的⽂件夹!
Replication
每一个分区都有多个副本,副本的作用是做备胎。当主分区(Leader)故障的时候会选择一个备胎(Follower)上位,成为Leader。
在kafka中默认副本的最大数量是10 个,且副本的数量不能大于Broker的数量,follower和leader绝对是在不同的机器,同一机器对同一个分区也只可能存放一个副本(包括自己)。
Consumer
消费者,即消息的消费方,是消息的出口。
Consumer Group
我们可以将多个消费组组成一个消费者组,在kafka的设计中同一个分区的数据只能被消费者组中的某一个消费者消费。同一个消费者组的消费者可以消费同一个 topic的不同分区的数据,这也是为了提高kafka的吞吐量!
⼯作流程

- ⽣产者从Kafka集群获取分区leader信息
- ⽣产者将消息发送给leader
- leader将消息写入本地磁盘
- follower从leader拉取消息数据
- follower将消息写入本地磁盘后向leader发送ACK
- leader收到所有的follower的ACK之后向生产者发送ACK
选择partition的原则(面试重点)
某个topic有多个partition,producer⼜怎么知道该将数据发往哪个partition?
- 直接指定:写入的时候可以指定需要写入的partition,如果有指定,则写入对应的partition。
- hash:如果没有指定partition,但是设置了数据的key,则会根据key的值hash出一个partition。
- 轮询:如果既没指定partition,又没有设置key,则会采用轮询⽅式,即每次取一小段时间的数据写入某个partition,下一小段的时间写入下一个partition。
ACK应答机制(面试重点)
producer在向kafka写入消息的时候,可以设置参数来确定是否确认kafka接收到数据,这个参数可设置 的值为 0,1,all
- 0:代表producer往集群发送数据不需要等到集群的返回,不确保消息发送成功。安全性最低但是效 率最高。
- 1:代表producer往集群发送数据只要leader应答就可以发送下一条,只确保leader发送成功。
- all:代表producer往集群发送数据需要所有的follower都完成从leader的同步才会发送下一条,确保 leader发送成功和所有的副本都完成备份。安全性最⾼高,但是效率最低。
如果往不存在的topic写数据,kafka会⾃动创建topic,partition和replication的数量 默认配置都是1。
Topic和数据⽇志
topic 是同⼀类别的消息记录(record)的集合。在Kafka中,⼀个主题通常有多个订阅者。对于每个
主题,Kafka集群维护了⼀个分区数据⽇志⽂件结构如下:

- 每个partition都是⼀个有序并且不可变的消息记录集合。
- 当新的数据写⼊时,就被追加到partition的末尾。
- 在每个partition中,每条消息都会被分配⼀个顺序的唯⼀标识,这个标识被称为offset,即偏移 量。Kafka只保证在同⼀个partition内部消息是有序的,在不同partition之间,并不能保证消息有序。
Kafka可以配置⼀个保留期限,⽤来标识⽇志会在Kafka集群内保留多⻓时间。Kafka集群会保留在保留期限内所有被发布的消息,不管这些消息是否被消费过。
⽐如保留期限设置为两天,那么数据被发布到 Kafka集群的两天以内,所有的这些数据都可以被消费。当超过两天,这些数据将会被清空,以便为后 续的数据腾出空间。
由于Kafka会将数据进⾏持久化存储(即写⼊到硬盘上),所以保留的数据⼤⼩可 以设置为⼀个⽐较⼤的值。
Partition结构
Partition在服务器上的表现形式就是⼀个⼀个的⽂件夹,每个partition的⽂件夹下⾯会有多组segment ⽂件,每组segment⽂件⼜包含 .index ⽂件、 .log ⽂件、 .timeindex ⽂件三个⽂件,其中 .log ⽂件就是实际存储message的地⽅,⽽ .index 和 .timeindex ⽂件为索引⽂件,⽤于检索消息。
消费数据
-
多个消费者实例可以组成⼀个消费者组,并⽤⼀个标签来标识这个消费者组。⼀个消费者组中的不同消费者实例可以运⾏在不同的进程甚⾄不同的服务器上。
-
如果所有的消费者实例都在不同的消费者组,那么每⼀条消息记录会被⼴播到每⼀个消费者实例。
-
在同⼀个消费者组中,每个消费者实例可以消费多个分区,但是每个分区最多只能被消费者组中的⼀个实例消费。
kafka环境搭建
kafka环境基于zookeeper,zookeeper环境基于JAVA-JDK。
!!!新版本的kafka自带zookeeper,可以不手动安装【不想花几个小时盯着cmd就不要手贱去安装】!!! ————Generalzy
java环境变量
https://www.oracle.com/technetwork/java/javase/downloads/jdk12-downloads-5295953.html
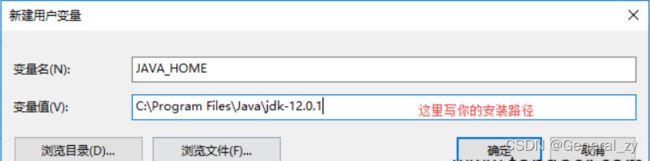
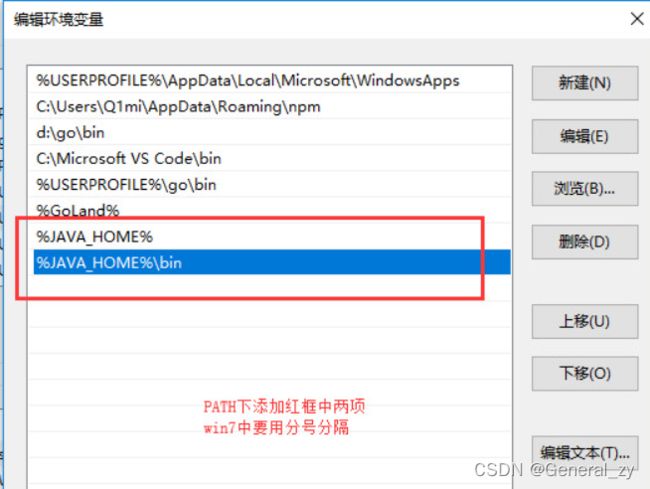
安装kafka
http://kafka.apache.org/downloads
1.打开config目录下的server.properties文件
2.修改log.dirs=F:/tmp/kafka-logs //日志存放
3.打开config目录下的zookeeper.properties文件
4.修改dataDir=F:/tmp/zookeeper //数据存放
启动:
先执行:bin\windows\zookeeper-server-start.bat config\zookeeper.properties
再执行:bin\windows\kafka-server-start.bat config\server.properties
zookeeper:

kafka:

操作Kafka
依赖
go get github.com/Shopify/sarama
windows: mod文件中手动加 require github.com/shopify/sarama v1.19.0
连接kafka发送消息
func main() {
config := sarama.NewConfig() // 配置对象
config.Producer.RequiredAcks = sarama.WaitForAll // 发送完数据需要leader和follow都确认
config.Producer.Partitioner = sarama.NewRandomPartitioner // 新选出一个partition
config.Producer.Return.Successes = true // 成功交付的消息将在success channel返回
// 构造一个消息
msg := &sarama.ProducerMessage{}
msg.Topic = "web_log"
msg.Value = sarama.StringEncoder("this is a test log")
// 连接kafka
client, err := sarama.NewSyncProducer([]string{"127.0.0.1:9092"}, config)
if err != nil {
fmt.Println("producer closed, err:", err)
return
}
defer client.Close()
// 发送消息
pid, offset, err := client.SendMessage(msg)
if err != nil {
fmt.Println("send msg failed, err:", err)
return
}
fmt.Printf("pid:%v offset:%v\n", pid, offset)
}
连接kafka消费消息
func main() {
consumer, err := sarama.NewConsumer([]string{"127.0.0.1:9092"}, nil)
if err != nil {
fmt.Printf("fail to start consumer, err:%v\n", err)
return
}
partitionList, err := consumer.Partitions("web_log") // 根据topic取到所有的分区
if err != nil {
fmt.Printf("fail to get list of partition:err%v\n", err)
return
}
fmt.Println(partitionList)
for partition := range partitionList { // 遍历所有的分区
// 针对每个分区创建一个对应的分区消费者
pc, err := consumer.ConsumePartition("web_log", int32(partition), sarama.OffsetNewest)
if err != nil {
fmt.Printf("failed to start consumer for partition %d,err:%v\n", partition, err)
return
}
defer pc.AsyncClose()
// 异步从每个分区消费信息
go func(sarama.PartitionConsumer) {
for msg := range pc.Messages() {
fmt.Printf("Partition:%d Offset:%d Key:%v Value:%v", msg.Partition, msg.Offset, msg.Key, msg.Value)
}
}(pc)
}
}