PaddlePaddle高层API,基于seq2seq的对联生成
PaddlePaddle高层API学习笔记与代码实践记录
课程链接:https://aistudio.baidu.com/aistudio/course/introduce/6771
对联,是汉族传统文化之一,是写在纸、布上或刻在竹子、木头、柱子上的对偶语句。对联对仗工整,平仄协调,是一字一音的汉语独特的艺术形式,是中国传统文化瑰宝。
这里,我们将根据上联,自动写下联。这是一个典型的序列到序列(sequence2sequence, seq2seq)建模的场景,编码器-解码器(Encoder-Decoder)框架是解决seq2seq问题的经典方法,它能够将一个任意长度的源序列转换成另一个任意长度的目标序列:编码阶段将整个源序列编码成一个向量,解码阶段通过最大化预测序列概率,从中解码出整个目标序列。编码和解码的过程通常都使用RNN实现。
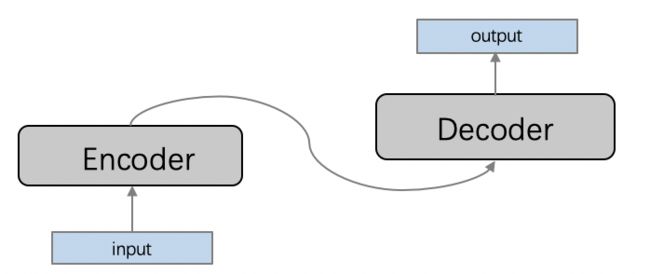
这里的Encoder采用LSTM,Decoder采用带有attention机制的LSTM。

我们将以对联的上联作为Encoder的输出,下联作为Decoder的输入,训练模型。
AI Studio平台后续会默认安装PaddleNLP,在此之前可使用如下命令安装。
!pip install --upgrade paddlenlp>=2.0.0b -i https://pypi.org/simple
import paddlenlp
paddlenlp.__version__
'2.0.0rc1'
import io
import os
from functools import partial
import numpy as np
import paddle
import paddle.nn as nn
import paddle.nn.functional as F
from paddlenlp.data import Vocab, Pad
from paddlenlp.metrics import Perplexity
from paddlenlp.datasets import CoupletDataset
数据部分
数据集介绍
采用开源的对联数据集couplet-clean-dataset,该数据集过滤了
couplet-dataset中的低俗、敏感内容。
这个数据集包含70w多条训练样本,1000条验证样本和1000条测试样本。
下面列出一些训练集中对联样例:
上联:晚风摇树树还挺 下联:晨露润花花更红
上联:愿景天成无墨迹 下联:万方乐奏有于阗
上联:丹枫江冷人初去 下联:绿柳堤新燕复来
上联:闲来野钓人稀处 下联:兴起高歌酒醉中
加载数据集
paddlenlp.datasets中内置了多个常见数据集,包括这里的对联数据集CoupletDataset。
paddlenlp.datasets均继承paddle.io.Dataset,支持paddle.io.Dataset的所有功能:
- 通过
len()函数返回数据集长度,即样本数量。 - 下标索引:通过下标索引[n]获取第n条样本。
- 遍历数据集,获取所有样本。
此外,paddlenlp.datasets,还支持如下操作:
- 调用
get_datasets()函数,传入list或者string,获取相对应的train_dataset、development_dataset、test_dataset等。其中train为训练集,用于模型训练; development为开发集,也称验证集validation_dataset,用于模型参数调优;test为测试集,用于评估算法的性能,但不会根据测试集上的表现再去调整模型或参数。 - 调用
apply()函数,对数据集进行指定操作。
这里的CoupletDataset数据集继承TranslationDataset,继承自paddlenlp.datasets,除以上通用用法外,还有一些个性设计:
- 在
CoupletDataset class中,还定义了transform函数,用于在每个句子的前后加上起始符和结束符,并将原始数据映射成id序列。
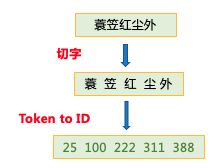
train_ds, dev_ds, test_ds = CoupletDataset.get_datasets(['train', 'dev', 'test'])
100%|██████████| 21421/21421 [00:01<00:00, 15104.55it/s]
来看看数据集有多大,长什么样:
print (len(train_ds), len(test_ds), len(dev_ds))
for i in range(5):
print (train_ds[i])
print ('\n')
for i in range(5):
print (test_ds[i])
702594 999 1000
([1, 447, 3, 509, 153, 153, 279, 1517, 2], [1, 816, 294, 378, 9, 9, 142, 32, 2])
([1, 594, 185, 10, 71, 18, 158, 912, 2], [1, 14, 105, 107, 835, 20, 268, 3855, 2])
([1, 335, 830, 68, 425, 4, 482, 246, 2], [1, 94, 51, 1115, 23, 141, 761, 17, 2])
([1, 126, 17, 217, 802, 4, 1103, 118, 2], [1, 125, 205, 47, 55, 57, 78, 15, 2])
([1, 1203, 228, 390, 10, 1921, 827, 474, 2], [1, 1699, 89, 426, 317, 314, 43, 374, 2])
([1, 6, 201, 350, 54, 1156, 2], [1, 64, 522, 305, 543, 102, 2])
([1, 168, 1402, 61, 270, 11, 195, 253, 2], [1, 435, 782, 1046, 36, 188, 1016, 56, 2])
([1, 744, 185, 744, 6, 18, 452, 16, 1410, 2], [1, 286, 102, 286, 74, 20, 669, 280, 261, 2])
([1, 2577, 496, 1133, 60, 107, 2], [1, 1533, 318, 625, 1401, 172, 2])
([1, 163, 261, 6, 64, 116, 350, 253, 2], [1, 96, 579, 13, 463, 16, 774, 586, 2])
vocab, _ = CoupletDataset.get_vocab()
trg_idx2word = vocab.idx_to_token
vocab_size = len(vocab)
pad_id = vocab[CoupletDataset.EOS_TOKEN]
bos_id = vocab[CoupletDataset.BOS_TOKEN]
eos_id = vocab[CoupletDataset.EOS_TOKEN]
print (pad_id, bos_id, eos_id)
2 1 2
构造dataloder
使用paddle.io.DataLoader来创建训练和预测时所需要的DataLoader对象。
paddle.io.DataLoader返回一个迭代器,该迭代器根据batch_sampler指定的顺序迭代返回dataset数据。支持单进程或多进程加载数据,快!
接收如下重要参数:
batch_sampler:批采样器实例,用于在paddle.io.DataLoader中迭代式获取mini-batch的样本下标数组,数组长度与 batch_size 一致。collate_fn:指定如何将样本列表组合为mini-batch数据。传给它参数需要是一个callable对象,需要实现对组建的batch的处理逻辑,并返回每个batch的数据。在这里传入的是prepare_input函数,对产生的数据进行pad操作,并返回实际长度等。
PaddleNLP提供了许多NLP任务中,用于数据处理、组batch数据的相关API。
| API | 简介 |
|---|---|
paddlenlp.data.Stack |
堆叠N个具有相同shape的输入数据来构建一个batch |
paddlenlp.data.Pad |
将长度不同的多个句子padding到统一长度,取N个输入数据中的最大长度 |
paddlenlp.data.Tuple |
将多个batchify函数包装在一起 |
更多数据处理操作详见: https://github.com/PaddlePaddle/PaddleNLP/blob/develop/docs/data.md
def create_data_loader(dataset):
data_loader = paddle.io.DataLoader(
dataset,
batch_sampler=None,
batch_size = batch_size,
collate_fn=partial(prepare_input, pad_id=pad_id))
return data_loader
def prepare_input(insts, pad_id):
src, src_length = Pad(pad_val=pad_id, ret_length=True)([inst[0] for inst in insts])
tgt, tgt_length = Pad(pad_val=pad_id, ret_length=True)([inst[1] for inst in insts])
tgt_mask = (tgt[:, :-1] != pad_id).astype(paddle.get_default_dtype())
return src, src_length, tgt[:, :-1], tgt[:, 1:, np.newaxis], tgt_mask
use_gpu = False
device = paddle.set_device("gpu" if use_gpu else "cpu")
batch_size = 128
num_layers = 2
dropout = 0.2
hidden_size =256
max_grad_norm = 5.0
learning_rate = 0.001
max_epoch = 20
model_path = './couplet_models'
log_freq = 200
# Define dataloader
train_loader = create_data_loader(train_ds)
test_loader = create_data_loader(test_ds)
print(len(train_ds), len(train_loader), batch_size)
# 702594 5490 128 共5490个batch
for i in train_loader:
print (len(i))
for ind, each in enumerate(i):
print (ind, each.shape)
break
702594 5490 128
5
0 [128, 18]
1 [128]
2 [128, 17]
3 [128, 17, 1]
4 [128, 17]
模型部分
下图是带有Attention的Seq2Seq模型结构。下面我们分别定义网络的每个部分,最后构建Seq2Seq主网络。
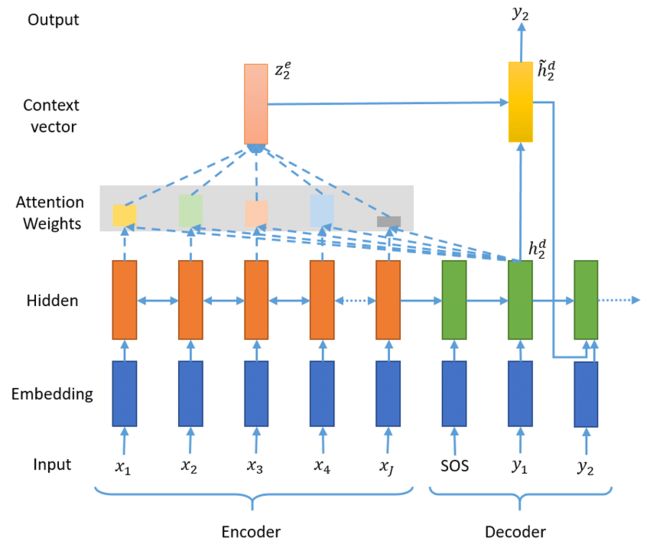
定义Encoder
Encoder部分非常简单,可以直接利用PaddlePaddle2.0提供的RNN系列API的nn.LSTM。
nn.Embedding:该接口用于构建 Embedding 的一个可调用对象,根据输入的size (vocab_size, embedding_dim)自动构造一个二维embedding矩阵,用于table-lookup。查表过程如下:

nn.LSTM:提供序列,得到encoder_output和encoder_state。
参数:
- input_size (int) 输入的大小。
- hidden_size (int) - 隐藏状态大小。
- num_layers (int,可选) - 网络层数。默认为1。
- direction (str,可选) - 网络迭代方向,可设置为forward或bidirect(或bidirectional)。默认为forward。
- time_major (bool,可选) - 指定input的第一个维度是否是time steps。默认为False。
- dropout (float,可选) - dropout概率,指的是出第一层外每层输入时的dropout概率。默认为0。
https://www.paddlepaddle.org.cn/documentation/docs/zh/api/paddle/nn/layer/rnn/LSTM_cn.html
输出:
outputs (Tensor) - 输出,由前向和后向cell的输出拼接得到。如果time_major为True,则Tensor的形状为[time_steps,batch_size,num_directions * hidden_size],如果time_major为False,则Tensor的形状为[batch_size,time_steps,num_directions * hidden_size],当direction设置为bidirectional时,num_directions等于2,否则等于1。
final_states (tuple) - 最终状态,一个包含h和c的元组。形状为[num_lauers * num_directions, batch_size, hidden_size],当direction设置为bidirectional时,num_directions等于2,否则等于1。
class Seq2SeqEncoder(nn.Layer):
def __init__(self, vocab_size, embed_dim, hidden_size, num_layers):
super(Seq2SeqEncoder, self).__init__()
self.embedder = nn.Embedding(vocab_size, embed_dim)
self.lstm = nn.LSTM(
input_size=embed_dim,
hidden_size=hidden_size,
num_layers=num_layers,
dropout=0.2 if num_layers > 1 else 0.)
def forward(self, sequence, sequence_length):
inputs = self.embedder(sequence)
encoder_output, encoder_state = self.lstm(
inputs, sequence_length=sequence_length)
# encoder_output [128, 18, 256] [batch_size,time_steps,hidden_size]
# encoder_state (tuple) - 最终状态,一个包含h和c的元组。 [2, 128, 256] [2, 128, 256] [num_lauers * num_directions, batch_size, hidden_size]
return encoder_output, encoder_state
定义Decoder
定义AttentionLayer
nn.Linear线性变换层传入2个参数
- in_features (int) – 线性变换层输入单元的数目。
- out_features (int) – 线性变换层输出单元的数目。

paddle.matmul用于计算两个Tensor的乘积,遵循完整的广播规则,关于广播规则,请参考广播 (broadcasting) 。 并且其行为与 numpy.matmul 一致。
- x (Tensor) : 输入变量,类型为 Tensor,数据类型为float32, float64。
- y (Tensor) : 输入变量,类型为 Tensor,数据类型为float32, float64。
- transpose_x (bool,可选) : 相乘前是否转置 x,默认值为False。
- transpose_y (bool,可选) : 相乘前是否转置 y,默认值为False。
-
paddle.unsqueeze用于向输入Tensor的Shape中一个或多个位置(axis)插入尺寸为1的维度 -
paddle.add逐元素相加算子,输入 x 与输入 y 逐元素相加,并将各个位置的输出元素保存到返回结果中。
输入 x 与输入 y 必须可以广播为相同形状。
class AttentionLayer(nn.Layer):
def __init__(self, hidden_size):
super(AttentionLayer, self).__init__()
self.input_proj = nn.Linear(hidden_size, hidden_size)
self.output_proj = nn.Linear(hidden_size + hidden_size, hidden_size)
def forward(self, hidden, encoder_output, encoder_padding_mask):
encoder_output = self.input_proj(encoder_output)
attn_scores = paddle.matmul(
paddle.unsqueeze(hidden, [1]), encoder_output, transpose_y=True)
# print('attention score', attn_scores.shape) #[128, 1, 18]
if encoder_padding_mask is not None:
attn_scores = paddle.add(attn_scores, encoder_padding_mask)
attn_scores = F.softmax(attn_scores)
attn_out = paddle.squeeze(
paddle.matmul(attn_scores, encoder_output), [1])
# print('1 attn_out', attn_out.shape) #[128, 256]
attn_out = paddle.concat([attn_out, hidden], 1)
# print('2 attn_out', attn_out.shape) #[128, 512]
attn_out = self.output_proj(attn_out)
# print('3 attn_out', attn_out.shape) #[128, 256]
return attn_out
定义Seq2SeqDecoderCell
由于Decoder部分是带有attention的LSTM,我们不能复用nn.LSTM,所以需要定义Seq2SeqDecoderCell
nn.LayerList用于保存子层列表,它包含的子层将被正确地注册和添加。列表中的子层可以像常规python列表一样被索引。这里添加了num_layers=2层lstm。
class Seq2SeqDecoderCell(nn.RNNCellBase):
def __init__(self, num_layers, input_size, hidden_size):
super(Seq2SeqDecoderCell, self).__init__()
self.dropout = nn.Dropout(0.2)
self.lstm_cells = nn.LayerList([
nn.LSTMCell(
input_size=input_size + hidden_size if i == 0 else hidden_size,
hidden_size=hidden_size) for i in range(num_layers)
])
self.attention_layer = AttentionLayer(hidden_size)
def forward(self,
step_input,
states,
encoder_output,
encoder_padding_mask=None):
lstm_states, input_feed = states
new_lstm_states = []
step_input = paddle.concat([step_input, input_feed], 1)
for i, lstm_cell in enumerate(self.lstm_cells):
out, new_lstm_state = lstm_cell(step_input, lstm_states[i])
step_input = self.dropout(out)
new_lstm_states.append(new_lstm_state)
out = self.attention_layer(step_input, encoder_output,
encoder_padding_mask)
return out, [new_lstm_states, out]
定义Seq2SeqDecoder
有了Seq2SeqDecoderCell,就可以构建Seq2SeqDecoder了
paddle.nn.RNN该OP是循环神经网络(RNN)的封装,将输入的Cell封装为一个循环神经网络。它能够重复执行 cell.forward() 直到遍历完input中的所有Tensor。
- cell (RNNCellBase) - RNNCellBase类的一个实例。
class Seq2SeqDecoder(nn.Layer):
def __init__(self, vocab_size, embed_dim, hidden_size, num_layers):
super(Seq2SeqDecoder, self).__init__()
self.embedder = nn.Embedding(vocab_size, embed_dim)
self.lstm_attention = nn.RNN(
Seq2SeqDecoderCell(num_layers, embed_dim, hidden_size))
self.output_layer = nn.Linear(hidden_size, vocab_size)
def forward(self, trg, decoder_initial_states, encoder_output,
encoder_padding_mask):
inputs = self.embedder(trg)
decoder_output, _ = self.lstm_attention(
inputs,
initial_states=decoder_initial_states,
encoder_output=encoder_output,
encoder_padding_mask=encoder_padding_mask)
predict = self.output_layer(decoder_output)
return predict
构建主网络Seq2SeqAttnModel
Encoder和Decoder定义好之后,网络就可以构建起来了
class Seq2SeqAttnModel(nn.Layer):
def __init__(self, vocab_size, embed_dim, hidden_size, num_layers,
eos_id=1):
super(Seq2SeqAttnModel, self).__init__()
self.hidden_size = hidden_size
self.eos_id = eos_id
self.num_layers = num_layers
self.INF = 1e9
self.encoder = Seq2SeqEncoder(vocab_size, embed_dim, hidden_size,
num_layers)
self.decoder = Seq2SeqDecoder(vocab_size, embed_dim, hidden_size,
num_layers)
def forward(self, src, src_length, trg):
# encoder_output 各时刻的输出h
# encoder_final_state 最后时刻的输出h,和记忆信号c
encoder_output, encoder_final_state = self.encoder(src, src_length)
print('encoder_output shape', encoder_output.shape) # [128, 18, 256] [batch_size,time_steps,hidden_size]
print('encoder_final_states shape', encoder_final_state[0].shape, encoder_final_state[1].shape) #[2, 128, 256] [2, 128, 256] [num_lauers * num_directions, batch_size, hidden_size]
# Transfer shape of encoder_final_states to [num_layers, 2, batch_size, hidden_size]
encoder_final_states = [
(encoder_final_state[0][i], encoder_final_state[1][i])
for i in range(self.num_layers)
]
print('encoder_final_states shape', encoder_final_states[0][0].shape, encoder_final_states[0][1].shape) #[128, 256] [128, 256]
# Construct decoder initial states: use input_feed and the shape is
# [[h,c] * num_layers, input_feed], consistent with Seq2SeqDecoderCell.states
decoder_initial_states = [
encoder_final_states,
self.decoder.lstm_attention.cell.get_initial_states(
batch_ref=encoder_output, shape=[self.hidden_size])
]
# Build attention mask to avoid paying attention on padddings
src_mask = (src != self.eos_id).astype(paddle.get_default_dtype())
print ('src_mask shape', src_mask.shape) #[128, 18]
print(src_mask[0, :])
encoder_padding_mask = (src_mask - 1.0) * self.INF
print ('encoder_padding_mask', encoder_padding_mask.shape) #[128, 18]
print(encoder_padding_mask[0, :])
encoder_padding_mask = paddle.unsqueeze(encoder_padding_mask, [1])
print('encoder_padding_mask', encoder_padding_mask.shape) #[128, 1, 18]
predict = self.decoder(trg, decoder_initial_states, encoder_output,
encoder_padding_mask)
print('predict', predict.shape) #[128, 17, 7931]
return predict
定义损失函数
这里使用的是交叉熵损失函数,我们需要将padding位置的loss置为0,因此需要在损失函数中引入trg_mask参数,由于PaddlePaddle框架提供的paddle.nn.CrossEntropyLoss不能接受trg_mask参数,因此在这里需要重新定义:
class CrossEntropyCriterion(nn.Layer):
def __init__(self):
super(CrossEntropyCriterion, self).__init__()
def forward(self, predict, label, trg_mask):
cost = F.softmax_with_cross_entropy(
logits=predict, label=label, soft_label=False)
cost = paddle.squeeze(cost, axis=[2])
masked_cost = cost * trg_mask
batch_mean_cost = paddle.mean(masked_cost, axis=[0])
seq_cost = paddle.sum(batch_mean_cost)
return seq_cost
执行过程
训练过程
使用高层API执行训练,需要调用prepare和fit函数。
在prepare函数中,配置优化器、损失函数,以及评价指标。其中评价指标使用的是PaddleNLP提供的困惑度计算API paddlenlp.metrics.Perplexity。
如果你安装了VisualDL,可以在fit中添加一个callbacks参数使用VisualDL观测你的训练过程,如下:
model.fit(train_data=train_loader,
epochs=max_epoch,
eval_freq=1,
save_freq=1,
save_dir=model_path,
log_freq=log_freq,
callbacks=[paddle.callbacks.VisualDL('./log')])
在这里,由于对联生成任务没有明确的评价指标,因此,可以在保存的多个模型中,通过人工评判生成结果选择最好的模型。
本项目中,为了便于演示,已经将训练好的模型参数载入模型,并省略了训练过程。读者自己实验的时候,可以尝试自行修改超参数,调用下面被注释掉的fit函数,重新进行训练。
如果读者想要在更短的时间内得到效果不错的模型,可以使用预训练模型技术,例如《预训练模型ERNIE-GEN自动写诗》项目为大家展示了如何利用预训练的生成模型进行训练。
model = paddle.Model(
Seq2SeqAttnModel(vocab_size, hidden_size, hidden_size,
num_layers, pad_id))
optimizer = paddle.optimizer.Adam(
learning_rate=learning_rate, parameters=model.parameters())
ppl_metric = Perplexity()
model.prepare(optimizer, CrossEntropyCriterion(), ppl_metric)
# model.fit(train_data=train_loader,
# epochs=max_epoch,
# eval_freq=1,
# save_freq=1,
# save_dir=model_path,
# log_freq=log_freq)
模型预测
定义预测网络Seq2SeqAttnInferModel
预测网络继承上面的主网络Seq2SeqAttnModel,定义子类Seq2SeqAttnInferModel
class Seq2SeqAttnInferModel(Seq2SeqAttnModel):
def __init__(self,
vocab_size,
embed_dim,
hidden_size,
num_layers,
bos_id=0,
eos_id=1,
beam_size=4,
max_out_len=256):
self.bos_id = bos_id
self.beam_size = beam_size
self.max_out_len = max_out_len
self.num_layers = num_layers
super(Seq2SeqAttnInferModel, self).__init__(
vocab_size, embed_dim, hidden_size, num_layers, eos_id)
# Dynamic decoder for inference
self.beam_search_decoder = nn.BeamSearchDecoder(
self.decoder.lstm_attention.cell,
start_token=bos_id,
end_token=eos_id,
beam_size=beam_size,
embedding_fn=self.decoder.embedder,
output_fn=self.decoder.output_layer)
def forward(self, src, src_length):
encoder_output, encoder_final_state = self.encoder(src, src_length)
encoder_final_state = [
(encoder_final_state[0][i], encoder_final_state[1][i])
for i in range(self.num_layers)
]
# Initial decoder initial states
decoder_initial_states = [
encoder_final_state,
self.decoder.lstm_attention.cell.get_initial_states(
batch_ref=encoder_output, shape=[self.hidden_size])
]
# Build attention mask to avoid paying attention on paddings
src_mask = (src != self.eos_id).astype(paddle.get_default_dtype())
encoder_padding_mask = (src_mask - 1.0) * self.INF
encoder_padding_mask = paddle.unsqueeze(encoder_padding_mask, [1])
# Tile the batch dimension with beam_size
encoder_output = nn.BeamSearchDecoder.tile_beam_merge_with_batch(
encoder_output, self.beam_size)
encoder_padding_mask = nn.BeamSearchDecoder.tile_beam_merge_with_batch(
encoder_padding_mask, self.beam_size)
# Dynamic decoding with beam search
seq_output, _ = nn.dynamic_decode(
decoder=self.beam_search_decoder,
inits=decoder_initial_states,
max_step_num=self.max_out_len,
encoder_output=encoder_output,
encoder_padding_mask=encoder_padding_mask)
return seq_output
解码部分
接下来对我们的任务选择beam search解码方式,可以指定beam_size为10。
def post_process_seq(seq, bos_idx, eos_idx, output_bos=False, output_eos=False):
"""
Post-process the decoded sequence.
"""
eos_pos = len(seq) - 1
for i, idx in enumerate(seq):
if idx == eos_idx:
eos_pos = i
break
seq = [
idx for idx in seq[:eos_pos + 1]
if (output_bos or idx != bos_idx) and (output_eos or idx != eos_idx)
]
return seq
beam_size = 10
# init_from_ckpt = './couplet_models/0' # for test
# infer_output_file = './infer_output.txt'
# test_loader, vocab_size, pad_id, bos_id, eos_id = create_data_loader(test_ds, batch_size)
# vocab, _ = CoupletDataset.get_vocab()
# trg_idx2word = vocab.idx_to_token
model = paddle.Model(
Seq2SeqAttnInferModel(
vocab_size,
hidden_size,
hidden_size,
num_layers,
bos_id=bos_id,
eos_id=eos_id,
beam_size=beam_size,
max_out_len=256))
model.prepare()
在预测之前,我们需要将训练好的模型参数load进预测网络,之后我们就可以根据对联的上联,生成对联的下联啦!
model.load('couplet_models/model_18')
test_ds = CoupletDataset.get_datasets(['test'])
idx = 0
for data in test_loader():
inputs = data[:2]
finished_seq = model.predict_batch(inputs=list(inputs))[0]
finished_seq = finished_seq[:, :, np.newaxis] if len(
finished_seq.shape) == 2 else finished_seq
finished_seq = np.transpose(finished_seq, [0, 2, 1])
for ins in finished_seq:
for beam in ins:
id_list = post_process_seq(beam, bos_id, eos_id)
word_list_l = [trg_idx2word[id] for id in test_ds[idx][0]][1:-1]
word_list_r = [trg_idx2word[id] for id in id_list]
sequence = "上联: "+" ".join(word_list_l)+"\t下联: "+" ".join(word_list_r) + "\n"
print(sequence)
idx += 1
break
/opt/conda/envs/python35-paddle120-env/lib/python3.7/site-packages/paddle/fluid/layers/utils.py:77: DeprecationWarning: Using or importing the ABCs from 'collections' instead of from 'collections.abc' is deprecated, and in 3.8 it will stop working
return (isinstance(seq, collections.Sequence) and
上联: 心 尘 须 自 扫 下联: 世 事 不 由 人
上联: 碧 涧 飞 泉 山 笑 语 下联: 青 山 叠 翠 鸟 谈 天
上联: 即 景 即 心 无 机 不 被 下联: 有 情 有 意 有 意 相 随
上联: 袋 鼓 黎 民 乐 下联: 胸 怀 社 稷 安
上联: 相 通 心 意 何 须 语 下联: 不 解 情 怀 不 必 言
上联: 促 公 义 一 身 正 气 下联: 保 民 生 两 袖 清 风
上联: 重 建 黉 宫 犹 忆 院 中 曾 起 凤 下联: 弘 扬 国 粹 更 期 天 下 再 腾 龙
上联: 落 字 不 从 奇 巧 胜 下联: 行 文 自 有 古 今 同
上联: 拂 水 柳 丝 撩 碎 月 下联: 落 花 花 影 醉 清 风
上联: 千 载 长 城 历 尽 沧 桑 烽 火 连 绵 留 胜 迹 下联: 万 年 大 业 历 经 坎 坷 英 雄 浩 荡 展 雄 风
上联: 核 能 火 箭 穿 空 跃 下联: 气 定 神 州 逐 梦 飞
上联: 正 道 不 衰 书 不 朽 下联: 清 风 常 在 德 无 穷
上联: 月 倚 高 楼 风 送 爽 下联: 花 开 小 院 雪 添 香
上联: 联 网 怡 情 寻 妙 语 下联: 春 风 得 意 送 佳 音
上联: 项 羽 吹 风 真 霸 气 下联: 刘 伶 煮 酒 忒 精 神
上联: 税 企 展 宏 图 促 小 康 圆 梦 下联: 民 生 兴 伟 业 兴 大 业 兴 邦
上联: 几 字 箴 言 德 养 清 廉 贪 养 腐 下联: 一 腔 热 血 情 融 诚 信 爱 扶 贫
上联: 歌 摇 香 雾 鬟 朱 唇 浅 破 桃 花 萼 下联: 画 卷 春 风 韵 翠 袖 轻 摇 杨 柳 枝
上联: 积 德 累 仁 远 矣 一 本 水 木 下联: 高 山 流 水 长 哉 千 古 风 流
上联: 花 言 巧 语 迷 心 窍 下联: 月 色 清 风 入 梦 乡
上联: 执 杖 空 山 风 问 道 下联: 弹 琴 古 寺 月 知 音
上联: 叹 亘 古 英 雄 欲 铸 和 平 刀 泣 血 下联: 看 今 朝 壮 志 更 添 华 夏 志 凌 云
上联: 一 盘 蒸 出 三 湘 韵 下联: 四 海 迎 来 四 海 春
上联: 良 辰 美 景 三 春 绿 下联: 明 月 清 风 一 夜 香
上联: 秦 岭 修 行 淮 水 斩 蛟 万 民 拥 戴 歌 千 载 下联: 东 风 浩 荡 春 风 化 雨 百 业 兴 隆 颂 九 州
上联: 结 友 还 应 诚 以 待 下联: 修 身 不 必 俭 而 勤
上联: 放 大 肚 皮 容 难 事 下联: 放 开 眼 界 见 真 情
上联: 长 篙 撑 破 烟 波 绿 下联: 短 笛 吹 开 雨 露 红
上联: 几 句 五 言 诗 便 教 胜 地 生 辉 王 郎 载 誉 下联: 千 年 千 古 史 犹 记 春 风 化 雨 桃 李 芬 芳
上联: 风 乱 诗 文 期 断 句 下联: 月 移 花 影 惹 残 花
上联: 一 捧 清 凉 半 瓢 月 下联: 半 窗 寂 寞 满 江 红
上联: 关 注 民 生 服 务 民 生 保 障 民 生 兴 国 祚 下联: 弘 扬 国 粹 弘 扬 国 粹 和 谐 社 会 富 民 生
上联: 书 香 醉 倒 窗 前 月 下联: 月 色 迷 离 梦 里 人
上联: 楼 高 不 碍 闲 云 渡 下联: 路 远 何 妨 野 鹤 归
上联: 以 汤 沃 雪 下联: 临 水 流 云
上联: 紫 燕 携 春 来 探 我 下联: 红 梅 傲 雪 去 迎 宾
上联: 崖 悬 风 雨 骤 下联: 月 落 月 光 寒
上联: 白 石 清 江 留 月 影 下联: 清 风 明 月 醉 花 香
上联: 流 金 时 节 云 霞 展 梦 下联: 大 地 春 秋 桃 李 争 春
上联: 打 趣 不 识 趣 自 讨 没 趣 下联: 求 真 务 求 真 何 必 求 真
上联: 最 宜 词 客 题 襟 结 对 赏 花 来 杏 岭 下联: 更 有 诗 人 醉 酒 邀 朋 邀 月 醉 诗 心
上联: 名 山 不 必 高 千 仞 下联: 大 海 何 须 纳 百 川
上联: 共 赋 新 诗 发 宫 徵 下联: 不 将 名 字 负 春 秋
上联: 体 健 神 怡 晚 景 好 下联: 风 和 日 丽 晚 霞 红
上联: 好 书 好 读 直 须 读 下联: 好 事 难 求 不 必 求
上联: 马 驰 和 县 康 庄 道 下联: 羊 跃 祥 云 锦 绣 春
上联: 舟 泊 寒 汀 惊 雁 字 下联: 月 临 古 寺 悟 禅 机
上联: 卖 菜 上 京 经 上 蔡 下联: 寻 春 故 里 醉 桃 花
上联: 谁 解 清 泉 低 语 意 下联: 我 知 明 月 近 人 心
上联: 朝 登 剑 阁 云 随 马 下联: 风 过 泸 州 带 酒 香
上联: 低 吟 浅 唱 一 纸 风 流 字 句 下联: 浅 唱 轻 歌 几 弦 寂 寞 弦 弦
上联: 戏 中 文 文 中 戏 看 戏 看 文 各 得 雅 趣 下联: 天 上 人 地 天 下 知 音 知 音 都 是 知 音
上联: 先 贤 圣 哲 书 中 坐 下联: 后 辈 英 雄 笔 下 行
上联: 尚 义 崇 文 法 治 护 航 中 国 梦 下联: 崇 文 尚 武 文 明 铺 锦 上 河 图
上联: 公 平 端 起 水 一 碗 下联: 正 气 正 直 风 满 怀
上联: 一 山 胜 概 华 表 高 标 犹 见 硕 儒 题 柱 句 下联: 千 古 文 章 清 风 明 月 更 闻 雏 凤 振 龙 声
上联: 天 临 暮 晚 余 辉 灿 下联: 风 过 泸 州 带 酒 香
上联: 岁 月 悠 悠 绿 水 微 澜 帆 影 梦 下联: 江 山 漫 漫 红 尘 不 染 雁 声 情
上联: 香 山 一 染 深 秋 色 下联: 绿 水 长 流 碧 水 情
上联: 无 事 聊 天 能 咋 地 下联: 有 情 对 月 可 当 家
上联: 快 马 加 鞭 妃 子 笑 下联: 春 风 得 意 美 人 来
上联: 夏 至 荷 塘 香 两 岸 下联: 春 分 柳 岸 绿 千 畴
上联: 芳 草 绿 阳 关 塞 上 春 风 入 户 下联: 清 风 明 月 渡 江 边 月 色 盈 窗
上联: 致 富 思 源 跟 党 走 下联: 脱 贫 致 富 为 民 生
上联: 欣 然 入 梦 抱 书 睡 下联: 何 必 登 楼 赏 月 眠
上联: 诗 赖 境 奇 赢 感 动 下联: 心 随 心 静 悟 禅 机
上联: 栀 子 牵 牛 犁 熟 地 下联: 莲 花 吐 蕊 吐 香 香
上联: 廿 载 相 交 成 知 己 下联: 千 秋 不 朽 著 文 章
上联: 润 下联: 修
上联: 设 帏 遇 芳 辰 百 岁 期 颐 刚 一 半 下联: 簪 缨 逢 盛 世 千 秋 俎 豆 祀 千 秋
上联: 波 光 云 影 满 目 葱 茏 谁 道 人 间 无 胜 地 下联: 鸟 语 花 香 一 帘 幽 梦 我 知 天 下 有 知 音
上联: 眸 中 映 月 心 如 镜 下联: 笔 下 生 花 气 若 虹
上联: 何 事 营 生 闲 来 写 幅 青 山 卖 下联: 此 情 入 世 静 坐 读 书 明 月 来
上联: 学 海 钩 深 毫 挥 具 见 三 长 足 下联: 书 山 登 绝 顶 放 开 怀 一 片 天
上联: 女 子 千 金 一 笑 贵 下联: 人 生 万 事 两 相 宜
上联: 柏 叶 为 铭 椒 花 献 瑞 下联: 芝 兰 在 抱 芝 草 生 香
上联: 家 国 遽 亡 天 涯 有 客 图 恢 复 下联: 英 雄 永 逝 地 狱 无 风 雨 滂 沱
上联: 侍 郎 赋 咏 穷 三 峡 下联: 游 子 吟 哦 遍 九 州
上联: 反 腐 堵 污 流 杜 渐 防 微 不 教 长 堤 崩 蚁 穴 下联: 倡 廉 扶 正 气 羊 羔 跪 乳 常 教 大 地 报 春 晖
上联: 已 兆 飞 熊 钓 渭 水 下联: 还 将 雁 字 寄 秦 川
上联: 建 生 态 文 明 人 与 自 然 协 调 发 展 下联: 创 科 学 发 展 家 和 社 会 和 谐 和 谐
上联: 于 自 不 高 于 他 不 下 下联: 与 人 同 乐 与 我 同 行
上联: 国 泰 民 安 军 民 人 人 歌 盛 世 下联: 风 和 日 丽 山 河 处 处 展 宏 图
上联: 金 龙 腾 大 地 看 四 野 平 畴 三 农 报 喜 下联: 玉 兔 跃 神 州 喜 九 州 大 地 万 户 迎 春
上联: 兴 盛 下联: 平 安
上联: 长 安 跑 马 谁 得 意 下联: 广 府 古 城 百 花 芳
上联: 诗 咏 律 工 歌 李 杜 下联: 联 吟 雅 韵 颂 刘 琨
上联: 立 脚 怕 随 流 俗 转 下联: 修 身 不 与 俗 人 知
上联: 忆 昨 日 天 涯 尤 藏 龙 卧 虎 堪 言 世 事 下联: 看 今 朝 大 地 更 有 虎 腾 龙 不 负 人 生
上联: 轶 才 钟 翰 墨 集 兰 撷 蕙 下联: 青 史 著 文 章 继 往 开 来
上联: 青 锋 破 茧 终 无 济 下联: 紫 燕 衔 泥 自 有 情
上联: 愿 看 者 看 愿 听 者 听 看 听 自 取 两 便 下联: 喜 喜 喜 喜 喜 喜 喜 喜 喜 喜 喜 迎 万 家
上联: 俭 是 传 家 宝 下联: 勤 为 济 世 根
上联: 佛 口 蛇 心 常 惑 众 下联: 春 风 春 雨 总 关 情
上联: 正 气 一 身 万 贯 不 如 人 格 贵 下联: 清 风 两 袖 千 秋 犹 似 世 风 淳
上联: 轻 云 拂 素 月 下联: 细 雨 洗 红 尘
上联: 缘 来 缘 去 缘 如 水 下联: 月 缺 月 缺 月 似 钩
上联: 看 篮 球 热 火 下联: 对 牖 外 芳 英
上联: 飞 觞 共 醉 天 边 月 下联: 泼 墨 同 吟 地 上 诗
上联: 鲜 花 朵 朵 九 州 放 下联: 紫 燕 翩 翩 四 海 来
上联: 春 风 播 绿 下联: 夏 雨 润 红
上联: 诗 书 味 道 齐 同 酒 下联: 笔 墨 情 怀 共 与 茶
上联: 酤 酒 帜 下联: 织 霓 裳
上联: 黑 白 休 颠 倒 下联: 丹 青 可 纵 横
上联: 领 风 领 雅 东 方 诗 圣 下联: 继 往 开 来 南 国 名 山
上联: 酒 兰 却 言 十 年 事 下联: 梅 花 独 占 一 枝 春
上联: 马 放 南 山 东 篱 赏 菊 夜 阑 时 忆 边 关 月 下联: 情 牵 故 里 西 子 浣 纱 夜 静 处 思 故 里 人
上联: 小 燕 归 来 君 不 在 下联: 清 风 过 后 我 还 来
上联: 林 间 绿 树 蝉 迹 隐 下联: 岭 上 青 山 鸟 语 幽
上联: 三 阳 开 泰 宏 图 阔 下联: 百 业 兴 隆 伟 业 兴
上联: 拐 弯 抹 角 难 行 路 下联: 反 腐 倡 廉 好 做 官
上联: 玉 堂 名 贯 古 今 主 人 易 招 牌 不 易 下联: 金 谷 香 飘 天 地 客 客 难 得 道 难 行
上联: 频 提 出 句 每 有 佳 联 十 八 子 下联: 一 点 成 联 常 将 妙 句 两 千 联
上联: 修 道 成 仙 色 分 青 白 下联: 悟 禅 悟 道 风 度 苍 生
上联: 有 心 醉 死 扑 花 冢 下联: 无 意 归 来 入 梦 乡
上联: 日 白 天 蓝 云 彩 紫 下联: 花 红 柳 绿 柳 丝 青
上联: 燕 使 加 鞭 追 旧 梦 下联: 羊 毫 蘸 彩 绘 新 图
上联: 阔 少 兜 中 都 少 阔 下联: 英 雄 上 下 不 轻 松
上联: 羊 角 送 吉 祥 国 梦 辉 煌 圆 我 梦 下联: 猴 年 迎 喜 庆 春 风 浩 荡 暖 人 心
上联: 白 云 过 处 惊 山 鸟 下联: 明 月 时 时 照 水 云
上联: 柳 系 丝 绦 春 入 赘 下联: 花 开 锦 绣 蝶 出 墙
上联: 万 里 悲 秋 常 作 客 下联: 千 年 大 梦 总 关 情
上联: 望 穿 秋 水 离 人 醉 下联: 唤 醒 春 风 过 客 愁
上联: 缘 定 三 生 几 世 轮 回 君 莫 忘 下联: 情 牵 一 梦 一 生 牵 挂 我 相 思
上联: 柳 暗 花 明 风 流 千 古 今 超 昔 下联: 山 高 水 远 浪 漫 九 州 古 不 今
上联: 慧 日 中 天 式 弘 佛 法 下联: 慈 云 大 地 光 耀 莲 台
上联: 樱 花 飞 舞 阿 里 山 中 谁 扫 榻 下联: 柳 絮 飞 飞 西 湖 月 下 我 吟 诗
上联: 米 洒 因 丢 盖 下联: 茶 香 自 纵 横
PaddleNLP更多教程
- 使用seq2vec模块进行句子情感分析
- 使用预训练模型ERNIE优化情感分析
- 使用BiGRU-CRF模型完成快递单信息抽取
- 使用预训练模型ERNIE优化快递单信息抽取
- 使用预训练模型ERNIE-GEN实现智能写诗
- 使用TCN网络完成新冠疫情病例数预测
- 使用预训练模型完成阅读理解
- 自定义数据集实现文本多分类任务
加入交流群,一起学习吧
现在就加入PaddleNLP的QQ技术交流群,一起交流NLP技术吧!
