【吴恩达机器学习笔记】九、机器学习系统的设计
✍个人博客:https://blog.csdn.net/Newin2020?spm=1011.2415.3001.5343
专栏定位:为学习吴恩达机器学习视频的同学提供的随堂笔记。
专栏简介:在这个专栏,我将整理吴恩达机器学习视频的所有内容的笔记,方便大家参考学习。
专栏地址:https://blog.csdn.net/Newin2020/article/details/128125806
视频地址:吴恩达机器学习系列课程
❤️如果有收获的话,欢迎点赞收藏,您的支持就是我创作的最大动力
九、机器学习系统的设计
1. 确定执行的优先级
现在我们先来看一个关于分类垃圾邮件和非垃圾邮件的例子。
这里所用到的就是监督学习,我们会选取一定的特征量x表示文章中出现的单词,下面就是选取了100个特征关键词作为判断标准,然后给于训练集在垃圾和非垃圾邮件中去判断其中这些单词是否出现。
而特征值等于1说明出现了,等于0说明没有出现。

这里需要注意的是,在现实中,我们通常会在训练集中选取出现频率最高的单词作为特征,一般数量在1000到50000个,而不是像我们上面那样手动选取100个特征来那个。
那么,该如何提高分类的准确度而降低错误率呢,这有以下几个方法:
- 增加你的训练数据集。
- 用更复杂的特征关注于邮件的标题。
- 对于文章主体即正文使用更复杂的特征。
- 用一些更复杂的算法来检测出拼写错误。
2. 误差分析
上面我们介绍过利用图像来判断高方差和高偏差的问题,能够帮你节省很多没必要的时间,接下来我将为你介绍另一个方法,能够帮助你更好的去完善模型,那就是误差分析。
还是拿上面垃圾邮件分类的例子,你可以通过分析那些被分错的邮件有哪些共同之处,然后可以去增加一些特征量,去想一个更好的模型,如下所示:

假设分类算法错误分类了100个邮件,这时你可以手动的分类,观察它们哪些类别的邮件出错率很高,比如可能钓鱼邮件分类错误率高,这时就去观察这些邮件中有什么共同之处,比如拼写错误、奇怪的来源或者是不正常的标点。假设有不正常的标点特征的邮件居多,这可能就值得你去花时间去思考一些新的特征量新的模型去改善这些情况,提高分类的准确度。
除此之外,我们最好能有一个单一规则的数值评价指标,能帮助我们快速分辨出某些算法适不适用于我们的模型,如果没有一个指标来评估,手动来测试好坏往往会使我们难以判断是否要用这些算法。
最后,还有一个建议就是,在你所有一切开始的时候,最好快速的先实现一个算法,不要管他是好是坏,人们一般在第一步构建上面花费太多时间即便是一个很简单的算法。快速的实现一个算法后你就可以通过误差分析等方法,快速的去改善你的算法。
3. 不对称分类的误差评估
上节课我们提到了数值评估,它可以帮助我们快速决定算法的适用性,但是如果出现偏斜类(skewed classes)问题,这种方法就很难进行判断,如下:

这个例子中是对癌症进行分类,上面原先的模型假设误差由1%,但是当我们换一个算法,就只判断是否y=0,这显然并不是一个很好的分类方法,但我们通过数值估计发现误差竟然降低了,因为上面这个偏斜类问题中,正样本数量远少于负样本数量,故我们无法很好的判断这个方法与我们原先用的模型哪个更适合。
面对这种偏斜类问题时,我们希望能有不同的误差度量值或者不同评估度量值,而其中一种误差度量值就是查准率和召回率,如下:
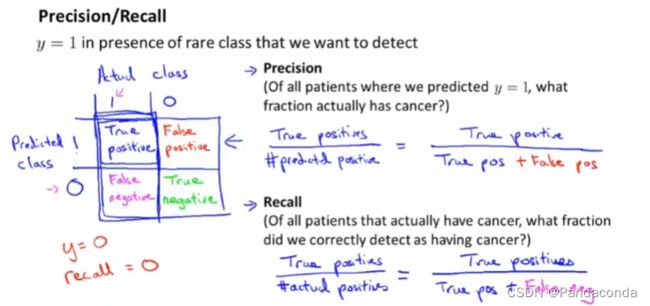
上面这种指标一般用于我们想要预测某种十分稀少的情况,比如说癌症。
而我们一般会先将所分出来的数据集划分为四个部分,分别是真阳性(True postive)即预测与实际都为1,假阳性(False postive)即预测为1但实际为0,假阴性(False negative)即预测为0但实际为1,真阴性(True negatvie)即预测与实际都为0。然后再对查准率和召回率进行定义。
查准率(Precision)
在所有预测为癌症的患者中,有多少患者是真真切切是患有癌症的。
召回率(Recall)
在所有实际患有癌症的患者中,有多少病人是你正确预测患有癌症的。
通过上面这两个度量指标,再回过去看之前那个总是预测y=0的模型,我们就可以得到它的召回率为0,因为他总是不预测是否患有癌症,故可以清楚知道这个模型并不好。
4. 查准率和召回率的权衡
通过上节课我们了解了查准率和召回率,这节课我们来学习该如何权衡这两者,在此之前我们先看下面这些情况:
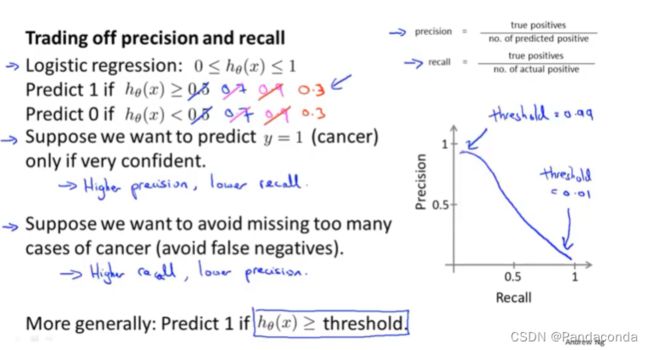
你可以通过改变临界值来得到你想要的结果:
- 如果你想有十足的把握告诉病人他得了癌症,避免误判,那么你可以设置较高的临界值例如0.7,只有当hθ(x)大于0.9,才会预测为1,这种情况下就会得到高查准率,低召回率。
- 如果你不想漏掉一些本该得了癌症的病人,那么你可以设置很低的临界值例如0.3,当hθ(x)大于0.3时,就会预测为1,这种情况下就会得到高召回率,低查准率。
所以有时候想要得到高查准率或者高召回率就要舍弃另一边的准确率,这就需要我们去权衡,可以通过画出查准率与召回率的曲线,来选择你想要的结果,那么是否一种方法可以自动的选择临界值呢。

上面我们说如果单一看一个评估数值无法很好判断算法好坏,所以引出了查准率和召回率,但是还存在一个问题,就算我们得到了这两个数值,我们也还是要花很长时间去思考去对比每个算法的查准率和召回率,这样效率仍然不高。所以我们就又要需要一个数值通过查准率和召回率帮助我们判断算法的好坏,但是如果仅算这两者的平均值,得到的结果仍然不准确,这就要引入第三个度量值F值(F score)。
这样,就算你一边很高但是另一边很低,得到的F值也会很低,从而排除掉一些极端的算法。
5. 机器学习数据
我们先来看一个例子,下面这是一个比较有影响力的研究。

通过给四个算法不断地喂训练集,然后观察它们随训练集数量的增多效果的变化,结果发现数量集越多时劣质算法竟然效果会更好,甚至比优质算法效果还要好,所以有句话就说并不是那些拥有好算法的人是赢家,赢家往往是那些手里掌握着很多数据的人,那么这句话在什么情况下是真的呢,我们来举些例子。

首先假设我们有足够多的特征信息能够准确判断y值,然后让我们去判断上面句子中的空白地方是填什么,通过大量的信息机器可能就知道这个地方要填two,而不是to或too,这样数据多看起来是一件不错的事情。
但是我们再来看一个反例,如果只给你一个特征即房屋的大小,不告诉你其它像房屋所处位置,房间个数等等信息,让你去预测房屋的价格,恐怕你有再多的数据集也无法很好的预测房屋的价格吧。
所以训练集越多效果越好是要分情况的,下面这种情况就完美的符合了。

我们可以用拥有很多参数的算法,这样我们就可以使偏差变得很低,并且训练误差会很小。
然后再通过很大的数据集去训练,这样就可以使方差变得很低,并且测试误差会接近于训练误差。
两者结合起来即解决了高偏差问题也解决了高方差问题,并且使训练误差也很低。