python的opencv使用总结
作为最容易上手之一的语言,python拥有着大量的第三方库,这些第三方库的存在使得很多人可以专注于业务逻辑、数学逻辑而忽略繁琐的代码操作,python的opencv第三方库就是其中之一。
一、第三方库的安装和简单使用
安装
简单的pip安装就可以了,opencv库的使用,很经常地涉及一些矩阵运算,所以numpy算是和它一家亲了。
pip install opencv-python
安装好了以后,就可以简单地打开图片、打开视频了,来个简单试验:
读取图片
import cv2
# 读取图像,第一种是正常读取,第二种是读取灰度图像
img = cv2.imread(r"D:\img\among.png")
gray = cv2.imread(r"D:\img\among.png", 0)
# 显示图像
cv2.imshow("colorful", img)
cv2.imshow("gray", gray)
# 不再等待键盘输入事件,直接显示
cv2.waitKey(0)
# 关闭所有显示窗口
cv2.destroyAllWindows()
显示效果如下:
读取视频并播放
import cv2
# 读取视频
video = cv2.VideoCapture('badapple_color.mp4')
# 获取视频对象的帧数
fps = video.get(cv2.CAP_PROP_FPS)
# 设定循环条件
while(video.isOpened()):
_, frame = video.read()
cv2.imshow("video", frame)
# 设置退出条件是输入'q'
if cv2.waitKey(int(fps)) in [ord('q'), 27]:
break
cv2.destroyAllWindows()
video.release()
注意:这里的播放是没有正常播放器那样的进度条和音频的,因为这里是读取的视频的每一帧,然后循环播放而已,并没有读取音频,而且设置了退出条件是输入q。

获取摄像头录像并保存视频
import cv2
video = cv2.VideoCapture(0)
while(True):
# 获取一帧
_, frame = video.read()
# 将这帧转换为灰度图
gray = cv2.cvtColor(frame, cv2.COLOR_BGR2GRAY)
cv2.imshow('frame', gray)
if cv2.waitKey(1) == ord('q'):
break
video.release()
然后它就输出持续输出摄像头排到的每一帧画面,因为读取的是灰度的,这里也是灰度的,你可以由着它正常输出,不修改,也就是注释掉cvtColor那条转换语句,顺便把imshow输出对象换回开始的frame(读取到的帧),就可以得到彩图了。


小改一下让它保存视频:
import cv2
video = cv2.VideoCapture(0)
# 定义编码方式并创建VideoWriter对象
fourcc = cv2.VideoWriter_fourcc(*'mp4v')
outfile = cv2.VideoWriter('res.mp4', fourcc, 25., (640, 480))
while(video.isOpened()):
flag, frame = video.read()
if flag:
outfile.write(frame) # 写入文件
cv2.imshow('frame', frame)
if cv2.waitKey(1) == ord('q'):
break
else:
break
video.release()
如下:

二、图像基础
计算机中的图像,由一个个带有颜色的小方块组成,这些小方块就是基本的处理单位,称为像素。它的大小取决于计算机的分辨率,分辨率越高,像素点越小。简单的二值图片,其像素点的值只有0和1,用来标识黑白两种颜色;在此更进一步的灰度图片,则是把黑白色更细腻化,使得图像生动许多,也就是表示黑白的值由0-255存储,0为纯黑,1为纯白,中间的黑白色的渐变就更加细腻了;再进一步,就是彩色图像,颜色的构成基本都是由三原色以不同的比例调和出来的,而彩色图像就是有三种值共同表示三原色的值,也就是说一个彩色图像的像素点,它的颜色由三种值共同构成,这种模式也被称为RGB色彩空间。比如[0, 0, 0]表示纯黑,[255, 255, 255]表示纯白,而[255, 0, 0]、[0, 255, 0]和[0, 0, 255]分别表示红绿蓝三原色,因此RGB色彩空间也被称为三通道,在opencv中,三通道顺序为BGR逆序。一幅彩色图像由三通道构成的矩阵而成,这也是处理彩色图的时候,常常引入Numpy来进行配合的原因。处理图像,也是考究数学的。
简单的例子:
import cv2
import numpy as np
# 黑白图
b = np.zeros((100, 100), dtype=np.uint8)
w = np.zeors((100, 100), dtype=np.uint8)
w[:100, :100] = 255
print(b, w, sep="\n\n")
cv2.imshow("black", b)
cv2.imgshow("white", w)
cv2.waitKey()
# 三个三原色图片
r = np.zeros((300, 300, 3),dtype=np.uint8)
g = np.zeros((300, 300, 3),dtype=np.uint8)
b = np.zeros((300, 300, 3),dtype=np.uint8)
r[:,:, 2] = 255
g[:,:, 1] = 255
b[:,:, 0] = 255
cv2.imshow("red", r)
cv2.imshow("green", g)
cv2.imshow("blue", b)
cv2.waitKey()
# 包含三原色的图片
img = np.zeros((300, 300, 3), dtype=np.uint8)
img[:, 0:100, 2] = 255
img[:, 100:200, 1] = 255
img[:, 200:300, 0] = 255
cv2.imshow("RGB", img)
# 红橙黄绿蓝靛紫
img = np.zeros((300, 700, 3), dtype=np.uint8)
# 红
img[:,0:100,2] = 255
# 橙
img[:,100:200,2] = 255
img[:,100:200,1] = 97
# 黄
img[:,200:300,1] = 255
img[:,200:300,2] = 255
# 绿
img[:,300:400,1] = 255
# 蓝
img[:,400:500,0] = 255
# 靛
img[:,500:600,0] = 84
img[:,500:600,1] = 46
img[:,500:600,2] = 8
# 紫
img[:,600:700,0] = 240
img[:,600:700,1] = 32
img[:,600:700,2] = 160
# 输出
cv2.imshow("seven", img)
cv2.waitKey()
输出结果就不显示了,就那样。其实想要搞个颜色对照表也可以一条通道一条通道的叠代,然后叠代完整个序列就输出,那样就有个颜色表了,不过要想准备给值还是要参考一下真正的命名。
随机图
整一个随机灰度图像,就是以前那种电视没信号的状态。
import cv2
import numpy as np
img = np.random.randint(0, 256, size=[300, 300], dtype=np.uint8)
cv2.imshow("老花", img)
cv2.waitKey()
img = np.random.randint(0, 256, size=[300, 300], dtype=np.uint8)
cv2.imshow("彩色老花", img)
cv2.waitKey()
 |
|
上面已经描述了,RGB彩图是有着三通道的,而opencv提供了通道拆分的实现
import cv2
import numpy as np
img = cv2.imread(r"D:\img\among.png")
# b, g, r = cv2.split(img) 等同
cv2.imshow("0", img[:,:,0])
cv2.imshow("1", img[:,:,1])
cv2.imshow("2", img[:,:,2])
# 同样的拆分功能
b, g, r = cv2.split(img)
# 合并成原图
img_mer = cv2.merge([b, g, r])
cv2.waitKey()
效果:

三个属性值
- shape,img.shape,表示img序列的长宽和深度,
- size ,img.size,表示像素数,行x列x通道
- dtype,图像数据类型
三、色彩空间和转换
色彩空间,表述颜色的模式,常见的色彩空间是RGB色彩空间,但在opencv中是反过来的BGR通道。除此以外的,还有GRAY即八位灰度图、XYZ色彩空间、YCrCb色彩空间、HSV色彩空间、HLS色彩空间、Bayer色彩空间。。。。。。针对不同需要的色彩空间,在需要的时候还可以进行转换,这里就是针对它们的特性和相互转换进行学习。
GRAY色彩空间
8位灰度图,对应8位二进制的数值范围就是0-255,刚好表示256个灰度,0表示纯黑,255表示纯白,中间数值就是从纯黑到纯白的渐变,所以是灰度。在opencv中,RGB色彩空间转变为GRAY这种灰度色彩空间,它的转变公式如下:
G r a y = 0.299 ∗ R + 0.587 ∗ G + 0.114 ∗ B Gray = 0.299*R+0.587*G+0.114*B Gray=0.299∗R+0.587∗G+0.114∗B
而GRAY灰度转为RGB色彩空间就比较简单,RGB三通道的值直接就是GRAY的值,也就是
$$R = Gray\G = Gray\B = Gray\$$
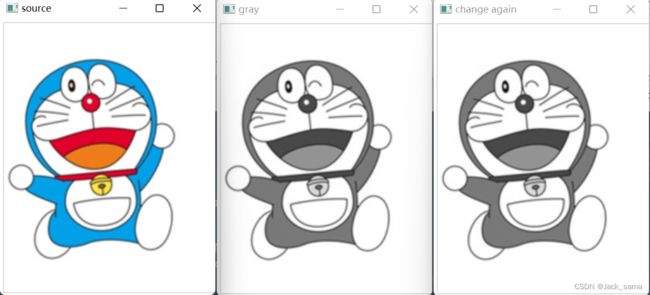
关于GRAY和BGR之间的互转,其实在opencv读取的时候就已经可以实现,在应用上暂时没啥想法,这里主要是玩一下例子。
>>> import cv2
>>> import numpy as np
>>>
>>>
>>> mong = cv2.imread("among.png")
>>> gray = cv2.cvtColor(mong, cv2.COLOR_BGR2GRAY)
>>> cv2.imshow("source", mong)
>>> cv2.imshow("gray", gray)
>>> bgr_img = cv2.cvtColor(gray, cv2.COLOR_GRAY2BGR)
>>> cv2.imshow("change again", bgr_img)
>>> cv2.waitKey()
-1
>>>
>>>
>>> img = np.random.randint(0, 256, size=[2,3], dtype=np.uint8)
>>> res = cv2.cvtColor(img, cv2.COLOR_GRAY2BGR)
>>> res_change = cv2.cvtColor(res, cv2.COLOR_BGR2GRAY)
>>> img
array([[ 48, 27, 228],
[ 94, 144, 234]], dtype=uint8)
>>> res
array([[[ 48, 48, 48],
[ 27, 27, 27],
[228, 228, 228]],
[[ 94, 94, 94],
[144, 144, 144],
[234, 234, 234]]], dtype=uint8)
>>> res_change
array([[ 48, 27, 228],
[ 94, 144, 234]], dtype=uint8)
>>>
玩脱了,没有转换回来原本的颜色。
YCrCb色彩空间
针对人眼视觉系统,由于人对颜色的感知要低于对光线亮度的感知,而RGB色彩空间专注于颜色,就少了亮度这一指标,所以有了YCrCb色彩空间。在这种色彩空间里,Y表示光源亮度,Cr表示红色分量,Cb表示蓝色分量。关于RGB转换成YCrCb的转换公式为:
Y = 0.299 ∗ R + 0.587 ∗ G + 0.114 ∗ B C r = ( R − Y ) × 0.713 + d e l t a C b = ( B − Y ) × 0.564 + d e l t a Y = 0.299*R + 0.587*G + 0.114*B \\ Cr = (R-Y)\times0.713+delta\\Cb=(B-Y)\times0.564+delta Y=0.299∗R+0.587∗G+0.114∗BCr=(R−Y)×0.713+deltaCb=(B−Y)×0.564+delta
关于delta的值,对应不同数位图像有不同的值:
| delta值 | 图像数位 |
|---|---|
| 128 | 8位 |
| 32768 | 16位 |
| 0.5 | 单精度图像 |
| 反过来从YCrCb转换成RGB的公式则是: |
R = Y + 1.403 ⋅ ( C r − d e l t a ) G = Y − 0.714 ⋅ ( c r − d e l t a ) − 0.344 ⋅ ( C b − d e l t a ) B = Y + 1.773 ⋅ ( C b − d e l t a ) R=Y+1.403\cdot(Cr-delta)\\G=Y-0.714\cdot(cr-delta)-0.344\cdot(Cb-delta)\\B=Y+1.773\cdot(Cb-delta) R=Y+1.403⋅(Cr−delta)G=Y−0.714⋅(cr−delta)−0.344⋅(Cb−delta)B=Y+1.773⋅(Cb−delta)
它也叫YUV,Y表示亮度,U和V表示色度,在做肤色检测上比HSV要好。
HSV色彩空间
听说是针对视觉感知的颜色模型,在这个色彩空间里面,有着色调、饱和度、亮度三要素,色调是光的颜色,饱和度是色彩的深浅,亮度是人眼感受到的光的明暗。
- 色调H,红黄绿青蓝红六种颜色对应圆周360度(所以才说这些创造概念的人就喜欢让人费解);
- 饱和度S,一个比例,也就是一个小数,范围时从0到1,表示颜色所占其颜色的最大纯度的比例,饱和度为0就是灰色,最大也就是1是这个颜色本身;
- 亮度V,色彩明亮程度,同样是[0, 1]的取值范围。
RGB转换为HSV的公式如下:
V = m a x ( R , G , B ) 亮 度 : S = { V − m i n ( R , G , B ) , V ≠ 0 0 , 其 他 色 调 : H = { 60 ( G − B ) v − m i n ( R , G , B ) , V = R 120 + 60 ( B − G ) V − m i n ( R , G , B ) , V = G 240 + 60 ( R − G ) V − m i n ( R , G , B ) , V = B 色 调 : H = { H + 360 , H < 0 H , 其 他 V = max(R, G, B)\\亮度: S= \begin{cases} V-min(R, G, B), &V\ne0\\ 0,&其他 \end{cases}\\色调: H= \begin{cases} \cfrac{60(G-B)}{v-min(R, G, B)},&V=R\\ 120+\cfrac{60(B-G)}{V-min(R, G, B)}, &V=G\\ 240+\cfrac{60(R-G)}{V-min(R, G, B)}, &V=B \end{cases}\\色调: H= \begin{cases} H+360,&H<0\\ H,&其他 \end{cases} V=max(R,G,B)亮度:S={V−min(R,G,B),0,V=0其他色调:H=⎩⎪⎪⎪⎪⎪⎪⎨⎪⎪⎪⎪⎪⎪⎧v−min(R,G,B)60(G−B),120+V−min(R,G,B)60(B−G),240+V−min(R,G,B)60(R−G),V=RV=GV=B色调:H={H+360,H,H<0其他
上面就是RGB转换成HSV的公式,真可谓是贼麻烦了,知道原理也是为了方便调试,实际上都可以由opencv的内部函数给搞定了,只需要关心上面重要的三要素意义即可。
>>> rgb_b = np.ones((2, 3, 3), dtype=np.uint8)
>>> rgb_g = np.ones((2, 3, 3), dtype=np.uint8)
>>> rgb_r = np.ones((2, 3, 3), dtype=np.uint8)
>>> rgb_b[:, :, 0], rgb_g[:, :, 1], rgb_r[:, :, 2] = 255, 255, 255
>>> hsv_b = cv2.cvtColor(rgb_b, cv2.COLOR_BGR2HSV)
>>> hsv_g = cv2.cvtColor(rgb_g, cv2.COLOR_BGR2HSV)
>>> hsv_r = cv2.cvtColor(rgb_r, cv2.COLOR_BGR2HSV)
>>> rgb_b
array([[[255, 1, 1],
[255, 1, 1],
[255, 1, 1]],
[[255, 1, 1],
[255, 1, 1],
[255, 1, 1]]], dtype=uint8)
>>> hsv_b
array([[[120, 254, 255],
[120, 254, 255],
[120, 254, 255]],
[[120, 254, 255],
[120, 254, 255],
[120, 254, 255]]], dtype=uint8)
>>> rgb_g
array([[[ 1, 255, 1],
[ 1, 255, 1],
[ 1, 255, 1]],
[[ 1, 255, 1],
[ 1, 255, 1],
[ 1, 255, 1]]], dtype=uint8)
>>> hsv_g
array([[[ 60, 254, 255],
[ 60, 254, 255],
[ 60, 254, 255]],
[[ 60, 254, 255],
[ 60, 254, 255],
[ 60, 254, 255]]], dtype=uint8)
>>> rgb_r
array([[[ 1, 1, 255],
[ 1, 1, 255],
[ 1, 1, 255]],
[[ 1, 1, 255],
[ 1, 1, 255],
[ 1, 1, 255]]], dtype=uint8)
>>> hsv_r
array([[[ 0, 254, 255],
[ 0, 254, 255],
[ 0, 254, 255]],
[[ 0, 254, 255],
[ 0, 254, 255],
[ 0, 254, 255]]], dtype=uint8)
>>>
HLS色彩空间
和HSV色彩空间类似,不过HLS色彩空间三要素为:色调H、亮度L、饱和度S,文中是这么描述的,所以不同在哪?描述亮度的单词吗?无语。
类型转换函数
上面的各种色彩空间与RGB色彩空间的转换,在opencv提供的类型转换函数中都可以实现。
dst = cv2.cvtColor(src, code[, dstCn])
针对不同的类型转换,传入不同的code参数值,而dstCn是目标图像的通道数,默认为0,然后通道数会自动通过原始图像和code确定。
| code值 | 解析 |
|---|---|
| cv2.COLOR_BGR2RGB | opencv中BGR类型转为RGB类型 |
| cv2.COLOR_RGB2BGR | opencv中RGB类型转为BGR类型 |
| cv2.COLOR_BGR2GRAY | BGR转为GRAY |
| cv2.COLOR_GRAY2BGR | GRAY转为BGR |
| cv2.COLOR_BGR2XYZ | BGR转为XYZ |
| cv2.COLOR_XYZ2BGR | XYZ转为BGR |
| cv2.COLOR_BGR2YCrCb | BGR转为YCrCb |
| cv2.COLOR_YCrCb2BGR | YCrCb转为BGR |
| cv2.COLOR_BGR2HSV | BGR转为HSV |
| cv2.COLOR_HSV2BGR | HSV转为BGR |
| cv2.COLOR_BGR2HLS | BGR转为HLS |
| cv2.COLOR_BayerBG2BGR | 逆马赛克,也是Bayer的BG模式 |
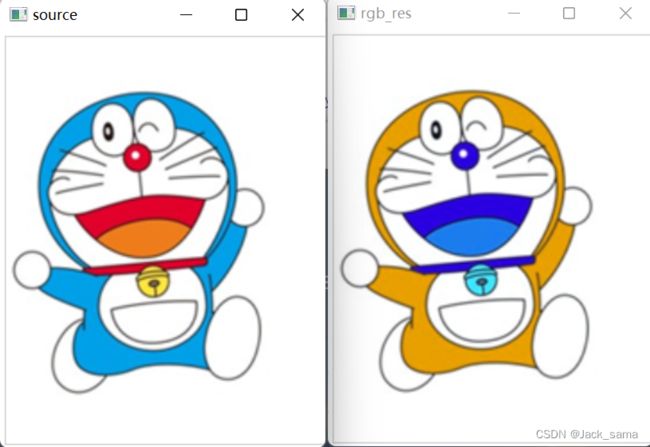
在上面的参数中,出现了RGB和BGR的互转,在opencv中,通道的顺序一般是BGR,是逆序的,那这个RGB的转换会咋样?实践操作的结果来看,会使得B、R两通道的值互相替换,就是两条通道换了过来,但opencv渲染图片还是那个通道顺序,所以如果显示图片,颜色就会发生变化。
>>> import cv2
>>> import numpy as np
>>>
>>>
>>> img = np.random.randint(0, 256, size=(2, 3, 3), dtype=np.uint8)
>>> rgb_img = cv2.cvtColor(img, cv2.COLOR_BGR2RGB)
>>> img
array([[[ 69, 184, 11],
[193, 4, 194],
[239, 139, 146]],
[[188, 30, 44],
[ 60, 145, 133],
[ 46, 181, 139]]], dtype=uint8)
>>> rgb_img
array([[[ 11, 184, 69],
[194, 4, 193],
[146, 139, 239]],
[[ 44, 30, 188],
[133, 145, 60],
[139, 181, 46]]], dtype=uint8)
>>> mong = cv2.imread("among.png")
>>> rgb_mong = cv2.cvtColor(mong, cv2.COLOR_BGR2RGB)
>>> cv2.imshow("source", mong)
>>> cv2.imshow("rgb_res", rgb_mong)
>>> cv2.waitKey()
-1
从上面的矩阵和下面图片的变化就能很清楚地看出内部变化和宏观变化,就算是替换了两通道,opencv的默认图片的通道顺序应该是没有变化,或者说imshow这一函数的内部规则依然是从bgr的通道顺序,从而使得图片颜色不一。
抽取特定颜色
针对图片中的特定颜色块,在我们需要的时候,可以叠代图片并产出一个只包含该颜色块的图片,比如上面的哆啦A梦的颜色分区就很明显,很适合用来进行这个尝试。另外,这个想法的实现是依赖于opencv的inRange函数。
dst = cv2.inRange(src, lowerb, upperb)
上面的函数就是针对图片中[lowerb, upperb]这一区域的颜色进行抽取,不过要注意的是,如果是灰度图片,lowerb就只是一个整型值就行,但如果是一个RGB颜色空间的图片,lowerb就需要一个矩阵来描述颜色了,upperb同上。嗯,不过三通道共同表述颜色这种针对硬件的特性,实在是让我头疼,在HSV中,表述颜色的只有一种,这种就很对用户胃口,好,用这个试试。
>>> import cv2
>>> import numpy as np
>>>
>>> mong = cv2.imread("among.png")
>>> mong_hsv = cv2.cvtColor(mong, cv2.COLOR_BGR2HSV)
>>> bmin, bmax = np.array((100, 43, 46)), np.array((125, 255, 255))
>>> mask = cv2.inRange(mong_hsv, bmin, bmax)
>>> blue = cv2.bitwise_and(mong, mong, mask=mask)
>>> ymin, ymax = np.array((26, 43, 46)), np.array((34, 255, 255))
>>> ymask = cv2.inRange(mong_hsv, ymin, ymax)
>>> rmin, rmax = np.array((0, 43, 46)), np.array((10, 255, 255))
>>> rmask = cv2.inRange(mong_hsv, rmin, rmax)
>>> yellow = cv2.bitwise_and(mong, mong, mask=ymask)
>>> red = cv2.bitwise_and(mong, mong, mask=rmask)
>>> cv2.imshow("source", mong)
>>> cv2.imshow("blue", blue)
>>> cv2.imshow("yellow", yellow)
>>> cv2.imshow("red", red)
>>> cv2.waitKey()
-1

上面是根据搜到的这个HSV的对照表进行的实验,应该图片中的颜色不是完全按照正规的颜色对照而来,所以得到的也是颜色块的碎碎块块,实在让人心累。
不过针对水印的提取倒是让我在这部分有意外的收获。
>>> import cv2
>>> import numpy as np
>>>
>>>
>>> watermark = img[850:, 580:]
>>> wm_abstract = cv2.inRange(watermark, (230, 230, 230), (255, 255, 255))
>>> cv2.imshow("source", img)
>>> cv2.imshow("watermark_part", watermark)
>>> cv2.imshow("watermark", wm_abstract)
>>> cv2.waitKey()
-1
>>>
这样就算提取出来了水印的那部分,对于这种纯色的水印,RGB的inRange反而更好用的感觉。

肤色标记和检测
和上面的确定颜色范围一致,对应人类照片进行肤色的颜色范围进行标记,然后就可以得到对应区域,然后抽取,书本中用的是HSV进行,不过有资料说YCrCb应用这种场景更好,我看看能不能两个都试试。
书本中把肤色的色调和饱和度定在[5, 170]和[25, 166]之间,我不确定是否是针对书中例子图片,但就先用着,虽然我用其他图片做实验.
>>> import cv2
>>> import numpy as np
>>>
>>>
>>> img = cv2.imread("eason.png")
>>> hsv = cv2.cvtColor(img, cv2.COLOR_BGR2HSV)
>>> h, s, v = cv2.split(hsv)
>>> hmask = cv2.inRange(h, 5, 170)
>>> smask = cv2.inRange(s, 25, 166)
>>> mask = hmask & smask
>>> roi = cv2.bitwise_and(img, img, mask=mask)
>>> cv2.imshow("source", img)
>>> cv2.imshow("skin", roi)
>>> cv2.waitKey()
-1
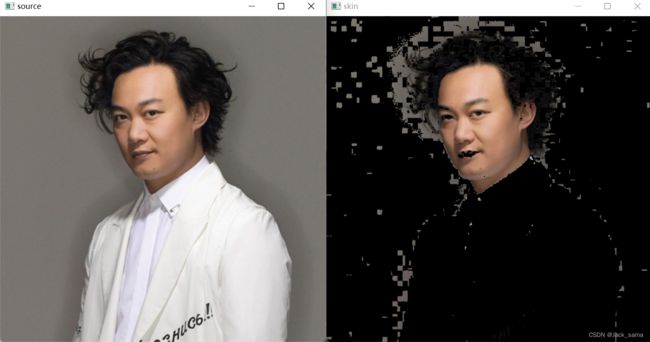
就结果来看,肤色的检测还是可以的,接下来试试YCrCb的检测。上面的效果来看的话,其实边缘部分没处理好,所以下面使用opencv的四种模糊技术之一的高通滤波。
# 引入部分和上面的一致
>>> ycrcb = cv2.cvtColor(img, cv2.COLOR_BGR2YCrCb)
>>> y, cr, cb = cv2.split(ycrcb)
>>> cr = cv2.GaussianBlur(cr, (5, 5), 0)
>>> _, skin = cv2.threshold(cr, 0, 255, cv2.THRESH_BINARY+cv2.THRESH_OTSU)
>>> cv2.imshow("res", skin)
>>> cv2.imshow("source", img)
>>> cv2.waitKey()
-1

效果还是蛮不错的,但七窍通了六窍的我只能照抄例子来进行,没办法得到有颜色的图片。
alpha通道
在RGB色彩空间基础上,添加A通道,表示透明或者不透明,这就是RGBA色彩空间。A通道的取值范围可以是[0, 1]也可以是[0, 255]。在常见的图像处理中,一般都是RGB三通道,所以要使用RGBA色彩空间就需要cvtColor进行转换。这里只是进行一下记录,并不拓展。
四、图像运算
据说,啊据说啊,图像的加法运算、位运算是针对图像的位平面分解、图像异或加密、数字水印、脸部加码/解码等使用的。那如果想要逆向,那就暂时不清楚了。这一部分的处理暂时都以python的交互式编程作为演示。
加法运算
主要有两种,一种是简单的+运算符引领的加法,另一种是opencv提供的add加法函数。描述一下规则:
- 加号运算符,在图像a和图像b使用简单的加号运算符进行加号运算时,它们的结果一旦超过灰度最大值255,就把这个值对256进行取模,加法的值就是这个余数,没有超出就正常运算。
a + b { a + b , a + b ≤ 255 m o d ( a + b , 256 ) , a + b > 255 a+b \begin{cases} a+b,&a+b\le255\\ mod(a+b, 256),&a+b>255 \end{cases} a+b{a+b,mod(a+b,256),a+b≤255a+b>255- cv2.add(a, b),图像a和图像b用这个函数进行加法运算,和上面的加号运算符主导的加法一样,同样有两种结果,第一种就是当两者之和大于255,那就让它作为最大值保留,255就是饱和值,封顶了;如果没有大于255,就正常相加。
c v 2. a d d ( a , b ) { a + b , a + b ≤ 255 255 , a + b > 255 cv2.add(a, b) \begin{cases} a+b, &a+b\le255\\ 255, &a+b>255 \end{cases} cv2.add(a,b){a+b,255,a+b≤255a+b>255
来个简单例子
import cv2
import numpy as np
# 灰度图模式读取
img = cv2.imread('among.png', 1)
# 加法处理
a = img + img
b = a + a
c = cv2.add(img, img)
c = cv2.add(c, c)
cv2.imshow("a", a)
cv2.imshow("b", b)
cv2.imshow("c", c)
cv2.imshow("d", d)
cv2.waitKey()
运算结果如下:

a和b都是进行加法运算符的图像加法,c和d则是用cv2的add函数进行加法运算,可以明显看得出来,前者在越来越进一步的加法运算中,线条感更明显,有颜色的越来越黑,而后者则是反过来,越来越饱和,显得越来越白。这是一个对于图像的简单处理,但如果是两个图像之间乃至数值和图像之间的处理就不甚明了,因为没有参考。
加权和
加权和,是在计算两图像像素值之和时,把图像权重的要素也考虑进去。两个进行加权和的图像,需要大小、类型相同,但通道和具体是什么类型没有要求。不过找到的博客资料基本都是照本宣科,没有适合人类参考的说法,mdzz。暂时这里也照抄书本概念吧,上公式:
d s t = s a t u r a t e ( s r c 1 × α + s r c 2 × β + γ ) dst = saturate(src1\times\alpha + src2\times\beta+\gamma) dst=saturate(src1×α+src2×β+γ)
这个加权和的实现是用的opencv中的函数addWeighted,对应上面公式,它也要传入五个参数:src1、alpha、src2、beta、gama,所谓权重在我看来就是两个图像所占比例,在最后的图像的结果来看谁更明显,所以上面可以理解成:结果图=图像1x系数1+图像2x系数2+亮度调节量。
简单的图片混合例子:
import cv2
import numpy as np
a = cv2.imread('blena.png')
b = cv2.imread('bboat.png')
c = cv2.addWeighted(a, 0.2, b, 0,8, 0)
d = cv2.addWeighted(a, 0.5, b, 0,5, 0)
e = cv2.addWeighted(a, 0.8, b, 0,2, 0)
cv2.imshow("c", c)
cv2.imshow("d", d)
cv2.imshow("e", e)
cv2.waitKey()
因为实在没资源,我只好百度书本上的两张图来截图保存来做实验,然后按照人脸像所占比例越来越大来进行显示,结果如下:

结果很明显,随着人脸像的比例越来越大,图片人脸也越来越明显,这就是混合图像的例子,听说如果大小不一样的图像,可以使用resize来进行调整,再试一下。换了一下图片,然后代码调整为:
import cv2
import numpy as np
a = cv2.imread("ayanamirei.jpg")
b = cv2.imread("asikaj.jpg")
# 比例调整大小,本来size并不一样,但调整后以外发现一致了,应该是算法问题
a = cv2.resize(a, None, fx=0.1, fy=0.1, interpolation=cv2.INTER_LINEAR)
b = cv2.resize(b, None, fx=0.1, fy=0.1, interpolation=cv2.INTER_LINEAR)
c = cv2.addWeighted(a, 0.2, b, 0.8, 0)
d = cv2.addWeighted(a, 0.5, b, 0.5, 0)
e = cv2.addWeighted(a, 0.8, b, 0.2, 0)
cv2.imshow("c", c)
cv2.imshow("d", d)
cv2.imshow("e", e)
cv2.waitKey()
调整效果以外得好,然后又能够进行混合图像处理了。得到的彩图如下:
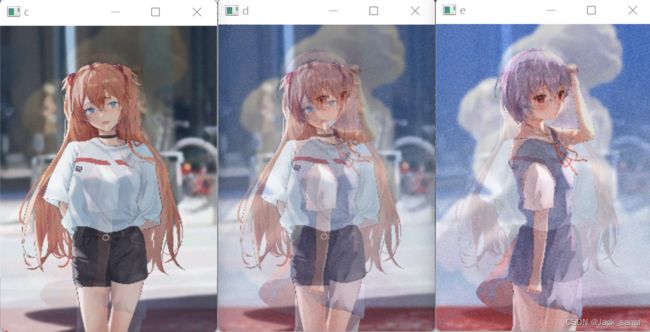
相对来说,应该0.4和0.3的比例是比较好的,在背景不是那么明显的情况下,清底应该比较好。resize最后的参数的选择对出图影响非常大:
- INTER_NEAREST:最近邻插值
- INTER_LINEAR:线性插值(默认)
- INTER_AREA:区域插值
- INTER_CUBIC:三次样条插值
- INTER_LANCZOS4:Lanczos 插值
缩小时推荐使用 cv2.INTER_AREA;扩展放大时推荐使用 cv2.INTER_CUBIC 和 cv2.INTER_LINEAR
按位逻辑运算
关于逻辑运算,存在与或非、异或等运算,这里的按位逻辑运算,就是把一个数转换成二进制数,每一个对应位的数进行逻辑运算。具体逻辑运算没有展开的必要,不做记录。opencv提供的按位逻辑运算函数分别是:
- 按位与,dst = cv2.bitwise_and(src1, src2[, mask])
- 按位或,dst = cv2.bitwise_or(src1, src2[, mask])
- 按位非,dst = cv2.bitwise_not(src[, mask])
- 按位异或,dst = cv2.bitwise_xor(src1, src2[, mask])
mask,可选操作掩码,8位单通道array值
按位与运算的使用
针对按位与运算,当处理灰度图像时,像素点与数值0按位与,得到的只有0,与255按位与得到的是本来的值,当一个具有大量0值和255值的图像与其按位与,得到的就是一个部分被"黑化"的图像,就像被抠掉了一样。说白了就是用另一个图像来对目标图像进行部分乃至全部遮挡。
import cv2
import numpy as np
img = cv2.imread("blena.png")
# 制作一个和原图同尺寸的数组
mask = np.zeros(img.shape, dtype=np.uint8)
# 固定区域设置纯白
mask[100:280, 100:250] = 255
a = cv2.bitwise_and(img, mask)
# 三图进行显示
cv2.imshow("source", img)
cv2.imshow("mask", mask)
cv2.imshow("res", a)
cv2.waitKey()
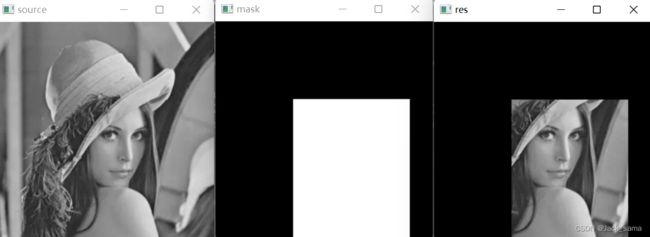
嗯,除了按位与运算的应用外,暂时另外两三个好像没啥子应用。不过要注意的是,两个进行按位逻辑运算的矩阵,应当是相同size的,不然会出错。所以有很多使用的时候会调整图片的大小。
位平面的分解
彩图根据RGB三通道可以拆分成三个矩阵,这是通道的拆解;把图像位于同一比特位上的像素进行组合,得到的图像,又被称为位平面,这个过程就叫位平面的分解。在灰度图中,一个像素点的值的范围为0-255,是一个字节8bit的范围,每个位上的值抽取出来,得到一个位平面,加上原图,一共会有9张图。如果把彩图进行位平面的分割,未免就太多了。所以这里的例子只是灰度图,这样好搞一点。
针对一个灰度图片,展开成二进制数并切割处位平面的情况下,位平面所在数位的权重越高,位平面和原图的相关性就越高,相对的,位平面所在数位的权重越低,对应的和原图的相关性就越低。说白了,就是2的0次方对应数位切出去的位平面就越看不出原图的痕迹,2的7次方对应数位切出去的位平面就越是和原图相似。
针对RGB彩图,它拆成三通道,三通道对应的颜色也是一个8位二进制数,将他们拆成三通道然后同步对应数位切出一个基于通道的位平面,再组合起来,也就是原图的位平面。嗯,好像彩图的位平面分割也不是太难。
位平面分割步骤:
- 抽取原图宽和高,构造一个同样规模的矩阵;
- 把上面矩阵构造成一个像素点的值均为 2 n 2^n 2n的矩阵做提取用;
- 将提取矩阵和原图做按位与运算得到位平面
- 为了让对应数位较小的位平面不至于显示成纯黑,需要对其进行阈值化处理,使得最后得到的只有0后者255这样非黑即白的值,或者说是非真既假
import cv2
import numpy as np
img = cv2.imread("alian.jpg", 0)
img = cv2.resize(img, None, fx=0.4, fy=0.4, interpolation=cv2.INTER_LINEAR)
cv2.imshow("source", img)
w, h = img.shape
# 创建8层同规模的矩阵,每个矩阵用来放置对应数位的提取矩阵,在后面的循环中给对应矩阵赋值
arrays = np.zeros((w, h, 8), dtype=np.uint8)
for i in range(8):
x[:, :, i] = 2**i
# 循环对原图进行按位与运算提取位平面,然后进行阈值处理,最后输出图像
for i in range(8):
temp = cv2.bitwise_and(img, x[:, :, i])
# 将temp中大于0的值转为True,除此以外的值转换为False
mask = temp>0
# 将temp中True换成255
temp[mask] = 255
cv2.imshow("res"+str(i+1), temp)
cv2.waitKey()
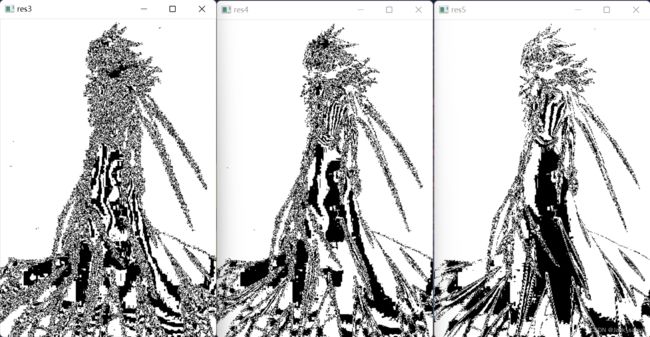

从上面就可以看得很清楚,关于一个灰度图的位平面抽取和显示(用的是阿连的头像,可惜太白了,而且本体太大了,需要修改尺寸),这样一来,想要处理彩图,在上面的过程中添加彩图拆分三通道和最后合成三通道即可。如下:
import cv2
import numpy as np
img = cv2.imread("alian.jpg")
img = cv2.resize(img, None, fx=0.4, fy=0.4, interpolation=cv2.INTER_LINEAR)
cv2.imshow("source", img)
w, h = img.shape[:2]
b, g, r = cv2.split(img)
b_arr = np.zeros((w, h, 8), dtype=np.uint8)
g_arr = np.zeros((w, h, 8), dtype=np.uint8)
r_arr = np.zeros((w, h, 8), dtype=np.uint8)
for i in range(8):
b_arr[:, :, i], g_arr[:, :, i], r_arr[:, :, i] = 2**i, 2**i, 2**i
for i in range(8):
t1 = cv2.bitwise_and(b, b_arr[:, :, i])
t2 = cv2.bitwise_and(g, g_arr[:, :, i])
t3 = cv2.bitwise_and(r, r_arr[:, :, i])
mask1 = t1 >0
mask2 = t2 >0
mask3 = t3 >0
t1[mask1], t2[mask2], t3[mask3] = 255, 255, 255
temp = cv2.merge([t1, t2, t3])
cv2.imshow("res"+str(i+1), temp)
cv2.waitKey()


水印
各大网站都很注视自己的版权问题,恨不得打上各种印记,图像上的水印就是一个体现,有时候是你上传上去的,到了网站上面,显示出来,就有了人家的印记,就很恶心。不过针对私人而言,这也是要保护的知识产权的一部分,是个公说公有理婆说婆有理的事。
上面有介绍位平面是一幅图像的像素点基于同一二进制上数位的数值集合,数位越大,对应的位平面图像就越是贴合原图,数位越小就越是和原图相差大。因此在二进制数中最低位也就是2的0次方位,也叫最低有效位(LSB, Least Significant Bit),而当把信息存在这个数位上,再合进原来的图像,这个信息就成了隐藏信息,水印就属于这种隐藏信息。那如何做到?
首先就是读取需要加水印的图片和一个水印清晰的图片,把后者的最低有效位对应位平面提取,然后根据图片尺寸进行适当或放大或缩小的调整,再粘贴到需要添加水印的图片上,这一步的进行可以使用cv2的加权和函数也可以用PIL的粘贴函数。
自制水印图
首先,因为我没有水印的原图,所以就想生成两张带有自己标签的水印原图,分别是黑底白字和白底黑字两张。关于生成黑底图和白底图是很简单的,像素值为0就是纯黑,像素值为255就是纯白,至于添加文字,就可以用cv2自带的putText函数。来,开造。
import cv2
import numpy as np
# 制造黑色和白色背景
black_w = np.zeros((300, 450), dtype=np.uint8)
white_b = np.ones((300, 450), dtype=np.uint8)*255
# 调用putText函数添加手写体的标签,距离左上角150的位置,字体大小为3,粗细为3
cv2.putText(black_w, 'JackSAMA', (0, 150), cv2.FONT_HERSHEY_SCRIPT_SIMPLEX, 3, 255, 2)
cv2.putText(white_b, 'JackSAMA', (0, 150), cv2.FONT_HERSHEY_SCRIPT_SIMPLEX, 3, 0, 2)
cv2.imshow("black", black_w)
cv2.imshow("white", white_b)
cv2.waitKey()

水印图片就制作好了,其实还可以根据实际情况来进行生成,只要定制好水印函数就好,还能根据图片大小来进行调节,当然,有实图也可以同步调整。关于putText的函数参数主要如下:
img = cv2.putText(img, text, org, fontFace, fontScale, color[, thickness[, lineType[, bottomLeftOrigin]]])
img, 操作图像对象
text,添加的文本,一般都是英文,中文使用会乱码,暂时也还没解决
fontFace,用过标签语言的应该都知道这是字体类型的意思
fontScale,字体大小
color,对于灰度图,简单的0-255表示即可,如果是rgb彩图就要适用(b, g, r)进行表示
thickness,线条粗细,默认是1
lineType,线条类型,默认是8连接类型
bottomLeftOrigin,默认为False,这样文本就是横着来;输入为True就是文本竖着来
| fontFace | 解析 |
|---|---|
| cv2.FONT_HERSHEY_SIMPLEX | 正常的sans-serif字体,就是常用的英文字体 |
| cv2.FONT_HERSHEY_PLAIN | 小号sans-serif字体 |
| cv2.FONT_HERSHEY_DUPLEX | 正常大小的sans-serif |
| cv2.FONT_HERSHEY_COMPLEX | 正常的serif字体 |
| cv2.FONT_HERSHEY_TRIPLEX | 正常大小的serif字体 |
| cv2.FONT_HERSHEY_COMPLEX_SMALL | serif简化版 |
| cv2.FONT_HERSHEY_SCRIPT_SIMPLEX | 手写风格的字体 |
| cv2.FONT_HERSHEY_SCRIPT_COMPLEX | 手写字体复杂版 |
| cv2.FONT_ITALIC | 斜体标记 |
| lineType | 解析 |
|---|---|
| cv2.FILLED | 填充型 |
| cv2.LINE_4 | 4连接型 |
| cv2.LINE_8 | 8连接型 |
| cv2.LINE_AA | 抗锯齿,让线条更平滑 |
上面就是opencv中字体参数和线条类型的一些解读,听说能换进去自我设计得库,不知道具体怎样。不过好像加了个抗锯齿的线条参数看起来舒服多了。
嵌入水印
把水印给添加到哆啦a梦的图片上去。
>>> import cv2
>>> import numpy as np
>>>
>>> mong = cv2.imread("among.png")
>>> mong.shape
(347, 272, 3)
>>> watermark = cv2.imread("white_black_sign.png")
>>> watermark.shape
(300, 450, 3)
# 调整水印原图大小和对应待处理图片补充空白
>>> watermark = cv2.resize(watermark, None, fx=0.3, fy=0.3, interpolation=cv2.INTER_AREA)
>>> cv2.imshow("", watermark)
>>> cv2.waitKey()
-1
>>> watermark.shape
(90, 135, 3)
>>> temp = np.ones(mong.shape, dtype=np.uint8)*255
>>> temp[210:300, 137:272] = watermark
>>> cv2.imshow("", temp)
>>> cv2.waitKey()
-1
# 进行加权和拼接,实现图片添加水印
>>> res1 = cv2.addWeighted(mong, 0.9, temp, 0.1, 0)
>>> cv2.imshow("", res1)
>>> cv2.waitKey()
-1
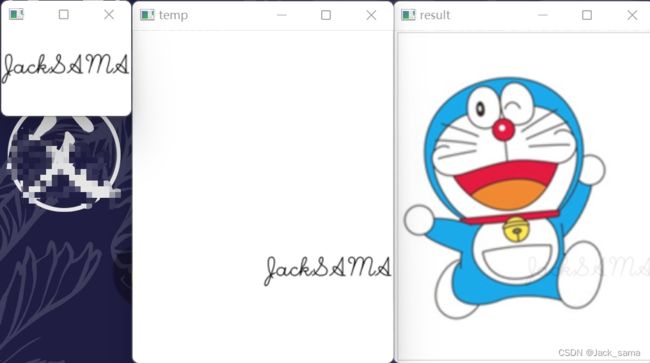
去水印
很多去水印的办法,都是让美工给搞一张纯色的像我上面生成的那种水印图,然后再来识别颜色范围,再来给两图合并,也就是给paste上去,所以有不少使用是用到PIL库的
import cv2
import PIL import Image
import numpy as np
img = cv2.imread("./iamfine.png")
h, w, _ = img.shape[0:3]
#切割,根据实际水印位置而定,[y0:y1, x0:x1]为下面裁剪用法,裁剪完后可以用上面的方法输出查看一下
cropped = img[int(h*0.9):h, int(w*0.75):w]
# 对图片进行阈值化处理,把由后面两个参数划定的RGB色彩空间范围外的色彩输出为0或者255,由图片底色确定这个范围
thresh = cv2.inRange(cropped, np.array([230, 230, 230]), np.array([250, 250, 250]))
#创建结构和尺寸的数据元素
kernel = np.ones((3, 3), np.uint8)
# 扩展待修复区域
watermask = cv2.dilate(thresh, kernel, iterations=10)
specular = cv2.inpaint(cropped, watermask, 5, flags=cv2.INPAINT_TELEA)
#保存去除水印的残图
cv2.imwrite("new.png", specular)
# 用PIL的paste函数把残图粘贴在原图上得到新图
i = Image.open("./img/iamfine.png")
i2 = Image.open("./img/new.png")
i2.paste(i, (int(w*0.75), int(h*0.9), w, h))
i2.save("final.png")
两图对比:
 |
|
其实用上面给添加水印的方法反推就行。
生成字符图片
图片是由一个个像素点构成的,而计算机存储图片一样是用的二进制存储,而存储像素点用到的比特位就是图片的深度,用1bit来存储,图片要么是黑要么是白,因为它只有0和1的选择;用一字节(8bit)来存储那就是0-255的值。颜色有三原色:红绿蓝,这三色可以交叠在一起表示其他颜色,而这个图片的像素点的颜色的确定就是有RGB三色确定,一般称为三通道,因为它们分别用三个字节分别表示三原色的单独的值,叠在一起就是该像素点的颜色,是以像素点的表示通常是(0-255,0-255,0-255)。
而我们要生成的字符图片,其实就是要建立一个像素点到字符的映射,因为字符集也是很大的,就连最基本的ASCII集也是128个字符,不过,我们也可以不需要用那么多,我们可以用一些简单字符凑成一个字符集,然后与像素点的颜色表配对即可(因为映射规则是自定义的嘛)。
道理是这样,不过别人的例子我没有悟透,倒是另外一个方法让我有了收获,那就是先将图片转换成灰度图,那就是黑白色图片了,这时候像素点转换成字符会简单很多。
简单操作如下:
import cv2
import numpy as np
str = "#+-."
img = cv2.imread("among.png", 0)
# 此时就只有height和width两个值,没有depth
h, w = img.shape[0:2]
for_change = np.ndarray([h, w])
font = cv2.FONT_HERSHEY_SIMPLEX
for i in range(0, h, 5):
for j in range(0, w, 5):
t = str[round(3-img[i, j]/255*3)]
cv2.putText(for_change, t, (j, i), font, 0.1, color=(255, 255, 255))
cv2.imshow("", for_change)
cv2.waitKey(0)
cv2.imwrite("asciiPic.png", for_change)
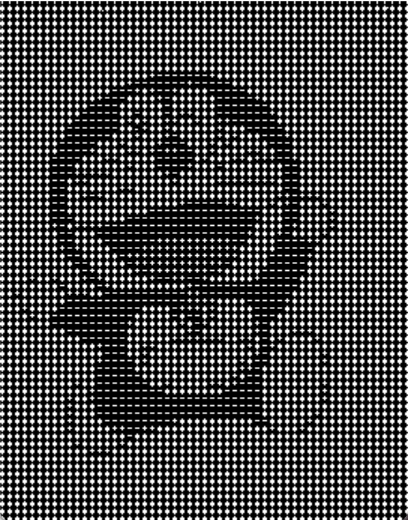
嗯,好歹是实现了,不过这种有点问题,那就是连带着底图也一起更换了,然后就有点伤眼。
生成字符视频
因为视频就是一帧一帧的图片,所以生成字符图片就走完了生成字符视频一半的路,把上面的逻辑进行叠代就可以生成字符视频了。
import cv2
import numpy as np
def pixel2char(pixel):
char_list = "@#$%&erytuioplkszxcv=+---. "
index = int(pixel / 256 * len(char_list))
return char_list[index]
def get_char_img(img, scale=4, font_size=5):
# 调整图片大小
h, w = img.shape
re_im = cv2.resize(img, (w//scale, h//scale))
# 创建一张图片用来填充字符
char_img = np.ones((h//scale*font_size, w//scale*font_size), dtype=np.uint8)*255
font = cv2.FONT_HERSHEY_SIMPLEX
# 遍历图片像素
for y in range(0, re_im.shape[0]):
for x in range(0, re_im.shape[1]):
char_pixel = pixel2char(re_im[y][x])
cv2.putText(char_img, char_pixel, (x*font_size, y*font_size), font, 0.5, (0, 0, 0))
return char_img
def generate(input_video, output_video):
# 1、读取视频
cap = cv2.VideoCapture(input_video)
# 2、获取视频帧率
fps = cap.get(cv2.CAP_PROP_FPS)
# 读取第一帧,获取转换成字符后的图片的尺寸
ret, frame = cap.read()
char_img = get_char_img(cv2.cvtColor(frame, cv2.COLOR_BGR2GRAY), 4)
# 创建一个VideoWriter,用于保存视频
fourcc = cv2.VideoWriter_fourcc(*'mp4v')
writer = cv2.VideoWriter(output_video, fourcc, fps, (char_img.shape[1], char_img.shape[0]))
while ret:
# 读取视频的当前帧,如果没有则跳出循环
ret, frame = cap.read()
if not ret:
break
# 将当前帧转换成字符图
gray = cv2.cvtColor(frame, cv2.COLOR_BGR2GRAY)
char_img = get_char_img(gray, 4)
# 转换成BGR模式,便于写入视频
char_img = cv2.cvtColor(char_img, cv2.COLOR_GRAY2BGR)
writer.write(char_img)
writer.release()
if __name__ == '__main__':
generate('in.mp4', 'out.mp4')
嗯,这个生成。。。。。。有点受不了,还没生成完,电脑就开始抽烟了!!!鲁大师抽烟了!!!断开后,视频还没到原视频的一半时长,但大小就是原视频的好几倍!!!后面再优化吧,不能奶不能奶。
上面用上的图片






还有一张绫波丽的,但超出大小了,没法传了。先这样吧,以后再记录,还有个视频:嗯,好像好难搞,这个资源。