【PyTorch】8 语言翻译Torchtext实战——英语和德语翻译、Attention模型、 Pytorch 1.8 安装
torchtext 语言翻译
- 1. 数据处理
- 2. DataLoader
- 3. 定义nn.Module和Optimizer
- 4. 训练
-
- 4.1 Pytorch 1.8 安装
- 4.2 训练网络
- 5. 测试模型
- 6. 全部代码
- 小结
这是官方文本篇的一个教程,原英文文档,中文文档和API文档
本教程介绍了如何使用torchtext预处理包含英语和德语句子的著名数据集的数据,并使用它来训练序列到序列模型,并能将德语句子翻译成英语
1. 数据处理
torchtext具有工具,可用于创建可以轻松迭代的数据集,以创建语言翻译模型。 在此示例中,我们展示了如何对原始文本句子进行标记,构建词汇表以及将标记数字化为张量
分词
注意:本教程中的分词需要 Spacy 我们使用 Spacy 是因为它为英语以外的其他语言的分词提供了强大的支持。 torchtext提供了basic_english标记器,并支持其他英语标记器(例如 Moses),但对于语言翻译(需要多种语言),Spacy 是最佳选择
输入:
pip install spacy
接下来,下载英语和德语 Spacy 分词器的原始数据:
python -m spacy download en
python -m spacy download de
报错:
No module named spacy
解决方法:在Anaconda Navigator里面启动CMD.exe Prompt命令行,运行报错:
⚠ As of spaCy v3.0, shortcuts like 'en' are deprecated. Please use the full
pipeline package name 'en_core_web_sm' instead.
...
requests.exceptions.ConnectionError: ('Connection aborted.', TimeoutError(10060, 'A connection attempt failed because the connected party did not properly respond after a period of time, or established connection failed because connected host has failed to respond', None, 10060, None))
解决办法:参考此文,以及spacy官网,使用VPN,命令行输入:
python -m spacy download en_core_web_sm
运行结果:
✔ Download and installation successful
You can now load the package via spacy.load('en_core_web_sm')
同样的,安装:
python -m spacy download de_core_news_sm
python -m spacy download zh_core_web_sm
德语下载成功,中文下载又出现之前那个问题,还是在此网站下载zh_core_web_sm-3.0.0-py3-none-any.whl,放在... your path Anaconda3\Scripts文件夹中,之后用命令行安装此.whl文件,命令行输入:
E:
cd E:\ProgramData\Anaconda3\Scripts
pip install zh_core_web_sm-3.0.0-py3-none-any.whl
运行结果:
Installing collected packages: spacy-pkuseg, zh-core-web-sm
Successfully installed spacy-pkuseg-0.0.28 zh-core-web-sm-3.0.0
现在在PyCharm中输入:
import spacy
from spacy.lang.zh.examples import sentences
nlp = spacy.load("zh_core_web_sm")
doc = nlp(sentences[0])
print(doc.text)
for token in doc:
print(token.text, token.pos_, token.dep_)
结果:
作为语言而言,为世界使用人数最多的语言,目前世界有五分之一人口做为母语。
作为 ADP case
语言 NOUN nmod:prep
而言 PART case
, PUNCT punct
为 ADP case
世界 NOUN compound:nn
使用 NOUN compound:nn
人数 NOUN nsubj
最多 VERB acl
的 PART mark
语言 NOUN nmod:prep
, PUNCT punct
目前 NOUN nmod:tmod
世界 NOUN dep
有 VERB ROOT
五分之一 NUM dep
人口 NOUN nsubj
做为 VERB ccomp
母语 NOUN dobj
。 PUNCT punct
现在训练、评估、测试数据集,依然有这个问题:
NewConnectionError(': Failed to establish a new connection: [WinError 10060] A connection attempt failed because the connected party did not properly respond after a period of time, or established connection failed because connected host has failed to respond' ))
直接在浏览器中输入链接下载
创建词汇表
这三个库在昨天创建vocab的时候就用到过,这里我们看一下Vocab函数里面的specials参数
from torchtext.data.utils import get_tokenizer
from collections import Counter
from torchtext.vocab import Vocab
在API文档里面:specials - 词汇前的特殊标记列表(例如,padding或eos)。默认情况下,[’
print(en_vocab['' ])
print(en_vocab['' ])
print(en_vocab['' ])
0
1
2
直接下载好了放到默认文件夹下,打印一下test_filepaths:
['... your path\\.data\\test_2016_flickr.de', '... your path\\.data\\test_2016_flickr.en']
iter()函数,用来生成迭代器,看一下结果:
print(next(raw_en_iter))
print(next(raw_en_iter))
print(raw_en_iter[0])
结果:
Two young, White males are outside near many bushes.
Several men in hard hats are operating a giant pulley system.
TypeError: '_io.TextIOWrapper' object is not subscriptable
迭代器不加zip的报错:
for (raw_de, raw_en) in (raw_de_iter, raw_en_iter):
ValueError: too many values to unpack (expected 2)
train_data = data_process(train_filepaths)数据处理完的结果:
print(train_data)
print(train_data[0])
print(train_data[0][0])
[...(tensor([ 6, 36, 11, 2493, 184, 9, 7, 1842, 10, 14, 668, 72,
25, 1430, 158, 5, 4]), tensor([ 50, 26, 36, 15, 1018, 152, 16, 4, 1425, 16, 12, 4,
663, 11, 98, 116, 9, 385, 5])),...]
(tensor([ 22, 86, 258, 32, 88, 23, 95, 8, 17, 113, 7911, 3210,
5, 4]), tensor([ 20, 26, 16, 1170, 809, 18, 58, 85, 337, 1340, 6, 5]))
tensor([ 22, 86, 258, 32, 88, 23, 95, 8, 17, 113, 7911, 3210,
5, 4])
可以对应词汇表观察一下结果:
print(en_vocab[','])
print(en_vocab['.'])
print(en_vocab['near'])
print(en_vocab[' '])
print(en_vocab['\n'])
16
6
85
4728
5
英文:
Two young, White males are outside near many bushes.
对应着:
tensor([ 20, 26, 16, 1170, 809, 18, 58, 85, 337, 1340, 6, 5])
2. DataLoader
我们将使用的特定函数是DataLoader,它易于使用,因为它将数据作为第一个参数。 具体来说,正如文档所说:DataLoader结合了一个数据集和一个采样器,并在给定的数据集上进行迭代。 DataLoader支持映射样式和可迭代样式的数据集,具有单进程或多进程加载,自定义加载顺序以及可选的自动批量(归类)和内存固定
请注意collate_fn(可选),它将合并样本列表以形成张量的小批量。 在从映射样式数据集中使用批量加载时使用
关于cat()函数:
x = torch.tensor([ 50, 26, 36, 15, 1018, 152])
print(torch.cat([torch.tensor([BOS_IDX]), x, torch.tensor([EOS_IDX])], dim=0))
tensor([ 2, 50, 26, 36, 15, 1018, 152, 3])
关于函数from torch.nn.utils.rnn import pad_sequence:
torch.nn.utils.rnn.pad_sequence(label_tokens, batch_first=False, padding_value=-1)
- label_tokens: list矩阵,shape=[batch_size, N] ,N长度不一
- batch_first:默认batch_size不在第一维度
- padding_value:填充的值
返回:
- [M, batch_size]
- M为batch中的最大长度
一个例子:
import torch
from torch.nn.utils.rnn import pad_sequence
list = [torch.tensor([2, 55, 100, 26, 12, 77, 260, 60, 150, 2239, 48, 76,
5, 4, 3]), torch.tensor([2, 6, 13, 10, 233, 40, 131, 5, 4, 3])]
print(list)
list = pad_sequence(list)
print(list)
[tensor([ 2, 55, 100, 26, 12, 77, 260, 60, 150, 2239, 48, 76,
5, 4, 3]), tensor([ 2, 6, 13, 10, 233, 40, 131, 5, 4, 3])]
tensor([[ 2, 2],
[ 55, 6],
[ 100, 13],
[ 26, 10],
[ 12, 233],
[ 77, 40],
[ 260, 131],
[ 60, 5],
[ 150, 4],
[2239, 3],
[ 48, 0],
[ 76, 0],
[ 5, 0],
[ 4, 0],
[ 3, 0]])
这样def generate_batch(data_batch): # BATCH_SIZE = 128函数产生的就是torch.Size([*, 128])的Tensor,每一列为一个句子,长度不够的地方使用PAD_IDX = 0补齐,这样Batch_first就是False了
3. 定义nn.Module和Optimizer
这大部分是从torchtext角度出发的:构建了数据集并定义了迭代器,本教程的其余部分仅将模型定义为nn.Module以及Optimizer,然后对其进行训练
具体来说,我们的模型遵循此处描述的架构(可以在这里找到注释更多的版本)
注意:这个模型只是一个可以用于语言翻译的示例模型;我们选择它是因为它是该任务的标准模型,而不是因为它是推荐用于翻译的模型。你可能知道,目前最先进的模型都是基于Transformer的;你可以在这里看到PyTorch实现Transformer层的能力;特别是,下面这个模型中使用的 "注意力 "不同于存在于Transformer模型中的多头自注意力
关于repeat()函数:对张量进行复制:
- 当参数只有两个时,第一个参数表示的是复制后的列数,第二个参数表示复制后的行数。
- 当参数有三个时,第一个参数表示的是复制后的通道数,第二个参数表示的是复制后的列数,第三个参数表示复制后的行数
例如:
>>> x = torch.tensor([6,7,8])
>>> x.repeat(4,2)
tensor([[6, 7, 8, 6, 7, 8],
[6, 7, 8, 6, 7, 8],
[6, 7, 8, 6, 7, 8],
[6, 7, 8, 6, 7, 8]])
>>> x.repeat(4,2,1)
tensor([[[6, 7, 8],
[6, 7, 8]],
[[6, 7, 8],
[6, 7, 8]],
[[6, 7, 8],
[6, 7, 8]],
[[6, 7, 8],
[6, 7, 8]]])
>>> x.repeat(4,2,1).size()
torch.Size([4, 2, 3])
def count_parameters(model: nn.Module):
return sum(p.numel() for p in model.parameters() if p.requires_grad)
print(f'The model has {count_parameters(model):,} trainable parameters')
The model has 3,491,070 trainable parameters
关于tensor .max()函数,例子:
import torch
x = torch.tensor([[1,2,3,4,5,6],
[1,3,2,4,7,0]])
y = x.max(1)
print(y)
y = x.max(1)[1]
print(y)
torch.return_types.max(
values=tensor([6, 7]),
indices=tensor([5, 4]))
tensor([5, 4])
关于output = output[1:].view(-1, output.shape[-1])函数:
output = torch.rand(3,3,4)
print(output)
print(output.size())
output = output[1:]
print(output)
print(output.size())
output = output.view(-1, output.shape[-1])
print(output)
print(output.size())
tensor([[[0.5124, 0.2095, 0.9685, 0.5130],
[0.5376, 0.5775, 0.2049, 0.5947],
[0.0388, 0.4460, 0.2137, 0.3159]],
[[0.8281, 0.7123, 0.8444, 0.1513],
[0.2278, 0.0783, 0.1102, 0.1280],
[0.8715, 0.9269, 0.5525, 0.4746]],
[[0.5208, 0.2078, 0.4011, 0.7671],
[0.8175, 0.8075, 0.3959, 0.0020],
[0.9868, 0.3610, 0.1186, 0.5527]]])
torch.Size([3, 3, 4])
tensor([[[0.8281, 0.7123, 0.8444, 0.1513],
[0.2278, 0.0783, 0.1102, 0.1280],
[0.8715, 0.9269, 0.5525, 0.4746]],
[[0.5208, 0.2078, 0.4011, 0.7671],
[0.8175, 0.8075, 0.3959, 0.0020],
[0.9868, 0.3610, 0.1186, 0.5527]]])
torch.Size([2, 3, 4])
tensor([[0.8281, 0.7123, 0.8444, 0.1513],
[0.2278, 0.0783, 0.1102, 0.1280],
[0.8715, 0.9269, 0.5525, 0.4746],
[0.5208, 0.2078, 0.4011, 0.7671],
[0.8175, 0.8075, 0.3959, 0.0020],
[0.9868, 0.3610, 0.1186, 0.5527]])
torch.Size([6, 4])
关于permute(dims)函数,例如:
>>> x = torch.randn(2, 3, 5)
>>> x.size()
torch.Size([2, 3, 5])
>>> x.permute(2, 0, 1).size()
torch.Size([5, 2, 3])
整个模型如下图所示,和之前的【PyTorch】6 法语英语翻译RNN实战——基于Attention的seq2seq模型、Attention可视化差不多,不同之处在于:
- 原Encoder的输入是一个单词一个单词输入的,需要将hidden作为输入,这里直接将一个句子作为输入,而且是双向的GRU
- 这里新建了一个Seq2Seq类,其实本质上是一样的
关于Attention模型,都是把Encoder的输出和Decoder的隐层组合求Attention权重矩阵,再与Decoder输入的Embedded相乘;Encoder的最后一次隐层的输出作为Decoder隐层的初始化,Decoder的输入初始化为SOS_Token
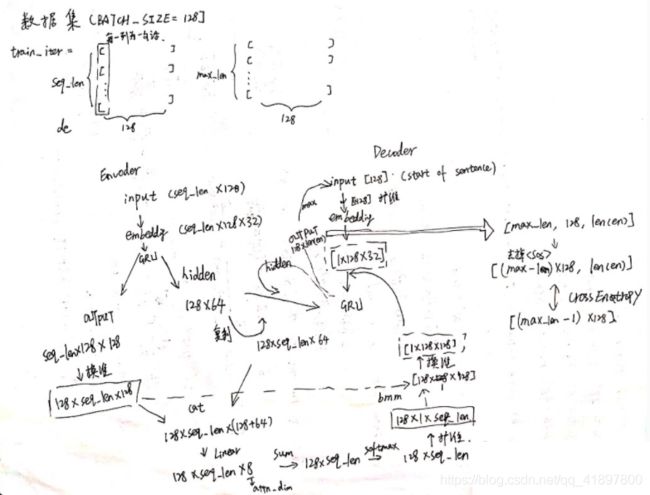
4. 训练
用默认参数训练的话时间很长:
Epoch: 01 | Time: 14m 0s
Train Loss: 5.727 | Train PPL: 307.114
Val. Loss: 5.169 | Val. PPL: 175.670
这里把embedding的维度改为16,隐层的数量改为32,把原来训练集的数据train.en和train.de的29000行改为前4500行,这样一个epoch大概和原代码的时间一样,为50s左右
4.1 Pytorch 1.8 安装
突然发现:
print(torch.cuda.is_available())
print(device)
居然是:
False
cpu
但是GPU没有问题:
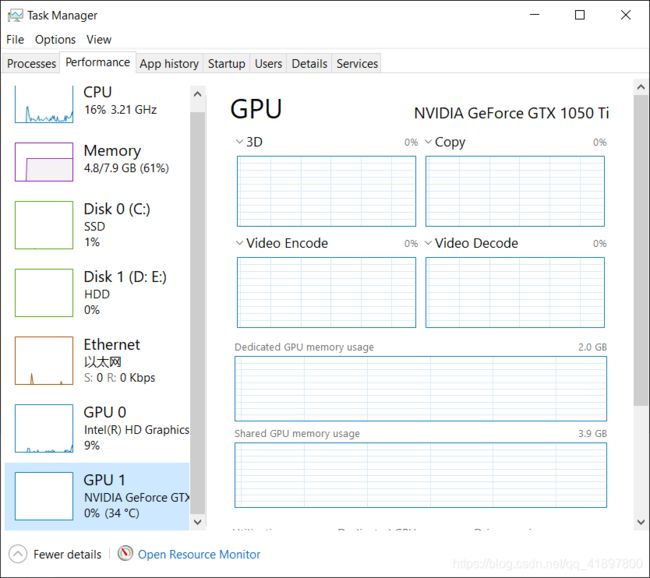
而且用命令行就可以:
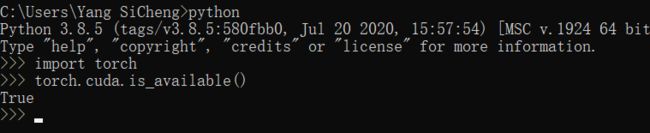
不会用pytorch查看cuda版本,输入:
print(torch.__version__)
print(torch.version.cuda)
结果:
1.8.0+cpu
None
仔细分析之后是cmd的pytorch环境是1.6.0,而Anaconda的pytorch环境是1.8.0+cpu,所以自然cmd里面torch.cuda.is_available()是True而Pycharm里面是False,解决办法:
把cmd的Python环境的Python包(E:\Users…\AppData\Local\Programs\Python\Python38\Lib\site-packages)复制粘贴到Anaconda的环境里(E:\ProgramData\Anaconda3\Lib\site-packages),结果:
import torch
print(torch.__version__) #注意是双下划线 # 1.8.0+cpu
print(torch.version.cuda)
print(torch.cuda.is_available())
device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
print(device)
1.6.0
10.2
True
cuda
之后运行程序:
ImportError: DLL load failed while importing _torchtext: The specified procedure could not be found.
在命令行输入:
pip install torchtext
问题分析,发现部分结果是:
Requirement already satisfied: torchtext in e:\programdata\anaconda3\lib\site-packages (0.9.0)
Requirement already satisfied: tqdm in e:\programdata\anaconda3\lib\site-packages (from torchtext) (4.47.0)
Requirement already satisfied: requests in e:\programdata\anaconda3\lib\site-packages (from torchtext) (2.24.0)
Requirement already satisfied: numpy in e:\programdata\anaconda3\lib\site-packages (from torchtext) (1.18.5)
Collecting torch==1.8.0
所以就是这个torchtext!!接下来就安装一个1.8.0的GPU版本的torch试一试,直接下载会很慢,换源参考此文章,用新的安装命令,将-c pytorch去掉,表示从我们配置的新路径中下载:
conda install pytorch=1.8.0 torchvision torchaudio cudatoolkit=10.2
报错:
RemoveError: 'setuptools' is a dependency of conda and cannot be removed from conda's operating environment.
解决方法参考此文,开源镜像站:
conda update --force conda
看Anaconda python 版本:
conda activate
python -V #注意V是大写
更新conda:
# conda update -n base -c defaults conda
conda update conda
再次再pycharm中运行以下代码:
import torch
print(torch.__version__)
device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
print(str(device) + ':' + str(torch.cuda.is_available()))
运行结果:
1.8.0
cuda:True
4.2 训练网络
还是把embedding的维度设为32,隐层的数量设为64:
Epoch: 01 | Time: 0m 7s
Train Loss: 7.272 | Train PPL: 1439.172
Val. Loss: 5.704 | Val. PPL: 300.015
Epoch: 02 | Time: 0m 6s
Train Loss: 5.456 | Train PPL: 234.190
Val. Loss: 5.510 | Val. PPL: 247.100
Epoch: 03 | Time: 0m 6s
Train Loss: 5.349 | Train PPL: 210.364
Val. Loss: 5.481 | Val. PPL: 240.074
...
还是把原来训练集的数据train.en和train.de的29000行都用上,报错:
RuntimeError: CUDA out of memory.
这里我们取10000行:
1.8.0
cuda:True
Epoch: 01 | Time: 0m 21s
Train Loss: 6.462 | Train PPL: 640.322
Val. Loss: 5.507 | Val. PPL: 246.461
Epoch: 02 | Time: 0m 17s
Train Loss: 5.298 | Train PPL: 199.927
Val. Loss: 5.297 | Val. PPL: 199.757
Epoch: 03 | Time: 0m 17s
Train Loss: 4.949 | Train PPL: 141.031
Val. Loss: 5.130 | Val. PPL: 169.056
Epoch: 04 | Time: 0m 17s
Train Loss: 4.750 | Train PPL: 115.582
Val. Loss: 5.080 | Val. PPL: 160.796
Epoch: 05 | Time: 0m 17s
Train Loss: 4.604 | Train PPL: 99.845
Val. Loss: 5.085 | Val. PPL: 161.652
Epoch: 06 | Time: 0m 17s
Train Loss: 4.518 | Train PPL: 91.668
Val. Loss: 5.020 | Val. PPL: 151.473
Epoch: 07 | Time: 0m 17s
Train Loss: 4.444 | Train PPL: 85.106
Val. Loss: 5.008 | Val. PPL: 149.587
Epoch: 08 | Time: 0m 17s
Train Loss: 4.386 | Train PPL: 80.340
Val. Loss: 4.988 | Val. PPL: 146.597
Epoch: 09 | Time: 0m 17s
Train Loss: 4.320 | Train PPL: 75.190
Val. Loss: 5.008 | Val. PPL: 149.537
Epoch: 10 | Time: 0m 17s
Train Loss: 4.248 | Train PPL: 69.960
Val. Loss: 4.906 | Val. PPL: 135.125
| Test Loss: 4.867 | Test PPL: 129.900 |
5. 测试模型
Ein Bergsteiger übt an einer Kletterwand.
= A rock climber practices on a rock climbing wall.
> A man in a in a a .
Zwei Bauarbeiter arbeiten auf einer Straße vor einem Hauses.
= Two male construction workers are working on a street outside someone's home
> men men are are are are are a are a are are are standing on a .
Ein Mann baut einen Holzstuhl zusammen.
= A man putting together a wooden chair.
> A man in a a a .
Zwei junge weiße Männer sind im Freien in der Nähe vieler Büsche. # (训练集)
= Two young, White males are outside near many bushes.
> men are are are are a a of a .
可以发现结果很烂……怪不得原来的代码里面没有放测试的句子,所以这里主要是演示一下Attention怎么搭建
6. 全部代码
import torch
print(torch.__version__)
device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
print(str(device) + ':' + str(torch.cuda.is_available()))
from torchtext.utils import download_from_url, extract_archive
url_base = 'https://raw.githubusercontent.com/multi30k/dataset/master/data/task1/raw/'
train_urls = ('train.de.gz', 'train.en.gz')
val_urls = ('val.de.gz', 'val.en.gz')
test_urls = ('test_2016_flickr.de.gz', 'test_2016_flickr.en.gz')
# train_filepaths = [extract_archive(download_from_url(url_base + url))[0] for url in train_urls]
train_filepaths = ['... your path\\.data\\train.de', '... your path\\.data\\train.en']
val_filepaths = [extract_archive(download_from_url(url_base + url))[0] for url in val_urls]
test_filepaths = [extract_archive(download_from_url(url_base + url))[0] for url in test_urls]
from torchtext.data.utils import get_tokenizer
de_tokenizer = get_tokenizer('spacy', language='de_core_news_sm')
en_tokenizer = get_tokenizer('spacy', language='en_core_web_sm')
from collections import Counter
from torchtext.vocab import Vocab
import io
def build_vocab(filepath, tokenizer):
counter = Counter()
with io.open(filepath, encoding="utf8") as f:
for string_ in f:
counter.update(tokenizer(string_))
return Vocab(counter, specials=['' , '' , '' , '' ])
de_vocab = build_vocab(train_filepaths[0], de_tokenizer)
en_vocab = build_vocab(train_filepaths[1], en_tokenizer)
def data_process(filepaths):
raw_de_iter = iter(io.open(filepaths[0], encoding="utf8")) # 生成迭代器
raw_en_iter = iter(io.open(filepaths[1], encoding="utf8")) # <_io.TextIOWrapper name='... your path\\.data\\train.en' mode='r' encoding='utf8'>
data = []
for (raw_de, raw_en) in zip(raw_de_iter, raw_en_iter): # raw_de, raw_en就是每一句话
de_tensor_ = torch.tensor([de_vocab[token] for token in de_tokenizer(raw_de)], dtype=torch.long)
en_tensor_ = torch.tensor([en_vocab[token] for token in en_tokenizer(raw_en)], dtype=torch.long)
data.append((de_tensor_, en_tensor_))
return data
train_data = data_process(train_filepaths)
val_data = data_process(val_filepaths)
test_data = data_process(test_filepaths)
BATCH_SIZE = 128
PAD_IDX = de_vocab['' ] # 1
BOS_IDX = de_vocab['' ] # 2
EOS_IDX = de_vocab['' ] # 3
from torch.nn.utils.rnn import pad_sequence
from torch.utils.data import DataLoader
def generate_batch(data_batch): # BATCH_SIZE = 128
de_batch, en_batch = [], []
for (de_item, en_item) in data_batch:
de_batch.append(torch.cat([torch.tensor([BOS_IDX]), de_item, torch.tensor([EOS_IDX])], dim=0))
en_batch.append(torch.cat([torch.tensor([BOS_IDX]), en_item, torch.tensor([EOS_IDX])], dim=0))
# len(de_batch) = 128
de_batch = pad_sequence(de_batch, padding_value=PAD_IDX) # , torch.Size([*, 128])
en_batch = pad_sequence(en_batch, padding_value=PAD_IDX)
return de_batch, en_batch
train_iter = DataLoader(train_data, batch_size=BATCH_SIZE, shuffle=True, collate_fn=generate_batch)
valid_iter = DataLoader(val_data, batch_size=BATCH_SIZE, shuffle=True, collate_fn=generate_batch)
test_iter = DataLoader(test_data, batch_size=BATCH_SIZE, shuffle=True, collate_fn=generate_batch)
import torch.nn as nn
from typing import Tuple
class Encoder(nn.Module):
def __init__(self, input_dim: int, emb_dim: int, enc_hid_dim:int, dec_hid_dim: int, dropout: float): # seq_len, 32, 64, 64, 0.5
super().__init__()
self.input_dim = input_dim
self.emb_dim = emb_dim
self.enc_hid_dim = enc_hid_dim
self.dec_hid_dim = dec_hid_dim
self.dropout = dropout
self.embedding = nn.Embedding(input_dim, emb_dim)
self.dropout = nn.Dropout(dropout)
self.rnn = nn.GRU(emb_dim, enc_hid_dim, bidirectional=True)
self.fc = nn.Linear(enc_hid_dim * 2, dec_hid_dim)
def forward(self, src: torch.Tensor) -> Tuple[torch.Tensor]: # 函数参数中的冒号是参数的类型建议符,告诉程序员希望传入的实参的类型。函数后面跟着的箭头是函数返回值的类型建议符,用来说明该函数返回的值是什么类型
embedded = self.dropout(self.embedding(src)) # seq_len * 128 * emb_dim
outputs, hidden = self.rnn(embedded) # 为什么没有hidden?因为这里直接把一句话输入,而不是一个词一个词输入
# hidden = torch.tanh(self.fc(torch.cat((hidden[-2, :, :], hidden[-1, :, :]), dim=1)))
hidden = torch.cat((hidden[-2,:,:], hidden[-1,:,:]), dim=1) # num_layers * num_directions, batch, hidden_size → torch.Size([128, 64*2])
hidden = self.fc(hidden) # torch.Size([128, 64])
hidden = torch.tanh(hidden) # 双曲正切函数, 激活函数, torch.Size([128, 64])
return outputs, hidden # seq_len, batch(128), num_directions(2) * hidden_size(64), torch.Size([128, 64])
import torch.nn.functional as F
class Attention(nn.Module):
def __init__(self, enc_hid_dim: int, dec_hid_dim: int, attn_dim: int):
super().__init__()
self.enc_hid_dim = enc_hid_dim
self.dec_hid_dim = dec_hid_dim
self.attn_in = (enc_hid_dim * 2) + dec_hid_dim
self.attn = nn.Linear(self.attn_in, attn_dim)
def forward(self, decoder_hidden, encoder_outputs) -> torch.Tensor:
src_len = encoder_outputs.shape[0]
repeated_decoder_hidden = decoder_hidden.unsqueeze(1).repeat(1, src_len, 1)
encoder_outputs = encoder_outputs.permute(1, 0, 2)
energy = torch.tanh(self.attn(torch.cat((repeated_decoder_hidden, encoder_outputs), dim=2)))
attention = torch.sum(energy, dim=2)
return F.softmax(attention, dim=1)
class Decoder(nn.Module):
def __init__(self, output_dim: int, emb_dim: int, enc_hid_dim: int, dec_hid_dim: int, dropout: int, attention: nn.Module):
super().__init__()
self.emb_dim = emb_dim
self.enc_hid_dim = enc_hid_dim
self.dec_hid_dim = dec_hid_dim
self.output_dim = output_dim
self.dropout = dropout
self.attention = attention
self.embedding = nn.Embedding(output_dim, emb_dim)
self.dropout = nn.Dropout(dropout)
self.rnn = nn.GRU((enc_hid_dim * 2) + emb_dim, dec_hid_dim)
self.out = nn.Linear(self.attention.attn_in + emb_dim, output_dim)
def _weighted_encoder_rep(self, decoder_hidden, encoder_outputs) -> torch.Tensor:
a = self.attention(decoder_hidden, encoder_outputs)
a = a.unsqueeze(1)
encoder_outputs = encoder_outputs.permute(1, 0, 2)
weighted_encoder_rep = torch.bmm(a, encoder_outputs)
weighted_encoder_rep = weighted_encoder_rep.permute(1, 0, 2)
return weighted_encoder_rep
def forward(self, input: torch.Tensor, decoder_hidden: torch.Tensor, encoder_outputs: torch.Tensor) -> Tuple[torch.Tensor]:
# input.size() = torch.Size([128])
input = input.unsqueeze(0) # 1 * 128
embedded = self.dropout(self.embedding(input)) # 1* 128 * 32
weighted_encoder_rep = self._weighted_encoder_rep(decoder_hidden, encoder_outputs) # torch.Size([128, 64]), torch.Size([len, 128, 128]), 1*128*128
rnn_input = torch.cat((embedded, weighted_encoder_rep), dim=2) # 1 *128 * (32+128) torch.Size([1, 128, 160])
output, decoder_hidden = self.rnn(rnn_input, decoder_hidden.unsqueeze(0)) # 1*128*160, 1*128*64 ,1*128*64, 1*128*64
embedded = embedded.squeeze(0) # torch.Size([128, 32])
output = output.squeeze(0) # 128*64
weighted_encoder_rep = weighted_encoder_rep.squeeze(0) # 128*128
output = self.out(torch.cat((output, weighted_encoder_rep, embedded), dim=1)) # 128*len(en)
return output, decoder_hidden.squeeze(0) # 128*len(en), 128*64
import random
class Seq2Seq(nn.Module):
def __init__(self, encoder: nn.Module, decoder: nn.Module, device: torch.device):
super().__init__()
self.encoder = encoder
self.decoder = decoder
self.device = device
def forward(self, src: torch.Tensor, trg: torch.Tensor, teacher_forcing_ratio: float = 0.5) -> torch.Tensor:
batch_size = src.shape[1]
max_len = trg.shape[0]
trg_vocab_size = self.decoder.output_dim
outputs = torch.zeros(max_len, batch_size, trg_vocab_size).to(self.device)
encoder_outputs, hidden = self.encoder(src)
output = trg[0,:] # first input to the decoder is the token
# output = tensor([2, 2, 2, 2, 2 ...(128个)
for t in range(1, max_len):
output, hidden = self.decoder(output, hidden, encoder_outputs)
outputs[t] = output # torch.Size([128, len(en)(6416)])
teacher_force = random.random() < teacher_forcing_ratio # teacher_force True(From Reference) or False(From Model)?
top1 = output.max(1)[1]
output = (trg[t] if teacher_force else top1)
return outputs
INPUT_DIM = len(de_vocab)
OUTPUT_DIM = len(en_vocab)
# ENC_EMB_DIM = 256
# DEC_EMB_DIM = 256
# ENC_HID_DIM = 512
# DEC_HID_DIM = 512
# ATTN_DIM = 64
# ENC_DROPOUT = 0.5
# DEC_DROPOUT = 0.5
ENC_EMB_DIM = 32
DEC_EMB_DIM = 32
ENC_HID_DIM = 64
DEC_HID_DIM = 64
ATTN_DIM = 8
ENC_DROPOUT = 0.5
DEC_DROPOUT = 0.5
enc = Encoder(INPUT_DIM, ENC_EMB_DIM, ENC_HID_DIM, DEC_HID_DIM, ENC_DROPOUT)
attn = Attention(ENC_HID_DIM, DEC_HID_DIM, ATTN_DIM)
dec = Decoder(OUTPUT_DIM, DEC_EMB_DIM, ENC_HID_DIM, DEC_HID_DIM, DEC_DROPOUT, attn)
model = Seq2Seq(enc, dec, device).to(device)
def init_weights(m: nn.Module):
for name, param in m.named_parameters():
if 'weight' in name:
nn.init.normal_(param.data, mean=0, std=0.01)
else:
nn.init.constant_(param.data, 0)
model.apply(init_weights)
import torch.optim as optim
optimizer = optim.Adam(model.parameters())
criterion = nn.CrossEntropyLoss(ignore_index=en_vocab.stoi['' ])
import math
import time
# model, train_iter, optimizer, criterion, CLIP
def train(model: nn.Module, iterator: torch.utils.data.DataLoader, optimizer: optim.Optimizer, criterion: nn.Module, clip: float):
model.train() # 模式选择
epoch_loss = 0
for _, (src, trg) in enumerate(iterator):
src, trg = src.to(device), trg.to(device)
optimizer.zero_grad()
output = model(src, trg) # max_len, batch_size, trg_vocab_size
output = output[1:].view(-1, output.shape[-1]) # torch.Size([(max_len-1)*128, 6416])
trg = trg[1:].view(-1) # # torch.Size([(max_len-1)*128])
loss = criterion(output, trg)
loss.backward()
torch.nn.utils.clip_grad_norm_(model.parameters(), clip)
optimizer.step()
epoch_loss += loss.item()
return epoch_loss / len(iterator)
def evaluate(model: nn.Module, iterator: torch.utils.data.DataLoader, criterion: nn.Module):
model.eval()
epoch_loss = 0
with torch.no_grad():
for _, (src, trg) in enumerate(iterator):
src, trg = src.to(device), trg.to(device)
output = model(src, trg, 0) #turn off teacher forcing
output = output[1:].view(-1, output.shape[-1])
trg = trg[1:].view(-1)
loss = criterion(output, trg)
epoch_loss += loss.item()
return epoch_loss / len(iterator)
def epoch_time(start_time, end_time):
elapsed_time = end_time - start_time
elapsed_mins = int(elapsed_time / 60)
elapsed_secs = int(elapsed_time - (elapsed_mins * 60))
return elapsed_mins, elapsed_secs
if __name__ == '__main__':
# N_EPOCHS = 10
# CLIP = 1
# best_valid_loss = float('inf')
# for epoch in range(N_EPOCHS): # 最大迭代次数
# start_time = time.time()
# train_loss = train(model, train_iter, optimizer, criterion, CLIP)
# valid_loss = evaluate(model, valid_iter, criterion)
# end_time = time.time()
# epoch_mins, epoch_secs = epoch_time(start_time, end_time)
#
# print(f'Epoch: {epoch+1:02} | Time: {epoch_mins}m {epoch_secs}s')
# print(f'\tTrain Loss: {train_loss:.3f} | Train PPL: {math.exp(train_loss):7.3f}')
# print(f'\t Val. Loss: {valid_loss:.3f} | Val. PPL: {math.exp(valid_loss):7.3f}')
#
# test_loss = evaluate(model, test_iter, criterion)
#
# print(f'| Test Loss: {test_loss:.3f} | Test PPL: {math.exp(test_loss):7.3f} |')
#
# torch.save(model.state_dict(), '... your path\\model_Translate.pth')
# 以下为测试
model.load_state_dict(torch.load('... your path\\model_Translate.pth'))
# str = 'Ein Bergsteiger übt an einer Kletterwand.'
str = 'Zwei junge weiße Männer sind im Freien in der Nähe vieler Büsche.'
de_tensor = torch.tensor([de_vocab[token] for token in de_tokenizer(str)], dtype=torch.long)
de_tensor = torch.cat([torch.tensor([BOS_IDX]), de_tensor, torch.tensor([EOS_IDX])], dim=0)
de_tensor = de_tensor.unsqueeze(1).to(device)
output = model(de_tensor, torch.zeros(50,1).long().to(device),0)
output = output[1:].view(-1, output.shape[-1]) # torch.Size([49, 6416])
result = []
for i in range(output.size()[0]):
index = output[i].data.topk(1)[1].item()
if en_vocab.itos[index] == '' :
break
result.append(en_vocab.itos[index]) # 1722, apple
print(' '.join(result))
小结
- 数据处理依然很费时费力,主要是下载失败,需要使用VPN进行下载或者直接使用浏览器下载再将文件移到目标文件夹中;分词、词汇表的创建(one-hot编码)还是比较好懂的
- 迭代器中使所有句子一样长,整个扩充的方法可以借鉴一下
- 定义的模型主要是关于Tensor矩阵的一些运算不熟,例如:reapeat(), max(), view(), permute()等等,Attention的原理还是比较好懂的
- 训练时踩了一个大坑,cuda给我整没了,原因是昨天pip安装torchtext把torch升级成为1.8+cpu版本了,然后辛辛苦苦把conda的环境和torch的环境整好了
- 测试模型很烂,猜测是Encoder没有用每个词作为输入?
未来工作:
- BERT、Transformer理论
- Transformer编程实现
- 聊天机器人编程实现