数学建模笔记——最优值之我见(爬山算法,模拟退火
目录
爬山问题
爬山算法的流程
爬山算法优缺点
先提物理退火
关于模拟退火
1.1总论
1.2主要流程
1.2.1产生初始解
1.2.2扰动产生新解
1.2.3计算
1.2.4判断
1.2.4循环
2013年国赛B题
原题
问题分析
模型假设
符号说明
模型的建立
代码
爬山问题
爬山问题简述:甲去爬山,想爬到最高处,那么他爬过一座山峰,看到更高的山峰,他就去下山再去爬更高的山峰,直到到达最高的山峰。

比如图中的情况:
1.一开始甲去爬山,从X点出发,那么甲能找到的最高的山峰就是A
2.甲到达A时,甲经过一些抉择,选择往B走
3.甲到达B后,通过对比A点和C点,两点,甲发现C点更高,所以甲前往c点
4.到达c点以后,甲随机走,走到D点,然后发现又有一座山峰F点
5.甲到达F点后发现C点比F点要高,所以又回到了C点
这是我们模拟出来的一个正常人的情况。
那么如果甲是一个机器人,不能做出长远的判断(没有视力,无法判断面前的山峰;没有记忆,无法记录登山路径),只能知道海拔高度呢?
问题存在,分析开始:
如果甲不能做出长远的判断,那么从X到A,海拔明显升高,甲可以自主去判断,做出正确的选择,从X走到A,但是甲能否做出从A峰到达更高C峰的选择呢?
答案是:不能,因为机器人甲判断出来X和B的海拔都比A点低。
那么这时我们该如何让机器人走到最高峰呢?
爬山算法的流程
1.我们让机器人随机做出一个决定,是向左走到X还是向右走到B,还是留在A
2.如果机器人甲随机决定向右走到达了B点,那么机器人发现B海拔没有A高,则机器人有一定概率接受这个现状,我们将概率设为p。
3.机器人到达B以后,和第1步一样,有概率向左或向右走,但是此时向左或向右都是海拔升高,所以都会被接受。
4.机器人甲到达C以后重复之前第2步的操作
5.一直循环234
6.到达一定的循环次数后,停止循环,那么只要循环次数足够多,最后一定会在最高峰处徘徊。
爬山算法优缺点
优点:爬山算法作为一种简单的贪心搜索算法,计算简单,实现容易
缺点:会陷入局部最优解,不一定能搜索到局部最优解
比如在这个情况下,爬山问题无法找到最高点X点,因为他会在一直D点徘徊,最后的结果也会锁定在D点,这就是所谓的局部最优,爬山算法无法求解全体的最优解。
那么为了更更更好的求解出最优值问题,我们来看另一种算法,模拟退火算法
先提物理退火
模拟退火算法来源于固体退火原理,是一种基于概率的算法,将固体加温至充分高,再让其徐徐冷却,加温时,固体内部粒子随温度升高为无序状,内能增大,而徐徐冷却时粒子渐趋有序,在每个温度都达到平衡状态,最后在常温时达到基态,内能减为最小
关于模拟退火
1.1总论
模拟退火算法是通过赋予搜索过程一种时变且最终趋于零的概率突跳性,从而可有效避免陷入局部极小并最终趋于全局最优的串行结构的优化算法。
之所以叫模拟退火,意为模拟物理退火的算法的过程,物理退火最后会到达一个最小值,即最后的退火的平衡温度。所以模拟退火算法也是一个求最小值的算法。
1.2主要流程

(来源:百度百科,作者偷懒,画流程图有点折磨)
1.2.1产生初始解
产生初始解的过程是这样的:
先根据方程的解区间随意挑选一个解,作为随机产生的初始解,可以用蒙特卡洛方法来提供任意解,也可以用随机数函数来提供,建议与提供一个与最优解较为接近的解作为初始解,这样的话可以极大的减少模拟退火算法计算次数。
产生初始解以后,将初始解带入函数中进行计算出初始函数值。
1.2.2扰动产生新解
将原来得到的初始解进行一些干扰,产生一个新的解,然后将新的解带入原函数中进行计算。
1.2.3计算
新解所产生的函数值与原函数值做差,若差值≤0,则接受新解,若差值>0,则按照一定概率接受新解,这个概率由Metropolis法则来提供。
Metropolis算法就是如何在局部最优解的情况下让其跳出来(如图中B、C、E为局部最优),是退火的基础。1953年Metropolis提出重要性采样方法,即以概率来接受新状态,而不是使用完全确定的规则,称为Metropolis准则,计算量较低。
假设前一个状态为x(n),系统根据某一指标(梯度下降,上节的能量),状态变为x(n+1),相应的,系统的能量由E(n)变为E(n+1),定义系统由x(n)变为x(n+1)的接受概率P为: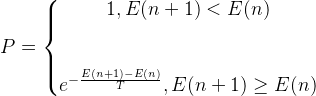
1.2.4判断
终止模拟退火算法,两种方法。
第一种,是传统的以循环次数结束为终止,由开始设置的循环次数来进行模拟的次数,当循环次数结束后,退出模拟退火算法,输出最终解。
第二种,是另加一个约束条件,比如最后解与理论最优解的差值,当差值小于一定值时,退出模拟退火算法,输出最终解。但是由于这种方式在设计算法时,难度比较大(不能简单的用一个循环来代替)而且也有可能时间复杂度会大的离谱,所以我们不怎么使用这一种方式来进行最后的判断
1.2.4循环
若不能经过判断,则返回产生初解的部分继续进行计算。
下面我们来一道经典例题,来进一步说一下模拟退火算法
2013年国赛B题
仅用第一问来做一个对于模拟退火简单的讲解,题目与附件放到了文末的链接中,可以自行下载
原题
B题 碎纸片的拼接复原
破碎文件的拼接在司法物证复原、历史文献修复以及军事情报获取等领域都有着重要的应用。传统上,拼接复原工作需由人工完成,准确率较高,但效率很低。特别是当碎片数量巨大,人工拼接很难在短时间内完成任务。随着计算机技术的发展,人们试图开发碎纸片的自动拼接技术,以提高拼接复原效率。请讨论以下问题:
1. 对于给定的来自同一页印刷文字文件的碎纸机破碎纸片(仅纵切),建立碎纸片拼接复原模型和算法,并针对附件1、附件2给出的中、英文各一页文件的碎片数据进行拼接复原。如果复原过程需要人工干预,请写出干预方式及干预的时间节点。复原结果以图片形式及表格形式表达
- 每一附件为同一页纸的碎片数据。
- 附件1、附件2为纵切碎片数据,每页纸被切为19条碎片。
- 附件3、附件4为纵横切碎片数据,每页纸被切为11×19个碎片。
- 附件5为纵横切碎片数据,每页纸被切为11×19个碎片,每个碎片有正反两面。该附件中每一碎片对应两个文件,共有2×11×19个文件,例如,第一个碎片的两面分别对应文件000a、000b。
【结果表达格式说明】
复原图片放入附录中,表格表达格式如下:
- 附件1、附件2的结果:将碎片序号按复原后顺序填入1×19的表格;
问题分析
对于问题一,我们需要先将附录里面提供的17个碎片数据进行定量处理,由于问题一中只有纵切一种切法,所以我们只需要考虑将碎纸片进行左右两边进行拼接即可。
但是对于如何拼接这一点,我们需要对于附件中的图片进行定量分析,定量的对象为图片的像素块
 (拿一个图片进行举例)
(拿一个图片进行举例)
我们用python里的PIL库进行图片的像素提取,因为在图片里文字不是只有黑白两种颜色
![]() 我们以这个字为例,我们可以很清晰的看到,字周围的为灰色块,字本身为黑色块,字外为白色块,所以我们可以利用灰度值进行定量。比如我们设定一个值,高于的就标为1,低于的就标为0,这样就可以将复杂的色块转换为简单的0-1矩阵了,如果有两张卡片两端灰度值数据相同或接近,那我们就可以认为是相邻的两张纸片。
我们以这个字为例,我们可以很清晰的看到,字周围的为灰色块,字本身为黑色块,字外为白色块,所以我们可以利用灰度值进行定量。比如我们设定一个值,高于的就标为1,低于的就标为0,这样就可以将复杂的色块转换为简单的0-1矩阵了,如果有两张卡片两端灰度值数据相同或接近,那我们就可以认为是相邻的两张纸片。
模型假设
1,纸片打印时,左右间距,字间距相等
符号说明
i,j 碎片数据
Fio 碎片数据i在横坐标为0的所有点上灰度值之和
Fi72 碎片数据i在横坐标为72的所有点上灰度值之和
y 碎片数据像素标准化后的纵坐标
fi(0,y) 碎片数据i在(0,y)点上的灰度值, .
fi(72,y) 碎片数据j在(72,y)点上的灰度值,
Sj 碎片数据i、j间的相关函数
Ai 第i张碎片数据最右端0-1矩阵
Bi 第j张碎片最左端0-1矩阵
Cij 第i张碎片数据最右端0-1矩阵与第j张碎片最左端0-1矩阵差值的绝对值之和
Mij 第i张碎片数据最右端0-1矩阵与所有碎片最左端0-1矩阵差值的绝对值的最小值
Nij 最左端0-1矩阵与第i张碎片数据最右端0-1矩阵差值的绝对值的最小的碎片编号
模型的建立
我们通过对附件的图片进行像素提取,发现附件的像素均为72*1980,所以我们将设置横竖坐标,以此来建立像素坐标系,然后再进行计算各碎片数据横坐标为0和72的灰度值之和:

Fio为碎片数据i在横坐标为0的所有点上灰度值之和,Fi72为碎片数据i在横坐标为72的所有点上度值之和,y为碎片数据像素标准化后的纵坐标,fi(0,y) 为碎片数据i在(0,y)点上的灰度值,fi(72,y) 为碎片数据i在(72,y)点上的灰度值。
我们定义函数 Sij=Fio-Fj72 作为我们下一步进行模拟退火算法的目标函数,我们只要让Sij函数的值最小,就说明的两张碎纸片的相关性越大。
所以下一步的目标,便是求解这个函数的最小值,只要找到了这个函数的最小值,就可以判断这个两张纸片相关性的大小,然后把相关性最大的两个纸片进行拼接即可。
这里我们提到一点,我们应该先确定最左边的一段,然后再从左向右依次拼接,这样我们就可以得到一份完整的图片。
代码
import glob #标准库,批量读取文件
import numpy as np
from PIL import Image #关于图像处理方面的库
class PaperRecovery:
IMAGE_ABS_PATH = '文件地址/*.bmp' #图片存在该目录下
img = {}
finded = set()
def read_img(self): # 读取指定目录下的碎纸图片,存入字典中,方便使用
img_name_list = glob.glob(self.IMAGE_ABS_PATH)
for img_name in img_name_list: #k = img_name.replace('.bmp','')[-3:] # 使用文件路径作为字典的键,方便找出正确图片顺序后,拼接还原图片
k = img_name
self.img[k] = Image.open(img_name)
def __init__(self):
self.read_img()
def find_match_paper(self,paper_img,direction): #根据图片边缘的相似度,找出给定碎纸片的相邻纸片
self_img_array = np.array(self.img[paper_img])
sh, sw = self_img_array.shape
if direction == "r":
self_edge = self_img_array[0:sh,sw-1:sw]
elif direction == 'l':
self_edge = self_img_array[0:sh,0:1]
min_var = -1
for k, v in self.img.items():
if k == paper_img:
continue
if k in self.finded:
continue
other_img_array = np.array(v)
h, w = other_img_array.shape
if direction == "r":
other_edge = other_img_array[0:h,0:1]
elif direction == 'l':
other_edge = other_img_array[0:h,w-1:w]
else:
pass
var = np.sum(abs(self_edge-other_edge))
if min_var == -1:
similar_img = k
min_var = var
if var < min_var:
similar_img = k
min_var = var
self.finded.add(paper_img)
return similar_img
def find_edge_paper(self):#函数找出原图片中的最左边和最右边的碎纸图片观察碎纸图片后,可以看出,在竖切时在完整纸片的最左端和最右端的碎纸片,有一定的留白
def is_all_white(edge_array):#检查是否是白色(数据为:255)
WHITE_RGB = 255
for k in edge_array:
if k != WHITE_RGB:
return False
return True
for k, v in self.img.items():
img_array = np.array(v)
h, w = img_array.shape
right_edge = img_array[0:h,w-1:w]
left_edge = img_array[0:h,0:1]
if is_all_white(right_edge):
right_img_name = k
elif is_all_white(left_edge):
left_img_name = k
return (left_img_name,right_img_name)
def find_correct_order(self):
correct_order = []
left_side_img, right_side_img = self.find_edge_paper()
correct_order.append(left_side_img)
paper_list = list(self.img.keys())
paper_list.remove(left_side_img)
paper_list.remove(right_side_img)
while paper_list:
now_paper = correct_order[len(correct_order)-1]
next_paper = self.find_match_paper(now_paper,direction="r")
paper_list.remove(next_paper)
correct_order.append(next_paper)
correct_order.append(right_side_img)
return correct_order
def combining(self,order):
"""
复原竖切的碎纸片
按照正确的图片顺序(从左到右),将碎纸片拼接成完整的纸片
"""
UNIT_W, UNIT_H = self.img[order[0]].size
TARGET_WIDTH = len(order) * UNIT_W
target = Image.new('RGB', (TARGET_WIDTH, UNIT_H))
x = 0
for img_name in order:
img = self.img[img_name]
target.paste(img,(x,0))
x += UNIT_W
return target
if __name__ == "__main__":
rp = PaperRecovery()
correct_order = rp.find_correct_order()
whole_img = rp.combining(correct_order)
whole_img.save('whole.bmp')
idx_list = []
for order in correct_order:
idx = order[-7:-3]
idx_list.append(idx)
print(idx_list)