自然语言处理概述及流程
目录
- 前言
- 一、自然语言处理的几个维度
- 二、调包工程师需要掌握的一些技能
-
- 2-1、理解算法复杂度
- 2-2、语言模型(Language Model)
-
- 2-2-1、Unigram
- 2-2-2、马尔可夫假设
- 2-2-3、Bigram
- 2-2-4、N-gram(N>2)
- 2-2-5、评估语言模型的好坏(困惑度/Perplexity)
- 2-3、平滑方法
-
- 2-3-1、Add-one Smoothing(拉普拉斯平滑)
- 2-3-2、Add-K Smoothing
- 2-3-3、Interpolation
- 2-3-4、Good-Turning Smoothing
- 2-4、特征选择技术
-
- 2-4-1、All Subsets
- 2-4-2、Greedy Approaches
- 2-4-3、使用正则的方式筛选特征
- 2-5、特征构建(命名实体识别)
-
- 2-5-1、词袋特征
- 2-5-2、词性
- 2-5-3、前缀&后缀
- 2-5-4、当前词的特性
- 2-5-5、案例
- 三、自然语言处理流程
-
- 3-1 分词
- 3-2 预处理
- 3-3 文本表示
-
- 3-3-1 (特征提取)转换为tf-idf的形式:
- 3-3-2(特征提取)(CountVectorizer):
- 3-3-3(特征提取)(Keras.Embedding层):
- 3-4 计算相似度并排序:
- 3-5 再一次进行过滤(可选)
- 3-6 返回结果
- 总结
前言
准备走上自然语言处理调包工程师的路,所以有必要对整体的架构有一些清楚的认知。
一、自然语言处理的几个维度
声音(Phonetics)
这里和自然语言处理调包工程师关系不大。
单词(Morphology)
1、分词
2、词性标注POS
3、命名实体识别NER:抽取句子中一些我们比较关心的词。
句子结构(Syntax)
1、句法分析
2、依存分析(判断词之间有什么关系)
3、关系抽取(Relation Extraction)
语义(Semantic)
主要是用一些机器学习算法去分析
二、调包工程师需要掌握的一些技能
2-1、理解算法复杂度
时间复杂度:反映了程序的执行量
空间复杂度:占用的空间
举个栗子:
int i,j,k=0
for(i=n/2;i<=n;i++){
for(j=2;j<=n;j=j*2){
k=k+n/2
}
}
分析:
假设n为20
1、i=10 j=2、4、8、16
2、i=11 j=2、4、8、16
.
.
.
11、i=20 j=2、4、8、16
表示为:((1/2)*n+1)*(log(n)+1),log(n)要记得向上取整
那么整体的时间复杂度就是 O(n*log(n))
空间复杂度 O(1)
2-2、语言模型(Language Model)
用来判断一个句子是否是正确的,即判断一句话是不是人话,如果错误则转化为正确的。
即:p(s) = p(w1,w2,w3…)=p(w1)p(w2|w1)p(w3|w1,w2)…
直接计算的缺点:会导致参数空间过大,计算复杂,数据稀疏等问题。
数据稀疏:由于语料有限,产生了零概率,即某些单词的概率为0.
为了解决这个问题,我们提出了以下方案:
2-2-1、Unigram
假设单词之间是相互独立的, 或者说一句话中每个词的概率与其它词无关,即一个句子的概率等于句子中每个词出现的概率的乘积。
p(s)= p(w1)p(w2)p(w3)…
缺点:不考虑单词之间的顺序,极度不友好。
2-2-2、马尔可夫假设
马尔可夫假设:一个词出现的概率只与它前面出现的有限的一个或者几个词有关。
2-2-3、Bigram
同样的一个句子的概率,在Bigram中,每个词的概率会依赖于前一个词。即:
p(s)= p(w1)p(w2|w1)p(w3|w2)…
优点:与Unigram相比,Bigram可以更好的考虑上下文。
trigram: 类比Bigram,每个词出现的概率只会依赖于前两个词。
2-2-4、N-gram(N>2)
N-gram就是假设当前词出现的概率只与它前面的N-1个词有关。
缺点:无法捕捉到长距离依赖。
2-2-5、评估语言模型的好坏(困惑度/Perplexity)
直接将语言模型运用到具体任务任务中来评价模型好坏难以操作并且费时费力,于是便发明了perplexity这个指标。
Perplexity:是语言模型的评价指标,基本思想是用各个语言模型在测试集的句子测试,给测试集句子赋予较高概率值的语言模型比较好。(测试集中的句子都是正常的句子)
即迷惑度越小的话,意味着句子的概率就越大,则语言模型就越好。
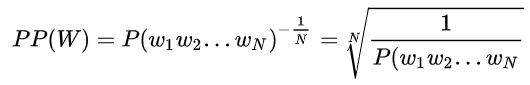
2-3、平滑方法
因为在求一些句子的整体概率时,如若句子中某些词的概率为0,则句子整体出现的概率一定为0,为了防止这种情况的发生,我们引入了平滑方法。
2-3-1、Add-one Smoothing(拉普拉斯平滑)
拉普拉斯平滑:分子加一,分母加V(V:词典的大小),效果相对其它平滑方法来说比较差。

2-3-2、Add-K Smoothing
加k平滑:分子加k,分母加kv(k:选择不同的k来尝试一下)。是拉普拉斯平滑的一个改进方法。
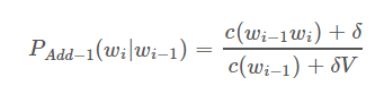
2-3-3、Interpolation
差值平滑:在计算Trigram概率的同时考虑Unigram,Bigram,Trigram出现的频次。每一种方法给一个权重,权重的和一定得为1。简单来说,就是把不同阶的模型结合起来。
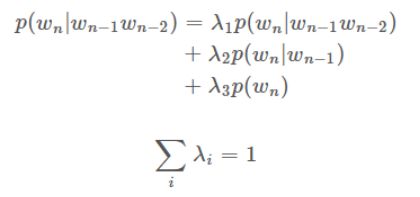
2-3-4、Good-Turning Smoothing
假设我们在钓鱼,钓到一条金鱼,两条鲤鱼。
默认情况下
未知的数据:我们认为钓到下一条鱼是鲫鱼的概率为0,即什么都不考虑。
已知的数据:我们认为下一条鱼是金鱼的概率是三分之一,即根据当前情况直接得出,不考虑未知。
Good-Turning
未知的数据:
n 1 n_1 n1: 出现了一次的数据一共有几个类别
N:数据的总数
概率为: n 1 n_1 n1/N
即我们认为鲫鱼出现的概率是1/3
已知的数据:
r:数据已经出现的次数
n r n_r nr: 出现了r次的数据一共有几个类别
公式是:
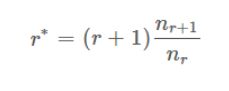
缺点: 因为要依赖后续的出现次数,但是后续出现次数可能是没有的,需要先使用机器学习去拟合一下曲线。
优点:具备一些准确率的,特别是在构建语言模型的时候。
2-4、特征选择技术
2-4-1、All Subsets
含义:依次选择单个特征构建模型,依次选择两个特征构建模型…直到选择所有特征构建模型。评估所有构建模型的准确率,选择模型准确率最高的。
缺点:特征比较多时,计算量太大,复杂度呈指数级增加。
2-4-2、Greedy Approaches
Forward Stepwise:(贪心算法)
1、依次选择单个特征构建模型,找到单个特征构建出来的模型准确率最高的特征。
2、将找到的最好的单个特征放入best_feature_set中,
3、使用一步骤找到的最好特征与其余的每个特征依次组合,选择构建出来准确率最高模型的特征。
4、将第二个找到的最好的单个特征放入best_feature_set中。
5、按照上边的步骤循环。
6、最终best_feature_set中放的就是可以使得模型准确率最高的一些特征。
注意:上边循环的终止条件是,下一次找到模型的准确率没有上一次的高,则终止循环。
Backward Stepwise: 与Forward Stepwise相反。
0、先计算出包含所有特征模型的准确率。
1、拿出所有特征,依次删掉单个特征,使用剩下的特征依次构建模型,找到使得模型准确率最高的一个组合。
2、将组合放入best_feature_set中。
3、下边的步骤和Forward Stepwise相同。
2-4-3、使用正则的方式筛选特征
Lasso回归:即引入L1范数惩罚项
2-5、特征构建(命名实体识别)
2-5-1、词袋特征
1、当前词
2、前后词
3、前前词、后后词
4、Bi-gram
5、Tri-gram
2-5-2、词性
1、当前词词性
2、前后词词性
3、前前词、后后词词性
2-5-3、前缀&后缀
1、当前词前后缀
2、前后词语前后缀
3、前前后后词前后缀
2-5-4、当前词的特性
1、词长
2、含有多少个大写字母
3、是否大写开头
4、前面词是否包含大写
5、是否包含数字
2-5-5、案例
ner_dataset.csv:一个标记好的表格
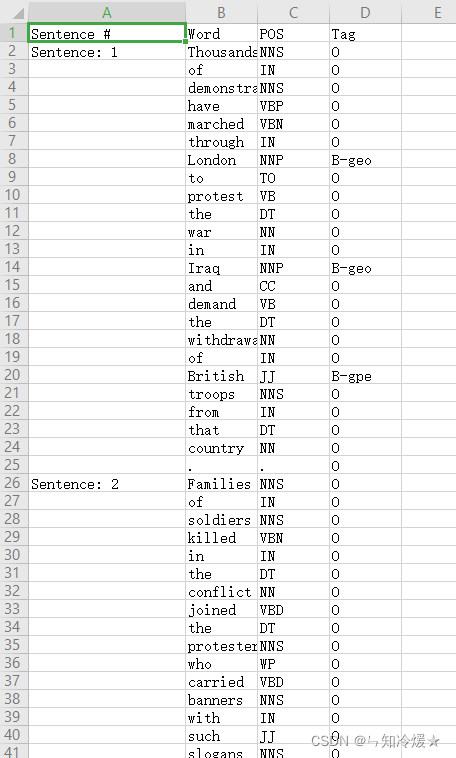
import pandas as pd
import numpy as np
data = pd.read_csv("ner_dataset.csv", encoding="latin1")
# 参数ffill:用前一个非缺失值去填充该缺失值。
data = data.fillna(method="ffill")
data.tail(10)
# 单词去重
words = list(set(data["Word"].values))
n_words = len(words);
def get_sentences(data):
# 聚合函数
# zip():从参数中的多个迭代器选取元素组合成一个新的迭代器
# 返回一个zip对象。
# 传入的参数是元组、列表、字典等迭代器。
agg_func = lambda s: [(w, p, t) for w, p, t in
zip(s["Word"].values.tolist(),
s["POS"].values.tolist(),
s["Tag"].values.tolist())]
sentence_grouped = data.groupby("Sentence #").apply(agg_func)
return [s for s in sentence_grouped]
sentences = get_sentences(data)
sentences:
[[('Thousands', 'NNS', 'O'),
('of', 'IN', 'O'),
('demonstrators', 'NNS', 'O'),
('have', 'VBP', 'O'),
('marched', 'VBN', 'O'),
('through', 'IN', 'O'),
('London', 'NNP', 'B-geo'),
('to', 'TO', 'O'),
('protest', 'VB', 'O'),
('the', 'DT', 'O'),………………
def word2features(sent, i):
"""
给每一个单词添加特征。
单词的小写、前缀、后缀、单词是否是大写的?是否是数字?单词对应的pos?pos的前缀等等。
如果单词为首个单词,需要设置BOS键值为True
如果单词为末尾单词,需要添加EOS键值为True
除此以外,除了首字母的所有单词还需要添加前一个单词的特征
除了末尾字母的所有单词还需要添加后一个单词的特征
"""
# 把每一个三元组的单词和pos拿出来
word = sent[i][0]
postag = sent[i][1]
features = {
'bias': 1.0,
'word.lower()': word.lower(),
'word[-3:]': word[-3:],
'word[-2:]': word[-2:],
'word.isupper()': word.isupper(),
'word.istitle()': word.istitle(),
'word.isdigit()': word.isdigit(),
'postag': postag,
'postag[:2]': postag[:2],
}
if i > 0: # word_prev, word_curr
# 如果i大于0,把前一个单词和它对应的pos取出来
word1 = sent[i-1][0]
postag1 = sent[i-1][1]
features.update({
'-1:word.lower()': word1.lower(),
'-1:word.istitle()': word1.istitle(),
'-1:word.isupper()': word1.isupper(),
'-1:postag': postag1,
'-1:postag[:2]': postag1[:2],
})
else:
features['BOS'] = True
if i < len(sent)-1:
word1 = sent[i+1][0]
postag1 = sent[i+1][1]
features.update({
'+1:word.lower()': word1.lower(),
'+1:word.istitle()': word1.istitle(),
'+1:word.isupper()': word1.isupper(),
'+1:postag': postag1,
'+1:postag[:2]': postag1[:2],
})
else:
features['EOS'] = True
return features
def sent2features(sent):
# i对应句子中的每一个三元组
return [word2features(sent, i) for i in range(len(sent))]
def sent2labels(sent):
return [label for token, postag, label in sent]
def sent2tokens(sent):
return [token for token, postag, label in sent]
# 遍历所有句子。
# s对应每一个句子,有很多三元组。
X = [sent2features(s) for s in sentences]
#
y = [sent2labels(s) for s in sentences]
from sklearn_crfsuite import CRF
crf = CRF(algorithm='lbfgs',
c1=0.1,
c2=0.1,
max_iterations=100)
from sklearn.model_selection import cross_val_predict
from sklearn_crfsuite.metrics import flat_classification_report
pred = cross_val_predict(estimator=crf, X=X, y=y, cv=5)
from sklearn.model_selection import cross_val_predict
from sklearn_crfsuite.metrics import flat_classification_report
pred = cross_val_predict(estimator=crf, X=X, y=y, cv=5)
三、自然语言处理流程
3-1 分词
分词的方法:
1、基于匹配规则的方法
2、基于概率统计的方法(LM、HMM、CRF)
常用分词工具:jieba(jieba的安装以及一些使用)、SnowNLP,LTP(哈工大),北京大学开源分词工具pkuseg,HanNLP,NLTK等。
句子分词流程如下:

3-2 预处理
数据清洗:无用的标签、特殊符号、大小写转换等。
拼写纠错:编辑距离为1、2:即原单词增加单词、替换单词、删除单词的操作步数为1或者是2。
过滤:将生成的单词进行过滤,如果词库里没有就过滤掉。
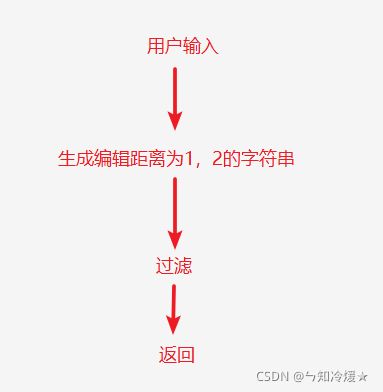
停用词处理、词语过滤:把停用词、出现频率很低的词汇过滤掉。除此以外,也要考虑一下自己的应用场景。
同义词:意义相同单词的一个合并。
词语合并、标准化:通常是对于英文来说的,单词各种形式的一个合并。
3-3 文本表示
将文本转化为向量:One-Hot编码的方式。
3-3-1 (特征提取)转换为tf-idf的形式:
因为one-hot编码并不能表示句子中哪个单词是比较重要的,所以这时候就需要tf-idf来解决这个问题。
# TF-IDF是一种统计方法,用于评估一字词对于一个文件集或一个语料库中的其中一份文件的重要程度。
# 字词的重要性会随着它在文件中出现的次数成正比增加,但是同时会随着它在语料库中出现的频率成反比下降。
# 某一个词对于文章的重要性越高,那么它的tf-idf的值就越大。
# TF:词频,表现词条在文本中出现的频率,被归一化,防止偏向长的文件。
# tf = 词条w在文档中出现的总次数/文档的词总数
# IDF:逆文件频率
# idf = log(文档总数/(包含该词的文档数+1))
# 某一特定词语的IDF,可以由总文件数目除以包含该词语的文件的数目,再将得到的商取对数得到。
# 公式: TF*IDF
from sklearn.feature_extraction.text import TfidfVectorizer
train_document = ["The flowers are beautiful.",
"The name of these flowers is rose, they are very beautiful.",
"Rose is beautiful",
"Are you like these flowers?"]
test_document = ["The flowers are mine.",
"My flowers are beautiful"]
#利用函数获取文档的TFIDF值
print("计算TF-IDF权重")
transformer = TfidfVectorizer()
# fit(): 根据训练集生成词典和逆文档词频
# transform():使用fit学习的词汇和文档频率,将文档转化为文档-词矩阵。
X_train = transformer.fit_transform(train_document)
X_test = transformer.transform(test_document)
#观察各个值
#(1)统计词列表
word_list = transformer.get_feature_names() # 所有统计的词
print("统计词列表")
print(word_list)
#(2)统计词字典形式
print("统计词字典形式")
print(transformer.fit(test_document).vocabulary_)
#(3)TFIDF权重
weight_train = X_train.toarray()
weight_test = X_test.toarray()
print("train TFIDF权重")
print(weight_train)
print("test TFIDF权重")
print(weight_test)
#(4)查看逆文档率(IDF)
print("train idf")
print(transformer.fit(train_document).idf_)
3-3-2(特征提取)(CountVectorizer):
# 对于每一个训练文本,它只是考虑每种词汇在该训练文本出现的频率
# 它会将文本中的词语转换为词频矩阵,通过fit_transform函数来计算每个词语出现的次数。
# CountVectorizer是在sklearn的feature_extraction里
from sklearn.feature_extraction.text import CountVectorizer
corpus = [
'This is the first document.',
'This document is the second document.',
'And this is the third one.',
'Is this the first document?',
]
vectorizer = CountVectorizer()
# fit: 根据CountVectorizer参数规则进行操作,比如说过滤停用词,拟合原始数据,生成文档中有价值的词汇表
# transform: 使用符合fit的词汇表或者是提供给构造函数的词汇表,从原始文本文档中提取词频,转换成词频矩阵。
# fit_transform: 拟合模型,并且返回一个文本矩阵。
X = vectorizer.fit_transform(corpus)
print(type(X))
# get_feature_names: 得到所有文本的词汇,是一个列表。
print(vectorizer.get_feature_names())
# ['and', 'document', 'first', 'is', 'one', 'second', 'the', 'third', 'this']
# vocabulary_: 所有文本组成的一个词汇表,是一个字典类型
print(vectorizer.vocabulary_)
# 返回停用词列表,默认的话是空的
print(vectorizer.stop_words_)
# toarray(): 将结果转化为稀疏矩阵的表达方式。
print(X.toarray())
3-3-3(特征提取)(Keras.Embedding层):
# 适合深度学习
# one-hot编码得到的向量是二进制的、稀疏的。
# 而词嵌入是低维的浮点数向量(密集向量)
# 从数据学习中得到,可以很好的反映词与词之间的关系。
import tensorflow as tf
from tensorflow import keras
from keras.datasets import imdb
# 作为特征的单词个数为10000
max_features = 10000
# 评论长度限制为20个单词
maxlen = 20
(x_train, y_train),(x_test, y_test)=imdb.load_data(num_words=max_features)
x_train = keras.preprocessing.sequence.pad_sequences(x_train,maxlen=maxlen)
x_test = keras.preprocessing.sequence.pad_sequences(x_test,maxlen=maxlen)
from tensorflow.keras.models import Sequential
from tensorflow.keras.layers import Flatten,Dense,Embedding
model = Sequential()
# 指定Embedding层的最大输入长度,Embedding层的激活激活形状为(samples,maxlen, 8)
model.add(Embedding(10000, 8, input_length=maxlen))
# 将三维的嵌入张量展平成形状为(samples, maxlen*8)的二维张量。
model.add(Flatten())
model.add(Dense(1, activation='sigmoid'))
model.compile(optimizer='rmsprop', loss='binary_crossentropy', metrics=['acc'])
model.summary()
history = model.fit(x_train, y_train, epochs=10, batch_size=32, validation_split=0.2)
(特征提取)词向量方式(Word2Vec):
seq2seq方式:
注意:
1、表示成词向量之后可以绘制在二维图上,观察词向量之间的关系是否符合常理。
3-4 计算相似度并排序:
欧式距离: d = |s1-s2| (s1、s2是已经转换完的两个句子向量,类似于求平面两点的距离,值越小,说明句子的相似度越高)
欧氏距离缺点:没有考虑方向,只考虑了大小。
余弦相似度:d = (s1·s2)/(|s1|*|s2|) (s1和s2进行内积, 分母的话类似于进行了标准化,值越大,说明句子的相似度越高。)
注意:一旦我们采用了one-hot编码,那我们是无法表示语义的相似度的。
3-5 再一次进行过滤(可选)
3-6 返回结果
参考文章:
深入浅出讲解语言模型.
在线NLP课程.
Statistical language model 统计语言模型.
求通俗解释NLP里的perplexity是什么?.
n-gram语言模型原理到实践.
【简单理解】自然语言处理-平滑方法(Smoothing).
总结
今天有亿点点困,呃,应该说每天都很困。