【pytorch】Densenet121迁移学习训练可视化
一、前言
由于要写相关的论文,仅仅只能做到训练和识别是远远不够的,必须有相关的训练过程的数据和图片来说明问题,所以我又又又写了篇关于迁移学习的文章,主要是更换了神经网络模型和增加了训练可视化这个模块,将SGD优化器更改成了Adam优化器,且使用ReduceLROnPlateau进行学习率的自适应调整。
先来看看Densenet的大致结构:
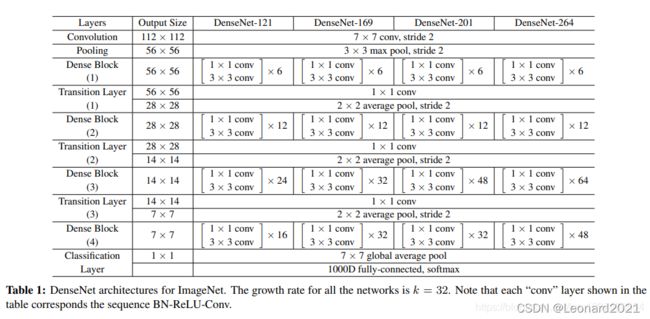
由于论文还未发布,出于安全考虑,我这里暂时不公布数据集。
这里给出大致的项目文件布局:
项目文件夹
--datasets
----train
----val
----test
--train.py
--predict_single.py
--predict_many.py
--Dataset_enhancement.py
--densenet121-a639ec97.pth
这里是用于迁移学习的Densenet121官方预训练模型:
densenet121-a639ec97.zip-深度学习文档类资源-CSDN下载z
我的代码是根据 pytorch迁移学习官方教程 爆改而来,这里给出官方教程:Transfer Learning for Computer Vision Tutorial — PyTorch Tutorials 1.11.0+cu102 documentation
二、代码
1.Dataset_segmentation.py
用于将数据集按 train : val :test = 8 : 1 :1 复制分配好,完成后备份好原数据集即可
# 工具类
import os
import random
import shutil
from shutil import copy2
"""
数据集默认的比例是--训练集:验证集:测试集=8:1:1
"""
def data_set_split(src_data_folder, target_data_folder, train_scale=0.8, val_scale=0.1, test_scale=0.1):
'''
读取源数据文件夹,生成划分好的文件夹,分为trian、val、test三个文件夹进行
:param src_data_folder: 源文件夹
:param target_data_folder: 目标文件夹
:param train_scale: 训练集比例
:param val_scale: 验证集比例
:param test_scale: 测试集比例
:return:
'''
print("开始数据集划分")
class_names = os.listdir(src_data_folder)
# 在目标目录下创建文件夹
split_names = ['train', 'val', 'test']
for split_name in split_names:
split_path = os.path.join(target_data_folder, split_name)
if os.path.isdir(split_path):
pass
else:
os.mkdir(split_path)
# 然后在split_path的目录下创建类别文件夹
for class_name in class_names:
class_split_path = os.path.join(split_path, class_name)
if os.path.isdir(class_split_path):
pass
else:
os.mkdir(class_split_path)
# 按照比例划分数据集,并进行数据图片的复制
# 首先进行分类遍历
for class_name in class_names:
current_class_data_path = os.path.join(src_data_folder, class_name)
current_all_data = os.listdir(current_class_data_path)
current_data_length = len(current_all_data)
current_data_index_list = list(range(current_data_length))
random.shuffle(current_data_index_list)
train_folder = os.path.join(os.path.join(target_data_folder, 'train'), class_name)
val_folder = os.path.join(os.path.join(target_data_folder, 'val'), class_name)
test_folder = os.path.join(os.path.join(target_data_folder, 'test'), class_name)
train_stop_flag = current_data_length * train_scale
val_stop_flag = current_data_length * (train_scale + val_scale)
current_idx = 0
train_num = 0
val_num = 0
test_num = 0
for i in current_data_index_list:
src_img_path = os.path.join(current_class_data_path, current_all_data[i])
if current_idx <= train_stop_flag:
copy2(src_img_path, train_folder)
# print("{}复制到了{}".format(src_img_path, train_folder))
train_num = train_num + 1
elif (current_idx > train_stop_flag) and (current_idx <= val_stop_flag):
copy2(src_img_path, val_folder)
# print("{}复制到了{}".format(src_img_path, val_folder))
val_num = val_num + 1
else:
copy2(src_img_path, test_folder)
# print("{}复制到了{}".format(src_img_path, test_folder))
test_num = test_num + 1
current_idx = current_idx + 1
print("*********************************{}*************************************".format(class_name))
print(
"{}类按照{}:{}:{}的比例划分完成,一共{}张图片".format(class_name, train_scale, val_scale, test_scale, current_data_length))
print("训练集{}:{}张".format(train_folder, train_num))
print("验证集{}:{}张".format(val_folder, val_num))
print("测试集{}:{}张".format(test_folder, test_num))
if __name__ == '__main__':
src_data_folder = r".\color" #划分前的数据集的位置
target_data_folder = r".\dataset" #划分后的数据集的位置
data_set_split(src_data_folder, target_data_folder)2.train.py
# --coding:utf-8--
import torch
import torch.nn as nn
import torch.optim as optim
from torch.optim import lr_scheduler
import numpy as np
import torchvision
from torchvision import datasets, models, transforms
import matplotlib.pyplot as plt
import time
import os
import copy
from tensorboardX import SummaryWriter
import json
# 获得数据生成器,以字典的形式保存。
data_transforms = {
'train': transforms.Compose([
transforms.RandomResizedCrop(224),
transforms.RandomHorizontalFlip(),
transforms.ToTensor(),
transforms.Normalize([0.485, 0.456, 0.406], [0.229, 0.224, 0.225])
]),
'val': transforms.Compose([
transforms.Resize(256),
transforms.CenterCrop(224),
transforms.ToTensor(),
transforms.Normalize([0.485, 0.456, 0.406], [0.229, 0.224, 0.225])
]),
}
data_dir = r'D:\pyCharmdata\resnet50_plant_3\datasets'
image_datasets = {x: datasets.ImageFolder(os.path.join(data_dir, x),
data_transforms[x])
for x in ['train', 'val']}
dataloaders = {x: torch.utils.data.DataLoader(image_datasets[x], batch_size=4,
shuffle=True, num_workers=0)#单线程
for x in ['train', 'val']}
# 数据集的大小
dataset_sizes = {x: len(image_datasets[x]) for x in ['train', 'val']}
# 类的名称
class_names = image_datasets['train'].classes
# 有GPU就用GPU训练
device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu")
train_dataset = datasets.ImageFolder(os.path.join(data_dir, 'train'),
data_transforms['train'])
train_num = len(train_dataset)
flower_list = train_dataset.class_to_idx
cla_dict = dict((val, key) for key, val in flower_list.items())
# write dict into json file
json_str = json.dumps(cla_dict, indent=4)
with open('class_indices.json', 'w') as json_file:
json_file.write(json_str)
# 模型训练和参数优化
def train_model(model, criterion, optimizer, scheduler, num_epochs):
since = time.time()
best_model_wts = copy.deepcopy(model.state_dict())
best_acc = 0.0
for epoch in range(num_epochs):
print('Epoch {}/{}'.format(epoch, num_epochs - 1))
print('-' * 10)
# Each epoch has a training and validation phase
for phase in ['train', 'val']:
if phase == 'train':
#scheduler.step()
model.train() # Set model to training mode
else:
model.eval() # Set model to evaluate mode
running_loss = 0.0
running_corrects = 0
# Iterate over data.
for inputs, labels in dataloaders[phase]:
inputs = inputs.to(device)
labels = labels.to(device)
# zero the parameter gradients
optimizer.zero_grad()
# forward
# track history if only in train
with torch.set_grad_enabled(phase == 'train'):
outputs = model(inputs)
_, preds = torch.max(outputs, 1)
loss = criterion(outputs, labels)
# backward + optimize only if in training phase
if phase == 'train':
loss.backward()
optimizer.step()
# statistics
running_loss += loss.item() * inputs.size(0)
running_corrects += torch.sum(preds == labels.data)
epoch_loss = running_loss / dataset_sizes[phase]
epoch_acc = running_corrects.double() / dataset_sizes[phase]
if phase == 'train':
scheduler.step(epoch_loss)
optimizer.step()
writer.add_scalar('loss_%s' % phase, epoch_loss, epoch)
writer.add_scalar('acc_%s' % phase, epoch_acc, epoch)
writer.add_histogram('loss_%s' % phase,epoch_loss, epoch)
writer.add_histogram('acc_%s' % phase, epoch_acc, epoch)
print('{} Loss: {:.4f} Acc: {:.4f}'.format(
phase, epoch_loss, epoch_acc))
# deep copy the model
if phase == 'val' and epoch_acc > best_acc:
best_acc = epoch_acc
best_model_wts = copy.deepcopy(model.state_dict())
print()
time_elapsed = time.time() - since
print('Training complete in {:.0f}m {:.0f}s'.format(
time_elapsed // 60, time_elapsed % 60))
print('Best val Acc: {:4f}'.format(best_acc))
# load best model weights
model.load_state_dict(best_model_wts)
return model
if __name__ == '__main__':
model_ft = models.densenet121() # pretrained=True
model_weight_path = "./densenet121-a639ec97.pth"
assert os.path.exists(model_weight_path), "file {} does not exist.".format(model_weight_path)
# net.load_state_dict载入模型权重。torch.load(model_weight_path)载入到内存当中还未载入到模型当中
missing_keys, unexpected_keys = model_ft.load_state_dict(torch.load(model_weight_path), strict=False)
writer = SummaryWriter()
'''冻结网络和参数
for param in model_ft.parameters():
param.requires_grad = False'''
num_ftrs = model_ft.classifier.in_features
model_ft.classifier = nn.Linear(num_ftrs, 3) # 分类种类个数
# 神经网络可视化
images = torch.zeros(1, 3, 224, 224)#要求大小与输入图片的大小一致
writer.add_graph(model_ft, images, verbose=False)
model_ft = model_ft.to(device)
criterion = nn.CrossEntropyLoss()
# Observe that all parameters are being optimized
#optimizer_ft = optim.SGD(model_ft.parameters(), lr=0.001, momentum=0.9)
optimizer_ft = optim.Adam(model_ft.parameters(), lr=0.001)
# Decay LR by a factor of 0.1 every 7 epochs
#exp_lr_scheduler = lr_scheduler.StepLR(optimizer_ft, step_size=30, gamma=0.1)
exp_lr_scheduler = lr_scheduler.ReduceLROnPlateau(optimizer_ft, mode='min', factor=0.1, patience=5, verbose=False,
threshold=0.0001, threshold_mode='rel', cooldown=0, min_lr=0,
eps=1e-08)#自适应学习率调整
model_ft = train_model(model_ft, criterion, optimizer_ft, exp_lr_scheduler,
num_epochs=100) # 训练次数
writer.close()
torch.save(model_ft.state_dict(), 'models/Densenet121_myself.pt')3.predict_single.py
对单张图片进行预测
import torch
from PIL import Image
import matplotlib.pyplot as plt
import json
from torchvision import datasets, models, transforms
import torch.nn as nn
#单张图片预测
if __name__ == '__main__':
device = torch.device("cpu") # "cuda:0" if torch.cuda.is_available() else"cpu"
data_transform = transforms.Compose(
[transforms.Resize(256),
transforms.CenterCrop(224),
transforms.ToTensor(),
transforms.Normalize([0.485, 0.456, 0.406], [0.229, 0.224, 0.225])]) # 预处理
# load image
img = Image.open(r"D:\pyCharmdata\resnet50_plant_3\datasets\test\zheng_chang\000000.jpg") # 导入需要检测的图片
plt.imshow(img)
# [N, C, H, W]
img = data_transform(img)
# expand batch dimension
img = torch.unsqueeze(img, dim=0)
# read class_indict
try:
json_file = open('./class_indices.json', 'r')
class_indict = json.load(json_file)
except Exception as e:
print(e)
exit(-1)
model = models.densenet121()
num_ftrs = model.classifier.in_features
model.classifier = nn.Linear(num_ftrs, 3) # 识别种类数
model = model.to(device)
model.load_state_dict(torch.load('models/Densenet121_myself.pt'))
model.eval()
with torch.no_grad(): # 不对损失梯度进行跟踪
# predict class
output = torch.squeeze(model(img)) # 压缩batch维度
predict = torch.softmax(output, dim=0) # 得到概率分布
predict_cla = torch.argmax(predict).numpy() # argmax寻找最大值对应的索引
print(class_indict[str(predict_cla)], predict[predict_cla].numpy())
plt.show()
4.predict_many.py
对test文件夹进行批量预测:
test文件夹布局为:
test文件夹
--种类1文件夹
--种类2文件夹
--种类3文件夹
----等等# --coding:utf-8--
import torch
import torch.nn as nn
import torch.optim as optim
from torch.optim import lr_scheduler
import numpy as np
import torchvision
from torchvision import datasets, models, transforms
import matplotlib.pyplot as plt
import time
import os
import copy
from tensorboardX import SummaryWriter
# 大批量随机预测
if __name__ == '__main__':
# 获得数据生成器,以字典的形式保存。
data_transforms = {
'test': transforms.Compose([
transforms.Resize(256),
transforms.CenterCrop(224),
transforms.ToTensor(),
transforms.Normalize([0.485, 0.456, 0.406], [0.229, 0.224, 0.225])
]),
}
data_dir = r'D:\pyCharmdata\resnet50_plant_3\datasets'
image_datasets = {x: datasets.ImageFolder(os.path.join(data_dir, x),
data_transforms[x])
for x in ['test']}
dataloaders = {x: torch.utils.data.DataLoader(image_datasets[x], batch_size=1,
shuffle=True, num_workers=0)
for x in ['test']}
# 数据集的大小
dataset_sizes = {x: len(image_datasets[x]) for x in ['train', 'val','test']}
# 类的名称
class_names = image_datasets['test'].classes
# 有GPU就用GPU
device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu")
# 单张测试可视化代码
model = models.densenet121()
num_ftrs = model.classifier.in_features
model.classifier = nn.Linear(num_ftrs, 3)#识别种类数
model = model.to(device)
model.load_state_dict(torch.load('models/Densenet121_myself.pt'))
model.eval()
def imshow(inp, title=None):
"""Imshow for Tensor."""
inp = inp.numpy().transpose((1, 2, 0))
mean = np.array([0.485, 0.456, 0.406])
std = np.array([0.229, 0.224, 0.225])
inp = std * inp + mean
inp = np.clip(inp, 0, 1)
plt.imshow(inp)
if title is not None:
plt.title(title)
with torch.no_grad():
for i, (inputs, labels) in enumerate(dataloaders['test']):#val
inputs = inputs.to(device)
labels = labels.to(device)
outputs = model(inputs)
_, preds = torch.max(outputs, 1)
''''''
output = torch.squeeze(outputs) # 压缩batch维度
predict = torch.softmax(output, dim=0) # 得到概率分布
predict_cla = torch.argmax(predict).cpu().numpy()
print('预测概率为:%s'%predict[predict_cla].cpu().numpy())
imshow(inputs.cpu().data[0], 'predicted: {}'.format(class_names[preds[0]]))
plt.show()
配置好数据集路径和python环境后,运行train.py即可训练,默认是训练100轮,你也可以自己调整轮数。我训练了100轮后,最高准确率可达:
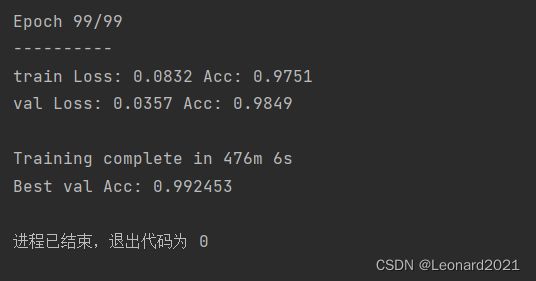
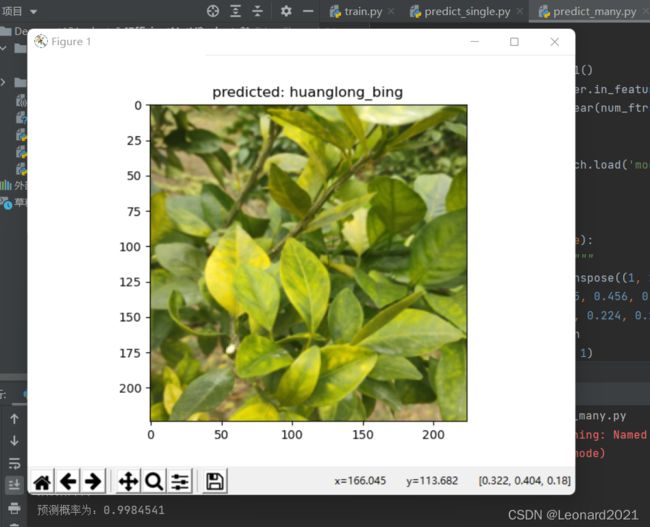
由于使用的是自适应学习率ls,你可以直接调大训练轮数即可提高准确率,无需调整其他参数。
训练过程中或者训练完成后,在pyCharm项目路径下的终端输入:
tensorboard --logdir=runs/则会弹出:

点击该网址即可弹出Tensorboard的可视化界面,使用 CTRL+C即可结束更新,本人使用火狐浏览器可正常打开,如图:
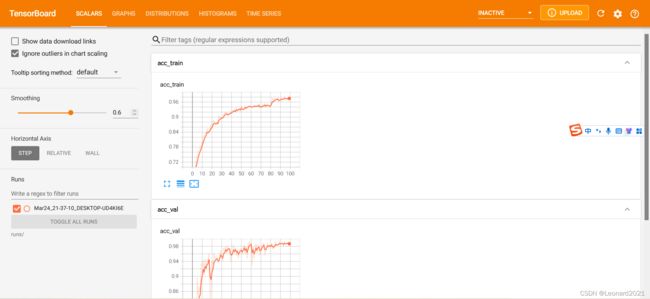

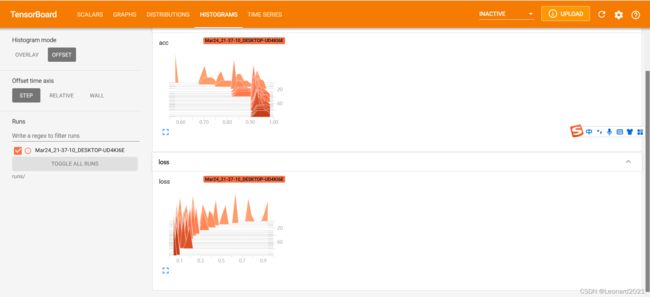
有图有真相,数据图说明一切,水论文必备。
这里给出我的完整项目文件:
Densenet121.zip-深度学习文档类资源-CSDN下载