【论文阅读IJCAI-19】Hybrid Actor-Critic Reinforcement Learning in Parameterized Action Space
【论文阅读IJCAI-19】Hybrid Actor-Critic Reinforcement Learning in Parameterized Action Space
标题 Hybrid Actor-Critic Reinforcement Learning in Parameterized Action Space
会议 IJCAI-19
论文地址
https://arxiv.org/pdf/1903.01344.pdf
https://www.ijcai.org/Proceedings/2019/0316.pdf
关键点 离散连续空间联合优化

最近在调研强化学习离散连续空间联合优化的相关文章,找到这一篇19年上交的文章,记录一下供日后参考。
摘要
提出了一种 actor-critic 的混合模型算法 for reinforcement learning in parameterized action space,并且在PPO算法上面做出了改进,提出了 hybrid proximal policy optimization (H-PPO) 算法,并通过了实验验证了该算法的可靠性。
核心思想
传统的RL大多只针对于连续的或者离散的空间提出优化的方案,但是实际情况下更多的是混合的空间,如在足球场上踢球,在离散的空间中,agent只能选择跑动或者踢球的方向但是不能选择连续的跑动速度/距离或者踢球的力度,但是在混合空间下,使得agent 有可能做出离散 + 连续的选择。传统的RL无法有效的处理混合空间中的联合优化,因此文章提出了一个新的框架来解决这种方法,这种框架基于actor-critic 形式,policy gradient 和 PPO 都可以有效的同时处理离散的和连续的空间,文章选择了在PPO基础上提出H-PPO算法。
文章标题中提到的 Parameterized Action Space,个人理解动作空间可以被分层,每一层的维度可以改变,是"Parameterized" 的。文章的解释如下:
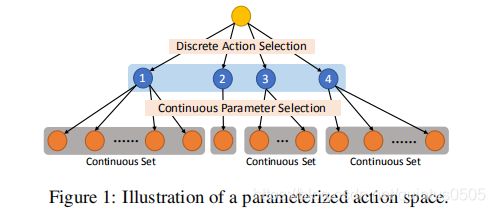
这张图片展示了 Parameterized Action Space 的结构,离散的动作空间拥有四个不同的action (蓝色),每一个离散的动作拥有连续的parameter space (灰色)。action 2 比较特别,连续的parameter space 中只有一个元素,但是并不妨碍将其和其他动作一样划分。
文章举出基于RoboCup 2D 仿真平台的子任务Half Field Offense (HFO),agent 可以选择离散的动作Kick 并且对real-valued parameter(power and direction) 进行细化。
Methodologies
Parameterized action space
Parameterized action spaces 是离散-连续混合的空间,具体定义直接贴上原文:

Actor-critic algorithms
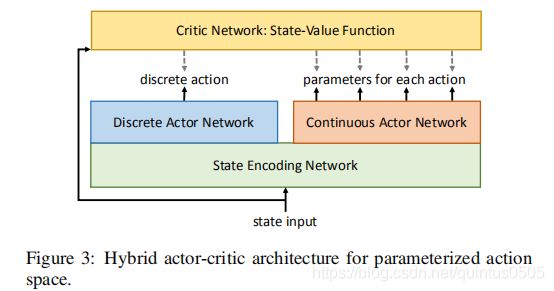
通常情况下,Actor-critic algroithms含有一个actor网络和用来计算actor网络parameters gradient 的critic 网络,文章提出的框架包含两个平行的actor网络,分别负责action选择和parameter选择:

执行的动作是选择的action a a a 以及对应的 x a x_a xa,
根据文章给出的Hybrid actor-critic 框架,所有的actor网络共享最初的用于encode的全连接网络中的state信息。
值得注意的是,框架中的single critic network 评估是是 state-value function V ( s ) V(s) V(s) 而不是action-value function. 由于 action-value function suffers from the over-parameterization problem 如果用 action-value fuction ,critic 网络会将 s s s,选择的 a a a以及所有被选择的离散动作的parameter x a 1 , x a 2 , . . . , x a k x_{a1},x_{a2},...,x_{ak} xa1,xa2,...,xak作为输入。不可能单独输入 x a x_a xa因为不同的离散动作的parameter的维度不同,同时输入其他独立的parameter会导致over-parameterization:
![]()
而state-value function V ( s ) V(s) V(s)并没有这个问题, V ( s ) V(s) V(s)用来计算variance-reduced advantage function estimator A ^ \hat{A} A^,将policy 跑T个timesteps:
![]()
唯一要注意的是optimization method 应该符合 actor critic style 而且用critic 提供的 advantage function来更新stochastic policies.
虽然完整的动作 ( a , x a ) (a,x_a) (a,xa)是由离散和联合的actor共同决定,但是两个actor是根据自己的策略单独更新的
Hybrid Proximal Policy Optimization
The hybrid proximal policy optimization (H-PPO) 依照上面的 Figure 3 框架和 PPO 更新离散的policy π θ d \pi_{\theta_d} πθd和连续的policy π θ c \pi_{\theta_c} πθc

更新步骤
对于离散的actions(假定有k个),H-PPO先输出k个value f a 1 , f a 2 , . . . , f a k f_{a_1},f_{a_2},...,f_{a_k} fa1,fa2,...,fak ,再通过softmax( f f f)随机采样出 a a a(这个地方我理解是每一个单独的离散action的actor从分布中采样出一个value,将这些value归一化后依据概率采样?)。对于连续的策略,和传统的PPO更新方法差不多(by outputting the mean and variance of a Gaussian distribution for each of the parameters),离散的和连续的完全分开更新。
Hybrid Actor-Critic Architecture for General Hierarchical Action Space

除了 parameterized action space,文章提出的hybrid actor-critic 算法可以延申到 general hierarchical action space,如前面Figure 2 所展示的树结构。每一个灰色的长方块代表一个action-selection sub-problem,整个动作的完成可以看作是离散-连续动作选择的迭代。
对于这种更加general的分层动作空间,Figure 4中展示了对应的hybrid actor-critic 框架。
实验
环境
实验选择了四个环境,如下图:

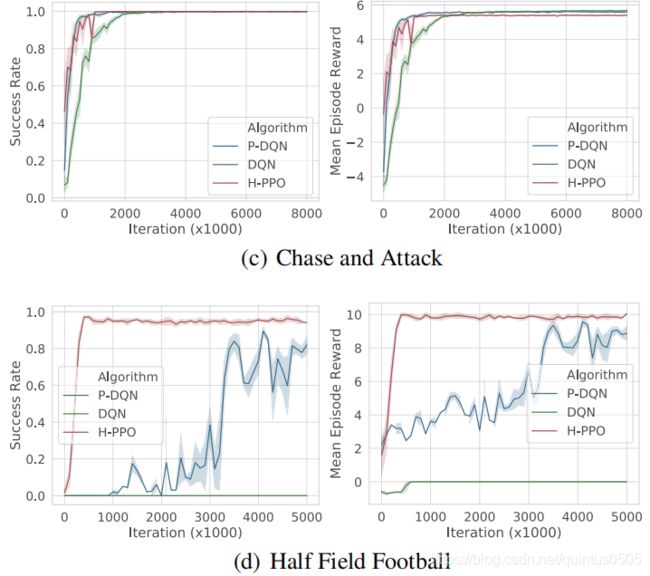
每一个实验任务中都有一个“winning state”的最终state,代表任务的成功。
四个任务的设定文章介绍如下:


结果
文章提出的框架和DQN,P-DQN(出自Parametrized deep q-networks learning: Reinforcement learning with discrete-continuous hybrid action space),DDPG(由于结果很差没有给出)进行比较:
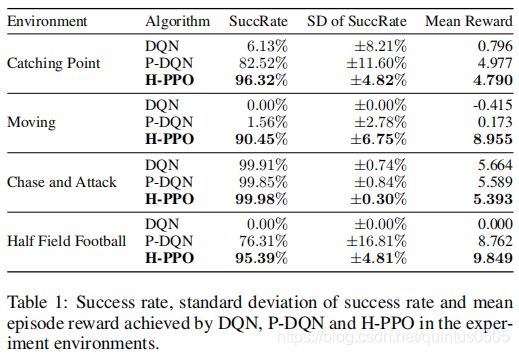
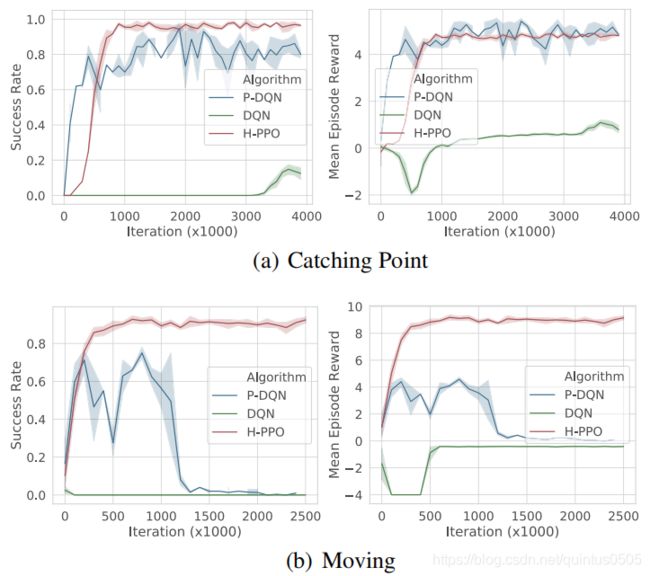

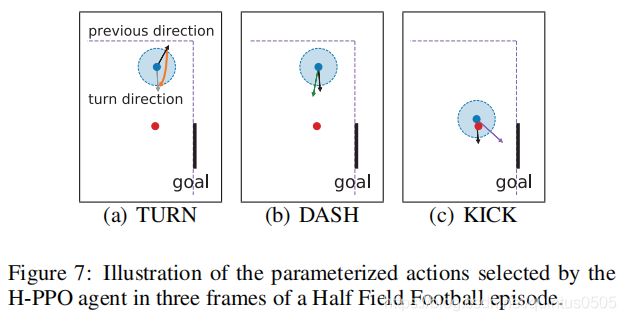
总结
对于混合的动作空间这篇文章提出了一种框架可以在动作基元的相关工作中试着使用一下。文章提到,后期的工作会常数做更多的实验来验证方案的可靠性。