【Django+MySQL】拆分详解图书管理系统案例
【Django+MySQL】拆分详解图书管理系统案例
在本科期间第二次遇到大作业需要使用Django+MySQL搭建数据库管理系统,这次以实现简单图书管理系统为目标,详细的记录每一步操作。
在第一次接触Django搭建数据库系统时,参考了这篇文章:https://blog.csdn.net/weixin_44953364/article/details/102993231
这个项目完成后,全部代码可见于github
项目要求
1 基本信息要求
图书基本信息包括:
- 图书ID
- 书名
- ISBN
- 出版社
- 出版年月
- 作者
- 标签(可选做)
读者基本信息包括:
- 读者ID
- 读者姓名
- 读者类型
- 读者联系电话
2 功能需求描述
- 图书信息维护。批量导入书目信息、手工添加书目信息、删除书目信息、修改书目信息。
图书购置批量入库(库存增加)、图书清理批量出库(因图书损坏,库存减少)。 - 读者信息维护。批量导入读者信息、手工添加读者、删除读者、修改读者信息。
- 图书信息查询。根据书名、作者、标签(可选做)、出版社和ISBN查询图书。显示库存数量,
根据图书库存数量显示是否可借。 - 读者信息查询。根据读者姓名或联系电话查询显示读者信息。查询显示读者在借图书信息。
查询显示读者借阅历史。 - 图书借出。
- 图书归还。
- 系统关闭。保存数据之后关闭系统。这些数据在系统启动的时候自动读入系统。
3 使用方法描述:
- 该系统由图书管理员操作,以上所有操作都不是由读者操作完成的。
- 同一个ID的图书可能有多本,库存量随着入库、出库而改变,可借数量随着借出、
归还而改变。库存量为可借数量与借出数量之和。 - 读者有两个类型:会员和非会员。主要区别是借阅的数量上限。会员上限8本,
非会员上限4本。当未还图书数量达到上限时,无法借阅。 - 只有在图书库存数量为0时,才可以删除书目。
4 菜单结构和导航设计:
不作强制要求。但有一些建议供考虑:
- 读者在借图书和借阅历史这两个功能(按钮或菜单),建议安排在读者信息显示界面。
- 图书借出功能,建议安排在图书显示界面。
- 图书归还功能,建议安排在读者在借图书界面。
- 图书入库和出库功能,建议安排在图书显示界面。
- 在每个子菜单下面需要考虑用户可能会继续操作,也可能希望返回主菜单。
首先是使用工具,由于之前有第一次的经历我已经成功安装好了两个工具— pycharm和navicat并配置好了anaconda环境(主要是Django)
首先在pycharm中创建Django环境,创建完成后,运行manage.py, 会发现创建了front/和templates/两个目录,分别是存放.py和.html文件
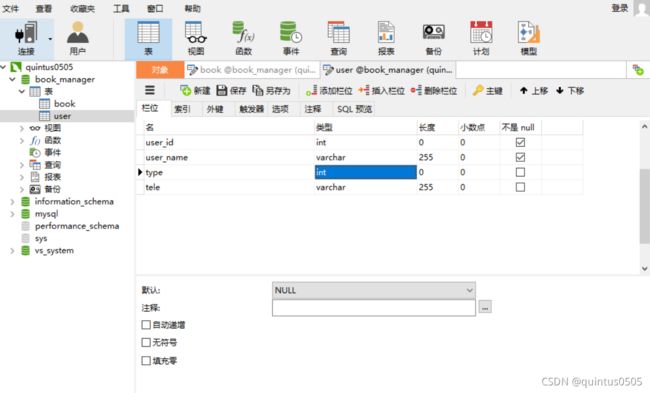
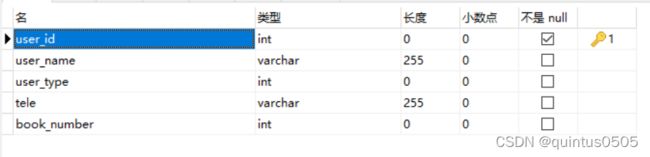
下面对照基本信息要求在navicat建立数据库以及对应的表与表项(这里的表名book, user在后面还修改过,修改就直接重命名,不需要其他操作):

接着,在setting.py中,更改DATABASES:
DATABASES = {
'default': {
'ENGINE': 'django.db.backends.mysql',
'NAME': 'book_manager', # 数据库名称
'USER':'root', # 数据库用户名
'PASSWORD':'zmkm', # 安装mysql时设置的数据库密码
'HOST':'127.0.0.1', # 数据库主机,默认用的是localhost
'PORT':'3306' # 数据库端口
}
}
在项目文件下面,运行如下指令:
python manage.py migrate
python manage.py makemigrations
产生如下输出,并且数据库刷新后如下,该步骤成功:

可以看见第二个运行指令没有产生变化,但是貌似不影响
后续先按照参考的文章中方法一步一步搭建。
功能能实现
手动逐一添加用户和图书
更新index.html:
<body>
<nav>
<ul class="nav">
<li><a href="/">首页a>li>
<li><a href="{% url 'book_info' %}">图书信息a>li>
<li><a href="{% url 'user_info' %}">用户信息a>li>
ul>
nav>
body>
效果如下:
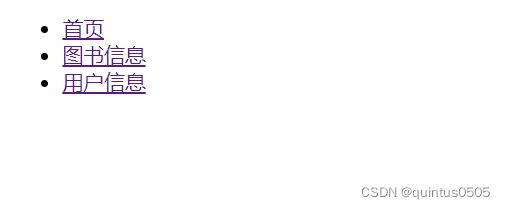
在urls.py中更新book_info, user_info, add_book, add_user 的路径:
from django.urls import path
from front import views
urlpatterns = [
path('', views.index, name='index'),
path('book_info/add_book/', views.add_book, name='add_book'),
path('book_info/', views.book_info, name='book_info'),
path('user_info/', views.user_info, name='user_info'),
path('user_info/add_user/', views.add_user, name='add_user'),
path('book_detail/', views.book_detail, name='book_detail'),
path('delete_book/',views.delete_book,name='delete_book'),
]
添加或修改html文件add_book.html, add_user.html, book_info.html, user_info.html, 由于book和user在这一步的结构基本相同,只展示user的添加方法:
{#{% extends 'base.html' %}#}
<body>
<nav>
<ul class="nav">
<li><a href="/">首页a>li>
<li><a href="{% url 'add_user' %}">添加用户a>li>
ul>
nav>
{% block content %}
{% endblock %}
body>
为了使操作者在任何位置都可以跳回主页,后面所有的html文件我都加上了下面这句:
<li><a href="/">首页a>li>
{#{% extends 'base.html' %}#}
{% block content %}
<li><a href="/">首页a>li>
<form action="" method="post">
<table>
<tbody>
<tr>
<td>读者姓名td>
<td><input type="text" name="user_name">td>
tr>
<tr>
<td>读者类型td>
<td><input type="text" name="user_type">td>
tr>
<tr>
<td>读者电话td>
<td><input type="text" name="tele">td>
tr>
<tr>
<td>td>
<td><input type="submit" value="提交">td>
tr>
tbody>
table>
form>
{% endblock %}
需要注意的是,输入有text和number两种type
结合path的定义,效果如下:
首页:
用户信息:

添加用户:

在view.py中,添加user_info, book_info, add_user, add_book
def user_info(request):
if request.method == 'GET':
return render(request, 'user_info.html')
else:
return redirect(reverse('index'))
def add_user(request):
if request.method == 'GET':
return render(request, 'add_user.html')
else:
try:
user_id = random.randint(10000, 20000)
user_name = request.POST.get("user_name")
user_type = int(request.POST.get("user_type"))
tele = request.POST.get("tele")
cursor = get_corsor()
cursor.execute(
"insert into the_user(user_id, user_name, user_type, tele, book_number) values('%d','%s','%d','%s','%d')" % (
user_id, user_name, user_type, tele, 0))
except:
pass
# 跳转到首页
return redirect(reverse('index'))
注意这里的插入部分
cursor.execute(
"insert into the_user(user_id, user_name, user_type, tele, book_number) \
values('%d','%s','%d','%s','%d')" \
% (user_id, user_name, user_type, tele, 0))
%d %s对应定义的表相应表项的属性。注意这里我的表名是"the_user",但是后续发现了小bug改成了"front_user", 由于这篇文章是按照每一步流程记录的,这里就不做修改。
展示用户和图书信息
这里同样只介绍如何在网页上显示数据库中存储的图书信息,用户信息同理可得
首先先展示该阶段成果:

放上修改后的html, 主要是生成了表格以及读取出全部信息
{% block content %}
<p>现有图书p>
<table border="1">
<tr>
<th>图书名称th>
<th>可借数量th>
<th>总数量th>
tr>
{% for book in Books %}
<tr>
<td>{{book.book_name}}td>
<td>{{book.current_number}}td>
<td>{{book.total_number}}td>
<td>
<form action="" method="post">
<input type="hidden" name="id" value={{book.book_id}}>
<input type="submit" name="alter_book_info" value="编辑">
form>
<td>
tr>
{# <p>{{book.book_name}},{{book.total_number}}p>#}
{% endfor %}
table>
{% endblock %}
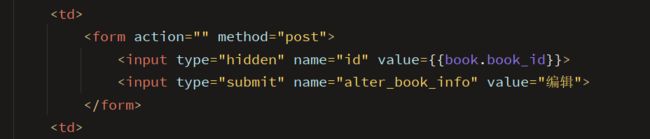
这里面最后一项"编辑"是为下一步修改做准备。通过如下代码,可以在表格中生成按钮,点击后post的id为该行的图书ID
首先先在front/models.py中添加Book和User两个类,相关属性须和数据库中属性统一
from __future__ import unicode_literals
from django.db import models
# Create your models here.
class Book(models.Model):
book_id = models.AutoField(primary_key=True)
book_name = models.CharField(max_length=50)
ISBN = models.CharField(max_length=50)
publish_date = models.CharField(max_length=50)
author = models.CharField(max_length=50)
label = models.CharField(max_length=30)
current_number = models.IntegerField()
total_number = models.IntegerField()
class User(models.Model):
user_id = models.AutoField(primary_key=True)
user_name = models.CharField(max_length=50)
user_type = models.CharField(max_length=50)
tele = models.CharField(max_length=50)
book_number = models.IntegerField()
修改view.py下book_info函数:
def book_info(request):
if request.method == 'GET':
Books = models.Book.objects.all()
return render(request, 'book_info.html', locals())
加上的那一句是把数据库中全部信息读取出来。这里可能会遇到一点小问题,先前数据库中表命名是"book",但是该代码只能读取"front_book"中间的数据,可以通过直接在Navicat中修改表的名字解决
修改图书和用户
这一步我没有添加新的html文件,直接用的旧的add_book和add_user。所有的更改基本在view.py中。
首先是现在urls.py下增加两条记录:

由于”编辑“按钮是在book_info\下面生成,修改view.py中的book_info函数:
def book_info(request):
if request.method == 'GET':
Books = models.Book.objects.all()
return render(request, 'book_info.html', locals())
elif request.POST.get('alter_book_info'):
id = request.POST.get("id")
newurl = '/alter_book_info/' + id
return redirect(newurl, locals())
else:
return redirect(reverse('index'))
这里的request.POST.get('alter_book_info'):对应了book_info.html中如下片段:
<form action="" method="post">
<input type="hidden" name="id" value={{book.book_id}}>
<input type="submit" name="alter_book_info" value="编辑">
form>
点击"编辑"按钮后,就会进入py中elif的环节。
添加新函数alter_book_info:
def alter_user_info(request):
if request.method == 'GET':
cur_url = str(request.path)
splited_url = cur_url.split('/')
id = splited_url[-1]
return render(request, 'add_user.html', locals())
else:
cur_url = str(request.path)
splited_url = cur_url.split('/')
id = splited_url[-1]
book = models.Book.objects.get(book_id=id)
if request.POST.get("book_name"):
book.book_name = request.POST.get("book_name")
if request.POST.get("ISBN"):
book.ISBN = request.POST.get("ISBN")
if request.POST.get("publish_date"):
book.publish_date = request.POST.get("publish_date")
if request.POST.get("author"):
book.author = request.POST.get("author")
if request.POST.get("label"):
book.label = request.POST.get("label")
if request.POST.get("total_number"):
new_total_number = int(request.POST.get("total_number"))
if new_total_number >= book.total_number or book.total_number - new_total_number < book.current_number: # 有新书入库
book.current_number += new_total_number - book.total_number
book.total_number = new_total_number
else: # 出库数量不应该大于图书馆现拥有数目
return render(request, 'error.html', locals())
book.save()
return redirect(reverse('index'))
这里两处url都需要和上文对应,通过该方法可以同时得到编辑的book_id, 后面代码都是和sql操作相关。
这里的error.html是简单的报错提醒,可以无视掉。最终实现的功能是,如果其他项不需要修改,可以直接忽略那些输入框
删除图书和读者
同样只介绍图书的删除,读者的删除操作方法相同
首先在book_info.html,user_info.html中添加删除按钮,放置在"编辑"后面。

这里在数据库的表项中添加了是否可借的项,供后续借阅功能使用,注意同时更新models.py下面对应的类


这个功能只需修改view.py下面的book_info和user_info两个函数

现通过id定位删除的书籍,按照要求,若数据库中该书的总数量为0才能删除,否则跳转至报错界面。
借书
设计将借还书都放在user_info中首先同上文操作相同,添加按钮:
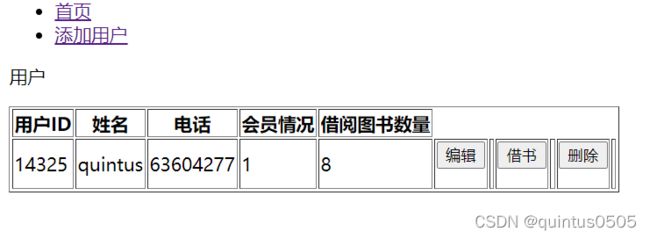
点击借书按钮后,跳转到http://127.0.0.1:8000/borrow_book/14325, 先展示整体界面:
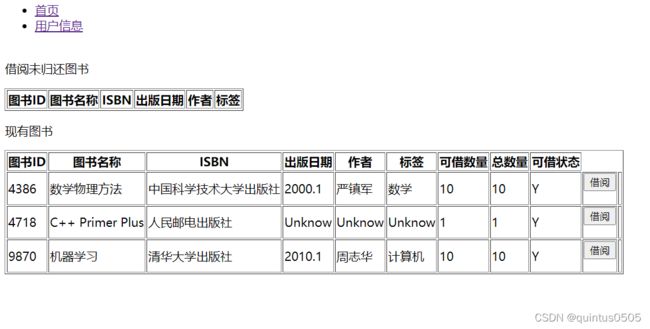
这里添加了一个新的html文件borrow_book.html,其核心是两个表格,展示可以借阅的图书和借阅未归还的图书,当某图书可借数量为0时,将不显示。

html代码构建方式全为上文用过的方法,代码可在github仓库中查阅,链接放在最后。
在models.py中添加Borrow表的属性,对应front_borrow中信息:
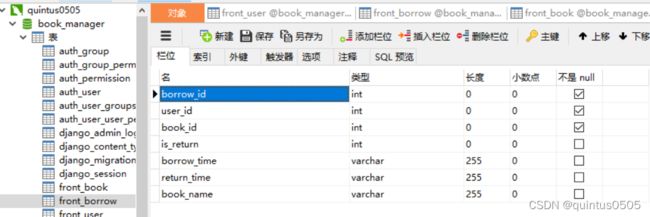
class Borrow(models.Model):
borrow_id = models.AutoField(primary_key=True)
user_id = models.IntegerField()
book_id = models.IntegerField()
book_name = models.CharField(max_length=100)
is_return = models.IntegerField()
borrow_time = models.CharField(max_length=100)
return_time = models.CharField(max_length=100)
在urls.py中添加新url项:

在user_info中添加相应对应功能的处理:
新的borrow_book函数:
def borrow_book(request):
if request.method == 'GET':
print('enter borrow get')
cur_url = str(request.path)
splited_url = cur_url.split('/')
user_id = int(splited_url[-1])
user_borrow = models.Borrow.objects.filter(user_id=user_id) # 将该用户所有借阅信息取出
# 联立两个表查询
Borrowed_Books = []
for item in user_borrow: # 展示该用户所有借阅信息中的书籍
Borrowed_Books.extend(list(models.Book.objects.filter(book_id=item.book_id)))
Books = models.Book.objects.filter(current_number__gt=0) # 查找现存数量大于0的图书
# 这个地方不能用get(),由于返回多个
return render(request, 'borrow_book.html', locals())
else:
cur_url = str(request.path)
splited_url = cur_url.split('/')
user_id = int(splited_url[-1]) # user_id是url的最后一项
book_id = int(request.POST.get("id")) # book_id为点击进去的某一项图书对应的id
borrow_id = random.randint(20000, 30000)
borrow_time = str(time.asctime(time.localtime(time.time())))
return_time = 'Unknow'
user = models.User.objects.get(user_id=user_id)
if (user.user_type == 1 and user.book_number >= 8) or (user.user_type == 0 and user.book_number >= 4):
# 超出借书限制
return render(request, 'error_borrow_book.html', locals())
# 添加借阅记录
borrow = models.Borrow(
borrow_id=borrow_id,
user_id=user_id,
book_id=book_id,
is_return=0,
borrow_time=borrow_time,
return_time='Unknow',
)
borrow.save()
# 更新图书current_number
book = models.Book.objects.get(book_id=book_id)
book.current_number -= 1
# 更新书籍可以借阅与否状态
if book.current_number <= 0:
book.can_borrow = 'N'
book.save()
# 更新用户book_number
user = models.User.objects.get(user_id=user_id)
user.book_number += 1
user.save()
Books = models.Book.objects.filter(current_number__gt=0) # 查找现存数量大于0的图书
user_borrow = models.Borrow.objects.filter(user_id=user_id)
Borrowed_Books = []
for item in user_borrow:
Borrowed_Books.extend(list(models.Book.objects.filter(book_id=item.book_id)))
# print(len(user_borrow), type(user_borrow))
# print(len(Borrowed_Books), type(Borrowed_Books))
return render(request, 'borrow_book.html', locals())
这里虽然看上去代码量很大,但是实际用到的技巧都是上文提到过的,唯一需要注意的是此处第一次使用了联立front_book和front_borrow两个表查找数据:
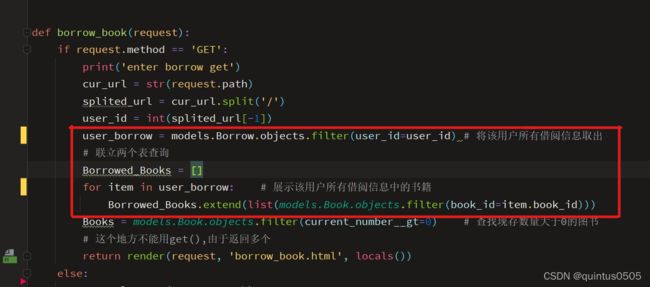
在borrow_book.html通过表格呈现出选择结果, 用到的是return中间的locals()中储存的Borrowed_Books的数据:

还书
这一步首先添加了借阅记录,同时对代码部分做了一些精简,同时为借阅未归还的图书添加了归还按钮,操作方法上文已经介绍
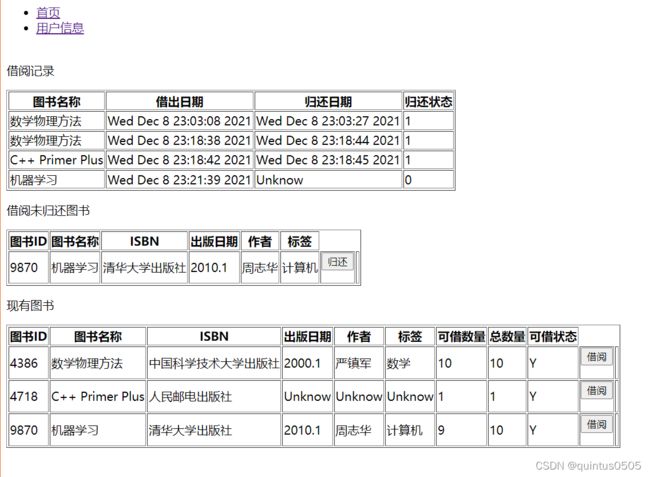
目前完整的borrow_book()函数如下:
def borrow_book(request):
cur_url = str(request.path)
splited_url = cur_url.split('/')
user_id = int(splited_url[-1]) # user_id是url的最后一项
# 将该用户所有借阅信息取出
user_borrow = models.Borrow.objects.filter(user_id=user_id, is_return=0)
user_return = models.Borrow.objects.filter(user_id=user_id, is_return=1)
if request.POST.get('return_book'): # 归还图书
book_id = int(request.POST.get("id")) # book_id为点击进去的某一项图书对应的id
# 更新归还信息, 下面选择的含义是选择含有目标user_id,book_id并且没有归还的第一个条目,防止用一个人借了好几本相同的书
borrow = models.Borrow.objects.filter(user_id=user_id, book_id=book_id, is_return=0).first()
borrow.is_return = 1
borrow.return_time = str(time.asctime(time.localtime(time.time())))
borrow.save()
# 更新图书current_number
book = models.Book.objects.get(book_id=book_id)
book.current_number += 1
# 更新书籍可以借阅与否状态
if book.current_number > 0:
book.can_borrow = 'Y'
book.save()
# 更新用户book_number
user = models.User.objects.get(user_id=user_id)
user.book_number -= 1
user.save()
elif request.POST.get('confirm_borrow_book'):
book_id = int(request.POST.get("id")) # book_id为点击进去的某一项图书对应的id
book_name = models.Book.objects.get(book_id=book_id).book_name
borrow_id = random.randint(20000, 30000)
borrow_time = str(time.asctime(time.localtime(time.time())))
return_time = 'Unknow'
user = models.User.objects.get(user_id=user_id)
if (user.user_type == 1 and user.book_number >= 8) or (user.user_type == 0 and user.book_number >= 4):
# 超出借书限制
return render(request, 'error_borrow_book.html', locals())
# 添加借阅记录
borrow = models.Borrow(
borrow_id=borrow_id,
user_id=user_id,
book_id=book_id,
book_name=book_name,
is_return=0,
borrow_time=borrow_time,
return_time='Unknow',
)
borrow.save()
# 更新图书current_number
book = models.Book.objects.get(book_id=book_id)
book.current_number -= 1
# 更新书籍可以借阅与否状态
if book.current_number <= 0:
book.can_borrow = 'N'
book.save()
# 更新用户book_number
user = models.User.objects.get(user_id=user_id)
user.book_number += 1
user.save()
Books = models.Book.objects.filter(current_number__gt=0) # 查找现存数量大于0的图书
Borrowed_Books = []
for item in user_borrow:
Borrowed_Books.extend(list(models.Book.objects.filter(book_id=item.book_id)))
return render(request, 'borrow_book.html', locals())
搜索查询
首先做到这一步的时候发现了一个小问题,我把ISBN和出版社当成了一项放在了数据库的表中,现在发现了问题,重新添加了ISBN表项:

添加搜索查询步骤仍然只需要在原有的book_info.html和user_info.html两个文件中增加修改:
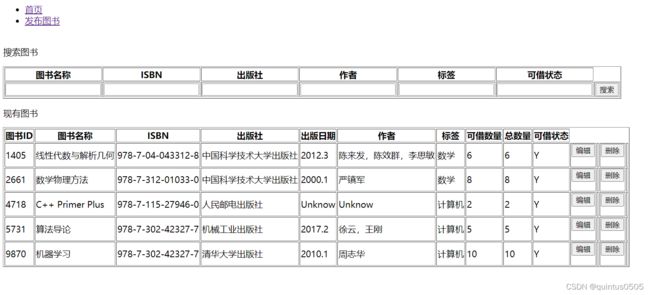

注意这里的将所有表项都包含进去了,这样才能在post的时候将所有信息全部收集
在view.py中的user_info函数中,通过层层filter,最后剩下所需数据:
这里使用查询图书做效果展示,构建方法和查询用户相同:
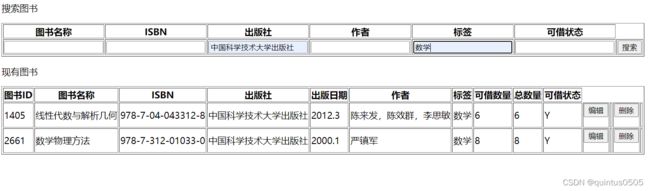
批量出入库
这两个功能实现方法完全相同,只介绍如何批量入库
在book_info.html中添加批量入库、批量出库功能:

在urls.py中添加新的path:
设计batch_book_in.html和batch_book_out.html,展示batch_book_in.html:
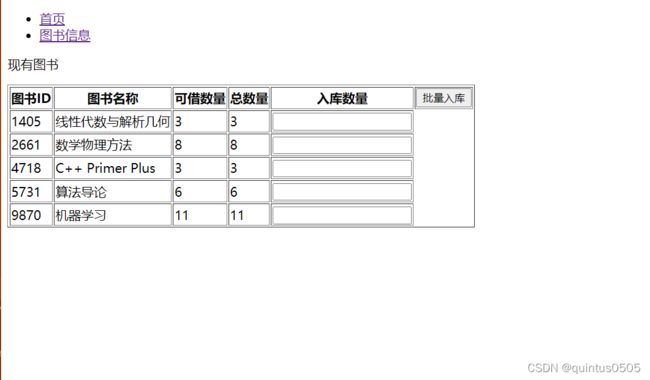
看起来和实际上都很简单,唯一注意的一点是如何全部接收需要入库的书籍的入库数量。这里先放上batch_book_in.html代码
DOCTYPE html>
<html lang="en">
<body>
<nav>
<ul class="nav">
<li><a href="/">首页a>li>
<li><a href="{% url 'book_info' %}">图书信息a>li>
ul>
nav>
body>
<p>现有图书p>
<form action="" method="post">
<table border="1">
<tr>
<th>图书IDth>
<th>图书名称th>
<th>可借数量th>
<th>总数量th>
<th>入库数量th>
<th>
<input type="submit" name="batch_book_in" value="批量入库">
th>
tr>
{% for book in Books %}
<tr>
<td>{{book.book_id}}td>
<td>{{book.book_name}}td>
<td>{{book.current_number}}td>
<td>{{book.total_number}}td>
<td>
<input type="hidden" name="id" value={{book.book_id}}>
<input type="text" name="in_number">
td>
tr>
{% endfor %}
table>
form>
html>
值得注意的是,为了提交时一次性将全部数据传走,我用将整个表格包含。
下面是在view.py中新创建的batch_book_in函数:
def batch_book_in(request):
Books = models.Book.objects.all()
if request.method == 'GET':
return render(request, 'batch_book_in.html', locals())
else:
# 通过request.POST.getlist把全部
book_id = request.POST.getlist("id")
for i in range(len(book_id)):
book = models.Book.objects.get(book_id=book_id[i])
in_number = request.POST.getlist("in_number")[i]
if in_number: # 如果含有修改的值
in_number = int(in_number)
book.total_number += in_number
book.current_number += in_number
if book.current_number <= 0: # 更新可借阅状态
book.can_borrow = 'N'
else:
book.can_borrow = 'Y'
book.save()
Books = models.Book.objects.all()
return render(request, 'batch_book_in.html', locals())
这里用到了request.POST.getlist()这个方法,可以将post的所有数据接收存放在列表中,下面举一个例子:

这里只将部分图书入库,同时添加打印以查看:

打印信息如下:

剩下都是重复性工作,不再赘述。
批量导入读者和图书信息
这是功能实现部分最后一个内容, 同样只展示如何批量导入图书信息,首先先在在book_info.html中添加相应功能:
创建新的batch_import_book.html和batch_import_user.html,并在urls.py中添加相应path。
最终效果如下:
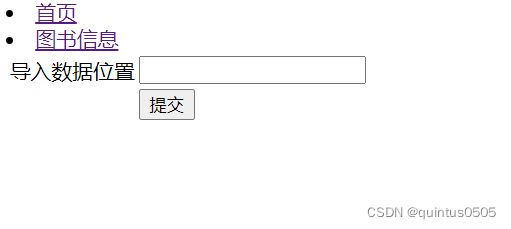
batch_import_book.html代码如下:
{% block content %}
<li><a href="/">首页a>li>
<li><a href="{% url 'book_info' %}">图书信息a>li>
<form action="" method="post">
<table>
<tbody>
<tr>
<td>导入数据位置td>
<td><input type="text" name="location">td>
tr>
<tr>
<td>td>
<td><input type="submit" value="提交">td>
tr>
tbody>
table>
form>
{% endblock %}
在view.py下创建新函数batch_import_book
def batch_import_book(request):
Books = models.Book.objects.all()
if request.method == 'GET':
return render(request, 'batch_import_book.html')
else:
location = request.POST.get("location")
if location:
try:
df_books = pd.read_csv(location)
except:
return render(request, 'error_batch_import.html', locals())
else:
df_books = pd.read_csv(osp.join(UTILS_PATH, 'books.csv'))
for i in range(len(df_books.index)):
book_id = random.randint(0, 10000)
while models.Book.objects.all().filter(book_id=book_id):
book_id = random.randint(0, 10000)
book_name = df_books.book_name[i]
# 使用pd.notnull判断是否为nan
if pd.notnull(df_books.ISBN[i]):
print(df_books.ISBN[i], type(df_books.ISBN[i]), np.float64('nan'), type(np.float64('nan')))
ISBN = df_books.ISBN[i]
else:
ISBN = 'Unknow'
if pd.notnull(df_books.publisher[i]):
publisher = df_books.publisher[i]
else:
publisher = 'Unknow'
if pd.notnull(df_books.publish_date[i]):
publish_date = df_books.publish_date[i]
else:
publish_date = 'Unknow'
if pd.notnull(df_books.author[i]):
author = df_books.author[i]
else:
author = 'Unknow'
if pd.notnull(df_books.label[i]):
label = df_books.label[i]
else:
label = 'Unknow'
total_number = int(df_books.total_number[i])
if total_number>0:
can_borrow = 'Y'
else:
total_number = 'N'
cursor = get_corsor()
cursor.execute(
"insert into front_book(book_id, book_name, ISBN, publish_date, author, label, current_number, total_number, can_borrow, publisher) values('%d','%s','%s','%s','%s','%s','%d','%d', '%s', '%s')" % (
book_id, book_name, ISBN, publish_date, author, label, total_number, total_number, can_borrow, publisher))
# 跳转到首页
Books = models.Book.objects.all()
return redirect('/book_info/', locals())
在这个功能中我调用了pandas的DataFrame来更直观的展示读取的数据,相关生成的数据的代码以及数据我放在了项目文件Book_managing_system/utils下面,读取默认路径也是该位置。
进过测试,本节所有功能都能正常运行
补上最后的数据库三个表格:
front_book
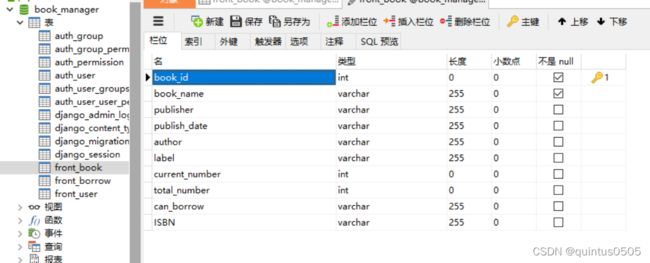
front_user

front_borrow

由于github中无法上传数据库的内容,在进行项目的时候多次修改了数据库表格,可能需要注意一下。
美化过程就不介绍了