tensorflow:使用mask-RCNN训练自己的数据集
一:所需环境
numpy
scipy
Pillow
cython
matplotlib
scikit-image
tensorflow>=1.3.0
keras>=2.0.8
opencv-python
h5py
imgaug
IPython[all]
快速安装tensorflow-gpu链接:
https://blog.csdn.net/m0_49100031/article/details/119534426?spm=1001.2014.3001.5502
二:准备数据
labelme数据标注工具安装,这个网上一堆教程
使用labelme标注完以后是json格式的文件,需要把json格式的文件批量转换。
目录下只留一个名字为json的文件夹即可,会生成四个文件夹:cv2_mask, labelme_sjon ,pic, json
批量转换代码:
import json
import os
import os.path as osp
import warnings
from shutil import copyfile
import PIL.Image
import yaml
from labelme import utils
import time
def main():
json_file = r'D:\2021年技术积累\mask-rcnn分割\train_data\json'
list = os.listdir(json_file)
if not os.path.exists(json_file + '/' + 'pic'):
os.makedirs(json_file + '/' + 'pic')
if not os.path.exists(json_file + '/' + 'cv_mask'):
os.makedirs(json_file + '/' + 'cv_mask')
if not os.path.exists(json_file + '/' + 'labelme_json'):
os.makedirs(json_file + '/' + 'labelme_json')
if not os.path.exists(json_file + '/' + 'json'):
os.makedirs(json_file + '/' + 'json')
for i in range(0, len(list)):
path = os.path.join(json_file, list[i])
if os.path.isfile(path):
copyfile(path, json_file + '/json/' + list[i])
data = json.load(open(path))
img = utils.img_b64_to_arr(data['imageData'])
lbl, lbl_names = utils.labelme_shapes_to_label(img.shape, data['shapes'])
captions = ['%d: %s' % (l, name) for l, name in enumerate(lbl_names)]
lbl_viz = utils.draw_label(lbl, img, captions)
out_dir = osp.basename(list[i]).replace('.', '_')
out_dir = osp.join(osp.dirname(list[i]), out_dir)
filename = out_dir[:-5]
out_dir = json_file + "/" + 'labelme_json' + "/" + out_dir
out_dir1 = json_file + "/" + 'pic'
out_dir2 = json_file + "/" + 'cv_mask'
if not osp.exists(out_dir):
os.mkdir(out_dir)
PIL.Image.fromarray(img).save(osp.join(out_dir, 'img' + '.png'))
PIL.Image.fromarray(img).save(osp.join(out_dir1, str(filename) + '.png'))
utils.lblsave(osp.join(out_dir, 'label.png'), lbl)
utils.lblsave(osp.join(out_dir2, str(filename) + '.png'), lbl)
PIL.Image.fromarray(lbl_viz).save(osp.join(out_dir, 'label_viz.png'))
with open(osp.join(out_dir, 'label_names' + '.txt'), 'w') as f:
for lbl_name in lbl_names:
f.write(lbl_name + '\n')
warnings.warn('info.yaml is being replaced by label_names.txt')
info = dict(label_names=lbl_names)
with open(osp.join(out_dir, 'info.yaml'), 'w') as f:
yaml.dump(info, f, default_flow_style=False)
fov = open(osp.join(out_dir, 'info' + '.yaml'), 'w')
for key in info:
fov.writelines(key)
fov.write(':\n')
for k, v in lbl_names.items():
fov.write('-')
fov.write(' ')
fov.write(k)
fov.write('\n')
fov.close()
print('Saved to: %s' % out_dir)
if __name__ == '__main__':
start = time.time()
main()
spend = time.time() - start
print(spend)
三:下载mask-RCNN coco模型,以供后续使用
这里提供下载代码,无需手动下载,只需运行即可。
import os
import urllib.request
import shutil
# URL from which to download the latest COCO trained weights
COCO_MODEL_URL = "https://github.com/matterport/Mask_RCNN/releases/download/v2.0/mask_rcnn_coco.h5"
def download_trained_weights(coco_model_path, verbose=1):
"""Download COCO trained weights from Releases.
coco_model_path: local path of COCO trained weights
"""
if verbose > 0:
print("Downloading pretrained model to " + coco_model_path + " ...")
with urllib.request.urlopen(COCO_MODEL_URL) as resp, open(coco_model_path, 'wb') as out:
shutil.copyfileobj(resp, out)
if verbose > 0:
print("... done downloading pretrained model!")
ROOT_DIR = os.path.abspath('./')
COCO_MODEL_PATH = os.path.join(ROOT_DIR, 'mask_rcnn_coco.h5')
if not os.path.exists(COCO_MODEL_PATH):
download_trained_weights(COCO_MODEL_PATH)
四:下载mask-RCNN源码
地址:https://github.com/matterport/Mask_RCNN
用不到的代码可以删掉,保留结构如下即可:
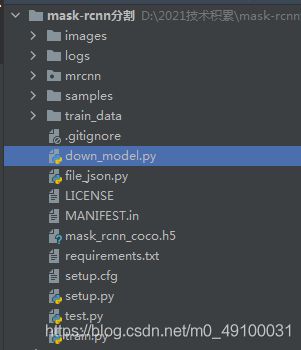
(train,test为自己新建,logs为后面生成,在这一步只保留除这三个文件以外的即可。)
五:训练模型:
# -*- coding: utf-8 -*-
import os
import numpy as np
import cv2
import matplotlib.pyplot as plt
import tensorflow as tf
from mrcnn.config import Config
from mrcnn import model as modellib,utils
import yaml
from PIL import Image
config = tf.ConfigProto()
config.gpu_options.allow_growth = True
sess = tf.Session(config = config)
os.environ["CUDA_VISIBLE_DEVICES"] = "0"
ROOT_DIR = os.getcwd()
MODEL_DIR = os.path.join(ROOT_DIR, "logs")
iter_num=0
COCO_MODEL_PATH = os.path.join(ROOT_DIR, "mask_rcnn_coco.h5") # 之前下载过的mask-rcnn-coco model
if not os.path.exists(COCO_MODEL_PATH):
utils.download_trained_weights(COCO_MODEL_PATH)
class ShapesConfig(Config):
NAME = "shapes"
GPU_COUNT = 1 # 表示用几块GPU
IMAGES_PER_GPU = 4 # 一次处理的数量,batch_szie=GPU_COUNT * IMAGES_PER_GPU(在源码当中表示了)
NUM_CLASSES = 1 + 6 # 类别,背景+你数据的分类
IMAGE_MIN_DIM = 320 # 将图片大小作为多大的去处理
IMAGE_MAX_DIM = 384
RPN_ANCHOR_SCALES = (8 * 6, 16 * 6, 32 * 6, 64 * 6, 128 * 6)
TRAIN_ROIS_PER_IMAGE = 32
STEPS_PER_EPOCH = 100
VALIDATION_STEPS = 5
config = ShapesConfig()
config.display()
class DrugDataset(utils.Dataset):
# 得到该图中有多少个实例(物体)
def get_obj_index(self, image):
n = np.max(image)
return n
# 解析labelme中得到的yaml文件,从而得到mask每一层对应的实例标签
def from_yaml_get_class(self, image_id):
info = self.image_info[image_id]
with open(info['yaml_path']) as f:
temp = yaml.load(f.read(),Loader=yaml.FullLoader)
labels = temp['label_names']
del labels[0]
return labels
def draw_mask(self, num_obj, mask, image,image_id):
info = self.image_info[image_id]
for index in range(num_obj):
for i in range(info['width']):
for j in range(info['height']):
at_pixel = image.getpixel((i, j))
if at_pixel == index + 1:
mask[j, i, index] = 1
return mask
def load_shapes(self, count, img_floder, mask_floder, imglist, dataset_root_path):
self.add_class("shapes", 1, "fabric")
self.add_class("shapes", 2, "glass")
self.add_class("shapes", 3, "leather")
self.add_class("shapes", 4, "metal")
self.add_class("shapes", 5, "plastic")
self.add_class("shapes", 6, "wood")
for i in range(count):
# 解析之间生成的四个文件夹,得到路径
filestr = imglist[i].split(".")[0]
mask_path = mask_floder + "/" + filestr + ".png"
yaml_path = dataset_root_path + "labelme_json/" + filestr + "_json/info.yaml"
print(dataset_root_path + "labelme_json/" + filestr + "_json/img.png")
cv_img = cv2.imread(dataset_root_path + "labelme_json/" + filestr + "_json/img.png")
self.add_image("shapes", image_id=i, path=img_floder + "/" + imglist[i],
width=cv_img.shape[1], height=cv_img.shape[0], mask_path=mask_path, yaml_path=yaml_path)
def load_mask(self, image_id):
global iter_num
print("image_id",image_id)
info = self.image_info[image_id]
count = 1
img = Image.open(info['mask_path'])
num_obj = self.get_obj_index(img)
mask = np.zeros([info['height'], info['width'], num_obj], dtype=np.uint8)
mask = self.draw_mask(num_obj, mask, img,image_id)
occlusion = np.logical_not(mask[:, :]).astype(np.uint8)
for i in range(count - 2, -1, -1):
mask[:, :, i] = mask[:, :, i] * occlusion
occlusion = np.logical_and(occlusion, np.logical_not(mask[:, :, i]))
labels = self.from_yaml_get_class(image_id)
labels_form = []
# 添加了多少个类别,就在这里写多少个elif
for i in range(len(labels)):
if labels[i].find("fabric") != -1:
labels_form.append("fabric")
elif labels[i].find("glass")!=-1:
labels_form.append("glass")
elif labels[i].find("leather")!=-1:
labels_form.append("leather")
elif labels[i].find("metal")!=-1:
labels_form.append("metal")
elif labels[i].find("plastic")!=-1:
labels_form.append("plastic")
elif labels[i].find("wood")!=-1:
labels_form.append("wood")
class_ids = np.array([self.class_names.index(s) for s in labels_form])
return mask, class_ids.astype(np.int32)
def get_ax(rows=1, cols=1, size=8):
_, ax = plt.subplots(rows, cols, figsize=(size * cols, size * rows))
return ax
#基础设置
dataset_root_path="train_data/"
img_floder = dataset_root_path + "pic"
mask_floder = dataset_root_path + "cv2_mask"
#yaml_floder = dataset_root_path
imglist = os.listdir(img_floder)
count = len(imglist)
print(count)
#train与val数据集准备
dataset_train = DrugDataset()
dataset_train.load_shapes(count, img_floder, mask_floder, imglist,dataset_root_path)
dataset_train.prepare()
dataset_val = DrugDataset()
dataset_val.load_shapes(40, img_floder, mask_floder, imglist,dataset_root_path)
dataset_val.prepare()
model = modellib.MaskRCNN(mode="training", config=config,
model_dir=MODEL_DIR)
init_with = "coco"
if init_with == "imagenet":
model.load_weights(model.get_imagenet_weights(), by_name=True)
elif init_with == "coco":
model.load_weights(COCO_MODEL_PATH, by_name=True,
exclude=["mrcnn_class_logits", "mrcnn_bbox_fc",
"mrcnn_bbox", "mrcnn_mask"])
elif init_with == "last":
model.load_weights(model.find_last()[1], by_name=True)
# 源码当中有两种模式训练,这里写的是all,即对模型所有层进行微调,如果你的数据类别与coco数据集中差异较大,可以用这种模式,如果差异较小,把all改成heads即可。
model.train(dataset_train, dataset_val,
learning_rate=config.LEARNING_RATE,
epochs=200,
layers='all')
等到训练结束后,会在当前路径下生成一个logs文件,里面是你训练好的模型,设置是一个epoch保存一次,可以自己修改,取最后一次训练的模型即可。
六:测试模型
测试模型代码如下:
需要修改的地方已在代码里标出
import os
import sys
import skimage.io
from mrcnn.config import Config
ROOT_DIR = os.getcwd()
sys.path.append(ROOT_DIR)
from mrcnn import utils
import mrcnn.model as modellib
from mrcnn import visualize
sys.path.append(os.path.join(ROOT_DIR, "samples/coco/"))
MODEL_DIR = os.path.join(ROOT_DIR, "logs")
# 你训练好的模型
COCO_MODEL_PATH = os.path.join(MODEL_DIR ,"mymodel.h5")
if not os.path.exists(COCO_MODEL_PATH):
utils.download_trained_weights(COCO_MODEL_PATH)
# 测试图片的地址
IMAGE_DIR = os.path.join(ROOT_DIR, "images")
class ShapesConfig(Config):
NAME = "shapes"
GPU_COUNT = 1
IMAGES_PER_GPU = 2
NUM_CLASSES = 1 + 6 # 和训练处修改一样
class InferenceConfig(ShapesConfig):
GPU_COUNT = 1
IMAGES_PER_GPU = 1
config = InferenceConfig()
model = modellib.MaskRCNN(mode="inference", model_dir=MODEL_DIR, config=config)
model.load_weights(COCO_MODEL_PATH, by_name=True)
# 你训练的数据集类别,一定要加背景,要不然会出现识别不准
class_names = ['bj','fabric', 'glass','leather','metal','plastic','wood']
file_names = next(os.walk(IMAGE_DIR))[2]
for x in range(len(file_names)):
image = skimage.io.imread(os.path.join(IMAGE_DIR, file_names[x]))
results = model.detect([image], verbose=1)
print(results)
r = results[0]
visualize.display_instances(image, r['rois'], r['masks'], r['class_ids'],class_names, r['scores'])
七:结果显示
测试结果如下:


以上就是所有过程,感兴趣的小伙伴可以自行尝试。