Faster R-CNN代码详解 标注数据形状
Faster R-CNN代码实战–潘登同学的深度学习笔记
文章目录
-
- Faster R-CNN代码实战--潘登同学的深度学习笔记
- 数据集介绍
- 数据处理
-
- 先看combined_roidb
- RoIDataLayer
- get_output_dir
- Trian过程
-
- create_architecture
-
- build_network
-
- Build head
- Build RPN
-
- 回到_anchor_component
- 回到Build RPN
-
- 接一层3\*3卷积,再接一层1\*1卷积
- Build proposals
-
- _proposal_layer
- _anchor_target_layer
- _proposal_target_layer
- build_predictions
- **回到build_network**
- **回到create_architecture**
-
- _add_losses
- **回到Train**
数据集介绍
采用的数据集是VOCDevkit2007/VOC2007

-
Annotation: XML文件,是给图像打框的标注数据
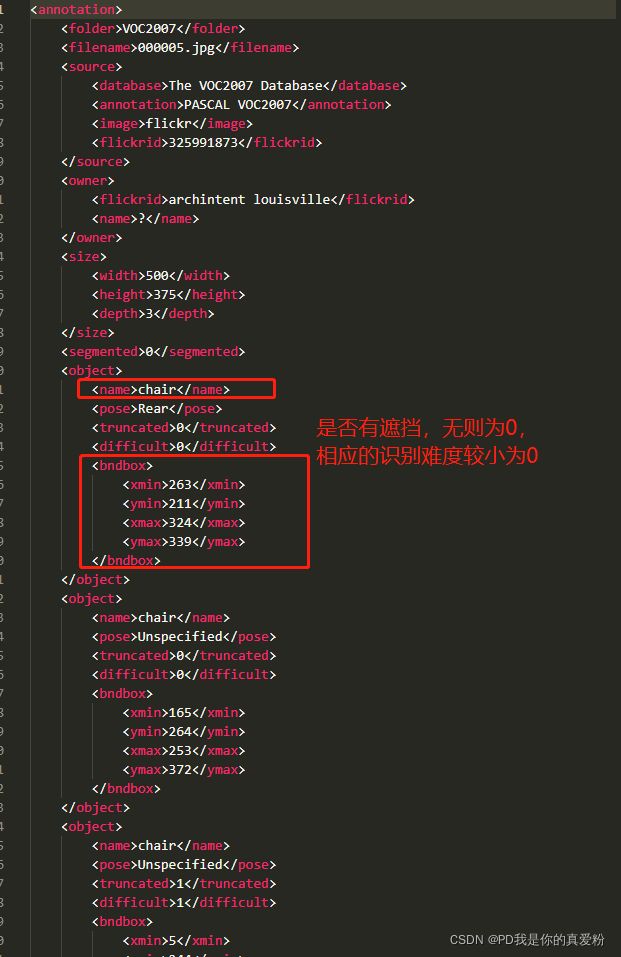
-
ImageSets: 图片的编号及属性
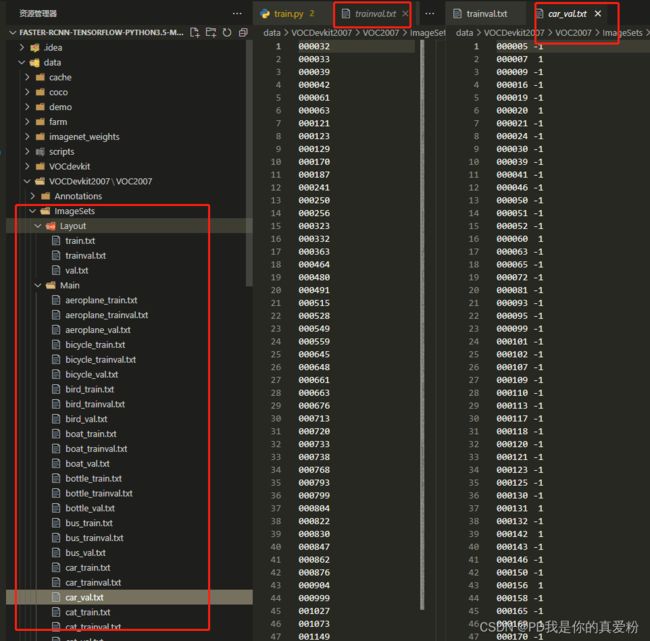
-
JPEGImages: 存储图片

-
下面的用不上,那些是做语义分割的…以后再说
数据处理

先看combined_roidb
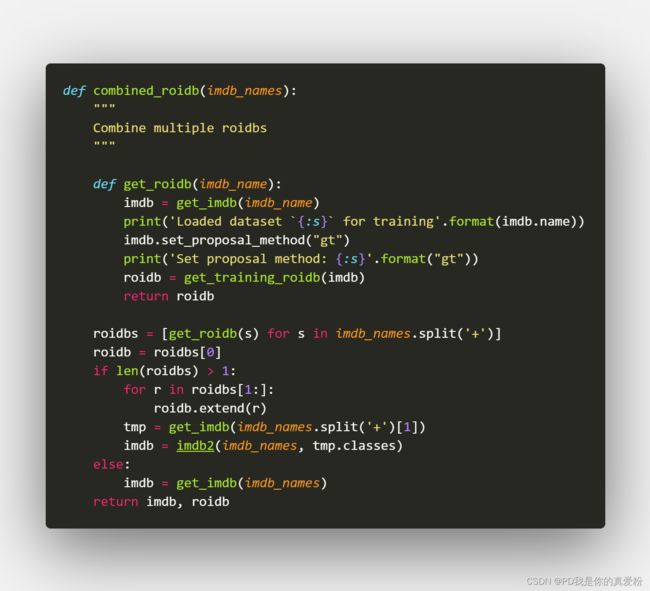
其中get_roidb会调用数据集里面写好的API的调用方法,这里就直接当成人家弄好的拿来用即可,看一看API给出的数据长啥样
-
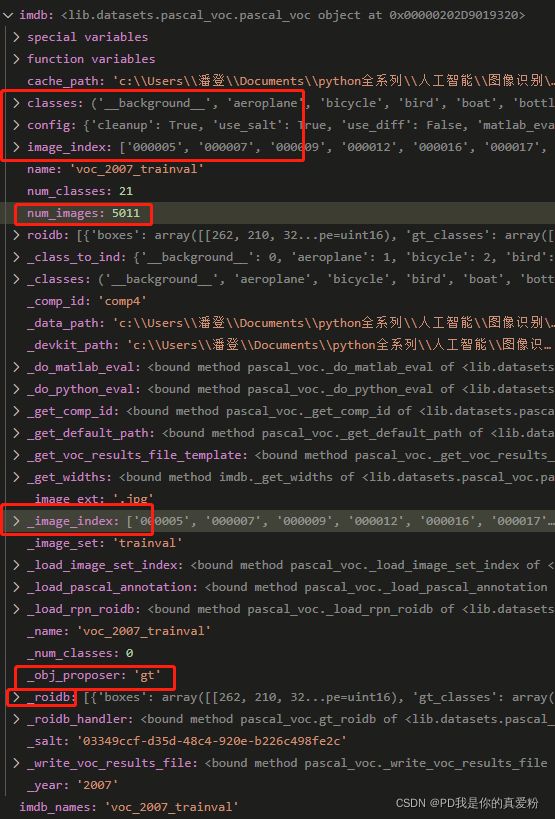
roidb

-
imdb
RoIDataLayer
在这里RoIDataLayer主要是打乱顺序,这里没用打乱顺序; 而后面这个RoIDataLayer的数据是专门喂给Fast R-CNN,去训练Fast R-CNN,所以这里初始化的时候,只要了roidb的数据
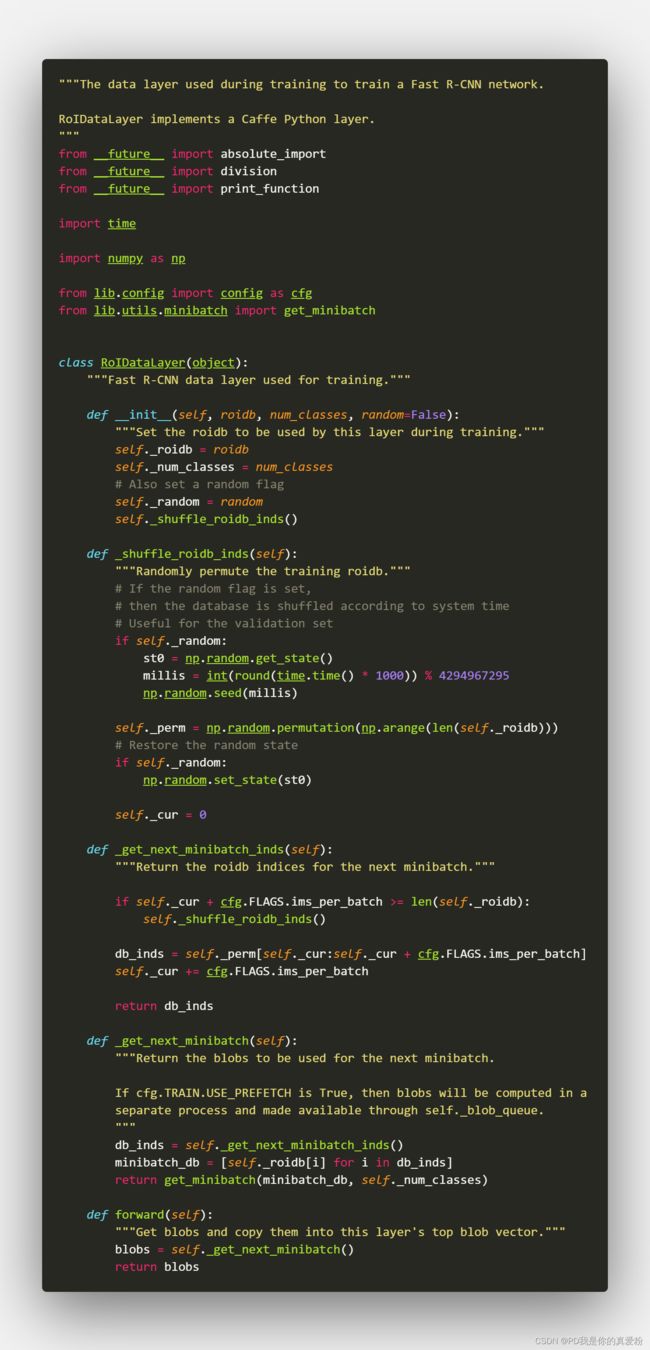
get_output_dir
get_output_dir主要是把预训练好的VGG保存起来,后面拿来用
Trian过程
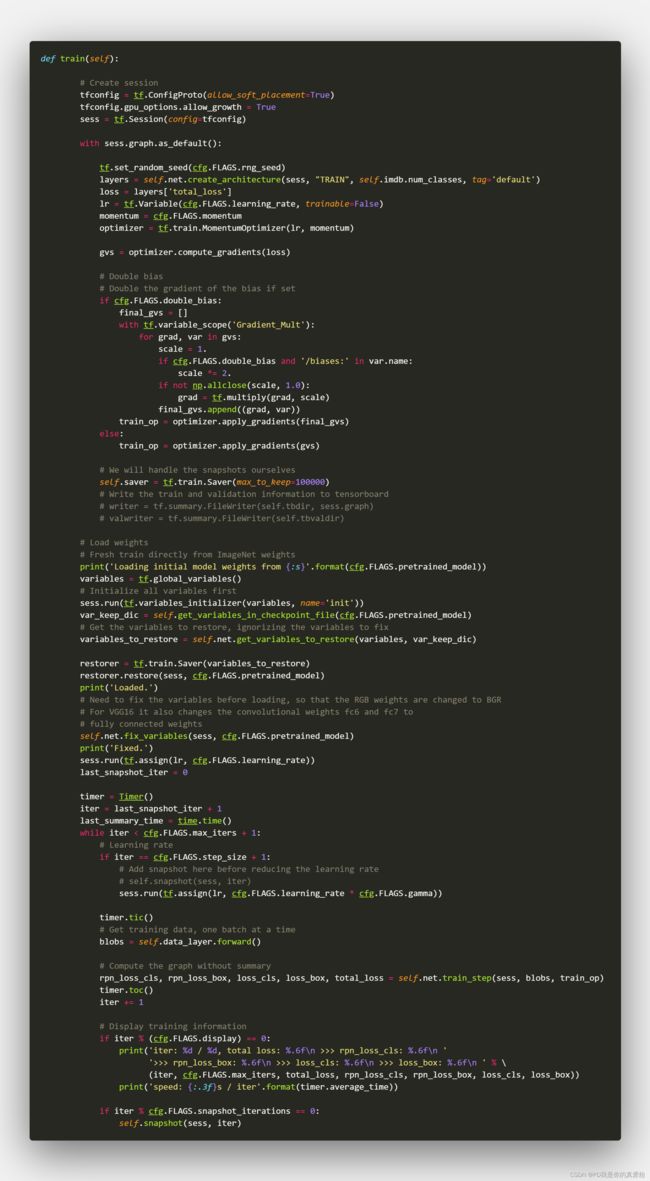
前面的没啥看的,关键是这句layers = self.net.create_architecture(sess, "TRAIN", self.imdb.num_classes, tag='default')
create_architecture

前面的也不关键,关键是这句self.build_network(sess, training)
build_network
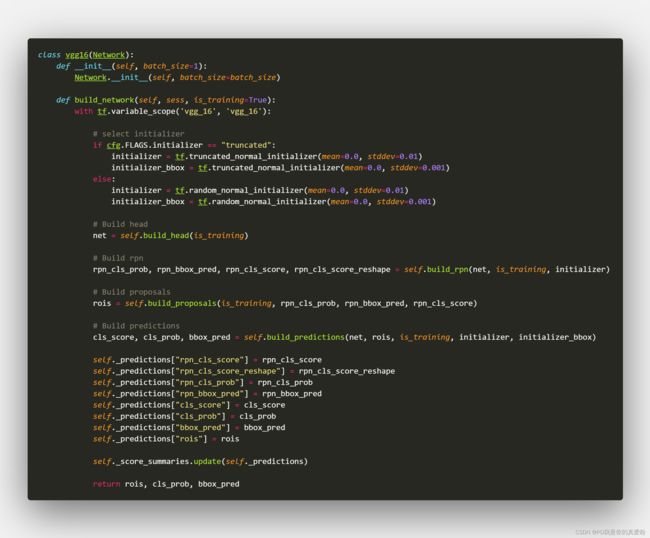
Build head
这里就是构建了一个VGG16网络而已

Build RPN
这里就是构建RPN网络了
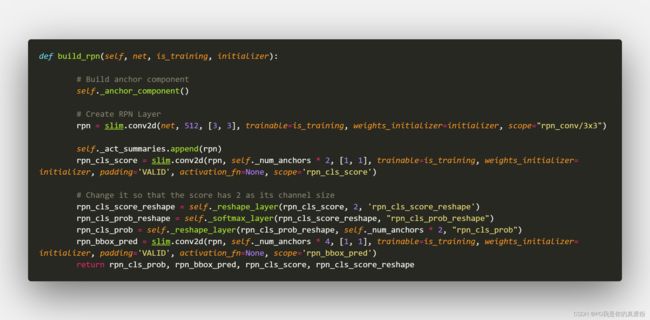
核心讲一下这里的数据形状,因为tf的tensor是静态结构,没有数据传进来就看不见大小,这里模拟一下…
假设一开始拿来的图片大小是shape=(333,500,3) 索引号为1807
1. forward
因为在Train的时候,会调用RoIDataLayer的forward方法,先看forward方法
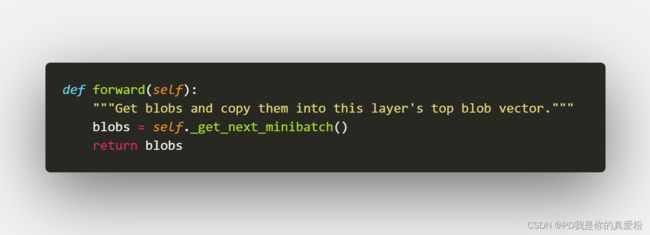
1.1 进_get_next_minibatch中

1.1.1 _get_next_minibatch_inds方法,获得小批量数据的索引

1.1.2 get_minibatch方法
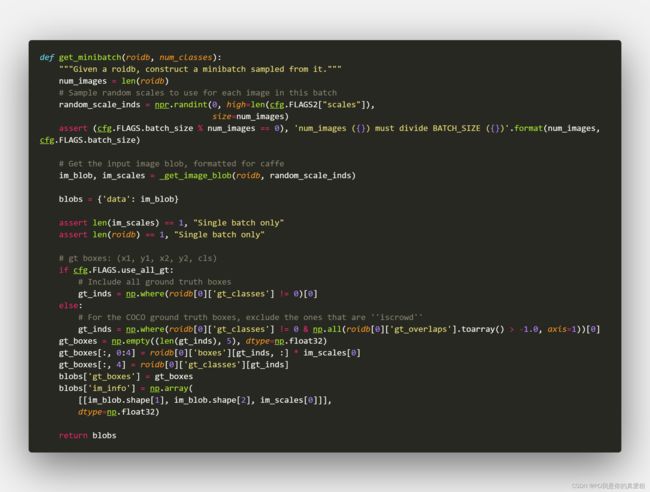
1.1.2.1 核心是_get_image_blob

其中一个if判断主要是判断数据增强,因为这里用的是水平增强,所以要将图片水平翻转
其中关键是prep_im_for_blob方法生成图片与缩放图片的比例
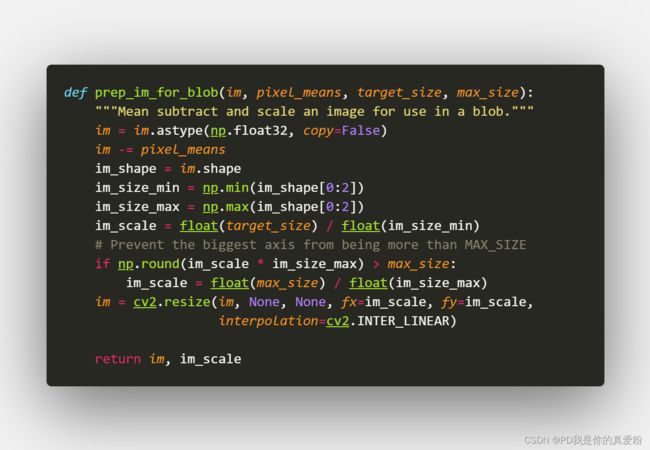
1.1.2.1.1 prep_im_for_blob
将图片缩放成要求的 (600,1000) 这里主要是将短边缩放为600,然后长边跟随变化,超过了就剪切掉,没超过就不管,与原论文有些许不同
回到1.1.2 get_minibatch方法
- im_scale: 对图片的缩放比例 1.8
- blobs[‘data’]: 是一个批次的图片(就是一张)缩放后的做了均值归一后的 shape=(600,901)
- blobs[‘gt_boxes’]: 是一个二维数组,shape=(K,5) 前四列放的是缩放后的坐标值,第五列放的是框的类别号
- blobs[‘im_info’]: 是一个一维数组前两个是图片的宽和长后一个是缩放比例, [600,901,1.8]
回到create_architecture,前面三行就是接受刚才forward导出的数据
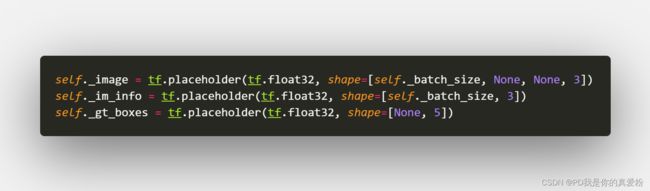
回到_anchor_component
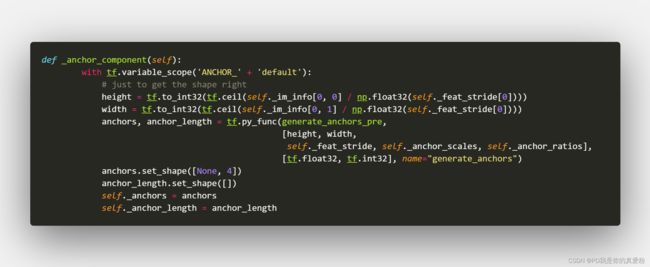
- Height=600/16=38
- Weight=901/16=57
38*57对应的就是Bottom的面积(即VGG出来的Feature Map的大小)
tf.py_func函数
这个函数的作用就是能将tensor的运算转为numpy的运算,方便地改变tensor,核心操作函数是里面的generate_anchors_pre
2.1 generate_anchors_pre
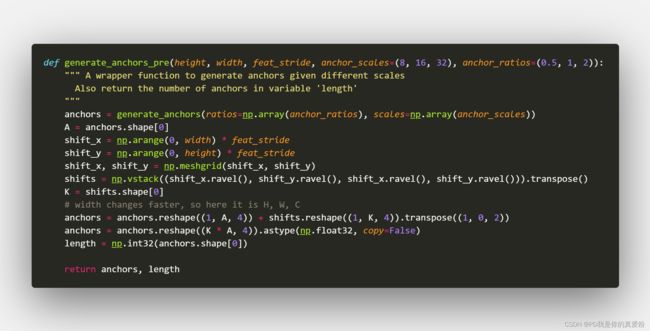
2.1.1 generate_anchors
generate_anchors函数是由原作者写的

主要就是生成那Anchor对应的九个Anchor boxes,要强调的是: Anchor boxes是跟着Anchor走的,而Anchor是Featrue Map上的一个像素,只要Anchor不变Anchor boxes,至于后面的Predict boxes要向ground truth靠近,那是将Anchor boxes进行了平移(相当于复制了一份,再拿去train),Anchor boxes是不变的
这个函数中的生成的anchors实际上是每个Anchor boxes的左上角与右下角的相对坐标
array([[ -83., -39., 100., 56.],
[-175., -87., 192., 104.],
[-359., -183., 376., 200.],
[ -55., -55., 72., 72.],
[-119., -119., 136., 136.],
[-247., -247., 264., 264.],
[ -35., -79., 52., 96.],
[ -79., -167., 96., 184.],
[-167., -343., 184., 360.]])
2.1.2 shifts
shifts是由Anchor中心坐标构成的shape=(K,4)(K=38*57=2166)的数组,其实只要shape=(K,2)就能描述Anchor中心坐标的位置,而之所以要四个,是为了让Anchor boxes的左上角与右下角相对坐标能直接与shifts运算变成绝对坐标
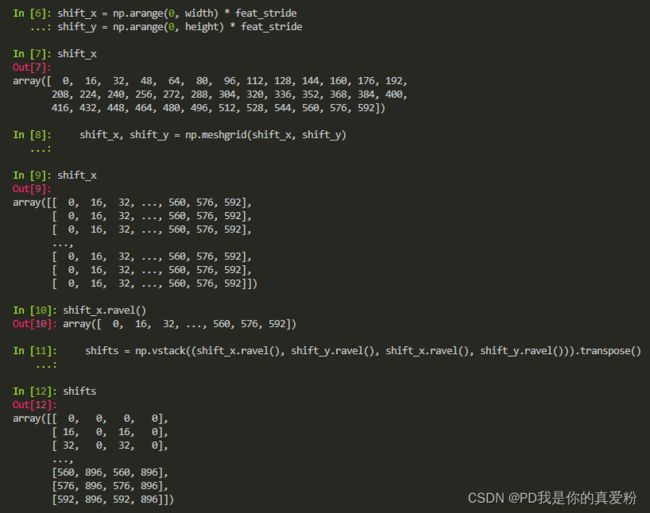
最后2166个Anchor与9个Anchor boxes进行相关运算,再reshape成(2166*9=19494),总共就有19494个框(与论文中的2万个差不多)
回到Build RPN
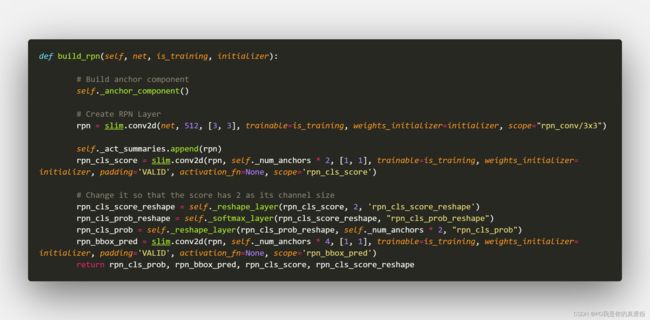
接一层3*3卷积,再接一层1*1卷积
- net --> 3*3卷积
- (1,38,57,512)
- 1*1卷积
- rpn_cls_score(1,38,57,18)
- _reshape_layer
- (1,18,38,57)
- (1,2,513,38)
- rpn_cls_score_reshape(1,513,38,2)
- _softmax_layer
- (19494,2)
- (1,513,38,2)
- _reshape_layer
- (1,2,513,38)
- (1,18,57,38)
- rpn_cls_prob(1,57,38,18)
- 1*1卷积
- (1,38,57,51)
- rpn_bbox_pred(1,38,57,36)
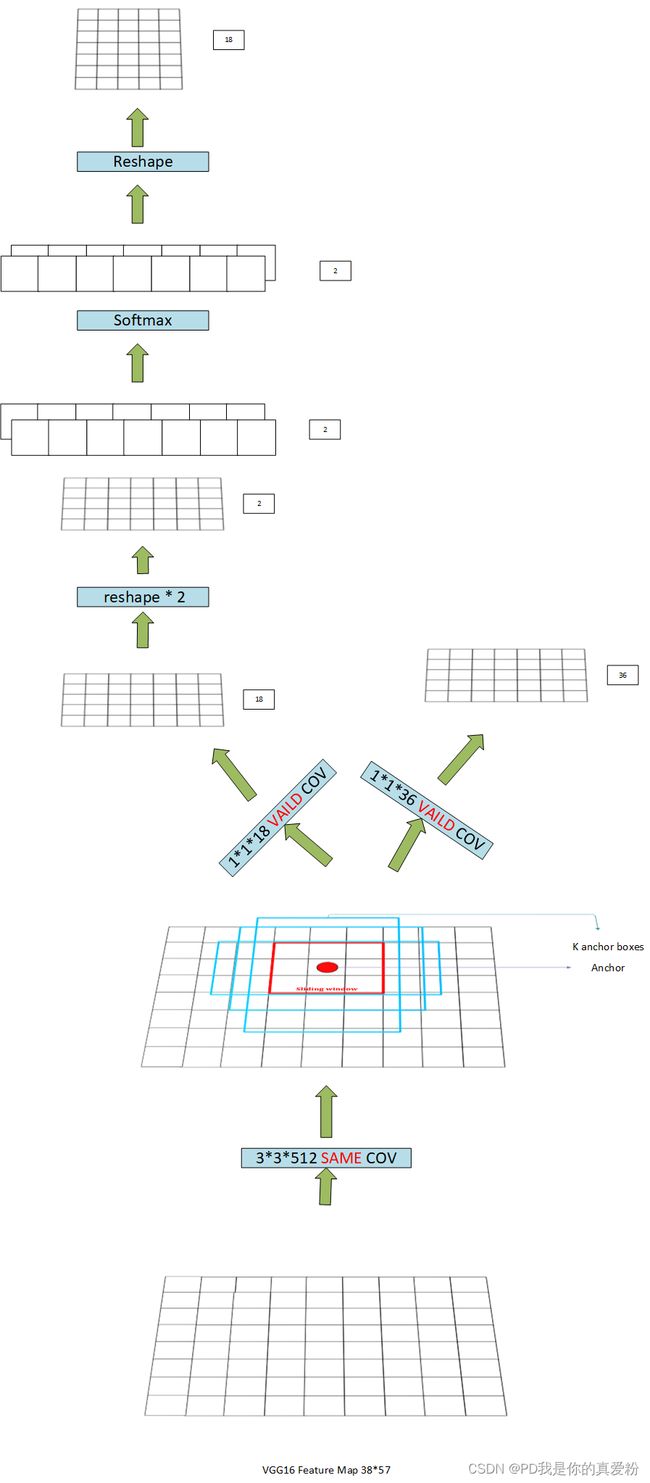
Build proposals

核心是三句
- _proposal_layer 相当于预测,给后面的ROI pooling去使用的候选框
- _anchor_target_layer 给RPN网络准备正负例的
- _proposal_target_layer
_proposal_layer
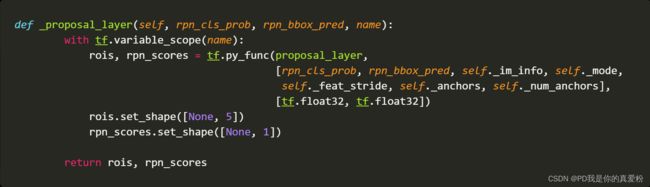
3.1 proposal_layer
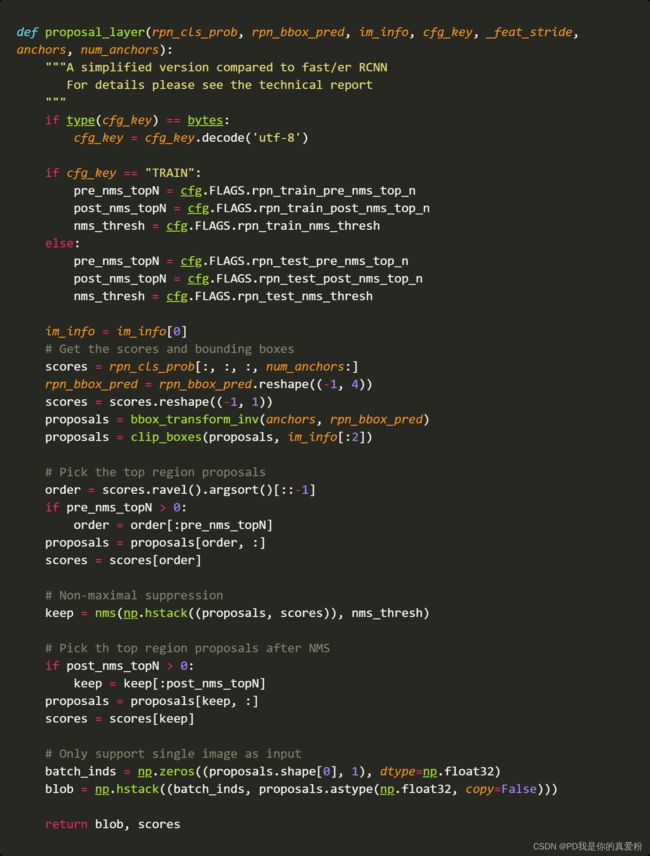
- pre_nms_topN: 12000
- post_nms_topN: 2000
- nms_thresh: 0.7
- im_info: 600
- scores: (19494,1), 就是前面的rpn_cls_prob(1,57,38,18)取了第四维的后九个,因为正例prob往往越高,所以排在后面,这里就是把正例取出来,后面reshape成(19494,1)
- rpn_bbox_pred: (19494,4), 将rpn_bbox_pred(1,38,57,36)reshape成(19494,4)
3.1.1 bbox_transform_inv
- 传进去的anchor在前面shifts中说到是shape(19494,4)代表原图上19494个框对应的4个坐标,是论文中的带下角标 a a a的 x , y , w , h x,y,w,h x,y,w,h

- 传进去的rpn_bbox_pred: (19494,4)代表预测的框的位置,(理应是)是论文中的 x , y , w , h x,y,w,h x,y,w,h,但是这里略有不同,这里的rpn_bbox_pred是预测值与原Anchor boxes的偏移量,我们知道,预测既可以直接预测值,也可以预测残差,这里就相当于预测残差
- 函数输出的就是论文中的 x , y , w , h x,y,w,h x,y,w,h
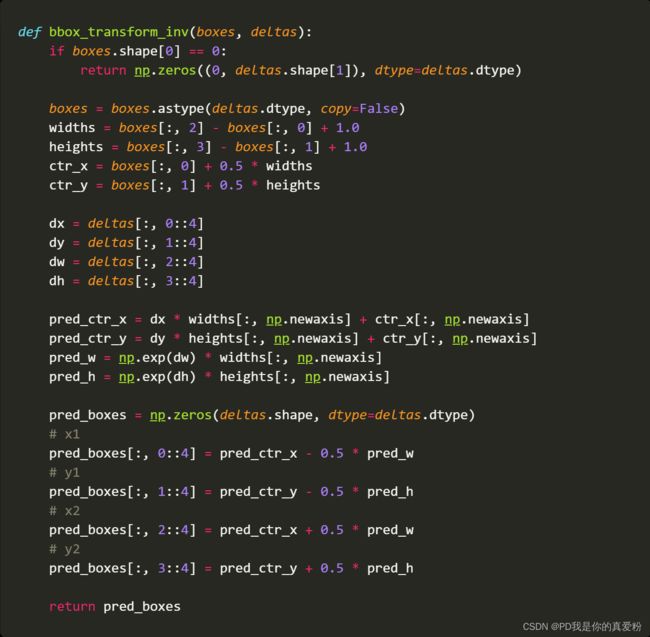
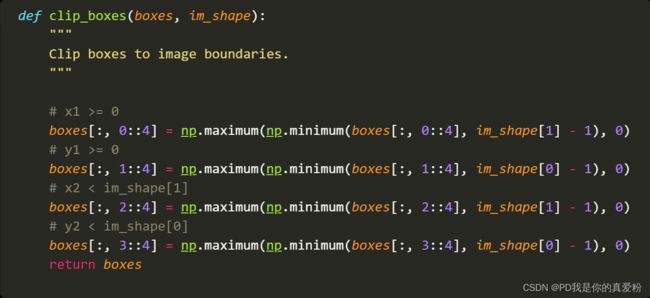
3.1.2 clip_boxes
clip_boxes就是对预测的框进行剪切了,大于原图的就不要了
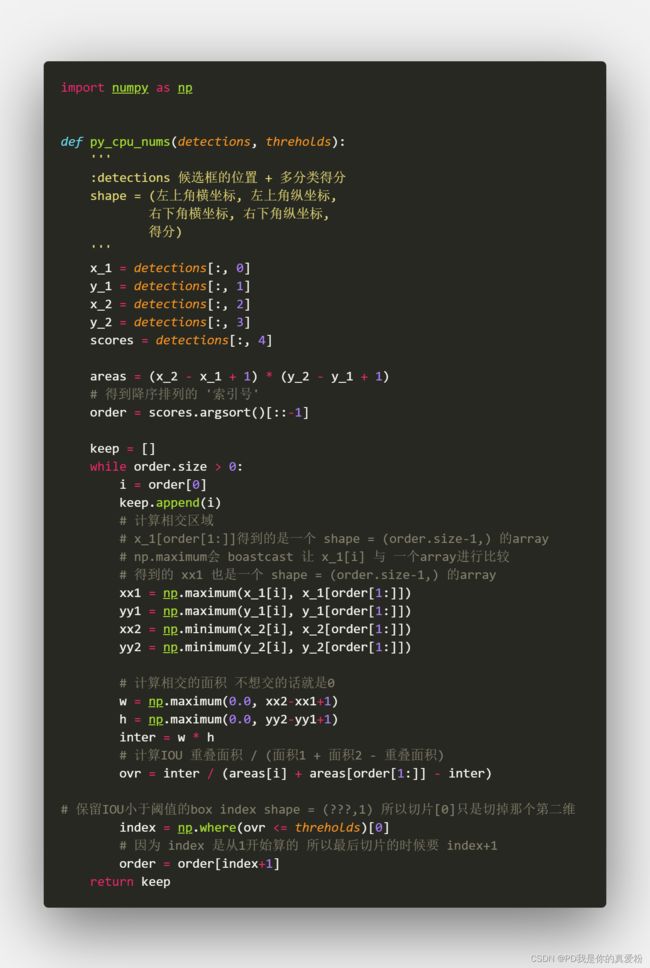
3.1.3 NMS
这个在之前看论文的时候说过,就不再赘述
3.1.4 其他
剩下就是将NMS之后的框,控制在post_nms_topN范围内,要是多了就去掉分数低的,少了就不管
- rois = 返回值blob: 第一列为batch的索引号,后四列为筛选出来框的位置坐标
- roi_scores = 返回值scores: 框的scores
_anchor_target_layer
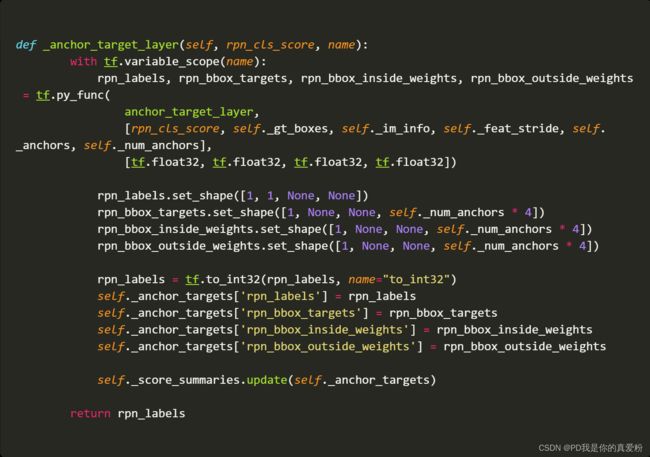
4.1 anchor_target_layer
这个函数也是原作者写的…
- rpn_cls_score: (1,38,57,18) 是未经过softmax变换的Z值
- all_anchors: shifts中产生的所有框
- A: 9
- total_anchors: 19494
- K: 2166
- im_info: 600
- height: 38
- width: 57
先是将所有超出图的框给去掉(可以通过**_allowed_border**来控制超出多少是可以忍受的)
注意: 为什么不在一开始生成anchor boxes的时候就把他给去掉,而是在处理样本的时候才去掉?
是因为在真正用的时候,可能在图片的边边角角有物体,这时候只需要对框进行裁剪就可以,而gt训练集的ground truth永远是在图里面的,不可能超出图,所以要把训练集的超出图的框给去掉
接着就是标注label: 1 is positive, 0 is negative, -1 is dont care
对上面过滤剩下的Anchor与ground truth计算重叠度,因为bbox_overlaps函数被反复调用,调用量很大,作者将其编译为了C,又转成了pyd,看不见,但是不难理解这个函数,其实就是计算IOU的
- overlaps: 二维数组(N,W) N表示ROI的数量,W表示GT的数量,里面装的就是IOU
- argmax_overlaps: 一维数组(N,) 表示候选框与哪个GT的IOU最大,里面装的是GT的索引号
- max_overlaps: 一维数组(N,) 与argmax_overlaps有关,argmax_overlaps装的是索引号,这里装的是IOU值,两个一一对应
- gt_argmax_overlaps:一维数组(W,) 表示与GT重叠度最大的那个候选框的索引号
- gt_max_overlaps: 一维数组(W,) 与gt_argmax_overlaps有关,这里装的是IOU值
- gt_argmax_overlaps: 重新搜索一遍,因为可能存在这样一种情况,就是
overlaps.argmax(axis=0)得到的只有一个值,但是可能最大的两个值相等,那argmax只会返回第一次出现的索引号,重新搜索一遍找出所有gt_max_overlaps相等的那些候选框,所以gt_argmax_overlaps最后的形状可能会大于W
接下来就是真正标准数据集了
-
相关划分参数

-
rpn_batchsize: 256,其中128为正例,128为负例
从上往下进行:
- max_overlaps小于0.3的候选框被划分为负例
- gt_argmax_overlaps的所有都被划分为正例
- max_overlaps大于0.7的候选框被划分成正例
- 随机选择128的正例,128个负例,多余的将label赋值为-1
4.1.1 _compute_targets

_compute_targets方法的主要作用是: 计算每个Anchor boxes与他们最接近的那个GT的位置到底相差多远
4.1.1.1 bbox_transform

这里就可以对应回论文的 t x ∗ , t y ∗ , t w ∗ , t h ∗ t_x^*,t_y^*,t_w^*,t_h^* tx∗,ty∗,tw∗,th∗
最后是把 t x ∗ , t y ∗ , t w ∗ , t h ∗ t_x^*,t_y^*,t_w^*,t_h^* tx∗,ty∗,tw∗,th∗按行摆放,得到的target shape(少于19494,4)(因为输入的ex_rois是过滤过的)
所以回到4.1 anchor_target_layer
- bbox_targets: (少于19494,4) 过滤后的anchor boxes的 t x ∗ , t y ∗ , t w ∗ , t h ∗ t_x^*,t_y^*,t_w^*,t_h^* tx∗,ty∗,tw∗,th∗按行摆放
- bbox_inside_weights: (少于19494,4) 过滤后的anchor boxes的权重,如果是labels为1,则那4的那个维度的数值为(1,1,1,1),否则为(0,0,0,0)
- bbox_outside_weights: (少于19494,4) 对应回原文中求loss的 1 N r e g \frac{1}{N_{reg}} Nreg1,所有都一样无论正负例,都是正例数量的倒数,即 1 n l a b e l = 1 \frac{1}{n_{label=1}} nlabel=11

4.1.2 _unmap
_unmap函数的作用就是将刚刚操作的少于19494的框,还原成19494,因为真正训练的时候,打的框还是19494,只不过我们不想用那些出界的框,现在还原回去,label照旧设置成-1,对结果也不影响
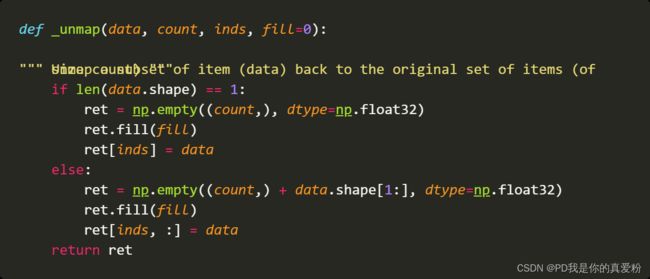
- labels: (19494,)
- bbox_targets: (19494,4)
- bbox_inside_weights: (19494,4)
- bbox_outside_weights: (19494,4)
回到4.1 anchor_target_layer
- rpn_labels: (1,1,9*38,57) 将labels(-1,) 先reshape成(1,38,57,9)再reshape成(1,9,38,57)再reshape成(1,1,9*38,57)
- rpn_bbox_targets: (1,38,57,9*4) 将bbox_targets(19494,4) reshape成(1,38,57,9*4)
- rpn_bbox_inside_weights: (1,38,57,9*4)
- bbox_outside_weights: (1,38,57,9*4)
_proposal_target_layer
_proposal_target_layer是给最终的Fast RCNN准备正负例样本的, 在执行_proposal_target_layer前先等待_anchor_target_layer执行结束可能是因为_anchor_target_layer里面用着bbox_overlaps,而这个函数也要用bbox_overlaps,所以避免GPU爆炸吧…
输入(NMS之后的框,控制在post_nms_topN范围)
- rois: (2000,5)第一列为batch的索引号,后四列为筛选出来框的位置坐标
- roi_scores: (2000,1)框的得分scores
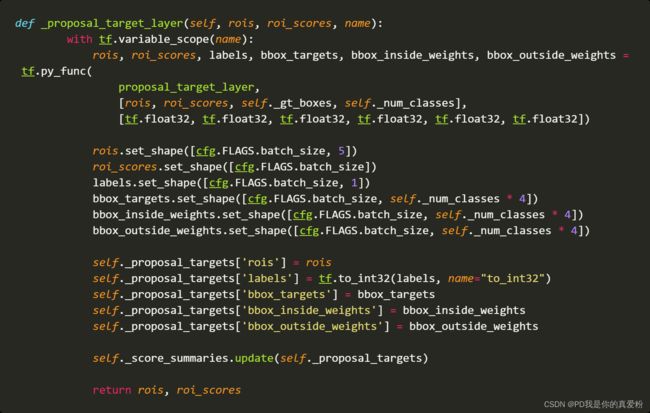
5.1 proposal_target_layer
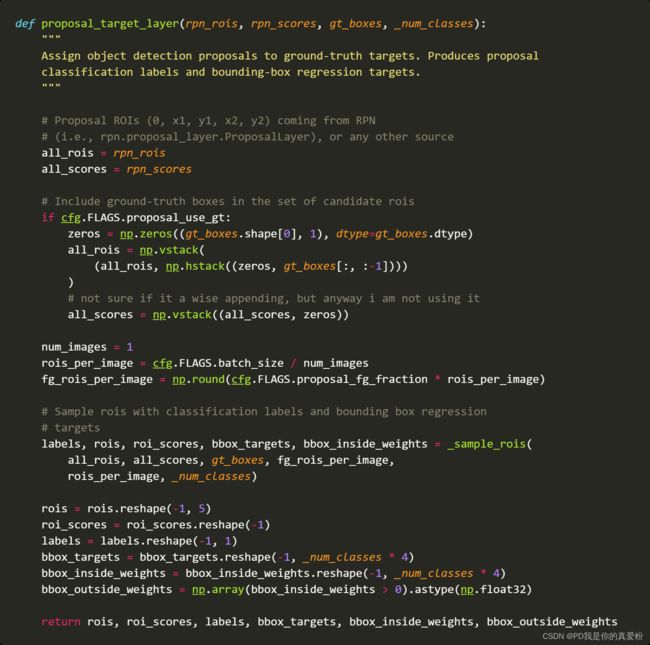
- all_rois: rois(2000,5)第一列为batch的索引号,后四列为筛选出来框的位置坐标
- all_scores: roi_scores: (2000,1)框的得分scores
if cfg.FLAGS.proposal_use_gt是想确定一下是否直接把GT用于训练,这里是False,那就不管- num_images: 1
- rois_per_image: 256
- fg_rois_per_image: 64
5.1.1 _sample_rois
_sample_rois函数是主要是生成roi及相关scores及框的最终调整位置
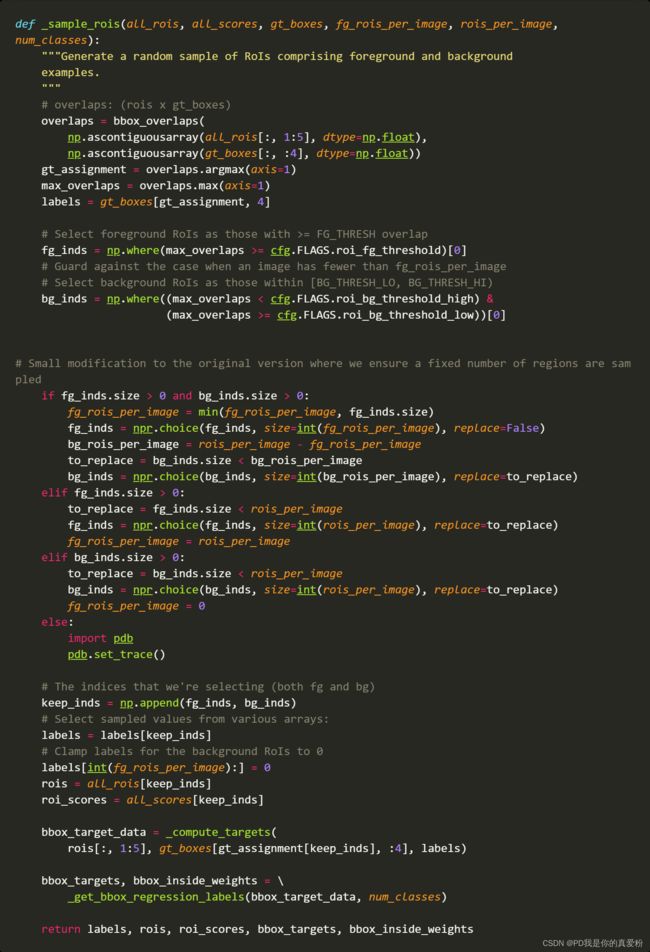
- overlaps: (2000,W) W是GT的数量
- gt_assignment: (2000,) 表示ROI与哪个GT的IOU最大,里面装的是GT的索引号
- max_overlaps: (2000,) 表示ROI与最大IOU的GT的IOU,里面装的是IOU的值
gt_boxes=blobs['gt_boxes']: (W,5) 前四列表示GT的坐标,后一列表示类别号- labels: (2000,) 表示ROI最可能属于哪一类
- fg_inds: 一维数组 表示max_overlaps中的IOU大于0.5的那些ROI的索引号
- bg_inds: 一维数组 表示max_overlaps中的IOU小于0.5但大于0.1的那些ROI的索引号
- 接着的逻辑判断,就是确保正负例到达要求… 总共有256, 正例为64个,剩下的为负例
- keep_inds: 将正负例的索引号组成列表(正例在前,负例在后)
labels = labels[keep_inds]对labels进行过滤 过滤后的形状为(256,1)labels[int(fg_rois_per_image):] = 0: 把负例标记为0- rois: 正负例的框的坐标
- roi_scores: 正负例的框的scores
- bbox_target_data: (256,5) 第一列的是label 后四列就是targets(往下看)
- bbox_targets: (256,84)相当于将每一个类别的框的位置做了一个One-hot编码,属于第k类的框只会在[4k,4k+4]的位置有坐标值
- bbox_inside_weights: 就是一个在[4k,4k+4]的位置(1.0, 1.0, 1.0, 1.0)的数组
5.1.1.1 _compute_targets
gt_boxes[gt_assignment[keep_inds], :4]的作用是形成与正负例形状一样的GT的坐标,因为在计算loss的时候一个正例需要与其对应的GT框进行匹配来计算偏移量…
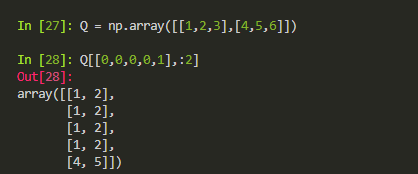
这个函数虽然跟前面的_compute_targets名字一样,但是具体方面还是有所不同,估计是作者忘记改名了吧
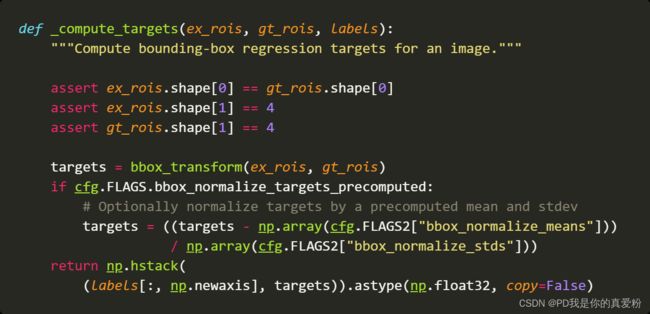
- ex_rois: (256,4) 256的正负例的坐标
- gt_rois: (256,4) 256的正负例最接近的的GT的坐标
- labels: (256,1)
- targets: bbox_transform前面说过这个方法,出来的是 target shape(256,4)
- 最后返回一个: (256,5) 第一列的是label 后四列就是targets
5.1.1.2 _get_bbox_regression_labels
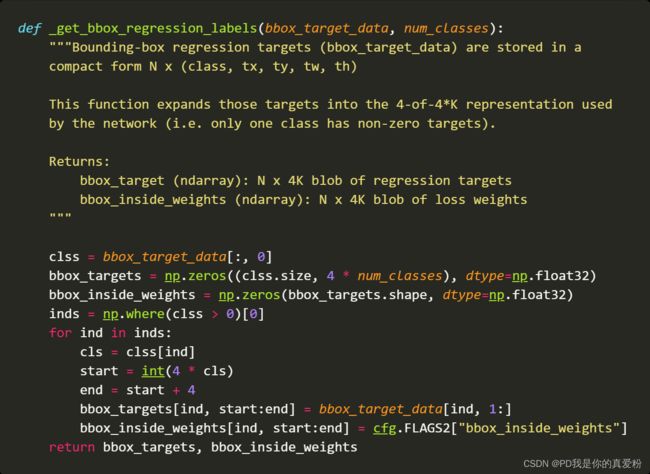
- bbox_target_data: (256,5) 第一列的是label 后四列就是targets(往下看)
- num_classes: 21
- bbox_targets: (256,84) 相当于将每一个类别的框的位置做了一个One-hot编码,属于第k类的框只会在[4k,4k+4]的位置有坐标值
- bbox_inside_weights: 就是一个在[4k,4k+4]的位置(1.0, 1.0, 1.0, 1.0)的数组
回到_proposal_target_layer
- rois: (256,5)
- roi_scores: (256,)
- labels: (256,)
- bbox_targets: (256,21*4)
- bbox_inside_weights: (256,21*4)
- bbox_outside_weights: (256,21*4)
build_predictions
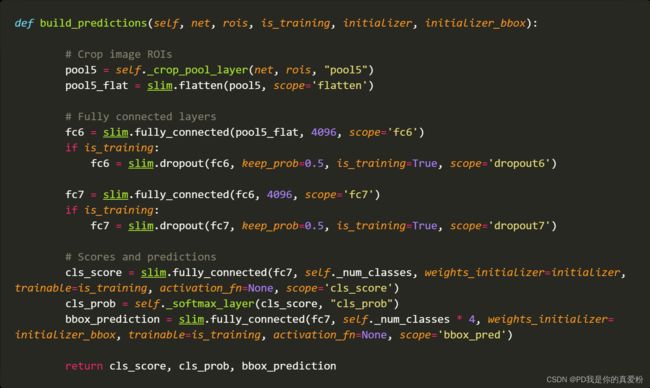
- 一层ROI池化层
- 一层展平
- 两层全连接
- 一层Output层
- cls_score: softmax前的Z值
- cls_prob: softmax之后的概率值
- 另一层Output层
- bbox_prediction: 没有激活函数的线性变换
回到build_network
后面就是将预测与得分等信息挂到net上
回到create_architecture
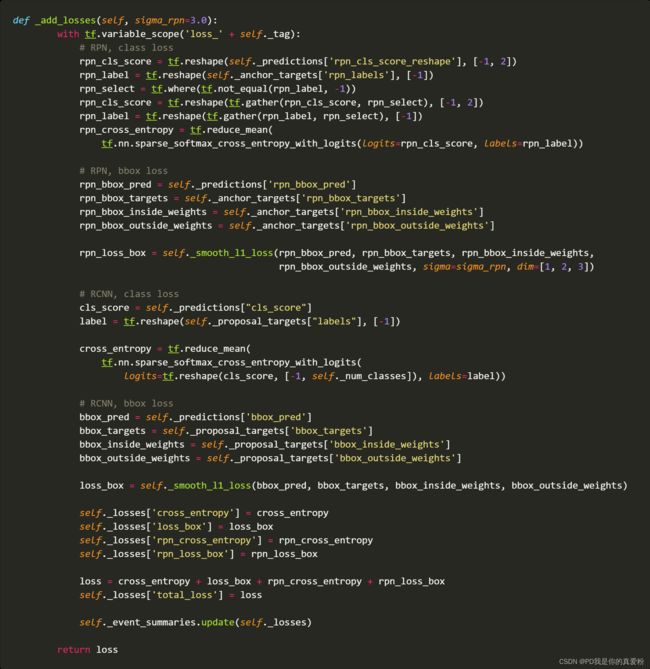
_add_losses
_add_losses方法就是将四个loss合并成一个loss(在这里是整体训练的,不像论文中是分开训练的,但是论文也说了可以整体训练,甚至论文中的loss与这里的loss就是一样的)
回到Train
最难搞的create_architecture已经搞定了,后面就是常规流程了,只不过这里写的比较友好,各种打印保存等等,就不再细聊了…
记得要将文件放在没有中文路径的文件夹下…
