摘要
我们提出了一种训练神经网络的方法,使用强化学习(RL)中的演员评论方法生成序列。当前的对数似然训练方法受到训练和测试模式之间差异的限制,因为模型必须以先前的猜测而不是地面真实标记为基础生成标记。我们通过引入一个经过训练来评估输出令牌价值的评论家网络来解决这个问题,给定了演员网络的策略。这导致训练过程更接近测试阶段,并允许我们直接优化任务特定分数,例如BLEU。
至关重要的是,由于我们在监督学习环境中利用这些技术而不是传统的RL设置,因此我们根据地面实况输出来评判批评网络。我们表明,我们的方法可以提高合成任务和德语 - 英语机器翻译的性能。我们的分析为这些方法应用于自然语言生成任务铺平了道路,例如机器翻译,字幕生成和对话建模。
介绍
在机器学习的许多重要应用中,任务是开发一个系统,该系统在给定输入的情况下产生一系列离散标记。最近的工作表明,当训练预测给定输入和先前令牌的下一个输出令牌时,递归神经网络(RNN)可以在许多此类任务中提供出色的性能。这种方法已成功应用于机器翻译(Sutskever等,2014,Bahdanau等,2015),标题生成(Kiros等,2014,Donahue等,2015,Vinyals等,2015,Xu等,2015, Karpathy和Fei-Fei,2015)和语音识别(Chorowski等,2015,Chan等,2015)。训练RNN生成序列的标准方法是在给定先前“正确”历史记录的情况下最大化“正确”标记的对数似然性,这种方法通常称为教师强制。在评估时,输出序列通常通过根据所学习的分布近似搜索最可能的候选者来产生。在此搜索过程中,模型以其自身的猜测为条件,这可能是不正确的,从而导致错误的复合(Bengio等,2015)。对于较长的序列,这可能变得特别成问题。由于训练和测试条件之间存在这种差异,已经表明最大似然训练可能不是最理想的(Bengio等,2015,Ranzato等,2015)。在这些工作中,作者认为应该训练网络,以便在已经由模型产生的输出而不是数据的地面实况参考输出的情况下继续正确生成。这引起了确定下一个网络输出的目标的挑战性问题。Bengio等人(2015)在步骤k使用来自地面实况答案的令牌k作为网络的目标,而Ranzato等人(2015)依靠REINFORCE算法(Williams,1992)来决定是否使用令牌从抽样预测导致高任务特定分数,如BLEU(Papineni等,2002)或ROUGE(Lin和Hovy,2003)。
在这项工作中,我们提出并研究了训练序列预测网络的替代程序,旨在直接改进他们的测试时的指标(通常不是对数似然)。特别是,我们训练一个名为批评者的额外网络来输出每个令牌的价值,我们将其定义为网络在输出令牌时将接收的预期任务特定得分,并根据其概率分布继续对输出进行抽样。此外,我们展示了预测值如何用于训练主序列预测网络,我们称之为演员。我们方法的理论基础是,在批评者计算精确值的假设下,我们用来训练行动者的表达是对预期任务特定分数的梯度的无偏估计。我们的方法从强化学习(RL)(Sutton和Barto,1998)领域中汲取灵感并借用术语,尤其是演员 - 评论家方法(Sutton,1984,Sutton等,1999,Barto等,1983)。 。RL研究了基于弱监督的有效行动问题,其形式是对某些代理人的行为给予的奖励。在我们的例子中,奖励类似于与预测相关的任务特定分数。然而,我们考虑的任务是监督学习的任务,我们通过允许评论家使用真实答案作为输入来利用这一关键差异。换句话说,评论家可以访问一系列已知导致高(或甚至最佳)回报的专家行为。为了训练评论家,我们将时间差异方法从RL文献(Sutton,1988)调整到我们的设置。虽然具有非线性函数逼近器的RL方法并不是新的(Tesauro,1994,Miller等,1995),但它们最近大受欢迎,引起了“深RL”领域(Mnih等,2015)。我们表明,最近在深RL中开发的一些技术,例如具有目标网络,也可能有益于序列预测。
该论文的贡献可归纳如下。
1)我们描述了如何将演员批评方法等RL方法应用于结构化输出的监督学习问题,以及
2)我们研究新方法在合成任务和机器实际任务中的性能和行为翻译,展示了由演员 - 评论家培训带来的最大可能性和REINFORCE的改进。
背景
我们考虑在给定输入X的情况下学习产生输出序列 Y =(y1,...,yT),yt∈A的问题,其中A是输出令牌的字母表。我们经常使用符号Yf···l来指代形式的子序列(yf,···,yl)。假设两组输入 - 输出对(X,Y)可用于训练和测试。通过计算测试集上的平均任务特定分数R(Y,Y)来评估训练的预测器h,其中Y = h(X)是预测。为了简化公式,我们总是使用T来表示输出序列的长度,忽略输出序列可能具有不同长度的事实。递归神经网络递归神经网络(RNN)通过从初始s0状态开始并应用T,给出一系列输入向量(e1,...,eT),产生一系列状态向量(s1,...,sT)。乘以过渡函数f。stef(st-1,和)。映射f的流行选择是长短期记忆(Hochreiter和Schmidhuber,1997)和门控循环单位(Cho等,2014),后者我们用于我们的模型。为了使用RNN构建用于序列生成的概率模型,可以添加随机输出层g(通常是离散输出的softmax),其生成输出yt∈A并且可以通过用它们的嵌入e(yt)替换它们来反馈这些输出。
yt ∼ g(st−1) (1)
因此,RNN定义给定先前令牌(y1,...,yt-1)的下一输出令牌yt的概率分布p(yt | y1,...,yt-1)。在将特殊的序列结束标记adding添加到字母A中时,RNN可以在所有可能的序列上定义分布p(Y),如p(Y)= p(y1)p(y2 | y1)···p (yT | y1,··,,yT -1)p(∅|y1,...,yT)。用于序列预测的RNN。为了使用RNN进行序列预测,必须对它们进行扩充以生成以输入X为条件的Y.最简单的方法是从初始状态s0 = s0(X)开始(Sutskever等,2014,Cho等,2014)。或者,可以将X编码为可变长度的载体序列(h1,...,hL),并使用注意机制对该序列上的RNN进行调节。在我们的模型中,矢量序列由双向RNN(Schuster和Paliwal,1997)或卷积编码器(Rush等,2015)产生。我们使用软关注机制(Bahdanau等,2015)来计算一系列向量的加权和。注意力量决定了每个载体的相对重要性。更正式地说,我们考虑以下关于RNN的方程式。
yt ∼ g(st−1, ct−1) (3)
st = f(st−1, ct−1, e(yt)) (4)
αt = β(st,(h1, . . . , hL)) (5)
ct = X L j=1 αt,jhj (6)
其中β是产生注意力αt的注意机制,而ct是时间步长t的上下文向量或“glimpse”。注意权重由MLP计算,该MLP将当前RNN状态和要关注的每个单独矢量作为输入。权重通常(如我们的工作中)被约束为正,并且通过使用softmax函数求和为1。通过对来自训练集的输入 - 输出对(X,Y)的对数似然log p(Y | X)的梯度上升,可以训练条件RNN用于序列预测。为了产生测试输入序列X的预测Y,通常进行最大p(·| X)的近似波束搜索。在该搜索期间,考虑概率p(·|y1,...,yt-1),其中先前的标记y1,...,yt-1包括预测Y的候选开始。
价值函数

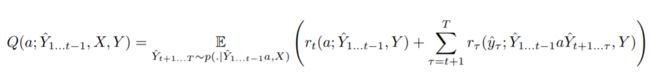
我们如下定义未完成预测Y 1 ... t的值。我们将未完成预测Y 1 ... t-1的候选下一个标记a的值定义为生成标记a之后的预期未来返回。我们将旁边的候选人称为行动。为了符号简单,我们今后从p,V,Q,R和rt的签名中删除X和Y,假设从上下文中可以清楚地看出X和Y的含义。我们还将使用不带参数的V来获得随机预测的预期奖励。
ACTOR-CRITIC FOR SEQUENCE PREDICTION
设θ为条件RNN的参数,我们也将其称为演员。我们的训练算法基于以下重写预期返回dVdθ的梯度的方式。
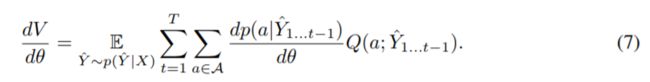
这种平等在RL中以名称政策梯度定理(Sutton等,1999)和随机行为者 - 评论家(Sutton,1984)而为人所知。请注意,我们在此公式中使用概率而不是对数概率(这在RL应用程序中更为典型),因为我们总结了操作而不是期望。直观地,这种相等性对应于增加给出高值的动作的概率,并且降低给出低值的动作的概率。由于这种梯度表达式是一种期望,因此为它建立一个无偏估计是微不足道的。

其中Yk是来自p(Y)的M个随机样本。通过用参数估计Q替换Q,可以获得具有相对低方差的偏差估计。参数估计Q称为评论家。上述公式在精神上类似于Ranzato等人(2015)在相同背景下使用的REINFORCE学习规则。
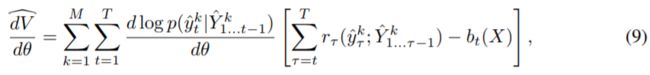
标量vt(X)称为基线或控制变量。不同之处在于,在REINFORCE中,所有动作的内部总和被其1样本估计(即
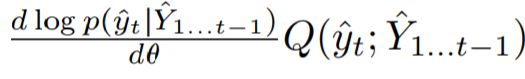
取代,其中引入对数概率
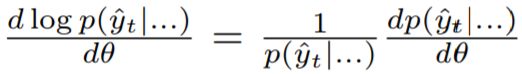
以校正yt的采样。此外,代替值Q(yt,Y 1 ... t-1),REINFORCE使用动作yt之后的累积奖励,其再次可以被视为Q的单样本估计。由于这些简化和累积奖励的潜在高方差,REINFORCE梯度估计器具有非常高的方差。为了对其进行改进,我们考虑了方程式8中的行为者 - 批评者的估计,其以显着偏差为代价具有较低的方差,因为批评者不完美并且与行动者同时训练。成功取决于我们通过设计评论网络并使用适当的培训标准来控制偏见的能力。为了实现批评,我们建议使用由φ参数化的单独RNN。评论家RNN与演员并行运行,消耗演员输出的代币yt并为所有a∈A产生估计Q(a,Y 1 ... t)。批评者和演员之间的关键区别在于,正确的答案Y被赋予评论家作为输入,类似于演员如何以X为条件。实际上,返回R(Y,Y)是Y的确定性函数,我们认为使用Y来计算Q应该会有很大的帮助。我们可以这样做,因为这些值仅在培训期间需要,我们不会在测试时使用评论家。我们还尝试提供演员国家作为评论家的额外输入。有关我们的演员 - 评论家架构的直观表示,请参见图1。

待补充